 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Gradient Descent with Nonlinear Conjugate Gradient-Style Adaptive Momentum
Dec 03, 2020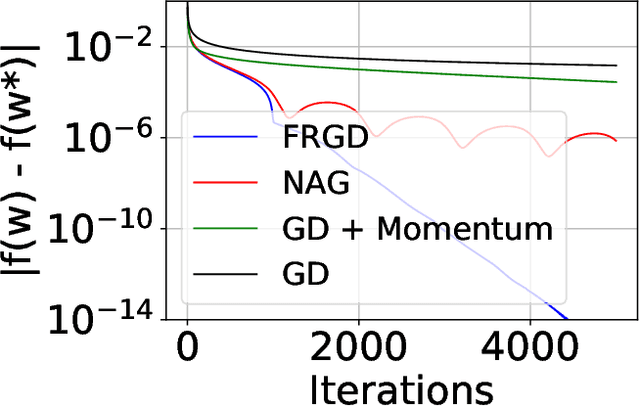
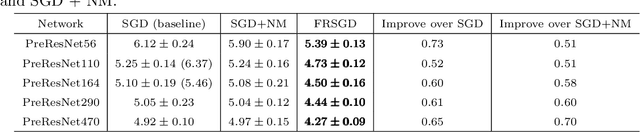
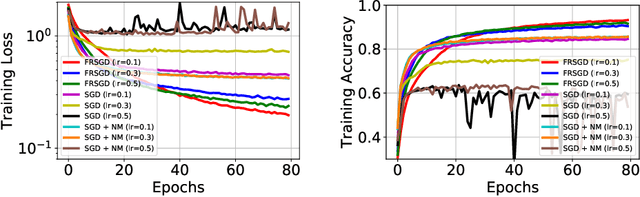
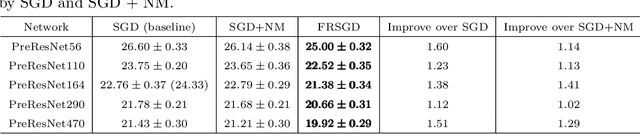
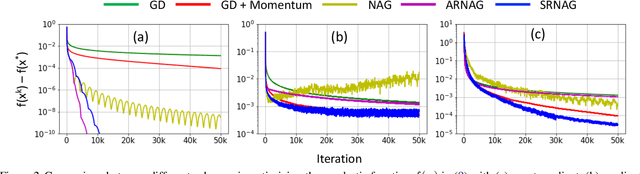
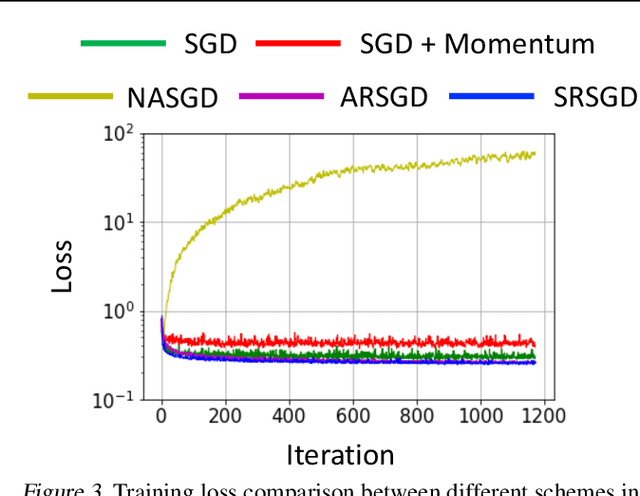
Momentum plays a crucial role in stochastic gradient-based optimization algorithms for accelerating or improving training deep neural networks (DNNs). In deep learning practice, the momentum is usually weighted by a well-calibrated constant. However, tuning hyperparameters for momentum can be a significant computational burden. In this paper, we propose a novel \emph{adaptive momentum} for improving DNNs training; this adaptive momentum, with no momentum related hyperparameter required, is motivated by the nonlinear conjugate gradient (NCG) method. Stochastic gradient descent (SGD) with this new adaptive momentum eliminates the need for the momentum hyperparameter calibration, allows a significantly larger learning rate, accelerates DNN training, and improves final accuracy and robustness of the trained DNNs. For instance, SGD with this adaptive momentum reduces classification errors for training ResNet110 for CIFAR10 and CIFAR100 from $5.25\%$ to $4.64\%$ and $23.75\%$ to $20.03\%$, respectively. Furthermore, SGD with the new adaptive momentum also benefits adversarial training and improves adversarial robustness of the trained DNNs.
An Integrated Approach to Produce Robust Models with High Efficiency
Aug 31, 2020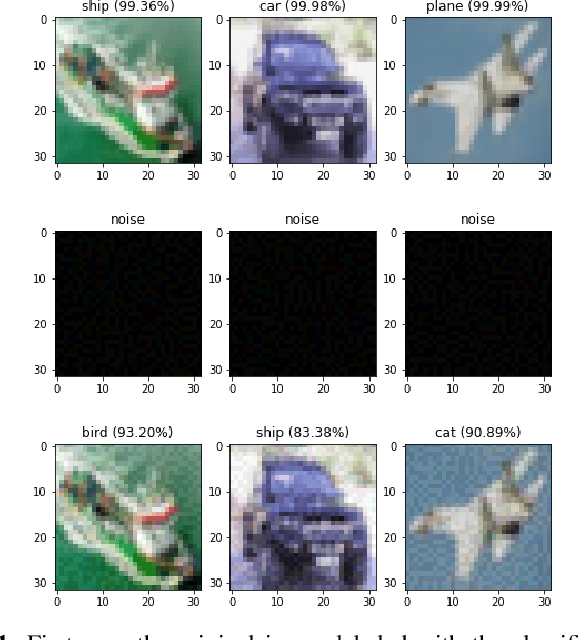
Deep Neural Networks (DNNs) needs to be both efficient and robust for practical uses. Quantization and structure simplification are promising ways to adapt DNNs to mobile devices, and adversarial training is the most popular method to make DNNs robust. In this work, we try to obtain both features by applying a convergent relaxation quantization algorithm, Binary-Relax (BR), to a robust adversarial-trained model, ResNets Ensemble via Feynman-Kac Formalism (EnResNet). We also discover that high precision, such as ternary (tnn) and 4-bit, quantization will produce sparse DNNs. However, this sparsity is unstructured under advarsarial training. To solve the problems that adversarial training jeopardizes DNNs' accuracy on clean images and the struture of sparsity, we design a trade-off loss function that helps DNNs preserve their natural accuracy and improve the channel sparsity. With our trade-off loss function, we achieve both goals with no reduction of resistance under weak attacks and very minor reduction of resistance under strong attcks. Together with quantized EnResNet with trade-off loss function, we provide robust models that have high efficiency.
MomentumRNN: Integrating Momentum into Recurrent Neural Networks
Jun 12, 2020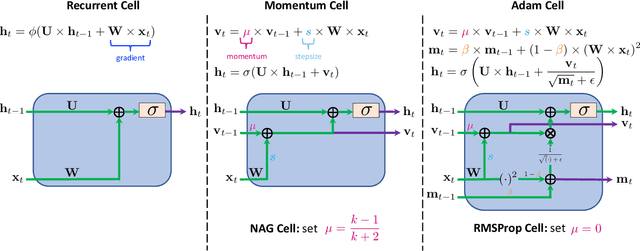
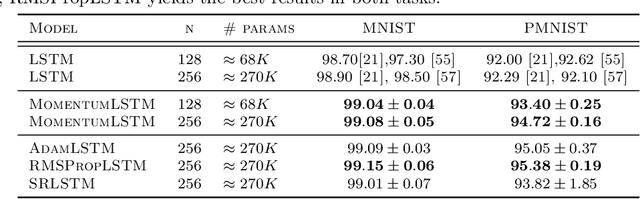
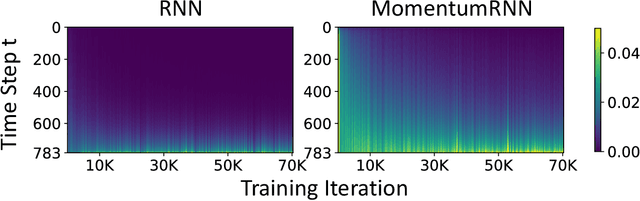
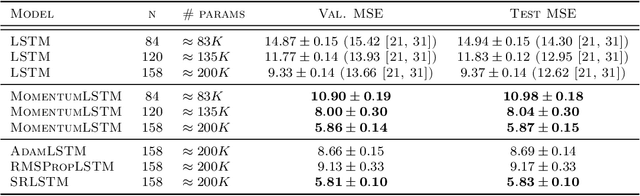
Designing deep neural networks is an art that often involves an expensive search over candidate architectures. To overcome this for recurrent neural nets (RNNs), we establish a connection between the hidden state dynamics in an RNN and gradient descent (GD). We then integrate momentum into this framework and propose a new family of RNNs, called {\em MomentumRNNs}. We theoretically prove and numerically demonstrate that MomentumRNNs alleviate the vanishing gradient issue in training RNNs. We study the momentum long-short term memory (MomentumLSTM) and verify its advantages in convergence speed and accuracy over its LSTM counterpart across a variety of benchmarks, with little compromise in computational or memory efficiency. We also demonstrate that MomentumRNN is applicable to many types of recurrent cells, including those in the state-of-the-art orthogonal RNNs. Finally, we show that other advanced momentum-based optimization methods, such as Adam and Nesterov accelerated gradients with a restart, can be easily incorporated into the MomentumRNN framework for designing new recurrent cells with even better performance. The code is available at \url{https://github.com/minhtannguyen/MomentumRNN}.
Exploring Private Federated Learning with Laplacian Smoothing
May 01, 2020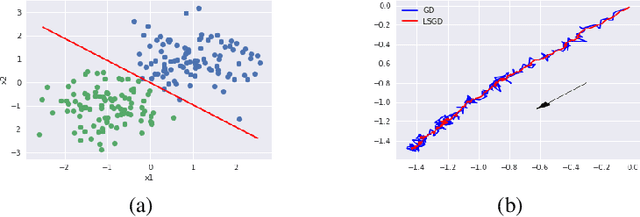
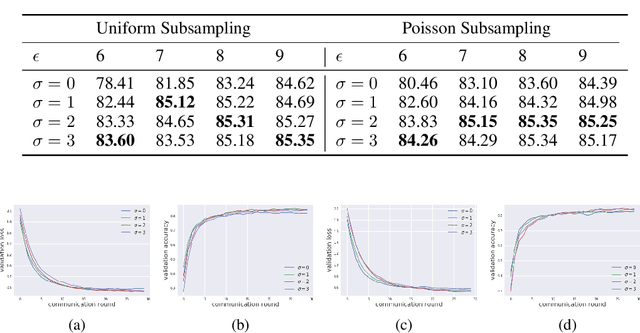
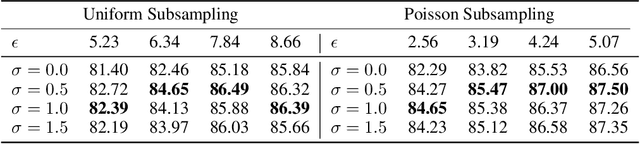
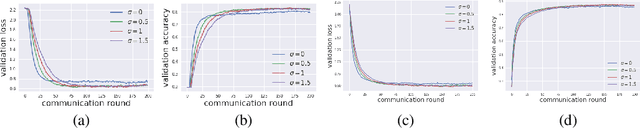
Federated learning aims to protect data privacy by collaboratively learning a model without sharing private data among users. However, an adversary may still be able to infer the private training data by attacking the released model. Differential privacy(DP) provides a statistical guarantee against such attacks, at a privacy of possibly degenerating the accuracy or utility of the trained models. In this paper, we apply a utility enhancement scheme based on Laplacian smoothing for differentially-private federated learning (DP-Fed-LS), where the parameter aggregation with injected Gaussian noise is improved in statistical precision. We provide tight closed-form privacy bounds for both uniform and Poisson subsampling and derive corresponding DP guarantees for differential private federated learning, with or without Laplacian smoothing. Experiments over MNIST, SVHN and Shakespeare datasets show that the proposed method can improve model accuracy with DP-guarantee under both subsampling mechanisms.
Sparsity Meets Robustness: Channel Pruning for the Feynman-Kac Formalism Principled Robust Deep Neural Nets
Mar 02, 2020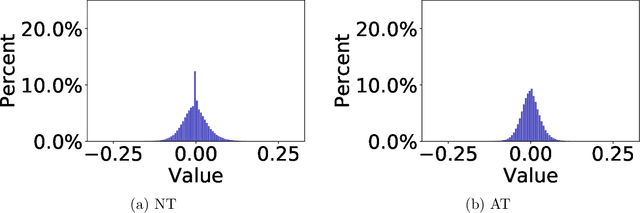
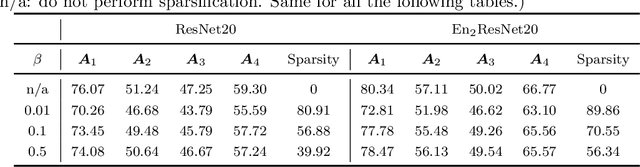
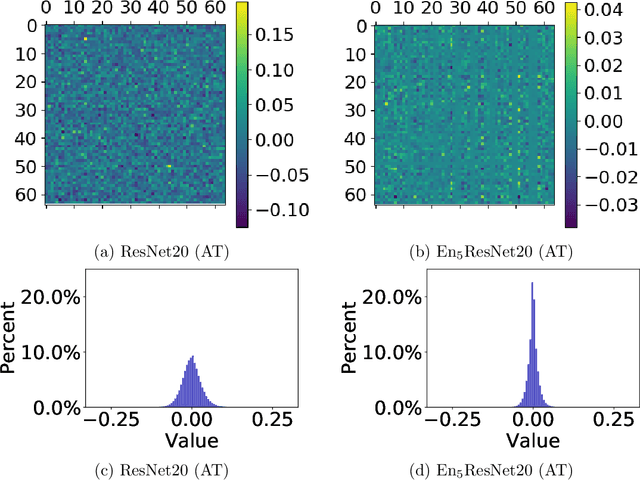
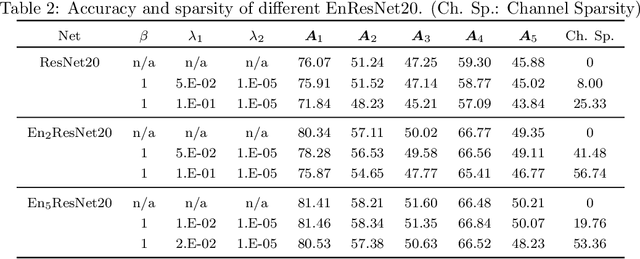
Deep neural nets (DNNs) compression is crucial for adaptation to mobile devices. Though many successful algorithms exist to compress naturally trained DNNs, developing efficient and stable compression algorithms for robustly trained DNNs remains widely open. In this paper, we focus on a co-design of efficient DNN compression algorithms and sparse neural architectures for robust and accurate deep learning. Such a co-design enables us to advance the goal of accommodating both sparsity and robustness. With this objective in mind, we leverage the relaxed augmented Lagrangian based algorithms to prune the weights of adversarially trained DNNs, at both structured and unstructured levels. Using a Feynman-Kac formalism principled robust and sparse DNNs, we can at least double the channel sparsity of the adversarially trained ResNet20 for CIFAR10 classification, meanwhile, improve the natural accuracy by $8.69$\% and the robust accuracy under the benchmark $20$ iterations of IFGSM attack by $5.42$\%. The code is available at \url{https://github.com/BaoWangMath/rvsm-rgsm-admm}.
Scheduled Restart Momentum for Accelerated Stochastic Gradient Descent
Feb 24, 2020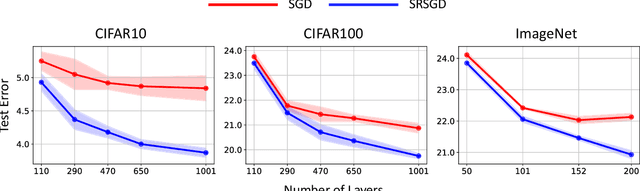

Stochastic gradient descent (SGD) with constant momentum and its variants such as Adam are the optimization algorithms of choice for training deep neural networks (DNNs). Since DNN training is incredibly computationally expensive, there is great interest in speeding up convergence. Nesterov accelerated gradient (NAG) improves the convergence rate of gradient descent (GD) for convex optimization using a specially designed momentum; however, it accumulates error when an inexact gradient is used (such as in SGD), slowing convergence at best and diverging at worst. In this paper, we propose Scheduled Restart SGD (SRSGD), a new NAG-style scheme for training DNNs. SRSGD replaces the constant momentum in SGD by the increasing momentum in NAG but stabilizes the iterations by resetting the momentum to zero according to a schedule. Using a variety of models and benchmarks for image classification, we demonstrate that, in training DNNs, SRSGD significantly improves convergence and generalization; for instance in training ResNet200 for ImageNet classification, SRSGD achieves an error rate of 20.93% vs. the benchmark of 22.13%. These improvements become more significant as the network grows deeper. Furthermore, on both CIFAR and ImageNet, SRSGD reaches similar or even better error rates with fewer training epochs compared to the SGD baseline. We provide code for SRSGD at https://github.com/minhtannguyen/SRSGD.
Laplacian Smoothing Stochastic Gradient Markov Chain Monte Carlo
Nov 02, 2019
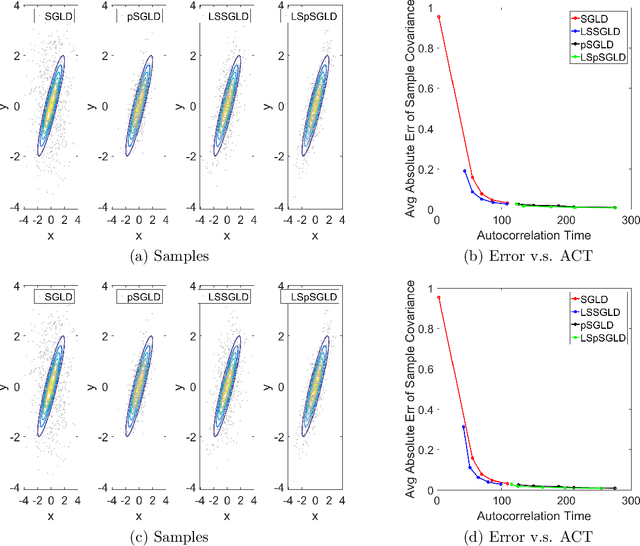
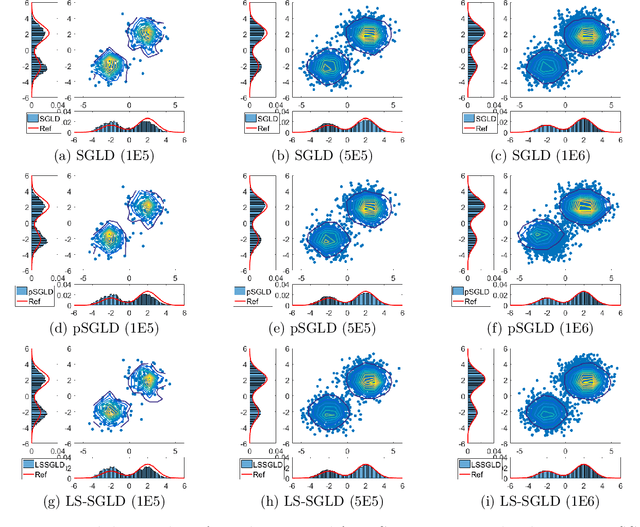

As an important Markov Chain Monte Carlo (MCMC) method, stochastic gradient Langevin dynamics (SGLD) algorithm has achieved great success in Bayesian learning and posterior sampling. However, SGLD typically suffers from slow convergence rate due to its large variance caused by the stochastic gradient. In order to alleviate these drawbacks, we leverage the recently developed Laplacian Smoothing (LS) technique and propose a Laplacian smoothing stochastic gradient Langevin dynamics (LS-SGLD) algorithm. We prove that for sampling from both log-concave and non-log-concave densities, LS-SGLD achieves strictly smaller discretization error in $2$-Wasserstein distance, although its mixing rate can be slightly slower. Experiments on both synthetic and real datasets verify our theoretical results, and demonstrate the superior performance of LS-SGLD on different machine learning tasks including posterior sampling, Bayesian logistic regression and training Bayesian convolutional neural networks. The code is available at \url{https://github.com/BaoWangMath/LS-MCMC}.
Graph Interpolating Activation Improves Both Natural and Robust Accuracies in Data-Efficient Deep Learning
Jul 16, 2019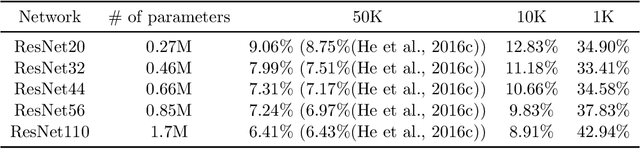
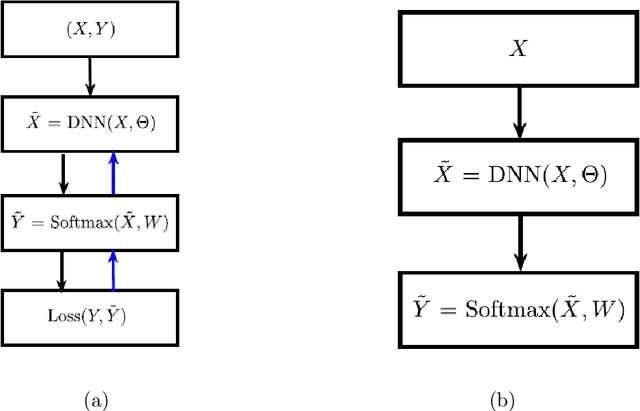
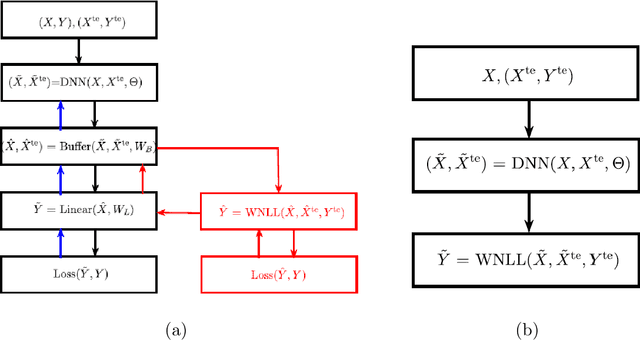

Improving the accuracy and robustness of deep neural nets (DNNs) and adapting them to small training data are primary tasks in deep learning research. In this paper, we replace the output activation function of DNNs, typically the data-agnostic softmax function, with a graph Laplacian-based high dimensional interpolating function which, in the continuum limit, converges to the solution of a Laplace-Beltrami equation on a high dimensional manifold. Furthermore, we propose end-to-end training and testing algorithms for this new architecture. The proposed DNN with graph interpolating activation integrates the advantages of both deep learning and manifold learning. Compared to the conventional DNNs with the softmax function as output activation, the new framework demonstrates the following major advantages: First, it is better applicable to data-efficient learning in which we train high capacity DNNs without using a large number of training data. Second, it remarkably improves both natural accuracy on the clean images and robust accuracy on the adversarial images crafted by both white-box and black-box adversarial attacks. Third, it is a natural choice for semi-supervised learning. For reproducibility, the code is available at \url{https://github.com/BaoWangMath/DNN-DataDependentActivation}.
DP-LSSGD: A Stochastic Optimization Method to Lift the Utility in Privacy-Preserving ERM
Jun 28, 2019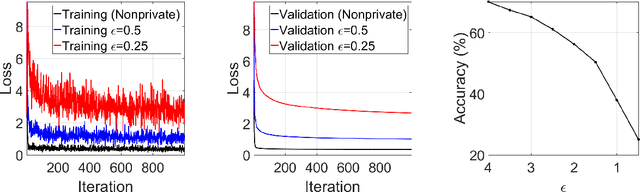

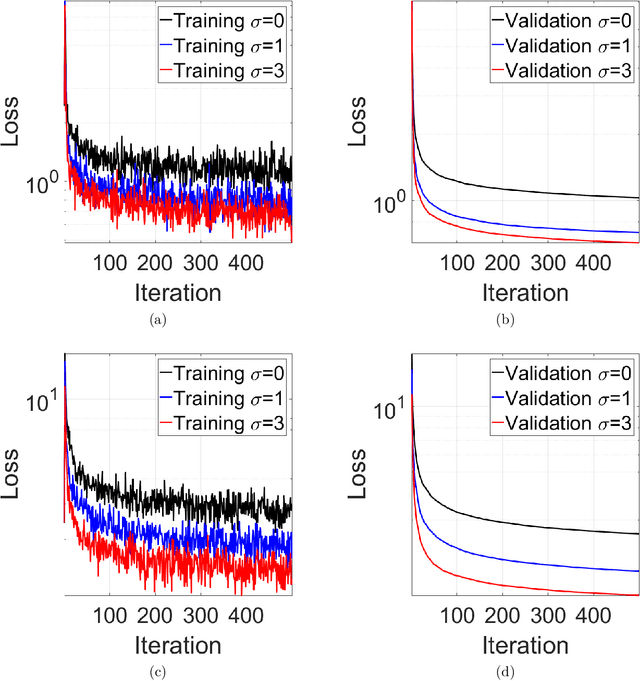
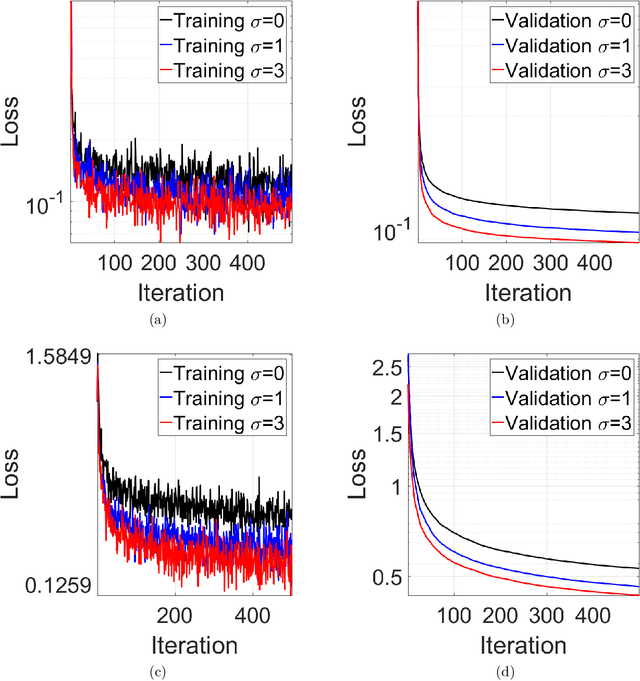
Machine learning (ML) models trained by differentially private stochastic gradient descent (DP-SGD) has much lower utility than the non-private ones. To mitigate this degradation, we propose a DP Laplacian smoothing SGD (DP-LSSGD) for privacy-preserving ML. At the core of DP-LSSGD is the Laplace smoothing operator, which smooths out the Gaussian noise vector used in the Gaussian mechanism. Under the same amount of noise used in the Gaussian mechanism, DP-LSSGD attains the same differential privacy guarantee, but a strictly better utility guarantee, excluding an intrinsic term which is usually dominated by the other terms, for convex optimization than DP-SGD by a factor which is much less than one. In practice, DP-LSSGD makes training both convex and nonconvex ML models more efficient and enables the trained models to generalize better. For ResNet20, under the same strong differential privacy guarantee, DP-LSSGD can lift the testing accuracy of the trained private model by more than $8$\% compared with DP-SGD. The proposed algorithm is simple to implement and the extra computational complexity and memory overhead compared with DP-SGD are negligible. DP-LSSGD is applicable to train a large variety of ML models, including deep neural nets. The code is available at \url{https://github.com/BaoWangMath/DP-LSSGD}.
A Study on Graph-Structured Recurrent Neural Networks and Sparsification with Application to Epidemic Forecasting
Feb 13, 2019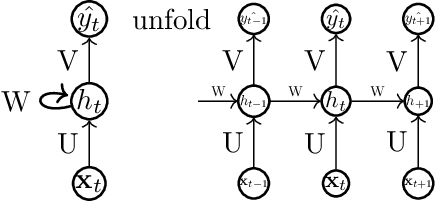
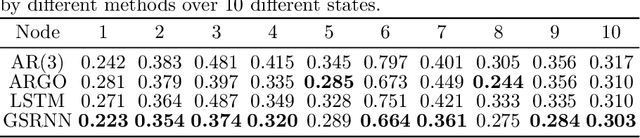
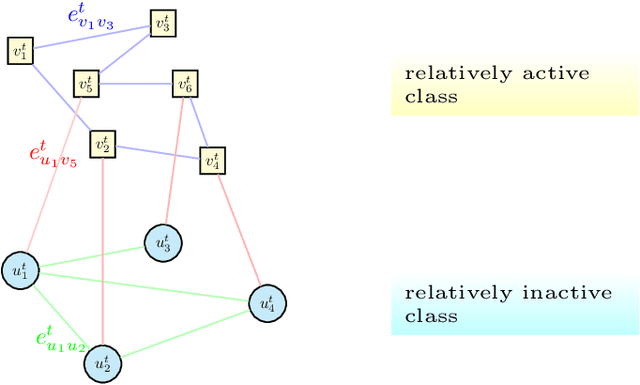

We study epidemic forecasting on real-world health data by a graph-structured recurrent neural network (GSRNN). We achieve state-of-the-art forecasting accuracy on the benchmark CDC dataset. To improve model efficiency, we sparsify the network weights via transformed-$\ell_1$ penalty and maintain prediction accuracy at the same level with 70% of the network weights being zero.