 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExTra: Transfer-guided Exploration
Jun 27, 2019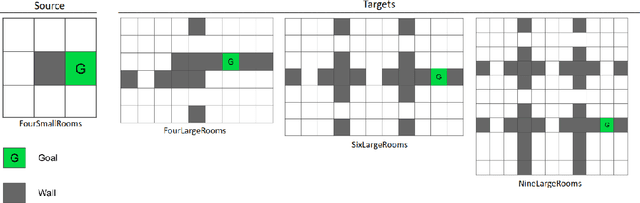
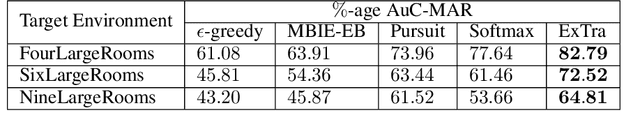
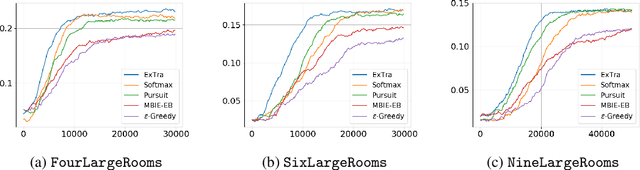

In this work we present a novel approach for transfer-guided exploration in reinforcement learning that is inspired by the human tendency to leverage experiences from similar encounters in the past while navigating a new task. Given an optimal policy in a related task-environment, we show that its bisimulation distance from the current task-environment gives a lower bound on the optimal advantage of state-action pairs in the current task-environment. Transfer-guided Exploration (ExTra) samples actions from a Softmax distribution over these lower bounds. In this way, actions with potentially higher optimum advantage are sampled more frequently. In our experiments on gridworld environments, we demonstrate that given access to an optimal policy in a related task-environment, ExTra can outperform popular domain-specific exploration strategies viz. epsilon greedy, Model-Based Interval Estimation - Exploration Based (MBIE-EB), Pursuit and Boltzmann in terms of sample complexity and rate of convergence. We further show that ExTra is robust to choices of source task and shows a graceful degradation of performance as the dissimilarity of the source task increases. We also demonstrate that ExTra, when used alongside traditional exploration algorithms, improves their rate of convergence. Thus it is capable of complimenting the efficacy of traditional exploration algorithms.
Learning Interpretable Models Using an Oracle
Jun 17, 2019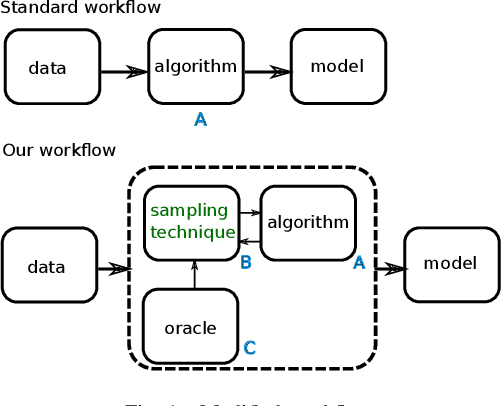
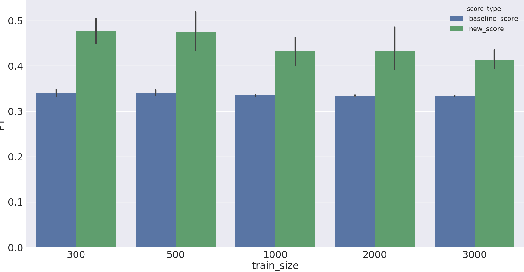
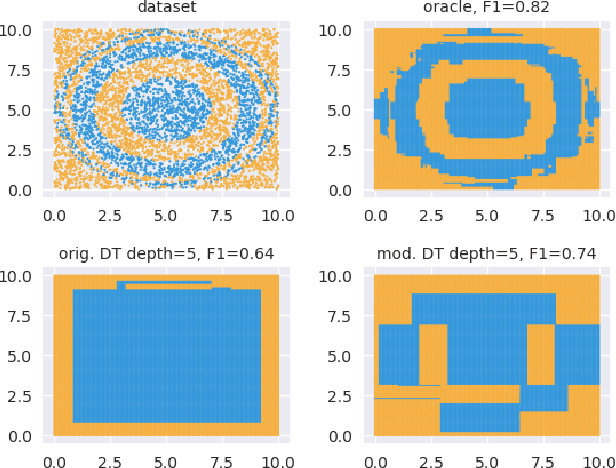
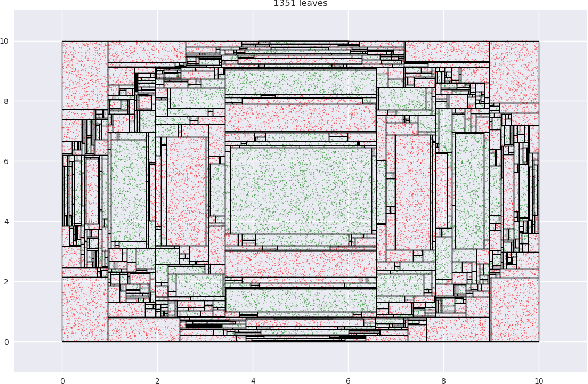
As Machine Learning (ML) becomes pervasive in various real world systems, the need for models to be interpretable or explainable has increased. We focus on interpretability, noting that models often need to be constrained in size for them to be considered understandable, e.g., a decision tree of depth 5 is easier to interpret than one of depth 50. This suggests a trade-off between interpretability and accuracy. We propose a technique to minimize this tradeoff. Our strategy is to first learn a powerful, possibly black-box, probabilistic model on the data, which we refer to as the oracle. We use this to adaptively sample the training dataset to present data to our model of interest to learn from. Determining the sampling strategy is formulated as an optimization problem that, independent of the dimensionality of the data, uses only seven variables. We empirically show that this often significantly increases the accuracy of our model. Our technique is model agnostic - in that, both the interpretable model and the oracle might come from any model family. Results using multiple real world datasets, using Linear Probability Models and Decision Trees as interpretable models, and Gradient Boosted Model and Random Forest as oracles are presented. Additionally, we discuss an interesting example of using a sentence-embedding based text classifier as an oracle to improve the accuracy of a term-frequency based bag-of-words linear classifier.
MaMiC: Macro and Micro Curriculum for Robotic Reinforcement Learning
May 17, 2019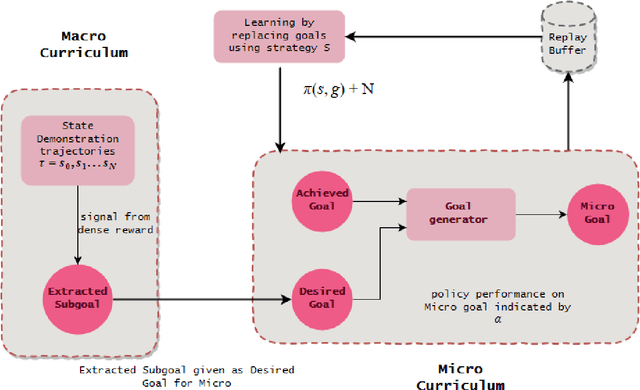

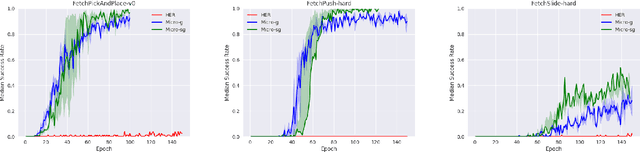
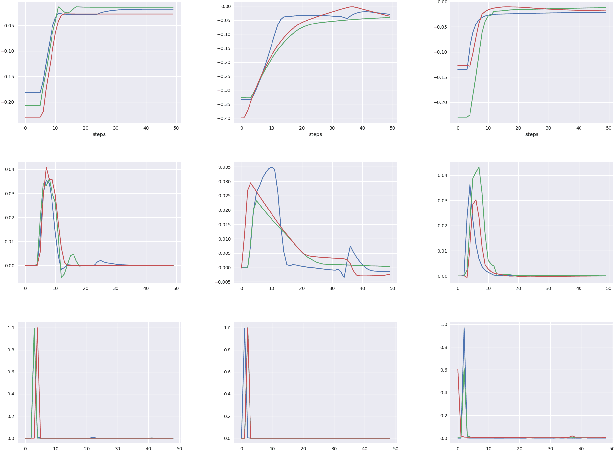
Shaping in humans and animals has been shown to be a powerful tool for learning complex tasks as compared to learning in a randomized fashion. This makes the problem less complex and enables one to solve the easier sub task at hand first. Generating a curriculum for such guided learning involves subjecting the agent to easier goals first, and then gradually increasing their difficulty. This paper takes a similar direction and proposes a dual curriculum scheme for solving robotic manipulation tasks with sparse rewards, called MaMiC. It includes a macro curriculum scheme which divides the task into multiple sub-tasks followed by a micro curriculum scheme which enables the agent to learn between such discovered sub-tasks. We show how combining macro and micro curriculum strategies help in overcoming major exploratory constraints considered in robot manipulation tasks without having to engineer any complex rewards. We also illustrate the meaning of the individual curricula and how they can be used independently based on the task. The performance of such a dual curriculum scheme is analyzed on the Fetch environments.
Successor Options: An Option Discovery Framework for Reinforcement Learning
May 14, 2019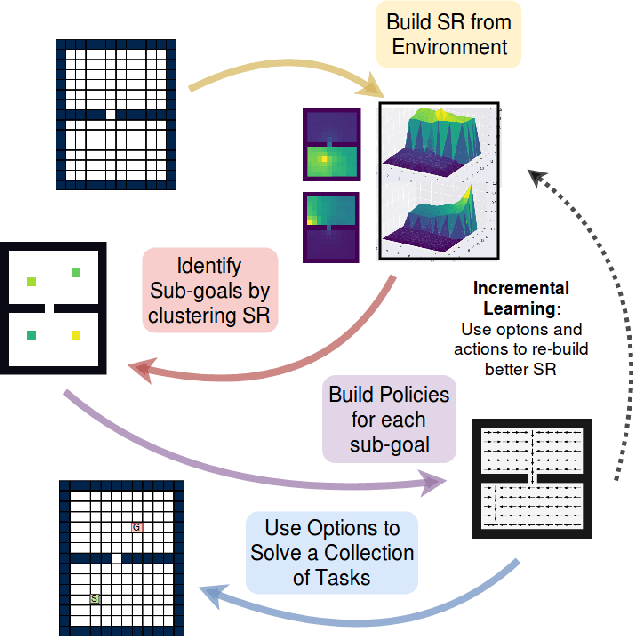
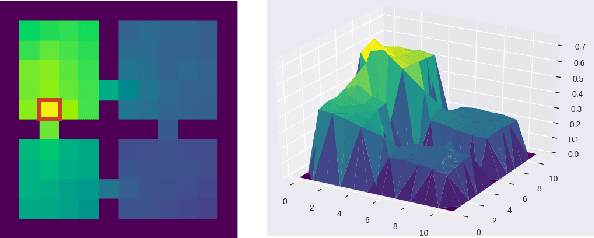
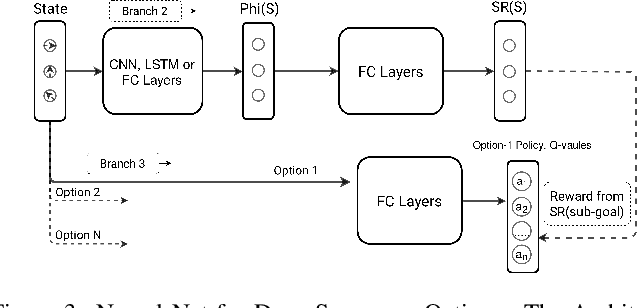
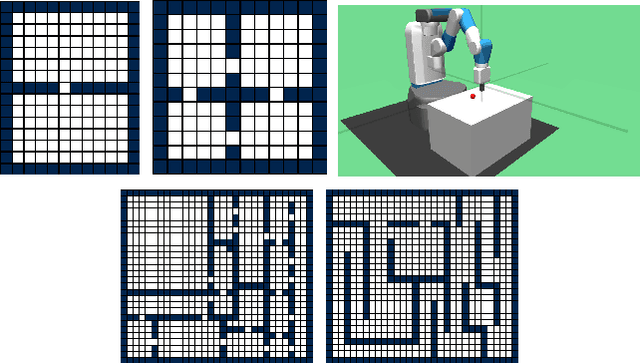
The options framework in reinforcement learning models the notion of a skill or a temporally extended sequence of actions. The discovery of a reusable set of skills has typically entailed building options, that navigate to bottleneck states. This work adopts a complementary approach, where we attempt to discover options that navigate to landmark states. These states are prototypical representatives of well-connected regions and can hence access the associated region with relative ease. In this work, we propose Successor Options, which leverages Successor Representations to build a model of the state space. The intra-option policies are learnt using a novel pseudo-reward and the model scales to high-dimensional spaces easily. Additionally, we also propose an Incremental Successor Options model that iterates between constructing Successor Representations and building options, which is useful when robust Successor Representations cannot be built solely from primitive actions. We demonstrate the efficacy of our approach on a collection of grid-worlds, and on the high-dimensional robotic control environment of Fetch.
Optimal Resampling for Learning Small Models
May 04, 2019
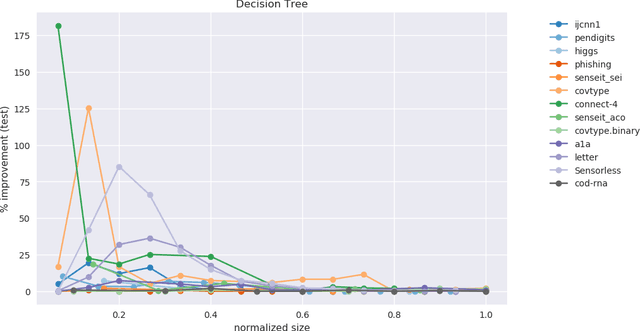
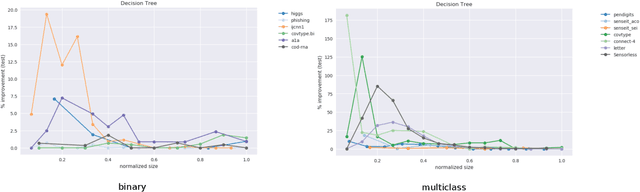
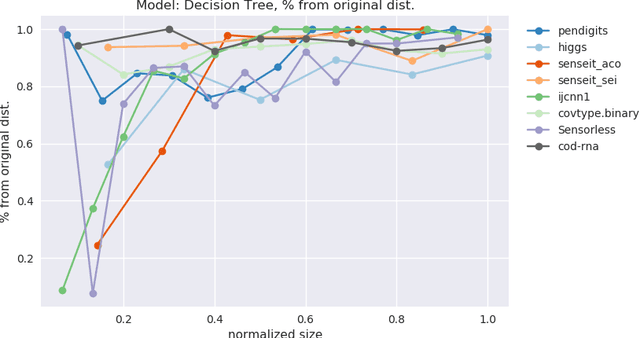
Models often need to be constrained to a certain size for them to be considered interpretable, for e.g., a decision tree of depth 5 is much easier to make sense of than one of depth 30. This suggests a trade-off between interpretability and accuracy. Our work tries to minimize this trade-off by suggesting the optimal distribution of the data to learn from, that surprisingly, may be different from the original distribution. We use an Infinite Beta Mixture Model (IBMM) to represent a specific set of sampling schemes. The parameters of the IBMM are learned using a Bayesian Optimizer (BO). While even under simplistic assumptions a distribution in the original $d$-dimensional space would need to optimize for $O(d)$ variables - cumbersome for most real-world data - our technique lowers this number significantly to a fixed set of 8 variables at the cost of some additional preprocessing. The proposed technique is \emph{model-agnostic}; it can be applied to any classifier. It also admits a general notion of model size. We demonstrate its effectiveness using multiple real-world datasets to construct decision trees, linear probability models and gradient boosted models.
Network Representation Learning: Consolidation and Renewed Bearing
May 02, 2019
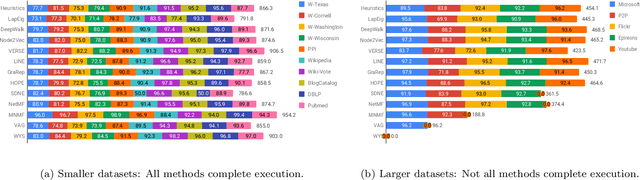
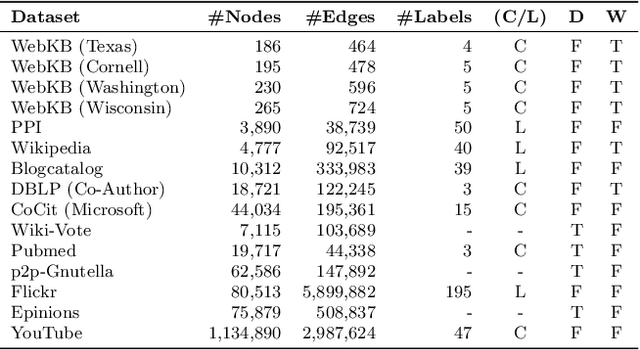
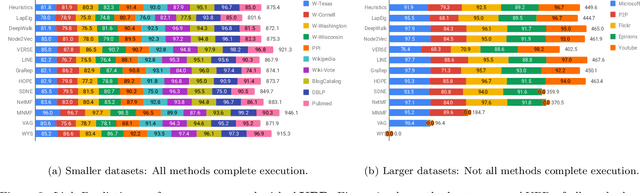
Graphs are a natural abstraction for many problems where nodes represent entities and edges represent a relationship across entities. An important area of research that has emerged over the last decade is the use of graphs as a vehicle for non-linear dimensionality reduction in a manner akin to previous efforts based on manifold learning with uses for downstream database processing, machine learning and visualization. In this systematic yet comprehensive experimental survey, we benchmark several popular network representation learning methods operating on two key tasks: link prediction and node classification. We examine the performance of 12 unsupervised embedding methods on 15 datasets. To the best of our knowledge, the scale of our study -- both in terms of the number of methods and number of datasets -- is the largest to date. Our results reveal several key insights about work-to-date in this space. First, we find that certain baseline methods (task-specific heuristics, as well as classic manifold methods) that have often been dismissed or are not considered by previous efforts can compete on certain types of datasets if they are tuned appropriately. Second, we find that recent methods based on matrix factorization offer a small but relatively consistent advantage over alternative methods (e.g., random-walk based methods) from a qualitative standpoint. Specifically, we find that MNMF, a community preserving embedding method, is the most competitive method for the link prediction task. While NetMF is the most competitive baseline for node classification. Third, no single method completely outperforms other embedding methods on both node classification and link prediction tasks. We also present several drill-down analysis that reveals settings under which certain algorithms perform well (e.g., the role of neighborhood context on performance) -- guiding the end-user.
Polyphonic Music Composition with LSTM Neural Networks and Reinforcement Learning
Mar 03, 2019
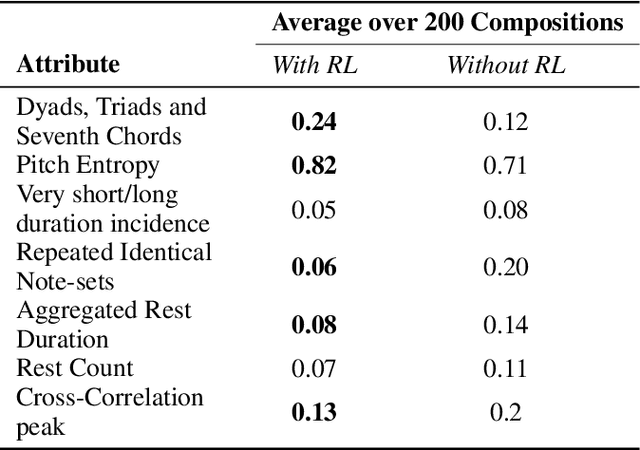

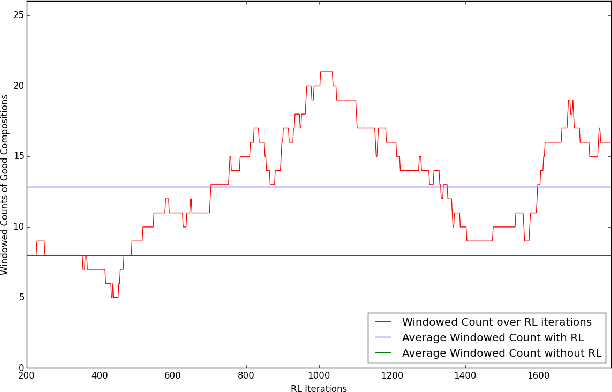
In the domain of algorithmic music composition, machine learning-driven systems eliminate the need for carefully hand-crafting rules for composition. In particular, the capability of recurrent neural networks to learn complex temporal patterns lends itself well to the musical domain. Promising results have been observed across a number of recent attempts at music composition using deep RNNs. These approaches generally aim at first training neural networks to reproduce subsequences drawn from existing songs. Subsequently, they are used to compose music either at the audio sample-level or at the note-level. We designed a representation that divides polyphonic music into a small number of monophonic streams. This representation greatly reduces the complexity of the problem and eliminates an exponential number of probably poor compositions. On top of our LSTM neural network that learnt musical sequences in this representation, we built an RL agent that learnt to find combinations of songs whose joint dominance produced pleasant compositions. We present Amadeus, an algorithmic music composition system that composes music that consists of intricate melodies, basic chords, and even occasional contrapuntal sequences.
An Active Learning Framework for Efficient Robust Policy Search
Jan 01, 2019
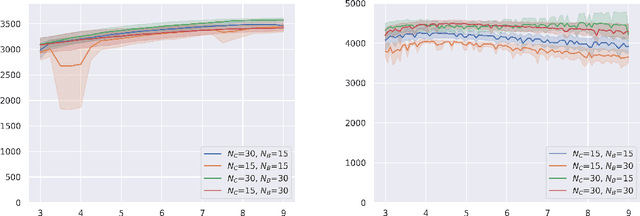
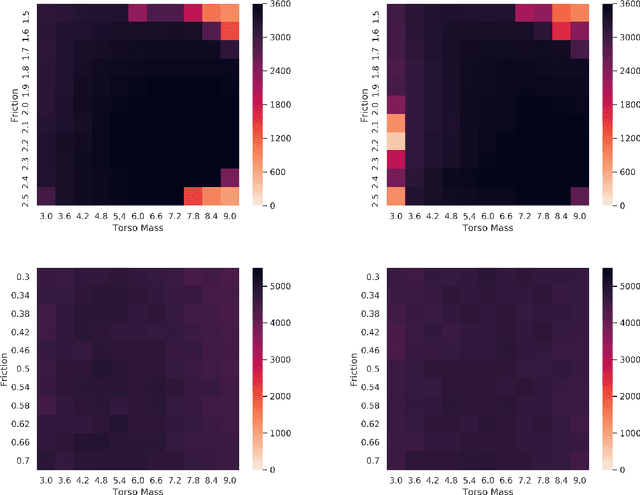
Robust Policy Search is the problem of learning policies that do not degrade in performance when subject to unseen environment model parameters. It is particularly relevant for transferring policies learned in a simulation environment to the real world. Several existing approaches involve sampling large batches of trajectories which reflect the differences in various possible environments, and then selecting some subset of these to learn robust policies, such as the ones that result in the worst performance. We propose an active learning based framework, EffAcTS, to selectively choose model parameters for this purpose so as to collect only as much data as necessary to select such a subset. We apply this framework to an existing method, namely EPOpt, and experimentally validate the gains in sample efficiency and the performance of our approach on standard continuous control tasks. We also present a Multi-Task Learning perspective to the problem of Robust Policy Search, and draw connections from our proposed framework to existing work on Multi-Task Learning.
Hypergraph Clustering: A Modularity Maximization Approach
Dec 28, 2018

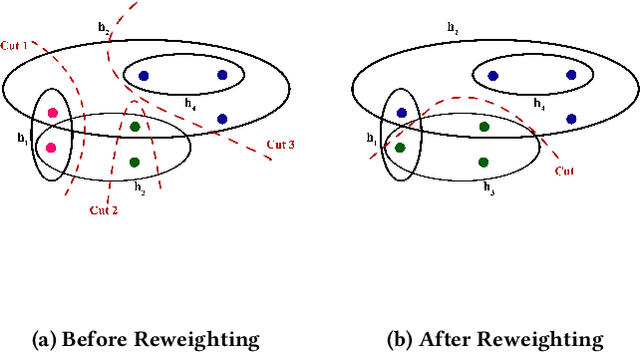
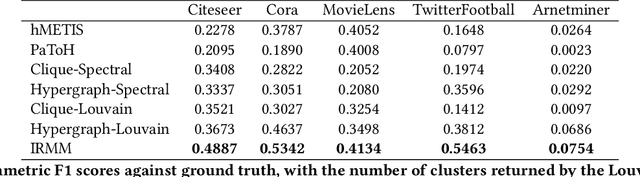
Clustering on hypergraphs has been garnering increased attention with potential applications in network analysis, VLSI design and computer vision, among others. In this work, we generalize the framework of modularity maximization for clustering on hypergraphs. To this end, we introduce a hypergraph null model, analogous to the configuration model on undirected graphs, and a node-degree preserving reduction to work with this model. This is used to define a modularity function that can be maximized using the popular and fast Louvain algorithm. We additionally propose a refinement over this clustering, by reweighting cut hyperedges in an iterative fashion. The efficacy and efficiency of our methods are demonstrated on several real-world datasets.
Studying the Plasticity in Deep Convolutional Neural Networks using Random Pruning
Dec 26, 2018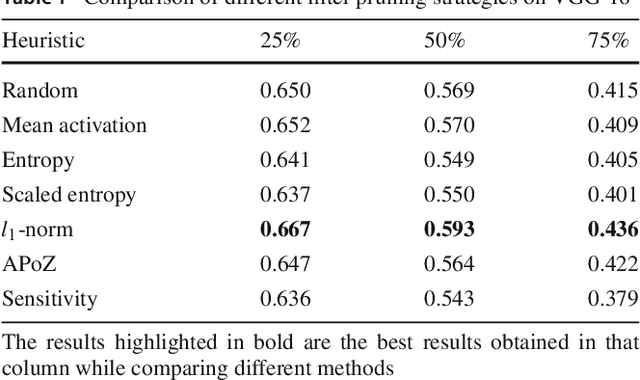
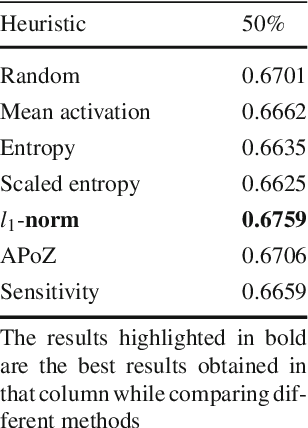
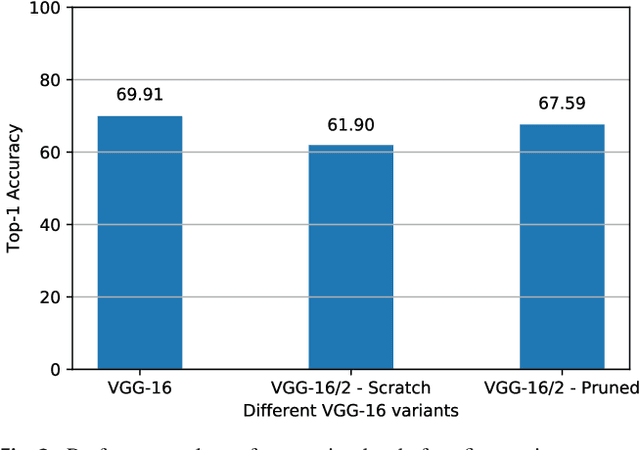
Recently there has been a lot of work on pruning filters from deep convolutional neural networks (CNNs) with the intention of reducing computations.The key idea is to rank the filters based on a certain criterion (say, l1-norm) and retain only the top ranked filters. Once the low scoring filters are pruned away the remainder of the network is fine tuned and is shown to give performance comparable to the original unpruned network. In this work, we report experiments which suggest that the comparable performance of the pruned network is not due to the specific criterion chosen but due to the inherent plasticity of deep neural networks which allows them to recover from the loss of pruned filters once the rest of the filters are fine-tuned. Specifically we show counter-intuitive results wherein by randomly pruning 25-50% filters from deep CNNs we are able to obtain the same performance as obtained by using state-of-the-art pruning methods. We empirically validate our claims by doing an exhaustive evaluation with VGG-16 and ResNet-50. We also evaluate a real world scenario where a CNN trained on all 1000 ImageNet classes needs to be tested on only a small set of classes at test time (say, only animals). We create a new benchmark dataset from ImageNet to evaluate such class specific pruning and show that even here a random pruning strategy gives close to state-of-the-art performance. Unlike existing approaches which mainly focus on the task of image classification, in this work we also report results on object detection and image segmentation. We show that using a simple random pruning strategy we can achieve significant speed up in object detection (74% improvement in fps) while retaining the same accuracy as that of the original Faster RCNN model. Similarly we show that the performance of a pruned Segmentation Network (SegNet) is actually very similar to that of the original unpruned SegNet.