 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Fragility of Active Learners
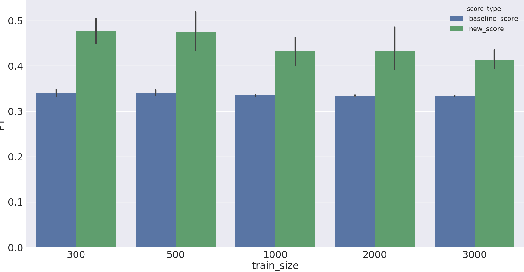
Mar 23, 2024Active learning (AL) techniques aim to maximally utilize a labeling budget by iteratively selecting instances that are most likely to improve prediction accuracy. However, their benefit compared to random sampling has not been consistent across various setups, e.g., different datasets, classifiers. In this empirical study, we examine how a combination of different factors might obscure any gains from an AL technique. Focusing on text classification, we rigorously evaluate AL techniques over around 1000 experiments that vary wrt the dataset, batch size, text representation and the classifier. We show that AL is only effective in a narrow set of circumstances. We also address the problem of using metrics that are better aligned with real world expectations. The impact of this study is in its insights for a practitioner: (a) the choice of text representation and classifier is as important as that of an AL technique, (b) choice of the right metric is critical in assessment of the latter, and, finally, (c) reported AL results must be holistically interpreted, accounting for variables other than just the query strategy.
Are Good Explainers Secretly Human-in-the-Loop Active Learners?
Jul 15, 2023Explainable AI (XAI) techniques have become popular for multiple use-cases in the past few years. Here we consider its use in studying model predictions to gather additional training data. We argue that this is equivalent to Active Learning, where the query strategy involves a human-in-the-loop. We provide a mathematical approximation for the role of the human, and present a general formalization of the end-to-end workflow. This enables us to rigorously compare this use with standard Active Learning algorithms, while allowing for extensions to the workflow. An added benefit is that their utility can be assessed via simulation instead of conducting expensive user-studies. We also present some initial promising results.
Accurate Small Models using Adaptive Sampling
Oct 08, 2022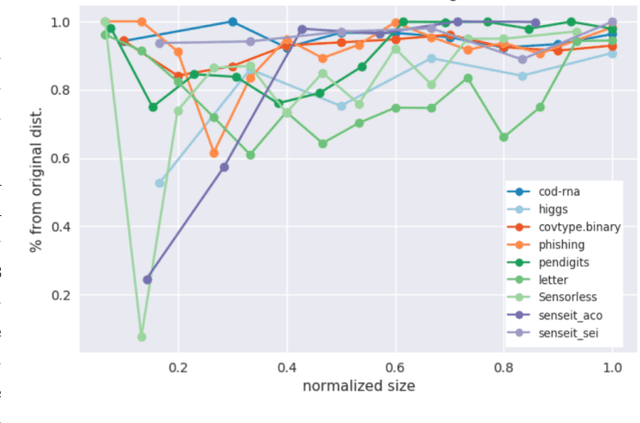
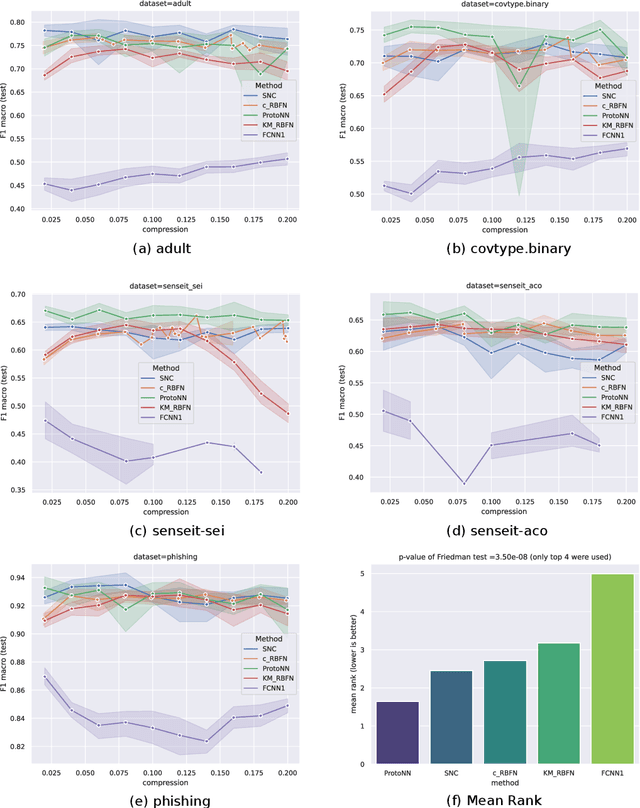
We highlight the utility of a certain property of model training: instead of drawing training data from the same distribution as test data, learning a different training distribution often improves accuracy, especially at small model sizes. This provides a way to build accurate small models, which are attractive for interpretability and resource-constrained environments. Here we empirically show that this principle is both general and effective: it may be used across tasks/model families, and it can augment prediction accuracy of traditional models to the extent they are competitive with specialized techniques. The tasks we consider are explainable clustering and prototype-based classification. We also look at Random Forests to illustrate how this principle may be applied to accommodate multiple size constraints, e.g., number of trees and maximum depth per tree. Results using multiple datasets are presented and are shown to be statistically significant.
Rational Kernels: A survey
Oct 20, 2019

Many kinds of data are naturally amenable to being treated as sequences. An example is text data, where a text may be seen as a sequence of words. Another example is clickstream data, where a data instance is a sequence of clicks made by a visitor to a website. This is also common for data originating in the domains of speech processing and computational biology. Using such data with statistical learning techniques can often prove to be cumbersome since most of them only allow fixed-length feature vectors as input. In casting the data to fixed-length feature vectors to suit these techniques, we lose the convenience, and possibly information, a good sequence-based representation can offer. The framework of rational kernels partly addresses this problem by providing an elegant representation for sequences, for algorithms that use kernel functions. In this report, we take a comprehensive look at this framework, its various extensions and applications. We start with an overview of the core ideas, where we look at the characterization of rational kernels, and then extend our discussion to extensions, applications and use at scale. Rational kernels represent a family of kernels, and thus, learning an appropriate rational kernel instead of picking one, suggests a convenient way to use them; we explore this idea in our concluding section. Rational kernels are not as popular as the many other learning techniques in use today; however, we hope that this summary effectively shows that not only is their theory well-developed, but also that various practical aspects have been carefully studied over time.
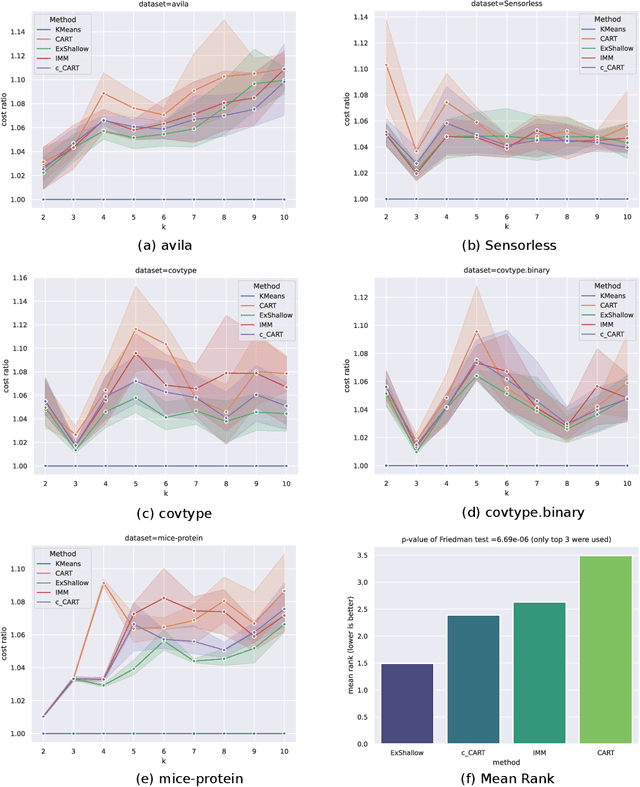
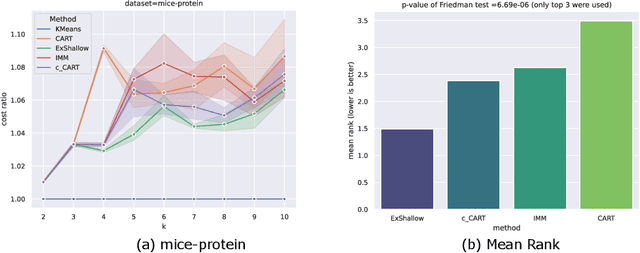
Learning Interpretable Models Using an Oracle
Jun 17, 2019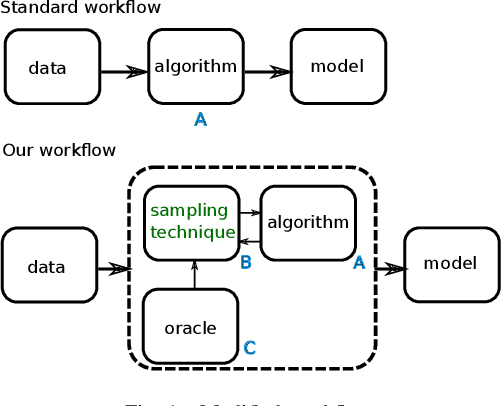
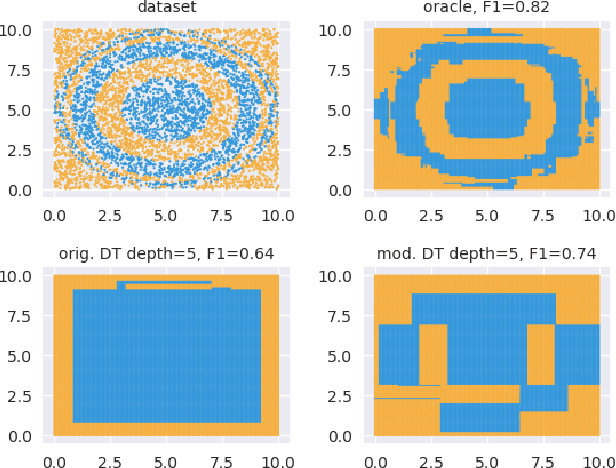
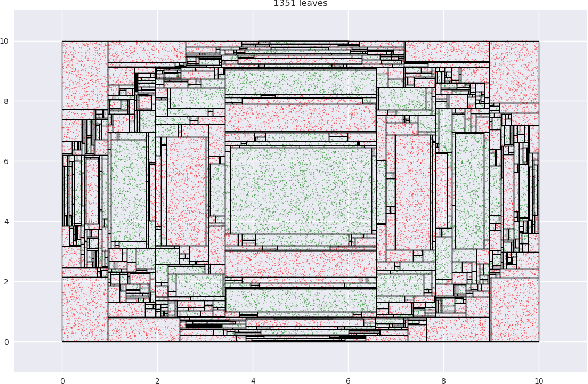
As Machine Learning (ML) becomes pervasive in various real world systems, the need for models to be interpretable or explainable has increased. We focus on interpretability, noting that models often need to be constrained in size for them to be considered understandable, e.g., a decision tree of depth 5 is easier to interpret than one of depth 50. This suggests a trade-off between interpretability and accuracy. We propose a technique to minimize this tradeoff. Our strategy is to first learn a powerful, possibly black-box, probabilistic model on the data, which we refer to as the oracle. We use this to adaptively sample the training dataset to present data to our model of interest to learn from. Determining the sampling strategy is formulated as an optimization problem that, independent of the dimensionality of the data, uses only seven variables. We empirically show that this often significantly increases the accuracy of our model. Our technique is model agnostic - in that, both the interpretable model and the oracle might come from any model family. Results using multiple real world datasets, using Linear Probability Models and Decision Trees as interpretable models, and Gradient Boosted Model and Random Forest as oracles are presented. Additionally, we discuss an interesting example of using a sentence-embedding based text classifier as an oracle to improve the accuracy of a term-frequency based bag-of-words linear classifier.
Optimal Resampling for Learning Small Models
May 04, 2019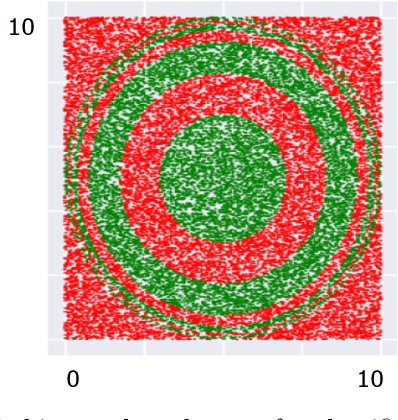
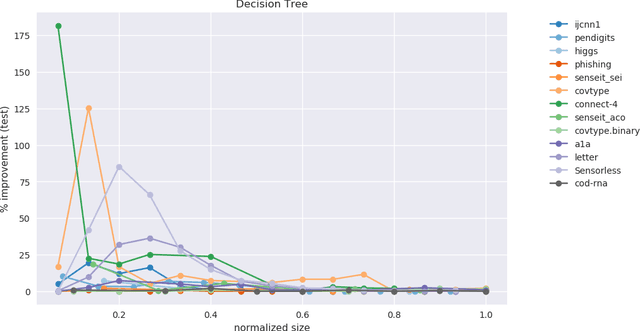
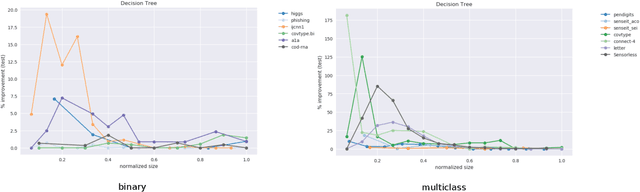
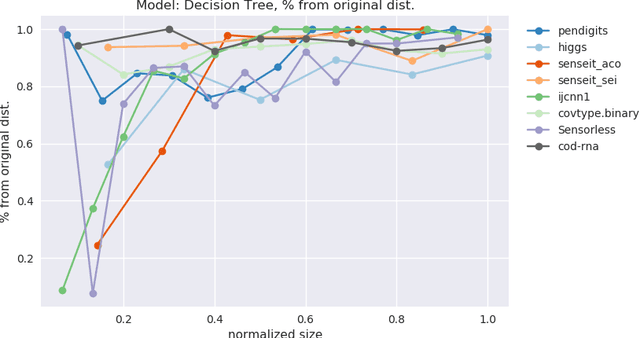
Models often need to be constrained to a certain size for them to be considered interpretable, for e.g., a decision tree of depth 5 is much easier to make sense of than one of depth 30. This suggests a trade-off between interpretability and accuracy. Our work tries to minimize this trade-off by suggesting the optimal distribution of the data to learn from, that surprisingly, may be different from the original distribution. We use an Infinite Beta Mixture Model (IBMM) to represent a specific set of sampling schemes. The parameters of the IBMM are learned using a Bayesian Optimizer (BO). While even under simplistic assumptions a distribution in the original $d$-dimensional space would need to optimize for $O(d)$ variables - cumbersome for most real-world data - our technique lowers this number significantly to a fixed set of 8 variables at the cost of some additional preprocessing. The proposed technique is \emph{model-agnostic}; it can be applied to any classifier. It also admits a general notion of model size. We demonstrate its effectiveness using multiple real-world datasets to construct decision trees, linear probability models and gradient boosted models.