 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgoal-Based Explanations for Unreliable Intelligent Decision Support Systems
Jan 11, 2022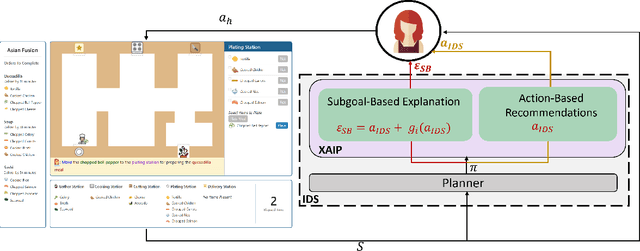

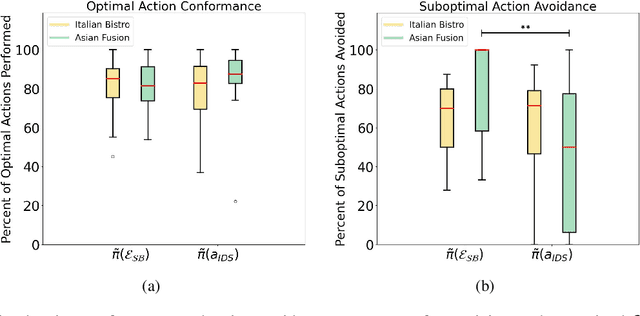
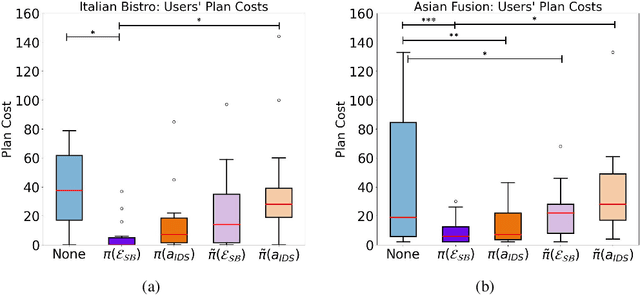
Intelligent decision support (IDS) systems leverage artificial intelligence techniques to generate recommendations that guide human users through the decision making phases of a task. However, a key challenge is that IDS systems are not perfect, and in complex real-world scenarios may produce incorrect output or fail to work altogether. The field of explainable AI planning (XAIP) has sought to develop techniques that make the decision making of sequential decision making AI systems more explainable to end-users. Critically, prior work in applying XAIP techniques to IDS systems has assumed that the plan being proposed by the planner is always optimal, and therefore the action or plan being recommended as decision support to the user is always correct. In this work, we examine novice user interactions with a non-robust IDS system -- one that occasionally recommends the wrong action, and one that may become unavailable after users have become accustomed to its guidance. We introduce a novel explanation type, subgoal-based explanations, for planning-based IDS systems, that supplements traditional IDS output with information about the subgoal toward which the recommended action would contribute. We demonstrate that subgoal-based explanations lead to improved user task performance, improve user ability to distinguish optimal and suboptimal IDS recommendations, are preferred by users, and enable more robust user performance in the case of IDS failure
Acquisition of Chess Knowledge in AlphaZero
Nov 27, 2021

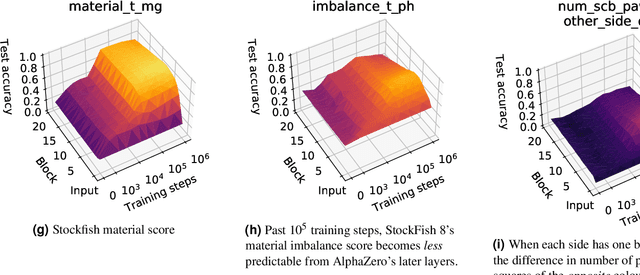
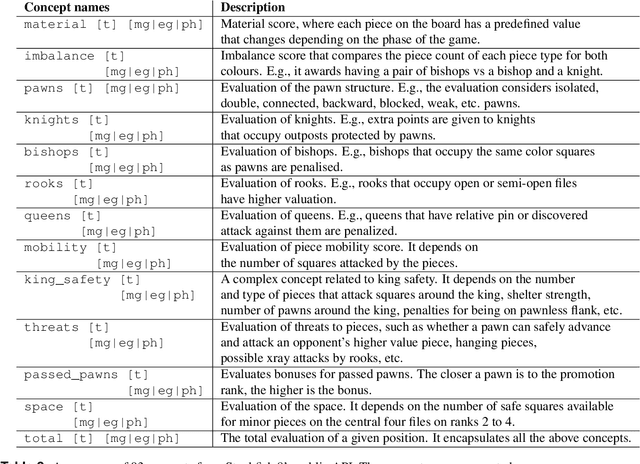
What is learned by sophisticated neural network agents such as AlphaZero? This question is of both scientific and practical interest. If the representations of strong neural networks bear no resemblance to human concepts, our ability to understand faithful explanations of their decisions will be restricted, ultimately limiting what we can achieve with neural network interpretability. In this work we provide evidence that human knowledge is acquired by the AlphaZero neural network as it trains on the game of chess. By probing for a broad range of human chess concepts we show when and where these concepts are represented in the AlphaZero network. We also provide a behavioural analysis focusing on opening play, including qualitative analysis from chess Grandmaster Vladimir Kramnik. Finally, we carry out a preliminary investigation looking at the low-level details of AlphaZero's representations, and make the resulting behavioural and representational analyses available online.
Best of both worlds: local and global explanations with human-understandable concepts
Jun 16, 2021



Interpretability techniques aim to provide the rationale behind a model's decision, typically by explaining either an individual prediction (local explanation, e.g. `why is this patient diagnosed with this condition') or a class of predictions (global explanation, e.g. `why are patients diagnosed with this condition in general'). While there are many methods focused on either one, few frameworks can provide both local and global explanations in a consistent manner. In this work, we combine two powerful existing techniques, one local (Integrated Gradients, IG) and one global (Testing with Concept Activation Vectors), to provide local, and global concept-based explanations. We first validate our idea using two synthetic datasets with a known ground truth, and further demonstrate with a benchmark natural image dataset. We test our method with various concepts, target classes, model architectures and IG baselines. We show that our method improves global explanations over TCAV when compared to ground truth, and provides useful insights. We hope our work provides a step towards building bridges between many existing local and global methods to get the best of both worlds.
DISSECT: Disentangled Simultaneous Explanations via Concept Traversals
May 31, 2021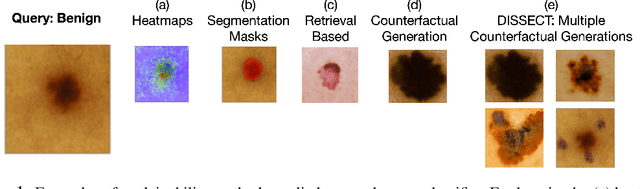


Explaining deep learning model inferences is a promising venue for scientific understanding, improving safety, uncovering hidden biases, evaluating fairness, and beyond, as argued by many scholars. One of the principal benefits of counterfactual explanations is allowing users to explore "what-if" scenarios through what does not and cannot exist in the data, a quality that many other forms of explanation such as heatmaps and influence functions are inherently incapable of doing. However, most previous work on generative explainability cannot disentangle important concepts effectively, produces unrealistic examples, or fails to retain relevant information. We propose a novel approach, DISSECT, that jointly trains a generator, a discriminator, and a concept disentangler to overcome such challenges using little supervision. DISSECT generates Concept Traversals (CTs), defined as a sequence of generated examples with increasing degrees of concepts that influence a classifier's decision. By training a generative model from a classifier's signal, DISSECT offers a way to discover a classifier's inherent "notion" of distinct concepts automatically rather than rely on user-predefined concepts. We show that DISSECT produces CTs that (1) disentangle several concepts, (2) are influential to a classifier's decision and are coupled to its reasoning due to joint training (3), are realistic, (4) preserve relevant information, and (5) are stable across similar inputs. We validate DISSECT on several challenging synthetic and realistic datasets where previous methods fall short of satisfying desirable criteria for interpretability and show that it performs consistently well and better than existing methods. Finally, we present experiments showing applications of DISSECT for detecting potential biases of a classifier and identifying spurious artifacts that impact predictions.
Debugging Tests for Model Explanations
Nov 10, 2020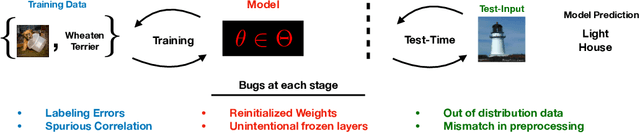
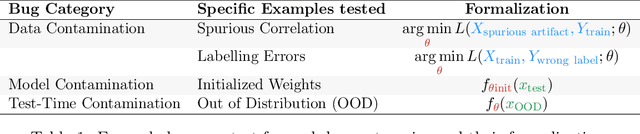


We investigate whether post-hoc model explanations are effective for diagnosing model errors--model debugging. In response to the challenge of explaining a model's prediction, a vast array of explanation methods have been proposed. Despite increasing use, it is unclear if they are effective. To start, we categorize \textit{bugs}, based on their source, into:~\textit{data, model, and test-time} contamination bugs. For several explanation methods, we assess their ability to: detect spurious correlation artifacts (data contamination), diagnose mislabeled training examples (data contamination), differentiate between a (partially) re-initialized model and a trained one (model contamination), and detect out-of-distribution inputs (test-time contamination). We find that the methods tested are able to diagnose a spurious background bug, but not conclusively identify mislabeled training examples. In addition, a class of methods, that modify the back-propagation algorithm are invariant to the higher layer parameters of a deep network; hence, ineffective for diagnosing model contamination. We complement our analysis with a human subject study, and find that subjects fail to identify defective models using attributions, but instead rely, primarily, on model predictions. Taken together, our results provide guidance for practitioners and researchers turning to explanations as tools for model debugging.
Concept Bottleneck Models
Jul 09, 2020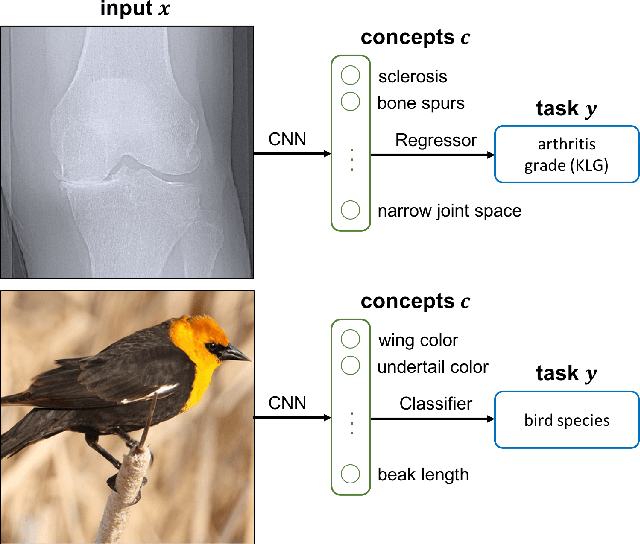
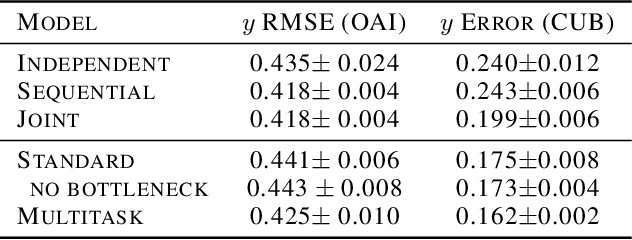
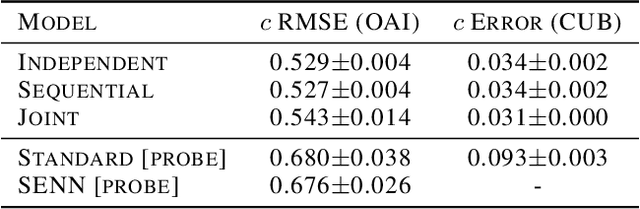
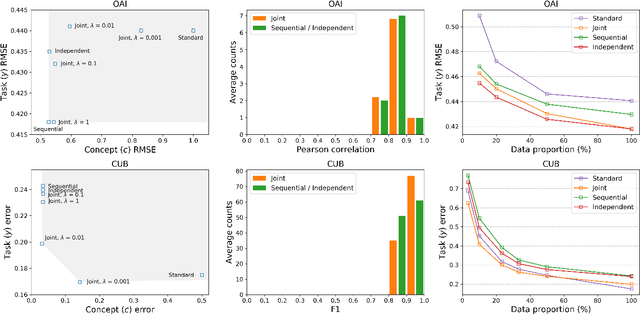
We seek to learn models that we can interact with using high-level concepts: if the model did not think there was a bone spur in the x-ray, would it still predict severe arthritis? State-of-the-art models today do not typically support the manipulation of concepts like "the existence of bone spurs", as they are trained end-to-end to go directly from raw input (e.g., pixels) to output (e.g., arthritis severity). We revisit the classic idea of first predicting concepts that are provided at training time, and then using these concepts to predict the label. By construction, we can intervene on these \emph{concept bottleneck models} by editing their predicted concept values and propagating these changes to the final prediction. On x-ray grading and bird identification, concept bottleneck models achieve competitive accuracy with standard end-to-end models, while enabling interpretation in terms of high-level clinical concepts ("bone spurs") or bird attributes ("wing color"). These models also allow for richer human-model interaction: accuracy improves significantly if we can correct model mistakes on concepts at test time.
On Concept-Based Explanations in Deep Neural Networks
Oct 17, 2019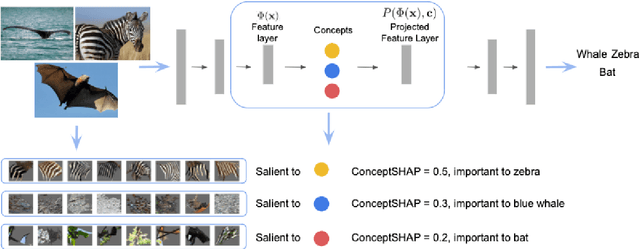
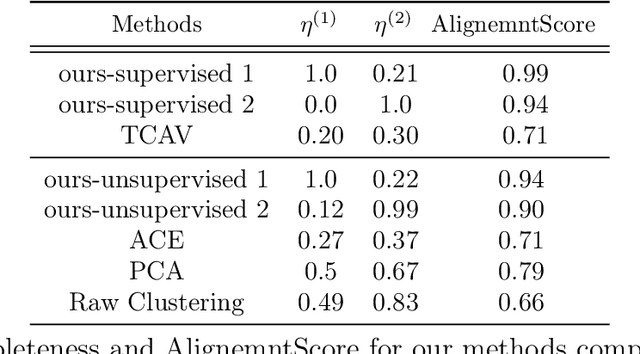
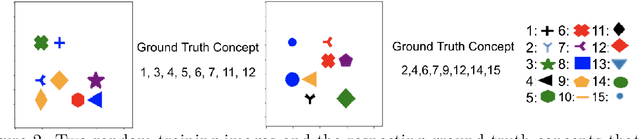

Deep neural networks (DNNs) build high-level intelligence on low-level raw features. Understanding of this high-level intelligence can be enabled by deciphering the concepts they base their decisions on, as human-level thinking. In this paper, we study concept-based explainability for DNNs in a systematic framework. First, we define the notion of completeness, which quantifies how sufficient a particular set of concepts is in explaining a model's prediction behavior. Based on performance and variability motivations, we propose two definitions to quantify completeness. We show that under degenerate conditions, our method is equivalent to Principal Component Analysis. Next, we propose a concept discovery method that considers two additional constraints to encourage the interpretability of the discovered concepts. We use game-theoretic notions to aggregate over sets to define an importance score for each discovered concept, which we call ConceptSHAP. On specifically-designed synthetic datasets and real-world text and image datasets, we validate the effectiveness of our framework in finding concepts that are complete in explaining the decision, and interpretable.
BIM: Towards Quantitative Evaluation of Interpretability Methods with Ground Truth
Jul 23, 2019
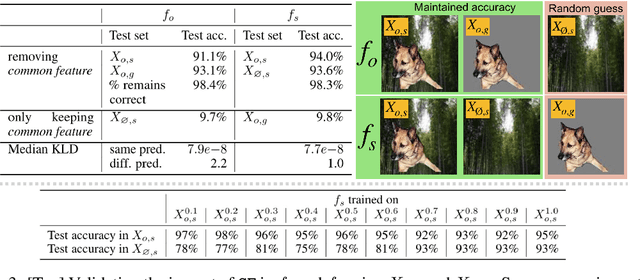

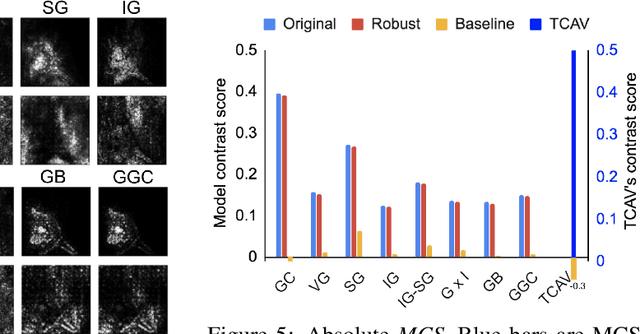
Interpretability is rising as an important area of research in machine learning for safer deployment of machine learning systems. Despite active developments, quantitative evaluation of interpretability methods remains a challenge due to the lack of ground truth; we do not know which features or concepts are important to a classification model. In this work, we propose the Benchmark Interpretability Methods (BIM) framework, which offers a set of tools to quantitatively compare a model's ground truth to the output of interpretability methods. Our contributions are: 1) a carefully crafted dataset and models trained with known ground truth and 2) three complementary metrics to evaluate interpretability methods. Our metrics focus on identifying false positives---features that are incorrectly attributed as important. These metrics compare how methods perform across models, across images, and per image. We open source the dataset, models, and metrics evaluated on many widely-used interpretability methods.
Towards Realistic Individual Recourse and Actionable Explanations in Black-Box Decision Making Systems
Jul 22, 2019
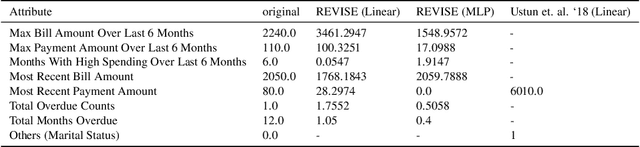
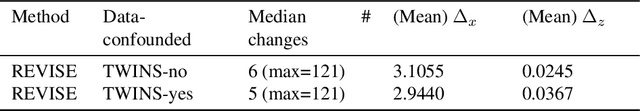
Machine learning based decision making systems are increasingly affecting humans. An individual can suffer an undesirable outcome under such decision making systems (e.g. denied credit) irrespective of whether the decision is fair or accurate. Individual recourse pertains to the problem of providing an actionable set of changes a person can undertake in order to improve their outcome. We propose a recourse algorithm that models the underlying data distribution or manifold. We then provide a mechanism to generate the smallest set of changes that will improve an individual's outcome. This mechanism can be easily used to provide recourse for any differentiable machine learning based decision making system. Further, the resulting algorithm is shown to be applicable to both supervised classification and causal decision making systems. Our work attempts to fill gaps in existing fairness literature that have primarily focused on discovering and/or algorithmically enforcing fairness constraints on decision making systems. This work also provides an alternative approach to generating counterfactual explanations.
Explaining Classifiers with Causal Concept Effect (CaCE)
Jul 16, 2019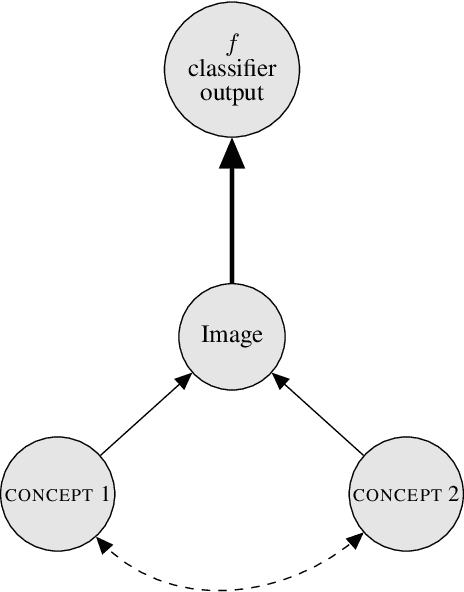
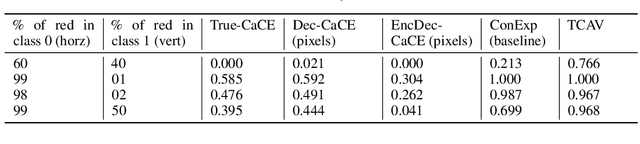


How can we understand classification decisions made by deep neural nets? We propose answering this question by using ideas from causal inference. We define the ``Causal Concept Effect'' (CaCE) as the causal effect that the presence or absence of a concept has on the prediction of a given deep neural net. We then use this measure as a mean to understand what drives the network's prediction and what does not. Yet many existing interpretability methods rely solely on correlations, resulting in potentially misleading explanations. We show how CaCE can avoid such mistakes. In high-risk domains such as medicine, knowing the root cause of the prediction is crucial. If we knew that the network's prediction was caused by arbitrary concepts such as the lighting conditions in an X-ray room instead of medically meaningful concept, this would prevent us from disastrous deployment of such models. Estimating CaCE is difficult in situations where we cannot easily simulate the do-operator. As a simple solution, we propose learning a generative model, specifically a Variational AutoEncoder (VAE) on image pixels or image embeddings extracted from the classifier to measure VAE-CaCE. We show that VAE-CaCE is able to correctly estimate the true causal effect as compared to other baselines in controlled settings with synthetic and semi-natural high dimensional images.