 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deterministic Approach to Avoid Saddle Points
Jan 21, 2019
Loss functions with a large number of saddle points are one of the main obstacles to training many modern machine learning models. Gradient descent (GD) is a fundamental algorithm for machine learning and converges to a saddle point for certain initial data. We call the region formed by these initial values the "attraction region." For quadratic functions, GD converges to a saddle point if the initial data is in a subspace of up to n-1 dimensions. In this paper, we prove that a small modification of the recently proposed Laplacian smoothing gradient descent (LSGD) [Osher, et al., arXiv:1806.06317] contributes to avoiding saddle points without sacrificing the convergence rate of GD. In particular, we show that the dimension of the LSGD's attraction region is at most floor((n-1)/2) for a class of quadratic functions which is significantly smaller than GD's (n-1)-dimensional attraction region.
EnResNet: ResNet Ensemble via the Feynman-Kac Formalism
Nov 26, 2018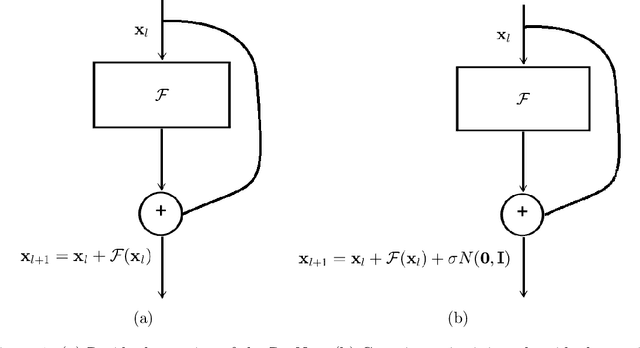

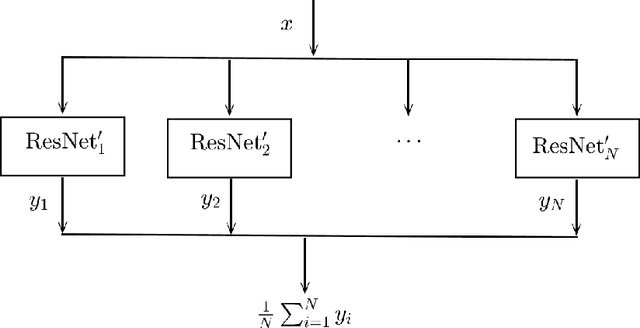
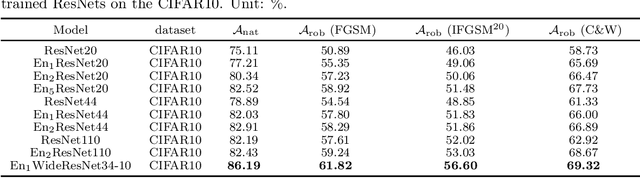
We propose a simple yet powerful ResNet ensemble algorithm which consists of two components: First, we modify the base ResNet by adding variance specified Gaussian noise to the output of each original residual mapping. Second, we average over the production of multiple parallel and jointly trained modified ResNets to get the final prediction. Heuristically, these two simple steps give an approximation to the well-known Feynman-Kac formula for representing the solution of a transport equation with viscosity, or a convection-diffusion equation. This simple ensemble algorithm improves neural nets' generalizability and robustness towards adversarial attack. In particular, for the CIFAR10 benchmark, with the projected gradient descent adversarial training, we show that even an ensemble of two ResNet20 leads to a 5$\%$ higher accuracy towards the strongest iterative fast gradient sign attack than the state-of-the-art adversarial defense algorithm.
Mathematical Analysis of Adversarial Attacks
Nov 25, 2018
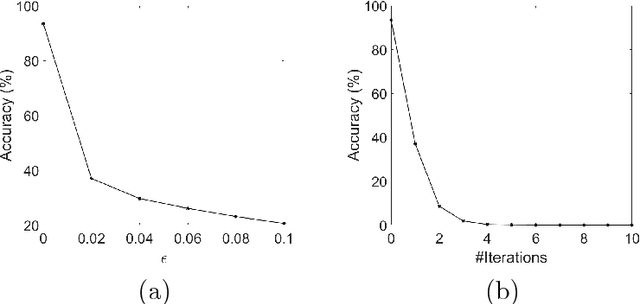
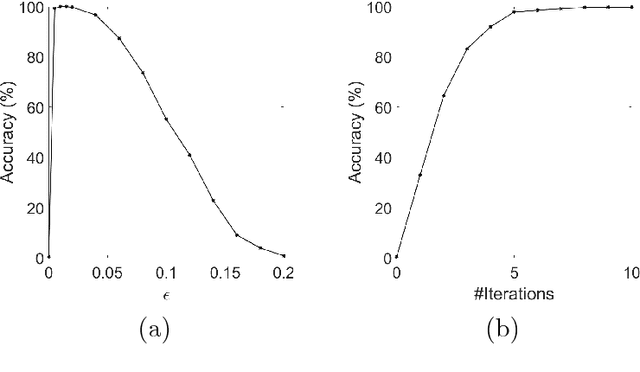
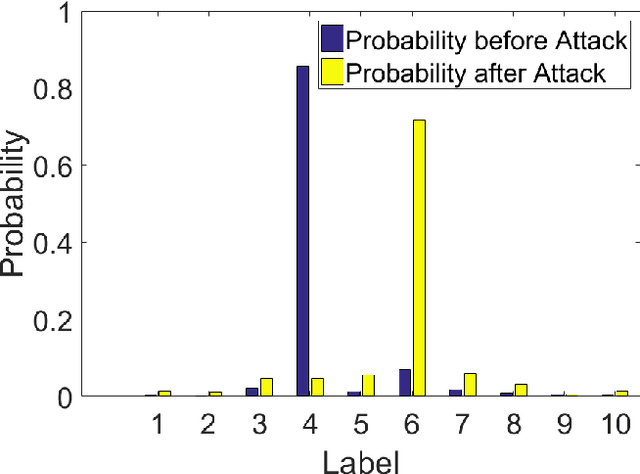
In this paper, we analyze efficacy of the fast gradient sign method (FGSM) and the Carlini-Wagner's L2 (CW-L2) attack. We prove that, within a certain regime, the untargeted FGSM can fool any convolutional neural nets (CNNs) with ReLU activation; the targeted FGSM can mislead any CNNs with ReLU activation to classify any given image into any prescribed class. For a special two-layer neural network: a linear layer followed by the softmax output activation, we show that the CW-L2 attack increases the ratio of the classification probability between the target and ground truth classes. Moreover, we provide numerical results to verify all our theoretical results.
Laplacian Smoothing Gradient Descent
Oct 17, 2018
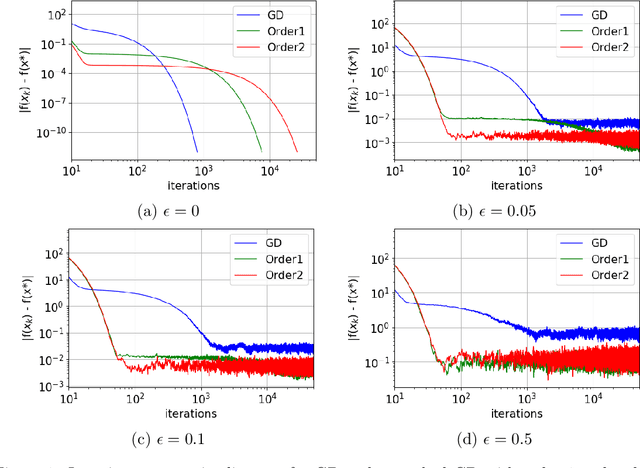

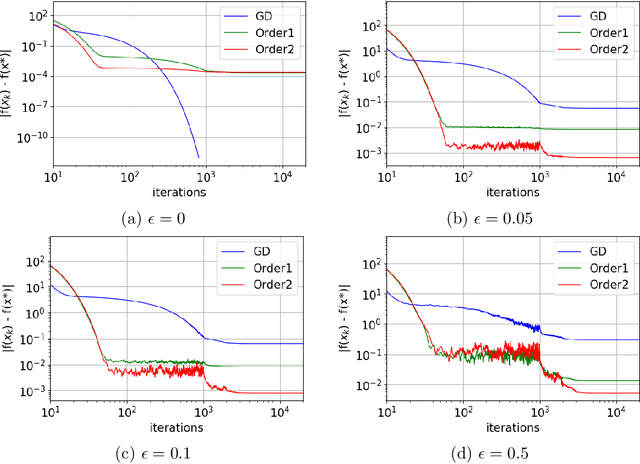
We propose a very simple modification of gradient descent and stochastic gradient descent. We show that when applied to a variety of machine learning models including softmax regression, convolutional neural nets, generative adversarial nets, and deep reinforcement learning, this very simple surrogate can dramatically reduce the variance and improve the accuracy of the generalization. The new algorithm, (which depends on one nonnegative parameter) when applied to non-convex minimization, tends to avoid sharp local minima. Instead it seeks somewhat flatter local (and often global) minima. The method only involves preconditioning the gradient by the inverse of a tri-diagonal matrix that is positive definite. The motivation comes from the theory of Hamilton-Jacobi partial differential equations. This theory demonstrates that the new algorithm is almost the same as doing gradient descent on a new function which (a) has the same global minima as the original function and (b) is "more convex". Again, the programming effort in doing this is minimal, in cost, complexity and effort. We implement our algorithm into both PyTorch and Tensorflow platforms, which will be made publicly available.
Adversarial Defense via Data Dependent Activation Function and Total Variation Minimization
Sep 23, 2018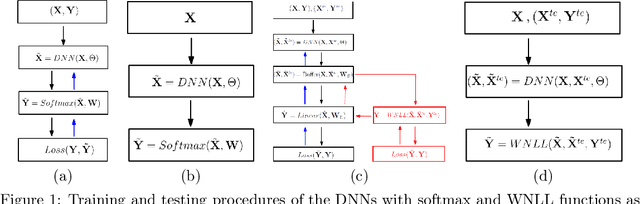
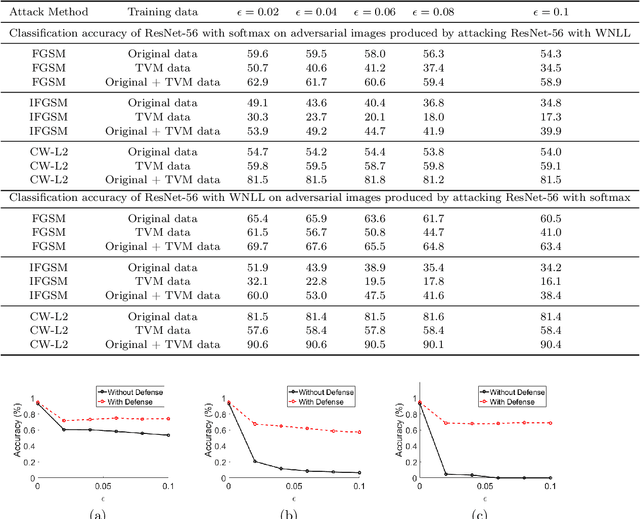

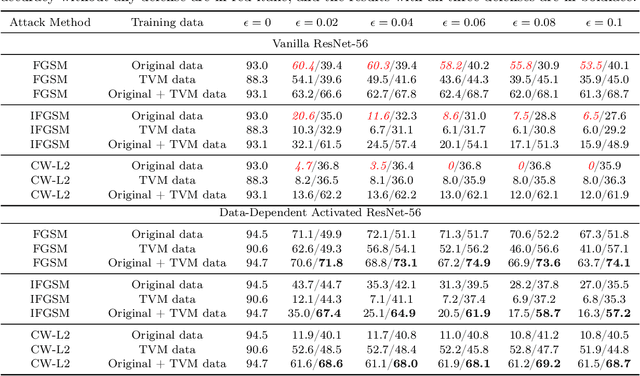
We improve the robustness of deep neural nets to adversarial attacks by using an interpolating function as the output activation. This data-dependent activation function remarkably improves both classification accuracy and stability to adversarial perturbations. Together with the total variation minimization of adversarial images and augmented training, under the strongest attack, we achieve up to 20.6$\%$, 50.7$\%$, and 68.7$\%$ accuracy improvement w.r.t. the fast gradient sign method, iterative fast gradient sign method, and Carlini-Wagner $L_2$ attacks, respectively. Our defense strategy is additive to many of the existing methods. We give an intuitive explanation of our defense strategy via analyzing the geometry of the feature space. For reproducibility, the code is made available at: https://github.com/BaoWangMath/DNN-DataDependentActivation.
Stop memorizing: A data-dependent regularization framework for intrinsic pattern learning
Sep 23, 2018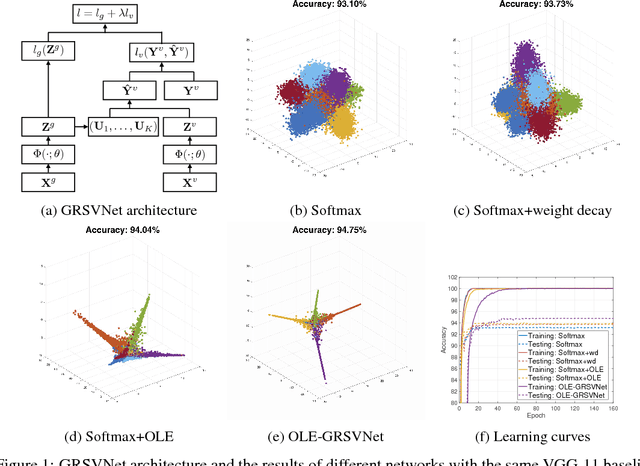

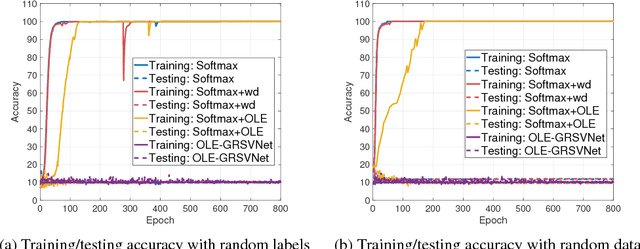
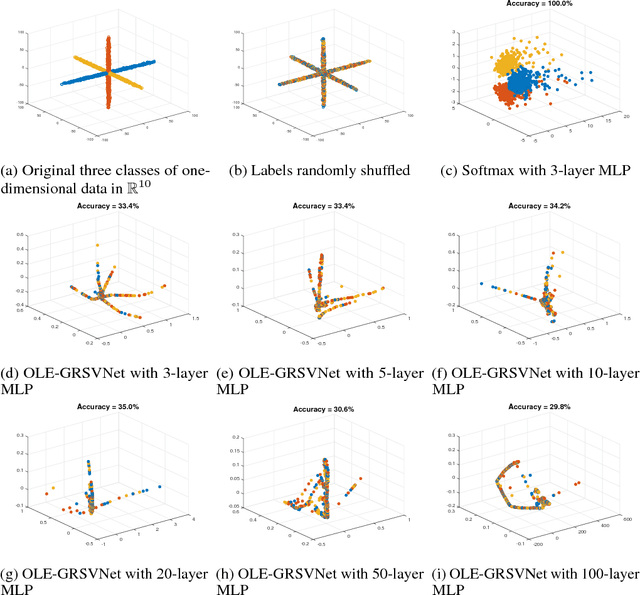
Deep neural networks (DNNs) typically have enough capacity to fit random data by brute force even when conventional data-dependent regularizations focusing on the geometry of the features are imposed. We find out that the reason for this is the inconsistency between the enforced geometry and the standard softmax cross entropy loss. To resolve this, we propose a new framework for data-dependent DNN regularization, the Geometrically-Regularized-Self-Validating neural Networks (GRSVNet). During training, the geometry enforced on one batch of features is simultaneously validated on a separate batch using a validation loss consistent with the geometry. We study a particular case of GRSVNet, the Orthogonal-Low-rank Embedding (OLE)-GRSVNet, which is capable of producing highly discriminative features residing in orthogonal low-rank subspaces. Numerical experiments show that OLE-GRSVNet outperforms DNNs with conventional regularization when trained on real data. More importantly, unlike conventional DNNs, OLE-GRSVNet refuses to memorize random data or random labels, suggesting it only learns intrinsic patterns by reducing the memorizing capacity of the baseline DNN.
Deep Neural Nets with Interpolating Function as Output Activation
Jun 17, 2018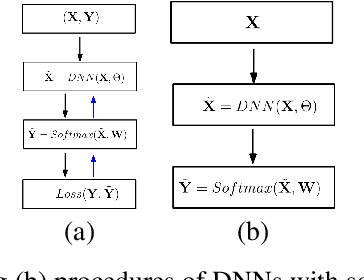
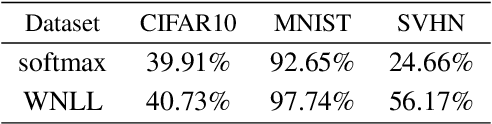
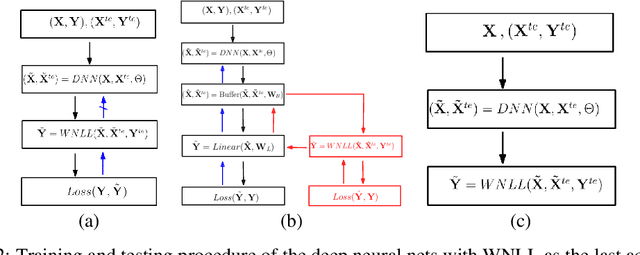
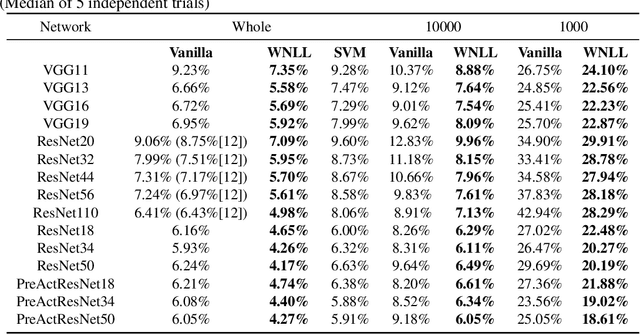
We replace the output layer of deep neural nets, typically the softmax function, by a novel interpolating function. And we propose end-to-end training and testing algorithms for this new architecture. Compared to classical neural nets with softmax function as output activation, the surrogate with interpolating function as output activation combines advantages of both deep and manifold learning. The new framework demonstrates the following major advantages: First, it is better applicable to the case with insufficient training data. Second, it significantly improves the generalization accuracy on a wide variety of networks. The algorithm is implemented in PyTorch, and code will be made publicly available.
Graph-Based Deep Modeling and Real Time Forecasting of Sparse Spatio-Temporal Data
Apr 02, 2018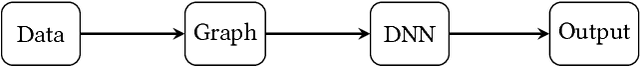
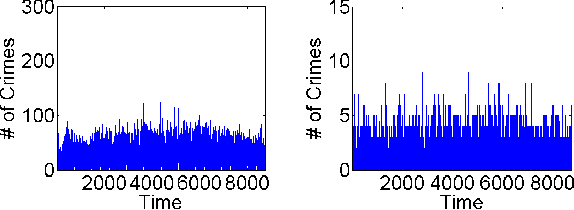
We present a generic framework for spatio-temporal (ST) data modeling, analysis, and forecasting, with a special focus on data that is sparse in both space and time. Our multi-scaled framework is a seamless coupling of two major components: a self-exciting point process that models the macroscale statistical behaviors of the ST data and a graph structured recurrent neural network (GSRNN) to discover the microscale patterns of the ST data on the inferred graph. This novel deep neural network (DNN) incorporates the real time interactions of the graph nodes to enable more accurate real time forecasting. The effectiveness of our method is demonstrated on both crime and traffic forecasting.
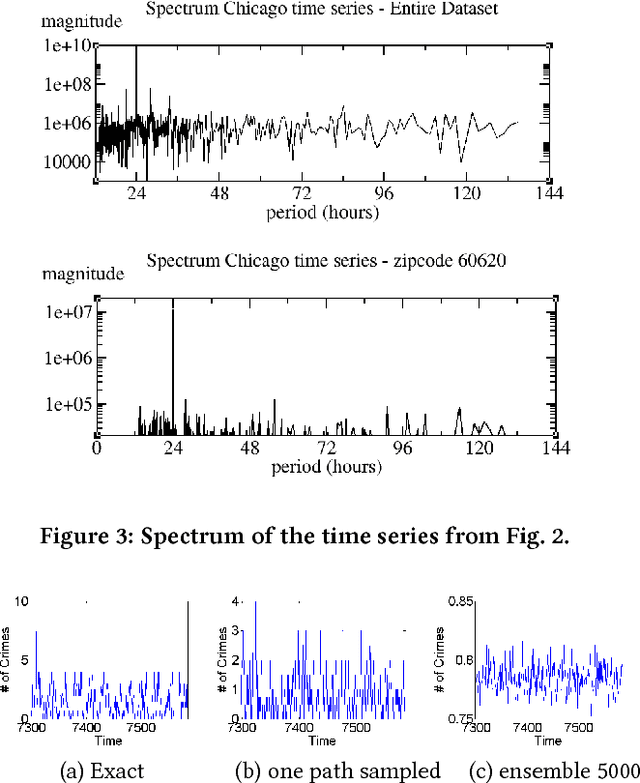
Deep Learning for Real-Time Crime Forecasting and its Ternarization
Nov 23, 2017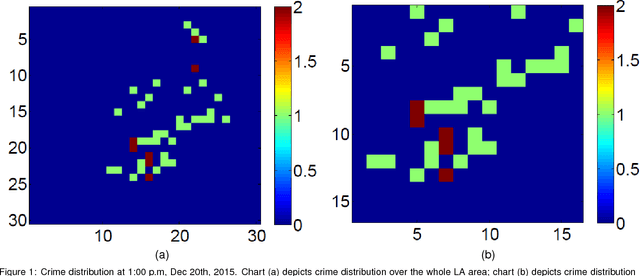
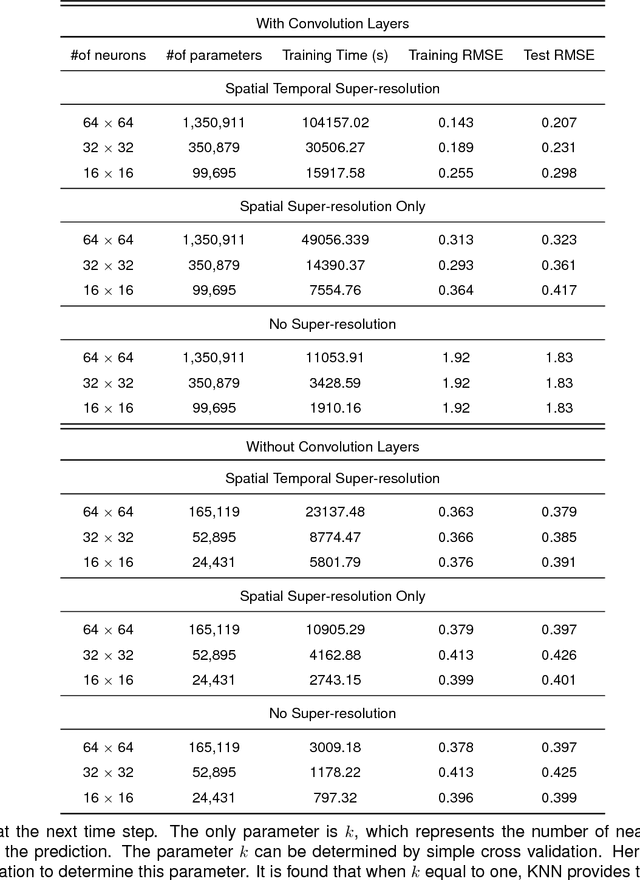
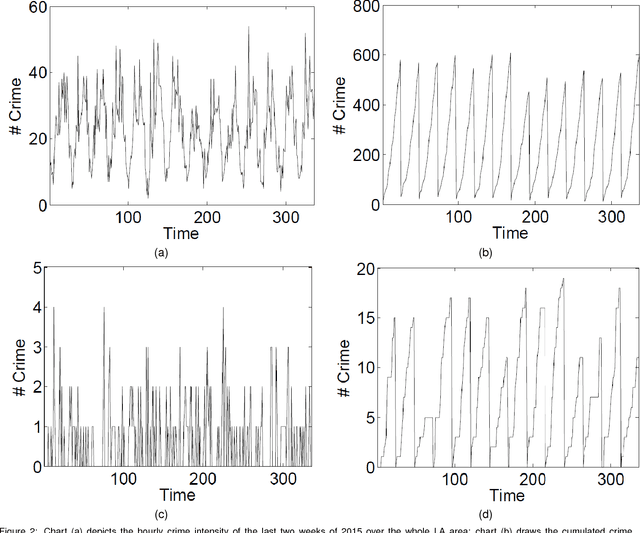
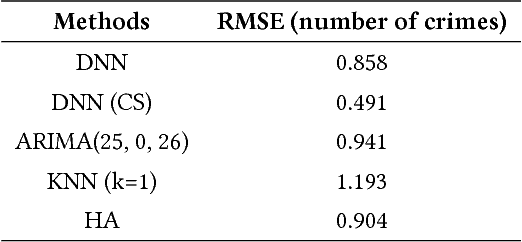
Real-time crime forecasting is important. However, accurate prediction of when and where the next crime will happen is difficult. No known physical model provides a reasonable approximation to such a complex system. Historical crime data are sparse in both space and time and the signal of interests is weak. In this work, we first present a proper representation of crime data. We then adapt the spatial temporal residual network on the well represented data to predict the distribution of crime in Los Angeles at the scale of hours in neighborhood-sized parcels. These experiments as well as comparisons with several existing approaches to prediction demonstrate the superiority of the proposed model in terms of accuracy. Finally, we present a ternarization technique to address the resource consumption issue for its deployment in real world. This work is an extension of our short conference proceeding paper [Wang et al, Arxiv 1707.03340].
Deep Learning for Real Time Crime Forecasting
Jul 09, 2017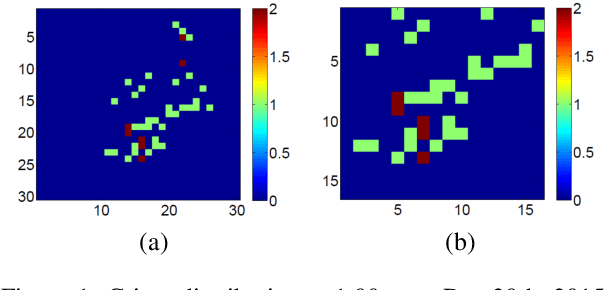
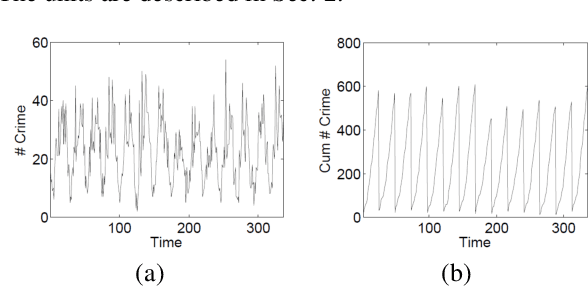
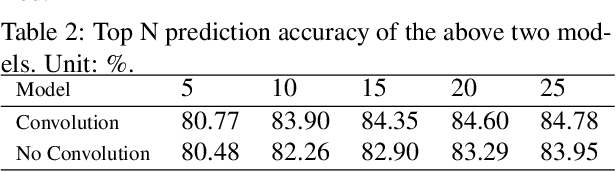
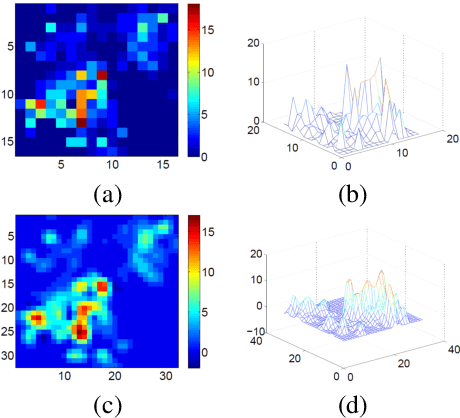
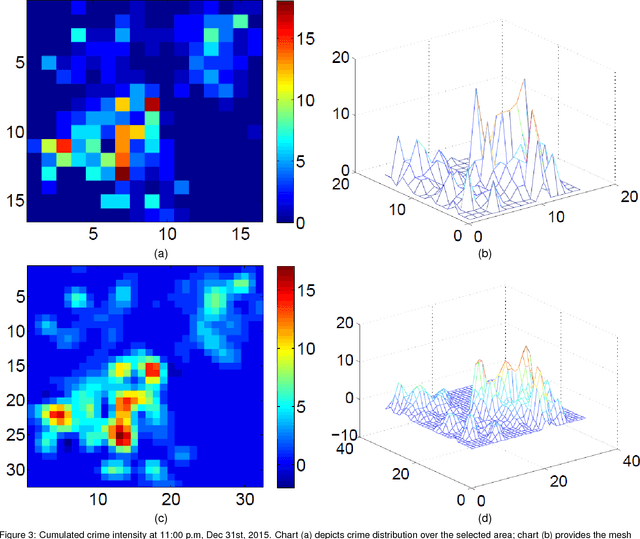
Accurate real time crime prediction is a fundamental issue for public safety, but remains a challenging problem for the scientific community. Crime occurrences depend on many complex factors. Compared to many predictable events, crime is sparse. At different spatio-temporal scales, crime distributions display dramatically different patterns. These distributions are of very low regularity in both space and time. In this work, we adapt the state-of-the-art deep learning spatio-temporal predictor, ST-ResNet [Zhang et al, AAAI, 2017], to collectively predict crime distribution over the Los Angeles area. Our models are two staged. First, we preprocess the raw crime data. This includes regularization in both space and time to enhance predictable signals. Second, we adapt hierarchical structures of residual convolutional units to train multi-factor crime prediction models. Experiments over a half year period in Los Angeles reveal highly accurate predictive power of our models.