 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchSeg: A Large-Scale Dataset and Benchmark for Multi-View Food Video Segmentation
Jan 12, 2026Food image segmentation is a critical task for dietary analysis, enabling accurate estimation of food volume and nutrients. However, current methods suffer from limited multi-view data and poor generalization to new viewpoints. We introduce BenchSeg, a novel multi-view food video segmentation dataset and benchmark. BenchSeg aggregates 55 dish scenes (from Nutrition5k, Vegetables & Fruits, MetaFood3D, and FoodKit) with 25,284 meticulously annotated frames, capturing each dish under free 360° camera motion. We evaluate a diverse set of 20 state-of-the-art segmentation models (e.g., SAM-based, transformer, CNN, and large multimodal) on the existing FoodSeg103 dataset and evaluate them (alone and combined with video-memory modules) on BenchSeg. Quantitative and qualitative results demonstrate that while standard image segmenters degrade sharply under novel viewpoints, memory-augmented methods maintain temporal consistency across frames. Our best model based on a combination of SeTR-MLA+XMem2 outperforms prior work (e.g., improving over FoodMem by ~2.63% mAP), offering new insights into food segmentation and tracking for dietary analysis. We release BenchSeg to foster future research. The project page including the dataset annotations and the food segmentation models can be found at https://amughrabi.github.io/benchseg.
PhysTalk: Language-driven Real-time Physics in 3D Gaussian Scenes
Dec 31, 2025Realistic visual simulations are omnipresent, yet their creation requires computing time, rendering, and expert animation knowledge. Open-vocabulary visual effects generation from text inputs emerges as a promising solution that can unlock immense creative potential. However, current pipelines lack both physical realism and effective language interfaces, requiring slow offline optimization. In contrast, PhysTalk takes a 3D Gaussian Splatting (3DGS) scene as input and translates arbitrary user prompts into real time, physics based, interactive 4D animations. A large language model (LLM) generates executable code that directly modifies 3DGS parameters through lightweight proxies and particle dynamics. Notably, PhysTalk is the first framework to couple 3DGS directly with a physics simulator without relying on time consuming mesh extraction. While remaining open vocabulary, this design enables interactive 3D Gaussian animation via collision aware, physics based manipulation of arbitrary, multi material objects. Finally, PhysTalk is train-free and computationally lightweight: this makes 4D animation broadly accessible and shifts these workflows from a "render and wait" paradigm toward an interactive dialogue with a modern, physics-informed pipeline.
ConceptPose: Training-Free Zero-Shot Object Pose Estimation using Concept Vectors
Dec 19, 2025Object pose estimation is a fundamental task in computer vision and robotics, yet most methods require extensive, dataset-specific training. Concurrently, large-scale vision language models show remarkable zero-shot capabilities. In this work, we bridge these two worlds by introducing ConceptPose, a framework for object pose estimation that is both training-free and model-free. ConceptPose leverages a vision-language-model (VLM) to create open-vocabulary 3D concept maps, where each point is tagged with a concept vector derived from saliency maps. By establishing robust 3D-3D correspondences across concept maps, our approach allows precise estimation of 6DoF relative pose. Without any object or dataset-specific training, our approach achieves state-of-the-art results on common zero shot relative pose estimation benchmarks, significantly outperforming existing methods by over 62% in ADD(-S) score, including those that utilize extensive dataset-specific training.
UnReflectAnything: RGB-Only Highlight Removal by Rendering Synthetic Specular Supervision
Dec 11, 2025Specular highlights distort appearance, obscure texture, and hinder geometric reasoning in both natural and surgical imagery. We present UnReflectAnything, an RGB-only framework that removes highlights from a single image by predicting a highlight map together with a reflection-free diffuse reconstruction. The model uses a frozen vision transformer encoder to extract multi-scale features, a lightweight head to localize specular regions, and a token-level inpainting module that restores corrupted feature patches before producing the final diffuse image. To overcome the lack of paired supervision, we introduce a Virtual Highlight Synthesis pipeline that renders physically plausible specularities using monocular geometry, Fresnel-aware shading, and randomized lighting which enables training on arbitrary RGB images with correct geometric structure. UnReflectAnything generalizes across natural and surgical domains where non-Lambertian surfaces and non-uniform lighting create severe highlights and it achieves competitive performance with state-of-the-art results on several benchmarks. Project Page: https://alberto-rota.github.io/UnReflectAnything/
Foundation Visual Encoders Are Secretly Few-Shot Anomaly Detectors
Oct 02, 2025Few-shot anomaly detection streamlines and simplifies industrial safety inspection. However, limited samples make accurate differentiation between normal and abnormal features challenging, and even more so under category-agnostic conditions. Large-scale pre-training of foundation visual encoders has advanced many fields, as the enormous quantity of data helps to learn the general distribution of normal images. We observe that the anomaly amount in an image directly correlates with the difference in the learnt embeddings and utilize this to design a few-shot anomaly detector termed FoundAD. This is done by learning a nonlinear projection operator onto the natural image manifold. The simple operator acts as an effective tool for anomaly detection to characterize and identify out-of-distribution regions in an image. Extensive experiments show that our approach supports multi-class detection and achieves competitive performance while using substantially fewer parameters than prior methods. Backed up by evaluations with multiple foundation encoders, including fresh DINOv3, we believe this idea broadens the perspective on foundation features and advances the field of few-shot anomaly detection.
MS-CLR: Multi-Skeleton Contrastive Learning for Human Action Recognition
Aug 20, 2025Contrastive learning has gained significant attention in skeleton-based action recognition for its ability to learn robust representations from unlabeled data. However, existing methods rely on a single skeleton convention, which limits their ability to generalize across datasets with diverse joint structures and anatomical coverage. We propose Multi-Skeleton Contrastive Learning (MS-CLR), a general self-supervised framework that aligns pose representations across multiple skeleton conventions extracted from the same sequence. This encourages the model to learn structural invariances and capture diverse anatomical cues, resulting in more expressive and generalizable features. To support this, we adapt the ST-GCN architecture to handle skeletons with varying joint layouts and scales through a unified representation scheme. Experiments on the NTU RGB+D 60 and 120 datasets demonstrate that MS-CLR consistently improves performance over strong single-skeleton contrastive learning baselines. A multi-skeleton ensemble further boosts performance, setting new state-of-the-art results on both datasets.
EgoExOR: An Ego-Exo-Centric Operating Room Dataset for Surgical Activity Understanding
May 30, 2025Operating rooms (ORs) demand precise coordination among surgeons, nurses, and equipment in a fast-paced, occlusion-heavy environment, necessitating advanced perception models to enhance safety and efficiency. Existing datasets either provide partial egocentric views or sparse exocentric multi-view context, but do not explore the comprehensive combination of both. We introduce EgoExOR, the first OR dataset and accompanying benchmark to fuse first-person and third-person perspectives. Spanning 94 minutes (84,553 frames at 15 FPS) of two emulated spine procedures, Ultrasound-Guided Needle Insertion and Minimally Invasive Spine Surgery, EgoExOR integrates egocentric data (RGB, gaze, hand tracking, audio) from wearable glasses, exocentric RGB and depth from RGB-D cameras, and ultrasound imagery. Its detailed scene graph annotations, covering 36 entities and 22 relations (568,235 triplets), enable robust modeling of clinical interactions, supporting tasks like action recognition and human-centric perception. We evaluate the surgical scene graph generation performance of two adapted state-of-the-art models and offer a new baseline that explicitly leverages EgoExOR's multimodal and multi-perspective signals. This new dataset and benchmark set a new foundation for OR perception, offering a rich, multimodal resource for next-generation clinical perception.
Generative Data Augmentation for Object Point Cloud Segmentation
May 23, 2025Data augmentation is widely used to train deep learning models to address data scarcity. However, traditional data augmentation (TDA) typically relies on simple geometric transformation, such as random rotation and rescaling, resulting in minimal data diversity enrichment and limited model performance improvement. State-of-the-art generative models for 3D shape generation rely on the denoising diffusion probabilistic models and manage to generate realistic novel point clouds for 3D content creation and manipulation. Nevertheless, the generated 3D shapes lack associated point-wise semantic labels, restricting their usage in enlarging the training data for point cloud segmentation tasks. To bridge the gap between data augmentation techniques and the advanced diffusion models, we extend the state-of-the-art 3D diffusion model, Lion, to a part-aware generative model that can generate high-quality point clouds conditioned on given segmentation masks. Leveraging the novel generative model, we introduce a 3-step generative data augmentation (GDA) pipeline for point cloud segmentation training. Our GDA approach requires only a small amount of labeled samples but enriches the training data with generated variants and pseudo-labeled samples, which are validated by a novel diffusion-based pseudo-label filtering method. Extensive experiments on two large-scale synthetic datasets and a real-world medical dataset demonstrate that our GDA method outperforms TDA approach and related semi-supervised and self-supervised methods.
LiteTracker: Leveraging Temporal Causality for Accurate Low-latency Tissue Tracking
Apr 14, 2025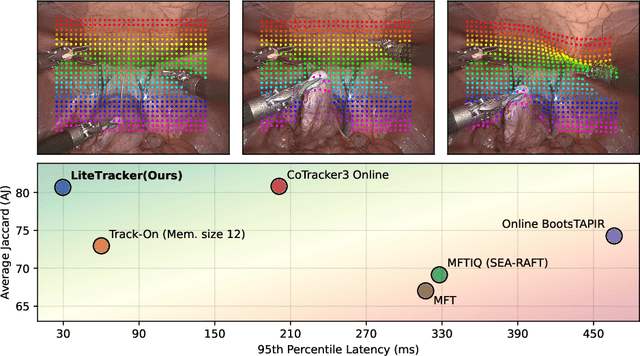
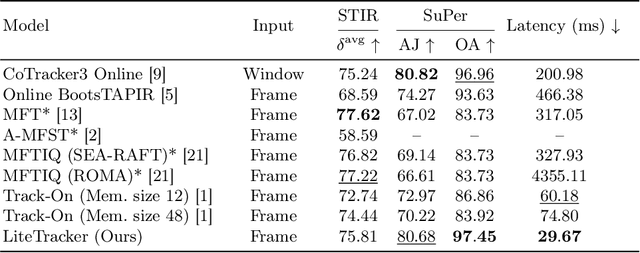
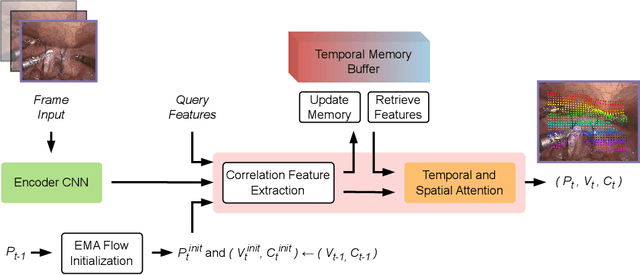

Tissue tracking plays a critical role in various surgical navigation and extended reality (XR) applications. While current methods trained on large synthetic datasets achieve high tracking accuracy and generalize well to endoscopic scenes, their runtime performances fail to meet the low-latency requirements necessary for real-time surgical applications. To address this limitation, we propose LiteTracker, a low-latency method for tissue tracking in endoscopic video streams. LiteTracker builds on a state-of-the-art long-term point tracking method, and introduces a set of training-free runtime optimizations. These optimizations enable online, frame-by-frame tracking by leveraging a temporal memory buffer for efficient feature reuse and utilizing prior motion for accurate track initialization. LiteTracker demonstrates significant runtime improvements being around 7x faster than its predecessor and 2x than the state-of-the-art. Beyond its primary focus on efficiency, LiteTracker delivers high-accuracy tracking and occlusion prediction, performing competitively on both the STIR and SuPer datasets. We believe LiteTracker is an important step toward low-latency tissue tracking for real-time surgical applications in the operating room.
PRISM-0: A Predicate-Rich Scene Graph Generation Framework for Zero-Shot Open-Vocabulary Tasks
Apr 01, 2025In Scene Graphs Generation (SGG) one extracts structured representation from visual inputs in the form of objects nodes and predicates connecting them. This facilitates image-based understanding and reasoning for various downstream tasks. Although fully supervised SGG approaches showed steady performance improvements, they suffer from a severe training bias. This is caused by the availability of only small subsets of curated data and exhibits long-tail predicate distribution issues with a lack of predicate diversity adversely affecting downstream tasks. To overcome this, we introduce PRISM-0, a framework for zero-shot open-vocabulary SGG that bootstraps foundation models in a bottom-up approach to capture the whole spectrum of diverse, open-vocabulary predicate prediction. Detected object pairs are filtered and passed to a Vision Language Model (VLM) that generates descriptive captions. These are used to prompt an LLM to generate fine-andcoarse-grained predicates for the pair. The predicates are then validated using a VQA model to provide a final SGG. With the modular and dataset-independent PRISM-0, we can enrich existing SG datasets such as Visual Genome (VG). Experiments illustrate that PRIMS-0 generates semantically meaningful graphs that improve downstream tasks such as Image Captioning and Sentence-to-Graph Retrieval with a performance on par to the best fully supervised methods.