 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidedBridge: Training-freely Improving Bridge Models with Prior Guidance
Jun 02, 2026Guidance methods, such as classifier-free guidance (CFG) and auto-guidance (AG), have advanced noise-to-data generation in diffusion models. Recently, bridge models have introduced a data-to-data generative process that can exploit an instructive clean prior. In this work, inspired by previous methods creating quality difference between denoising results as guidance, we propose a training-free bridge guidance method, termed Prior Guidance (PG). Specifically, we introduce a weak prior, which is unseen during bridge pre-training, hindering prior exploitation and thereby degrading denoising result. Then, we contrast it with the seen prior to highlight and enhance prior exploitation via a scaling factor. Moreover, we analyze the underlying mechanism of prior exploitation in the bridge process and design frequency-modulated prior guidance (FMPG), which tailors the guidance scale to low- and high-frequency bands coherent with bridge generative dynamics. To address prior exploitation in image in-painting, we develop a cascaded framework, CFG-FMPG, which first generates a noisy hidden representation via CFG and then exploits it as a generative prior with FMPG, fulfilling their complementary strengths without compromising inference efficiency. Experiments demonstrate that our PG methods consistently improve pre-trained bridge models across diverse image translation tasks.
EnResNet: ResNet Ensemble via the Feynman-Kac Formalism
Nov 26, 2018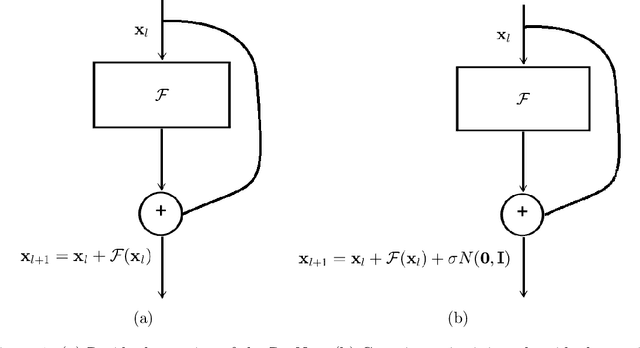

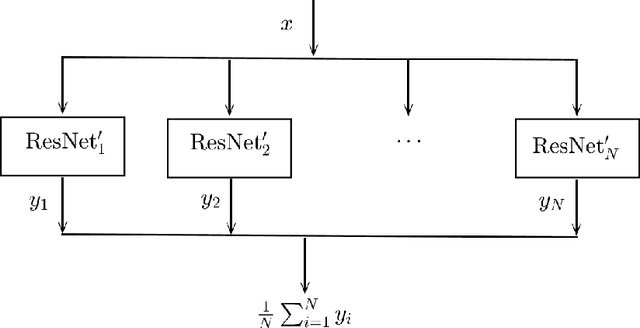
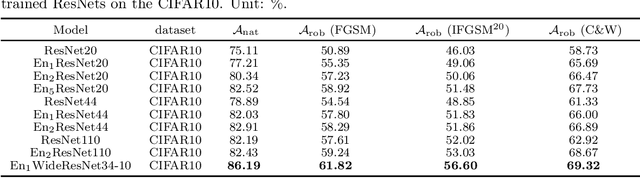
We propose a simple yet powerful ResNet ensemble algorithm which consists of two components: First, we modify the base ResNet by adding variance specified Gaussian noise to the output of each original residual mapping. Second, we average over the production of multiple parallel and jointly trained modified ResNets to get the final prediction. Heuristically, these two simple steps give an approximation to the well-known Feynman-Kac formula for representing the solution of a transport equation with viscosity, or a convection-diffusion equation. This simple ensemble algorithm improves neural nets' generalizability and robustness towards adversarial attack. In particular, for the CIFAR10 benchmark, with the projected gradient descent adversarial training, we show that even an ensemble of two ResNet20 leads to a 5$\%$ higher accuracy towards the strongest iterative fast gradient sign attack than the state-of-the-art adversarial defense algorithm.