 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective, Controlled and Domain-Agnostic Unlearning in Pretrained CLIP: A Training- and Data-Free Approach
Dec 16, 2025



Pretrained models like CLIP have demonstrated impressive zero-shot classification capabilities across diverse visual domains, spanning natural images, artistic renderings, and abstract representations. However, real-world applications often demand the removal (or "unlearning") of specific object classes without requiring additional data or retraining, or affecting the model's performance on unrelated tasks. In this paper, we propose a novel training- and data-free unlearning framework that enables three distinct forgetting paradigms: (1) global unlearning of selected objects across all domains, (2) domain-specific knowledge removal (e.g., eliminating sketch representations while preserving photo recognition), and (3) complete unlearning in selective domains. By leveraging a multimodal nullspace through synergistic integration of text prompts and synthesized visual prototypes derived from CLIP's joint embedding space, our method efficiently removes undesired class information while preserving the remaining knowledge. This approach overcomes the limitations of existing retraining-based methods and offers a flexible and computationally efficient solution for controlled model forgetting.
Erasing CLIP Memories: Non-Destructive, Data-Free Zero-Shot class Unlearning in CLIP Models
Dec 16, 2025We introduce a novel, closed-form approach for selective unlearning in multimodal models, specifically targeting pretrained models such as CLIP. Our method leverages nullspace projection to erase the target class information embedded in the final projection layer, without requiring any retraining or the use of images from the forget set. By computing an orthonormal basis for the subspace spanned by target text embeddings and projecting these directions, we dramatically reduce the alignment between image features and undesired classes. Unlike traditional unlearning techniques that rely on iterative fine-tuning and extensive data curation, our approach is both computationally efficient and surgically precise. This leads to a pronounced drop in zero-shot performance for the target classes while preserving the overall multimodal knowledge of the model. Our experiments demonstrate that even a partial projection can balance between complete unlearning and retaining useful information, addressing key challenges in model decontamination and privacy preservation.
Evaluating Table Structure Recognition: A New Perspective
Jul 31, 2022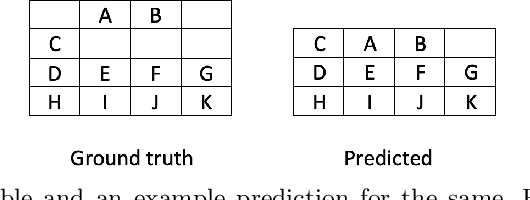

Existing metrics used to evaluate table structure recognition algorithms have shortcomings with regard to capturing text and empty cells alignment. In this paper, we build on prior work and propose a new metric - TEDS based IOU similarity (TEDS (IOU)) for table structure recognition which uses bounding boxes instead of text while simultaneously being robust against the above disadvantages. We demonstrate the effectiveness of our metric against previous metrics through various examples.
Hypergraph Clustering: A Modularity Maximization Approach
Dec 28, 2018

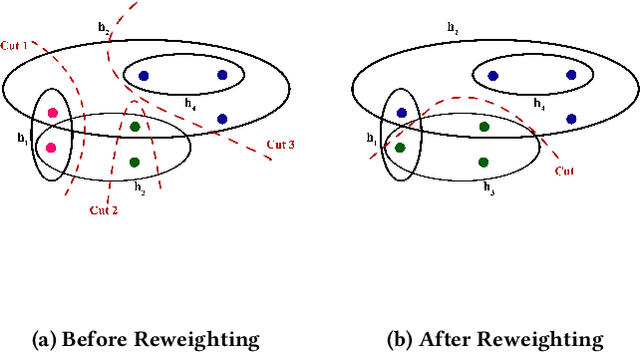
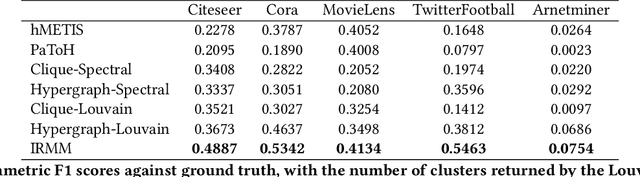
Clustering on hypergraphs has been garnering increased attention with potential applications in network analysis, VLSI design and computer vision, among others. In this work, we generalize the framework of modularity maximization for clustering on hypergraphs. To this end, we introduce a hypergraph null model, analogous to the configuration model on undirected graphs, and a node-degree preserving reduction to work with this model. This is used to define a modularity function that can be maximized using the popular and fast Louvain algorithm. We additionally propose a refinement over this clustering, by reweighting cut hyperedges in an iterative fashion. The efficacy and efficiency of our methods are demonstrated on several real-world datasets.