 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypothesis Transfer Learning via Transformation Functions
Nov 05, 2017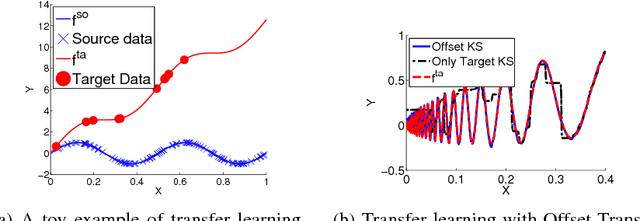
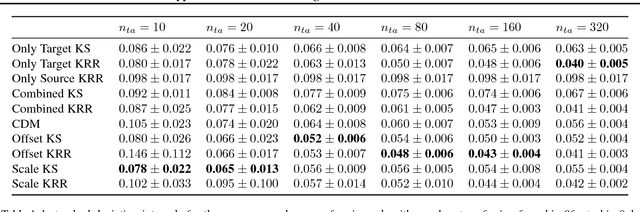
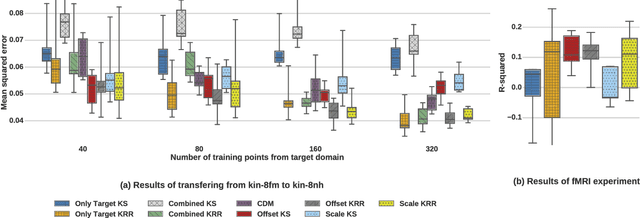
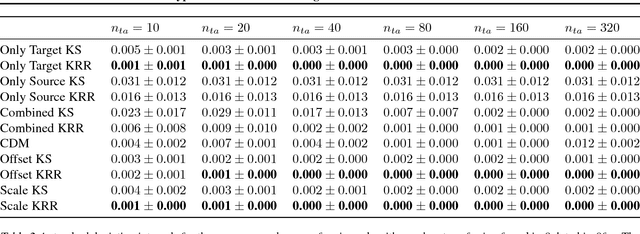
We consider the Hypothesis Transfer Learning (HTL) problem where one incorporates a hypothesis trained on the source domain into the learning procedure of the target domain. Existing theoretical analysis either only studies specific algorithms or only presents upper bounds on the generalization error but not on the excess risk. In this paper, we propose a unified algorithm-dependent framework for HTL through a novel notion of transformation function, which characterizes the relation between the source and the target domains. We conduct a general risk analysis of this framework and in particular, we show for the first time, if two domains are related, HTL enjoys faster convergence rates of excess risks for Kernel Smoothing and Kernel Ridge Regression than those of the classical non-transfer learning settings. Experiments on real world data demonstrate the effectiveness of our framework.
A Generic Approach for Escaping Saddle points
Sep 05, 2017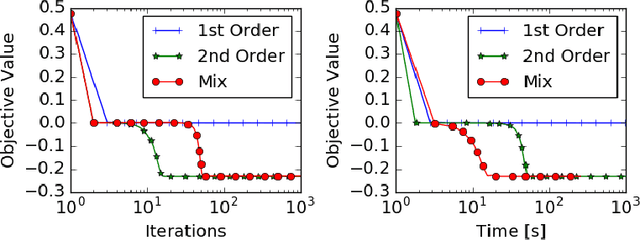
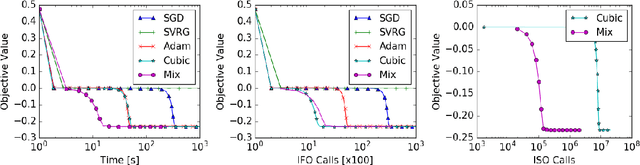

A central challenge to using first-order methods for optimizing nonconvex problems is the presence of saddle points. First-order methods often get stuck at saddle points, greatly deteriorating their performance. Typically, to escape from saddles one has to use second-order methods. However, most works on second-order methods rely extensively on expensive Hessian-based computations, making them impractical in large-scale settings. To tackle this challenge, we introduce a generic framework that minimizes Hessian based computations while at the same time provably converging to second-order critical points. Our framework carefully alternates between a first-order and a second-order subroutine, using the latter only close to saddle points, and yields convergence results competitive to the state-of-the-art. Empirical results suggest that our strategy also enjoys a good practical performance.
Equivariance Through Parameter-Sharing
Jun 13, 2017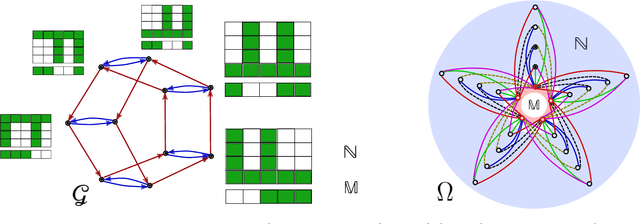
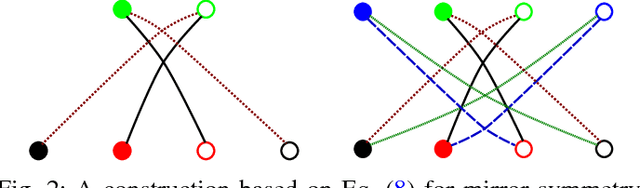
We propose to study equivariance in deep neural networks through parameter symmetries. In particular, given a group $\mathcal{G}$ that acts discretely on the input and output of a standard neural network layer $\phi_{W}: \Re^{M} \to \Re^{N}$, we show that $\phi_{W}$ is equivariant with respect to $\mathcal{G}$-action iff $\mathcal{G}$ explains the symmetries of the network parameters $W$. Inspired by this observation, we then propose two parameter-sharing schemes to induce the desirable symmetry on $W$. Our procedures for tying the parameters achieve $\mathcal{G}$-equivariance and, under some conditions on the action of $\mathcal{G}$, they guarantee sensitivity to all other permutation groups outside $\mathcal{G}$.
Recurrent Estimation of Distributions
May 30, 2017
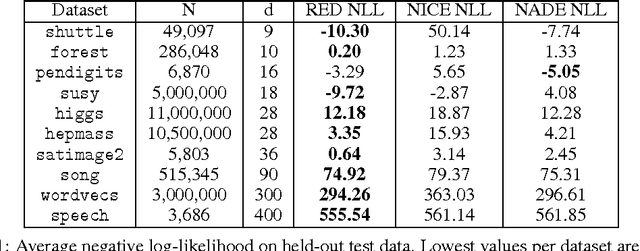

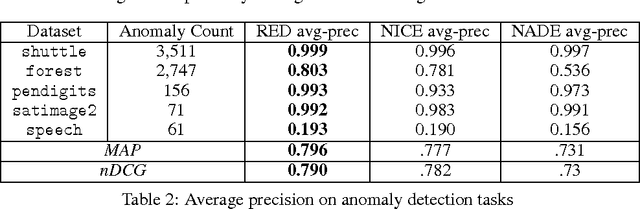
This paper presents the recurrent estimation of distributions (RED) for modeling real-valued data in a semiparametric fashion. RED models make two novel uses of recurrent neural networks (RNNs) for density estimation of general real-valued data. First, RNNs are used to transform input covariates into a latent space to better capture conditional dependencies in inputs. After, an RNN is used to compute the conditional distributions of the latent covariates. The resulting model is efficient to train, compute, and sample from, whilst producing normalized pdfs. The effectiveness of RED is shown via several real-world data experiments. Our results show that RED models achieve a lower held-out negative log-likelihood than other neural network approaches across multiple dataset sizes and dimensionalities. Further context of the efficacy of RED is provided by considering anomaly detection tasks, where we also observe better performance over alternative models.
Asynchronous Parallel Bayesian Optimisation via Thompson Sampling
May 25, 2017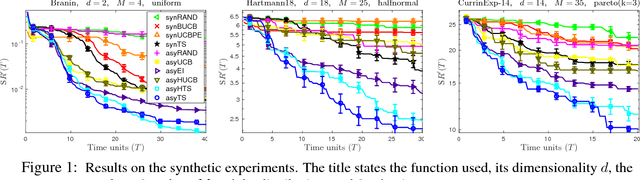

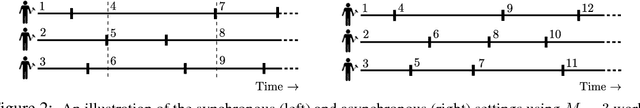
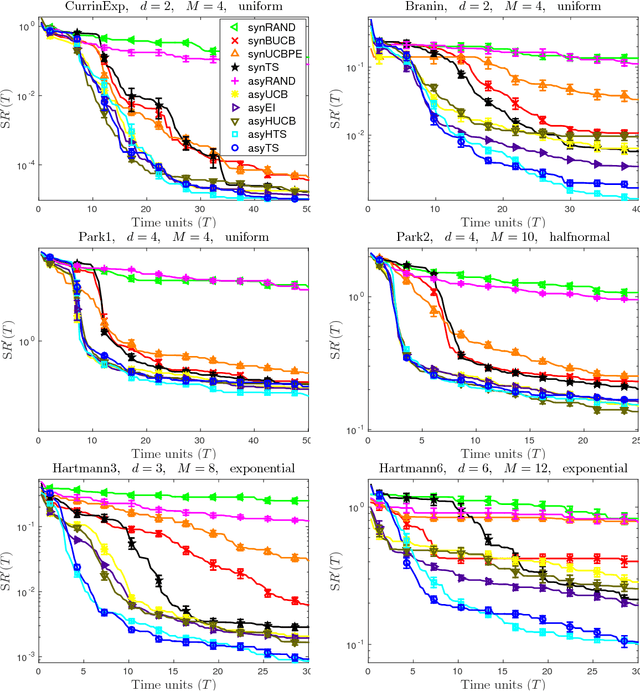
We design and analyse variations of the classical Thompson sampling (TS) procedure for Bayesian optimisation (BO) in settings where function evaluations are expensive, but can be performed in parallel. Our theoretical analysis shows that a direct application of the sequential Thompson sampling algorithm in either synchronous or asynchronous parallel settings yields a surprisingly powerful result: making $n$ evaluations distributed among $M$ workers is essentially equivalent to performing $n$ evaluations in sequence. Further, by modeling the time taken to complete a function evaluation, we show that, under a time constraint, asynchronously parallel TS achieves asymptotically lower regret than both the synchronous and sequential versions. These results are complemented by an experimental analysis, showing that asynchronous TS outperforms a suite of existing parallel BO algorithms in simulations and in a hyper-parameter tuning application in convolutional neural networks. In addition to these, the proposed procedure is conceptually and computationally much simpler than existing work for parallel BO.
Data-driven Random Fourier Features using Stein Effect
May 23, 2017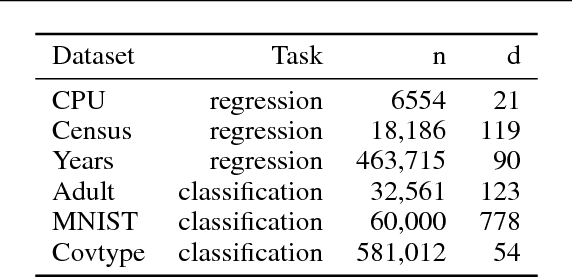
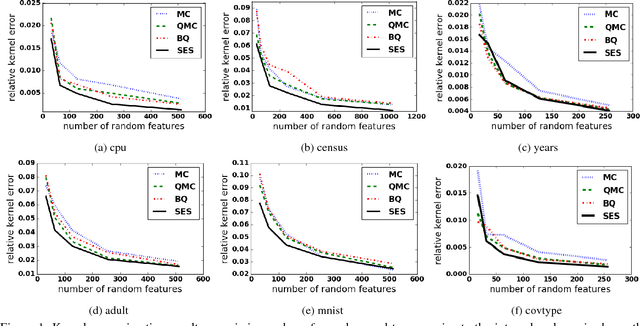
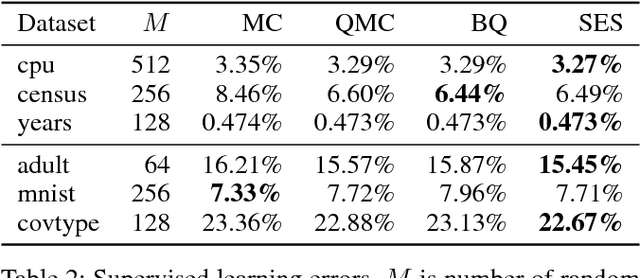
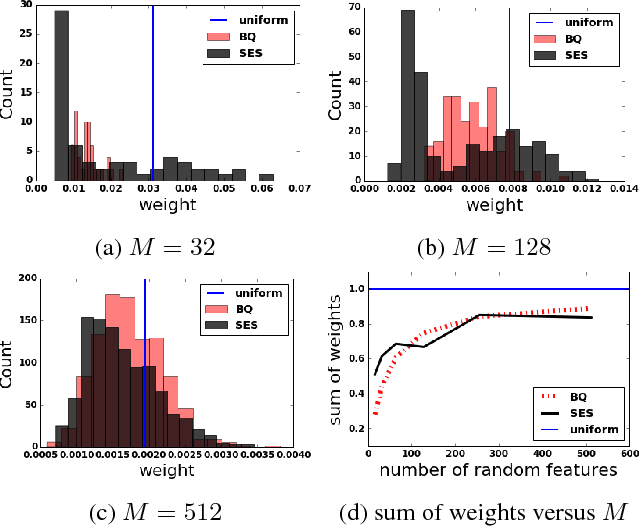
Large-scale kernel approximation is an important problem in machine learning research. Approaches using random Fourier features have become increasingly popular [Rahimi and Recht, 2007], where kernel approximation is treated as empirical mean estimation via Monte Carlo (MC) or Quasi-Monte Carlo (QMC) integration [Yang et al., 2014]. A limitation of the current approaches is that all the features receive an equal weight summing to 1. In this paper, we propose a novel shrinkage estimator from "Stein effect", which provides a data-driven weighting strategy for random features and enjoys theoretical justifications in terms of lowering the empirical risk. We further present an efficient randomized algorithm for large-scale applications of the proposed method. Our empirical results on six benchmark data sets demonstrate the advantageous performance of this approach over representative baselines in both kernel approximation and supervised learning tasks.
One Network to Solve Them All --- Solving Linear Inverse Problems using Deep Projection Models
Mar 29, 2017
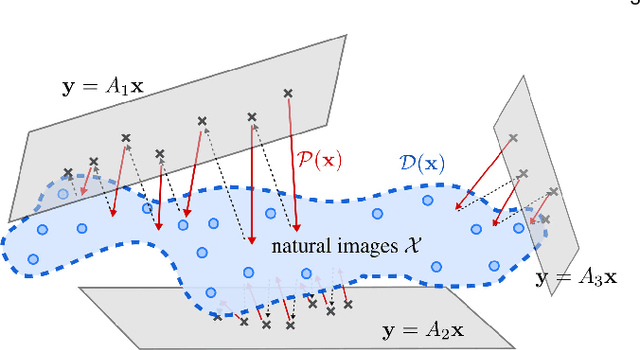
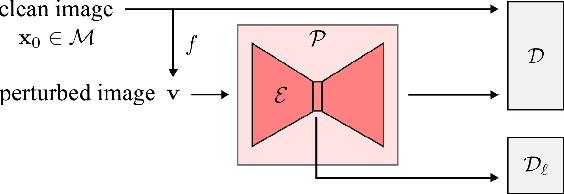
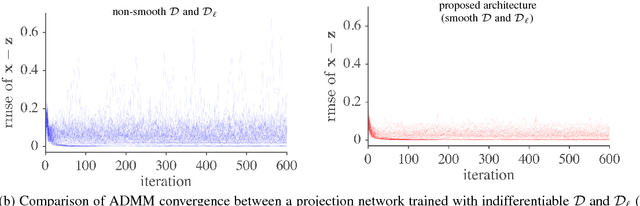
While deep learning methods have achieved state-of-the-art performance in many challenging inverse problems like image inpainting and super-resolution, they invariably involve problem-specific training of the networks. Under this approach, different problems require different networks. In scenarios where we need to solve a wide variety of problems, e.g., on a mobile camera, it is inefficient and costly to use these specially-trained networks. On the other hand, traditional methods using signal priors can be used in all linear inverse problems but often have worse performance on challenging tasks. In this work, we provide a middle ground between the two kinds of methods --- we propose a general framework to train a single deep neural network that solves arbitrary linear inverse problems. The proposed network acts as a proximal operator for an optimization algorithm and projects non-image signals onto the set of natural images defined by the decision boundary of a classifier. In our experiments, the proposed framework demonstrates superior performance over traditional methods using a wavelet sparsity prior and achieves comparable performance of specially-trained networks on tasks including compressive sensing and pixel-wise inpainting.
Multi-fidelity Bayesian Optimisation with Continuous Approximations
Mar 18, 2017
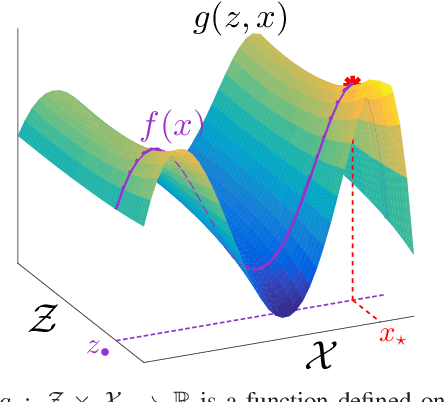
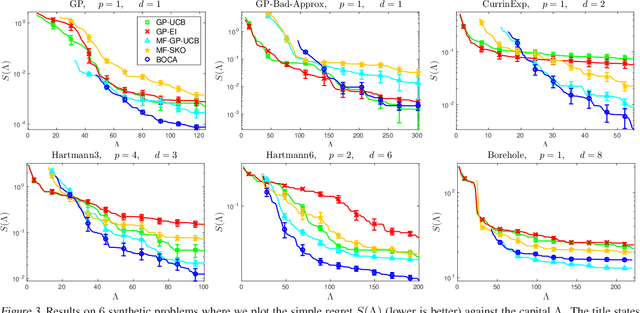
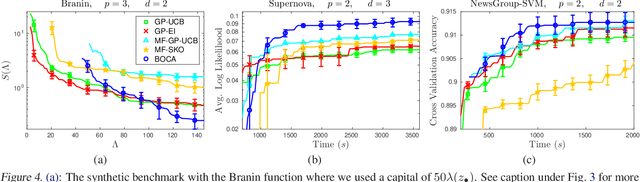
Bandit methods for black-box optimisation, such as Bayesian optimisation, are used in a variety of applications including hyper-parameter tuning and experiment design. Recently, \emph{multi-fidelity} methods have garnered considerable attention since function evaluations have become increasingly expensive in such applications. Multi-fidelity methods use cheap approximations to the function of interest to speed up the overall optimisation process. However, most multi-fidelity methods assume only a finite number of approximations. In many practical applications however, a continuous spectrum of approximations might be available. For instance, when tuning an expensive neural network, one might choose to approximate the cross validation performance using less data $N$ and/or few training iterations $T$. Here, the approximations are best viewed as arising out of a continuous two dimensional space $(N,T)$. In this work, we develop a Bayesian optimisation method, BOCA, for this setting. We characterise its theoretical properties and show that it achieves better regret than than strategies which ignore the approximations. BOCA outperforms several other baselines in synthetic and real experiments.
The Statistical Recurrent Unit
Mar 01, 2017
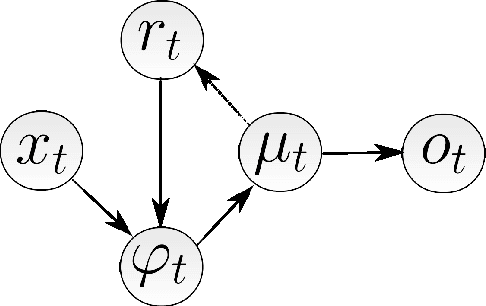
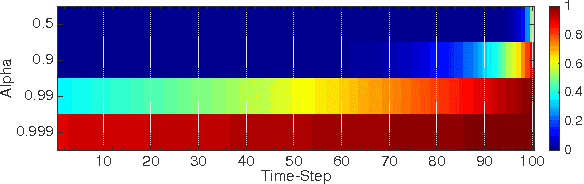

Sophisticated gated recurrent neural network architectures like LSTMs and GRUs have been shown to be highly effective in a myriad of applications. We develop an un-gated unit, the statistical recurrent unit (SRU), that is able to learn long term dependencies in data by only keeping moving averages of statistics. The SRU's architecture is simple, un-gated, and contains a comparable number of parameters to LSTMs; yet, SRUs perform favorably to more sophisticated LSTM and GRU alternatives, often outperforming one or both in various tasks. We show the efficacy of SRUs as compared to LSTMs and GRUs in an unbiased manner by optimizing respective architectures' hyperparameters in a Bayesian optimization scheme for both synthetic and real-world tasks.
Deep Learning with Sets and Point Clouds
Feb 24, 2017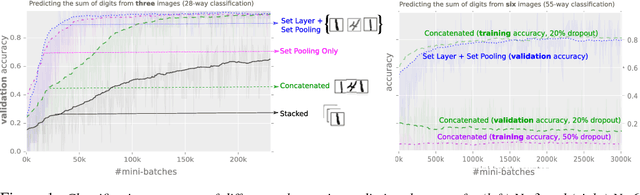
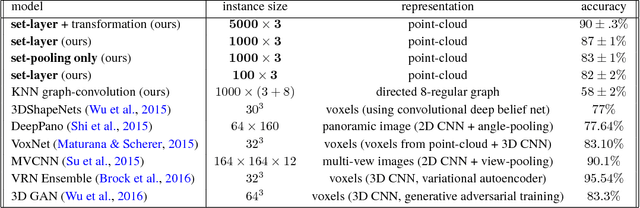
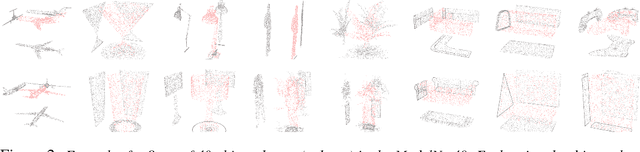
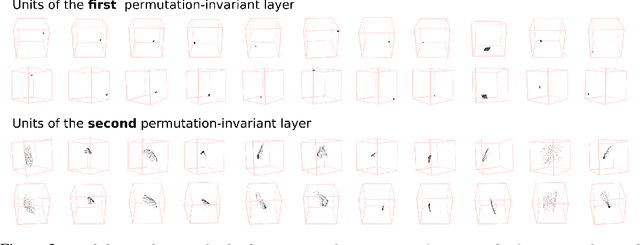
We introduce a simple permutation equivariant layer for deep learning with set structure.This type of layer, obtained by parameter-sharing, has a simple implementation and linear-time complexity in the size of each set. We use deep permutation-invariant networks to perform point-could classification and MNIST-digit summation, where in both cases the output is invariant to permutations of the input. In a semi-supervised setting, where the goal is make predictions for each instance within a set, we demonstrate the usefulness of this type of layer in set-outlier detection as well as semi-supervised learning with clustering side-information.