 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore Contextual Information for 3D Scene Graph Generation
Oct 12, 2022
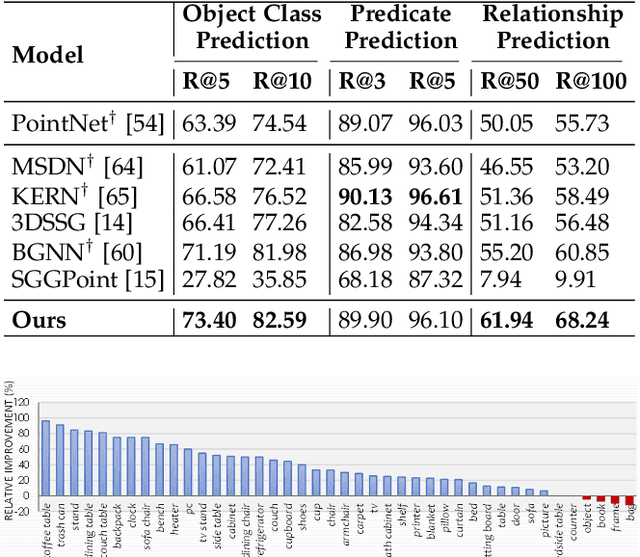
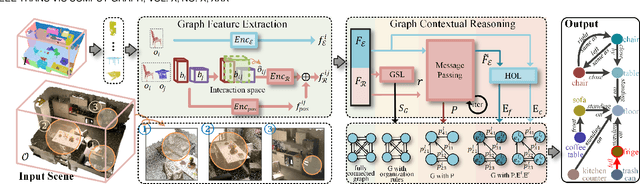
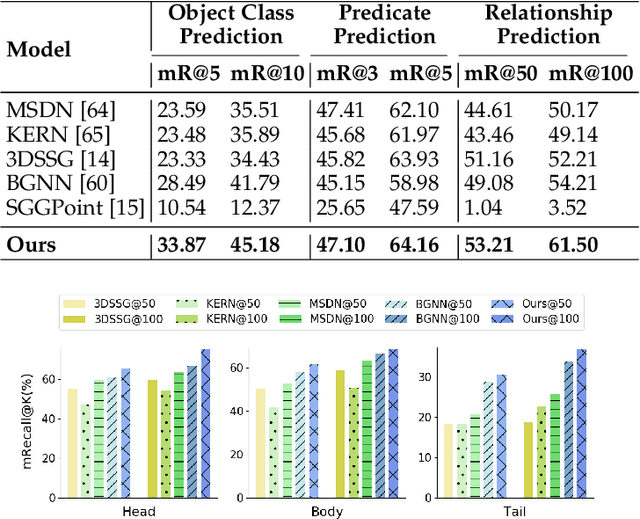
3D scene graph generation (SGG) has been of high interest in computer vision. Although the accuracy of 3D SGG on coarse classification and single relation label has been gradually improved, the performance of existing works is still far from being perfect for fine-grained and multi-label situations. In this paper, we propose a framework fully exploring contextual information for the 3D SGG task, which attempts to satisfy the requirements of fine-grained entity class, multiple relation labels, and high accuracy simultaneously. Our proposed approach is composed of a Graph Feature Extraction module and a Graph Contextual Reasoning module, achieving appropriate information-redundancy feature extraction, structured organization, and hierarchical inferring. Our approach achieves superior or competitive performance over previous methods on the 3DSSG dataset, especially on the relationship prediction sub-task.
NodeTrans: A Graph Transfer Learning Approach for Traffic Prediction
Jul 04, 2022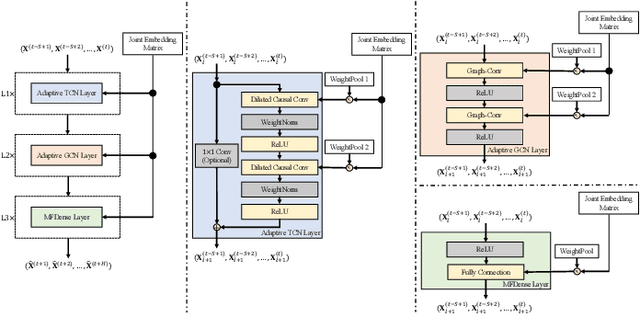
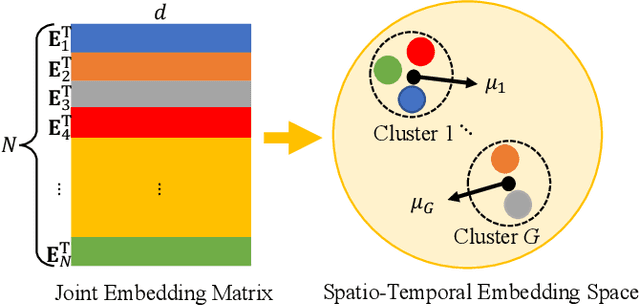
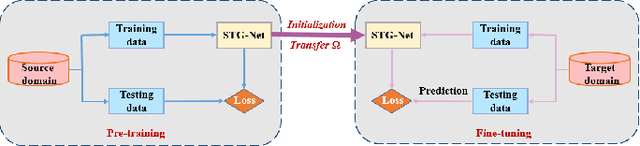
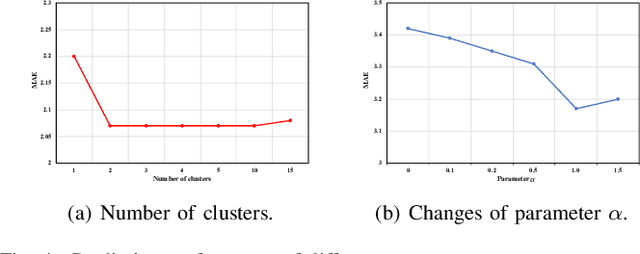
Recently, deep learning methods have made great progress in traffic prediction, but their performance depends on a large amount of historical data. In reality, we may face the data scarcity issue. In this case, deep learning models fail to obtain satisfactory performance. Transfer learning is a promising approach to solve the data scarcity issue. However, existing transfer learning approaches in traffic prediction are mainly based on regular grid data, which is not suitable for the inherent graph data in the traffic network. Moreover, existing graph-based models can only capture shared traffic patterns in the road network, and how to learn node-specific patterns is also a challenge. In this paper, we propose a novel transfer learning approach to solve the traffic prediction with few data, which can transfer the knowledge learned from a data-rich source domain to a data-scarce target domain. First, a spatial-temporal graph neural network is proposed, which can capture the node-specific spatial-temporal traffic patterns of different road networks. Then, to improve the robustness of transfer, we design a pattern-based transfer strategy, where we leverage a clustering-based mechanism to distill common spatial-temporal patterns in the source domain, and use these knowledge to further improve the prediction performance of the target domain. Experiments on real-world datasets verify the effectiveness of our approach.
Soft-mask: Adaptive Substructure Extractions for Graph Neural Networks
Jun 11, 2022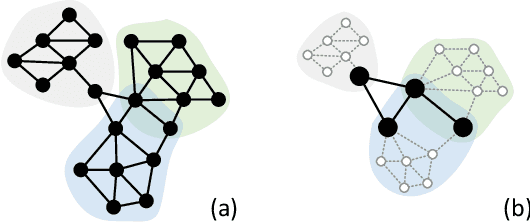
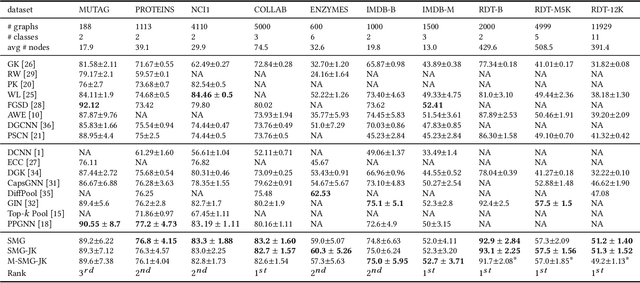

For learning graph representations, not all detailed structures within a graph are relevant to the given graph tasks. Task-relevant structures can be $localized$ or $sparse$ which are only involved in subgraphs or characterized by the interactions of subgraphs (a hierarchical perspective). A graph neural network should be able to efficiently extract task-relevant structures and be invariant to irrelevant parts, which is challenging for general message passing GNNs. In this work, we propose to learn graph representations from a sequence of subgraphs of the original graph to better capture task-relevant substructures or hierarchical structures and skip $noisy$ parts. To this end, we design soft-mask GNN layer to extract desired subgraphs through the mask mechanism. The soft-mask is defined in a continuous space to maintain the differentiability and characterize the weights of different parts. Compared with existing subgraph or hierarchical representation learning methods and graph pooling operations, the soft-mask GNN layer is not limited by the fixed sample or drop ratio, and therefore is more flexible to extract subgraphs with arbitrary sizes. Extensive experiments on public graph benchmarks show that soft-mask mechanism brings performance improvements. And it also provides interpretability where visualizing the values of masks in each layer allows us to have an insight into the structures learned by the model.
Biologically Inspired Dynamic Thresholds for Spiking Neural Networks
Jun 09, 2022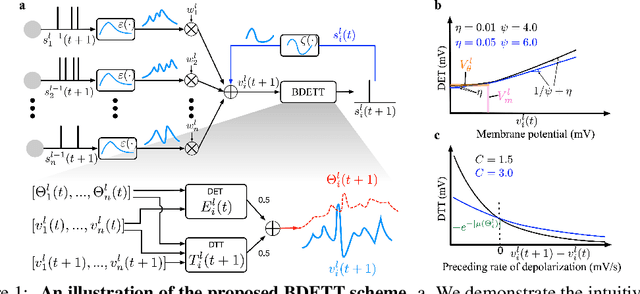
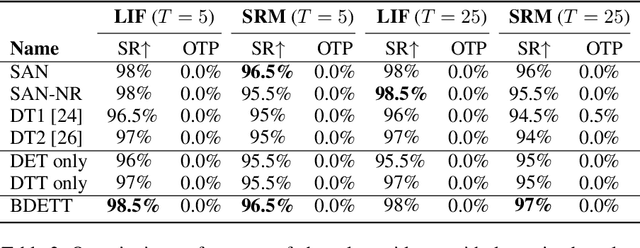
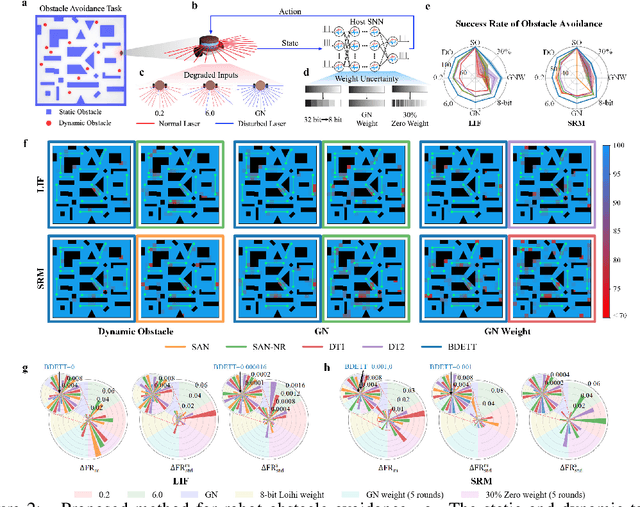
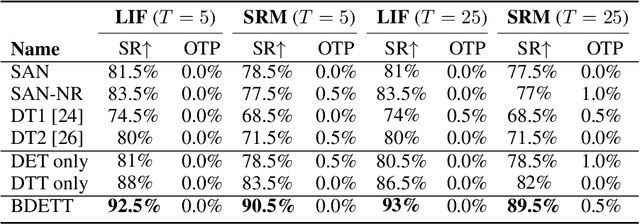
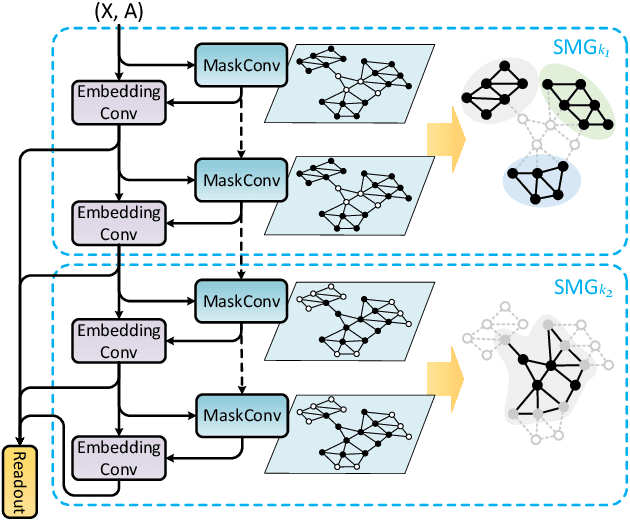
The dynamic membrane potential threshold, as one of the essential properties of a biological neuron, is a spontaneous regulation mechanism that maintains neuronal homeostasis, i.e., the constant overall spiking firing rate of a neuron. As such, the neuron firing rate is regulated by a dynamic spiking threshold, which has been extensively studied in biology. Existing work in the machine learning community does not employ bioplausible spiking threshold schemes. This work aims at bridging this gap by introducing a novel bioinspired dynamic energy-temporal threshold (BDETT) scheme for spiking neural networks (SNNs). The proposed BDETT scheme mirrors two bioplausible observations: a dynamic threshold has 1) a positive correlation with the average membrane potential and 2) a negative correlation with the preceding rate of depolarization. We validate the effectiveness of the proposed BDETT on robot obstacle avoidance and continuous control tasks under both normal conditions and various degraded conditions, including noisy observations, weights, and dynamic environments. We find that the BDETT outperforms existing static and heuristic threshold approaches by significant margins in all tested conditions, and we confirm that the proposed bioinspired dynamic threshold scheme offers bioplausible homeostasis to SNNs in complex real-world tasks.
DR-GAN: Distribution Regularization for Text-to-Image Generation
Apr 17, 2022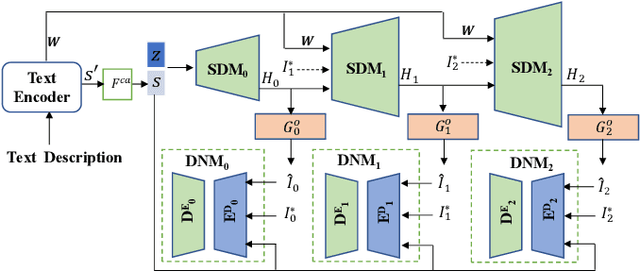
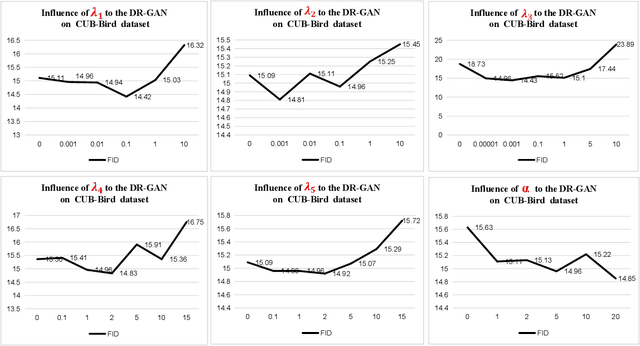

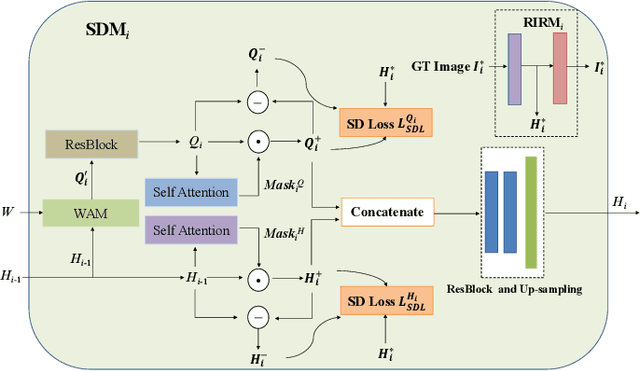
This paper presents a new Text-to-Image generation model, named Distribution Regularization Generative Adversarial Network (DR-GAN), to generate images from text descriptions from improved distribution learning. In DR-GAN, we introduce two novel modules: a Semantic Disentangling Module (SDM) and a Distribution Normalization Module (DNM). SDM combines the spatial self-attention mechanism and a new Semantic Disentangling Loss (SDL) to help the generator distill key semantic information for the image generation. DNM uses a Variational Auto-Encoder (VAE) to normalize and denoise the image latent distribution, which can help the discriminator better distinguish synthesized images from real images. DNM also adopts a Distribution Adversarial Loss (DAL) to guide the generator to align with normalized real image distributions in the latent space. Extensive experiments on two public datasets demonstrated that our DR-GAN achieved a competitive performance in the Text-to-Image task.
Bi-directional Object-context Prioritization Learning for Saliency Ranking
Mar 22, 2022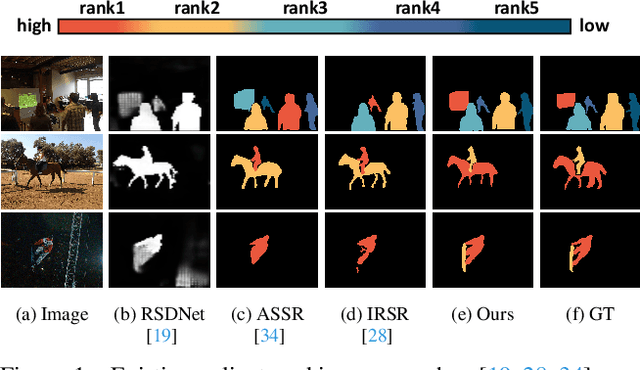
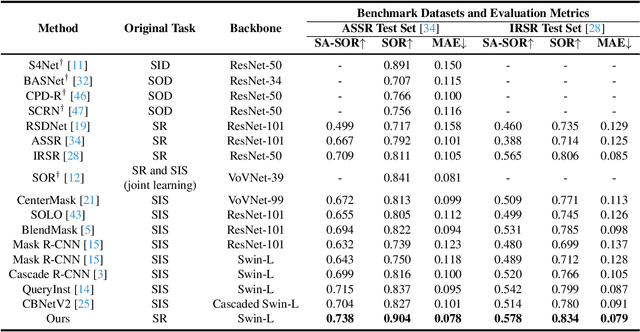

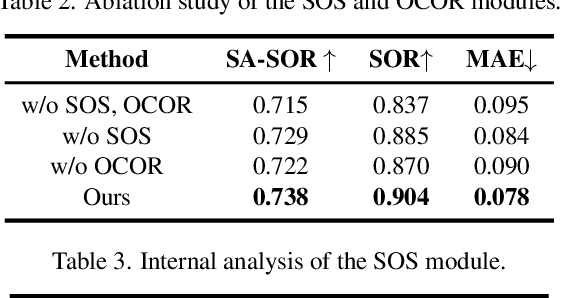
The saliency ranking task is recently proposed to study the visual behavior that humans would typically shift their attention over different objects of a scene based on their degrees of saliency. Existing approaches focus on learning either object-object or object-scene relations. Such a strategy follows the idea of object-based attention in Psychology, but it tends to favor those objects with strong semantics (e.g., humans), resulting in unrealistic saliency ranking. We observe that spatial attention works concurrently with object-based attention in the human visual recognition system. During the recognition process, the human spatial attention mechanism would move, engage, and disengage from region to region (i.e., context to context). This inspires us to model the region-level interactions, in addition to the object-level reasoning, for saliency ranking. To this end, we propose a novel bi-directional method to unify spatial attention and object-based attention for saliency ranking. Our model includes two novel modules: (1) a selective object saliency (SOS) module that models objectbased attention via inferring the semantic representation of the salient object, and (2) an object-context-object relation (OCOR) module that allocates saliency ranks to objects by jointly modeling the object-context and context-object interactions of the salient objects. Extensive experiments show that our approach outperforms existing state-of-theart methods. Our code and pretrained model are available at https://github.com/GrassBro/OCOR.
Improving Spectral Graph Convolution for Learning Graph-level Representation
Dec 14, 2021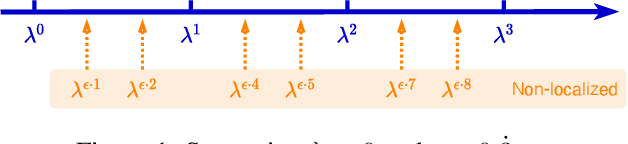
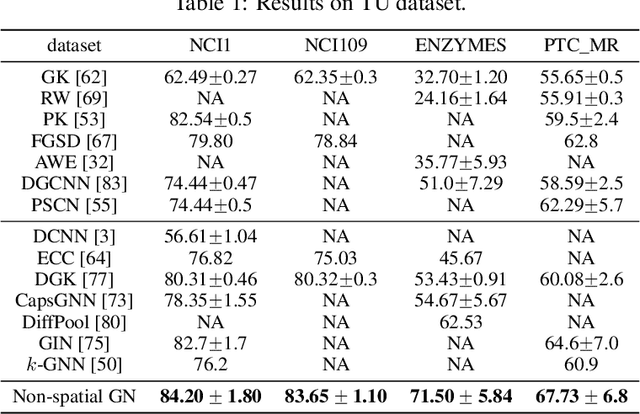
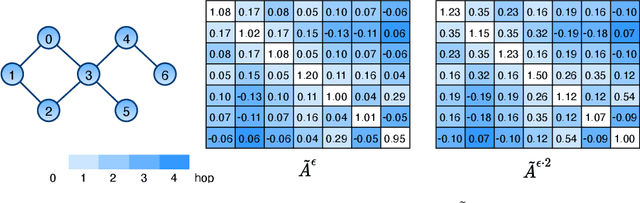
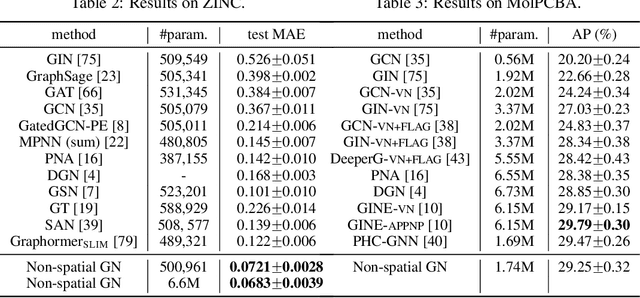
From the original theoretically well-defined spectral graph convolution to the subsequent spatial bassed message-passing model, spatial locality (in vertex domain) acts as a fundamental principle of most graph neural networks (GNNs). In the spectral graph convolution, the filter is approximated by polynomials, where a $k$-order polynomial covers $k$-hop neighbors. In the message-passing, various definitions of neighbors used in aggregations are actually an extensive exploration of the spatial locality information. For learning node representations, the topological distance seems necessary since it characterizes the basic relations between nodes. However, for learning representations of the entire graphs, is it still necessary to hold? In this work, we show that such a principle is not necessary, it hinders most existing GNNs from efficiently encoding graph structures. By removing it, as well as the limitation of polynomial filters, the resulting new architecture significantly boosts performance on learning graph representations. We also study the effects of graph spectrum on signals and interpret various existing improvements as different spectrum smoothing techniques. It serves as a spatial understanding that quantitatively measures the effects of the spectrum to input signals in comparison to the well-known spectral understanding as high/low-pass filters. More importantly, it sheds the light on developing powerful graph representation models.
Learning to Detect Instance-level Salient Objects Using Complementary Image Labels
Nov 19, 2021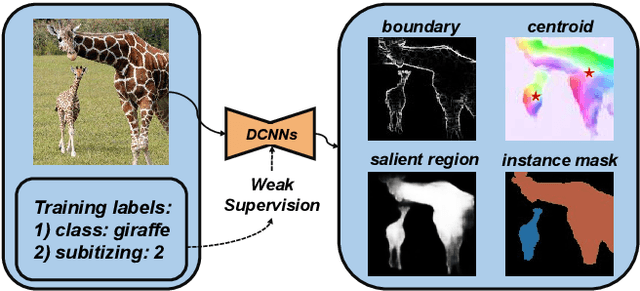
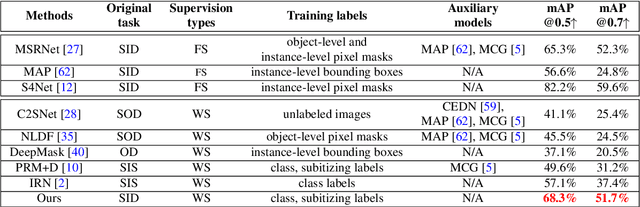
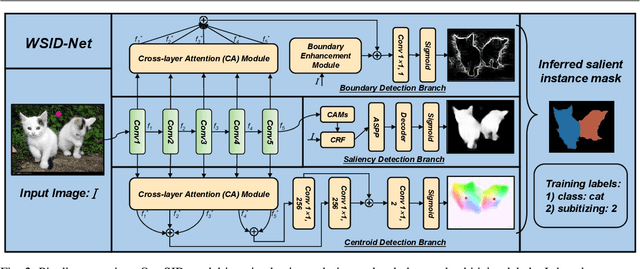
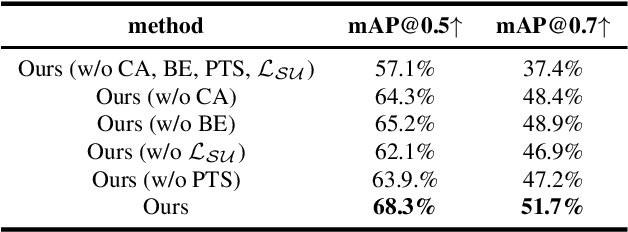
Existing salient instance detection (SID) methods typically learn from pixel-level annotated datasets. In this paper, we present the first weakly-supervised approach to the SID problem. Although weak supervision has been considered in general saliency detection, it is mainly based on using class labels for object localization. However, it is non-trivial to use only class labels to learn instance-aware saliency information, as salient instances with high semantic affinities may not be easily separated by the labels. As the subitizing information provides an instant judgement on the number of salient items, it is naturally related to detecting salient instances and may help separate instances of the same class while grouping different parts of the same instance. Inspired by this observation, we propose to use class and subitizing labels as weak supervision for the SID problem. We propose a novel weakly-supervised network with three branches: a Saliency Detection Branch leveraging class consistency information to locate candidate objects; a Boundary Detection Branch exploiting class discrepancy information to delineate object boundaries; and a Centroid Detection Branch using subitizing information to detect salient instance centroids. This complementary information is then fused to produce a salient instance map. To facilitate the learning process, we further propose a progressive training scheme to reduce label noise and the corresponding noise learned by the model, via reciprocating the model with progressive salient instance prediction and model refreshing. Our extensive evaluations show that the proposed method plays favorably against carefully designed baseline methods adapted from related tasks.
Temporal Knowledge Graph Reasoning Triggered by Memories
Nov 03, 2021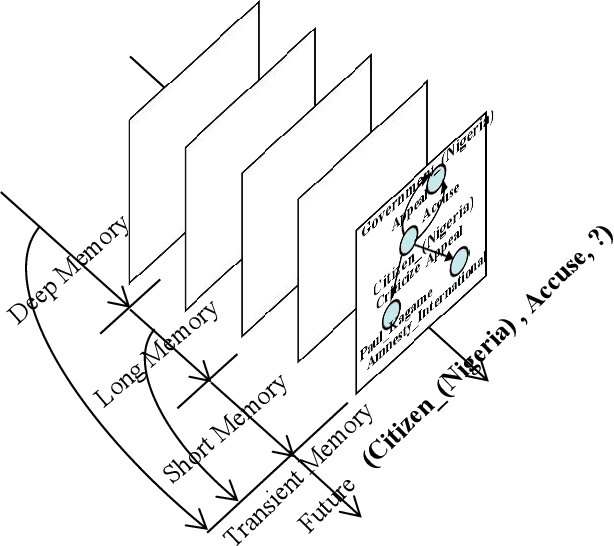
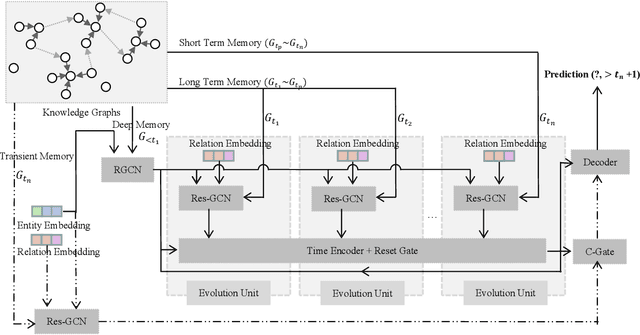
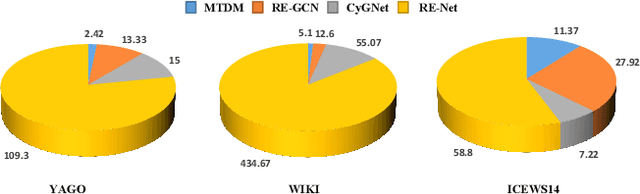
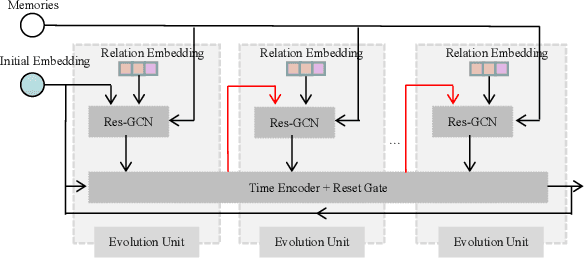
Inferring missing facts in temporal knowledge graphs is a critical task and has been widely explored. Extrapolation in temporal reasoning tasks is more challenging and gradually attracts the attention of researchers since no direct history facts for prediction. Previous works attempted to apply evolutionary representation learning to solve the extrapolation problem. However, these techniques do not explicitly leverage various time-aware attribute representations, i.e. the reasoning performance is significantly affected by the history length. To alleviate the time dependence when reasoning future missing facts, we propose a memory-triggered decision-making (MTDM) network, which incorporates transient memories, long-short-term memories, and deep memories. Specifically, the transient learning network considers transient memories as a static knowledge graph, and the time-aware recurrent evolution network learns representations through a sequence of recurrent evolution units from long-short-term memories. Each evolution unit consists of a structural encoder to aggregate edge information, a time encoder with a gating unit to update attribute representations of entities. MTDM utilizes the crafted residual multi-relational aggregator as the structural encoder to solve the multi-hop coverage problem. We also introduce the dissolution learning constraint for better understanding the event dissolution process. Extensive experiments demonstrate the MTDM alleviates the history dependence and achieves state-of-the-art prediction performance. Moreover, compared with the most advanced baseline, MTDM shows a faster convergence speed and training speed.
Object Tracking by Jointly Exploiting Frame and Event Domain
Sep 19, 2021
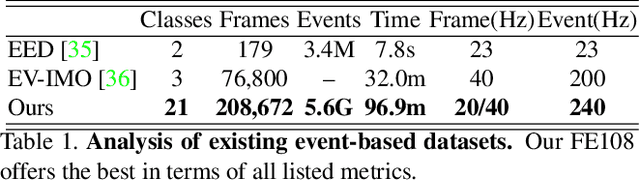
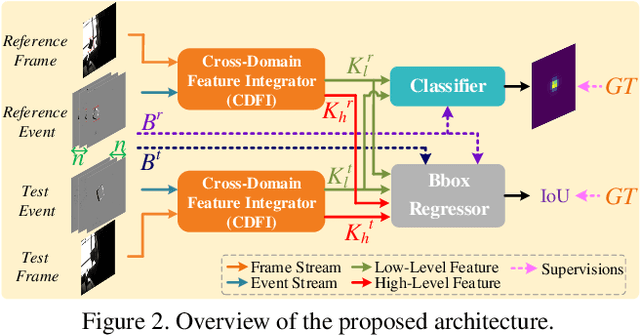
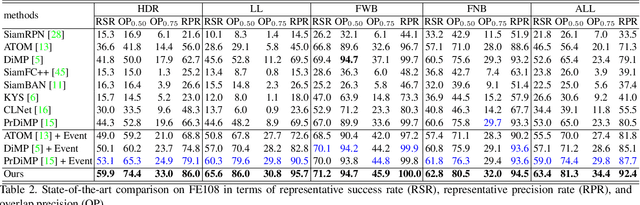
Inspired by the complementarity between conventional frame-based and bio-inspired event-based cameras, we propose a multi-modal based approach to fuse visual cues from the frame- and event-domain to enhance the single object tracking performance, especially in degraded conditions (e.g., scenes with high dynamic range, low light, and fast-motion objects). The proposed approach can effectively and adaptively combine meaningful information from both domains. Our approach's effectiveness is enforced by a novel designed cross-domain attention schemes, which can effectively enhance features based on self- and cross-domain attention schemes; The adaptiveness is guarded by a specially designed weighting scheme, which can adaptively balance the contribution of the two domains. To exploit event-based visual cues in single-object tracking, we construct a large-scale frame-event-based dataset, which we subsequently employ to train a novel frame-event fusion based model. Extensive experiments show that the proposed approach outperforms state-of-the-art frame-based tracking methods by at least 10.4% and 11.9% in terms of representative success rate and precision rate, respectively. Besides, the effectiveness of each key component of our approach is evidenced by our thorough ablation study.