 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan You Trust Your Model's Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift
Jun 06, 2019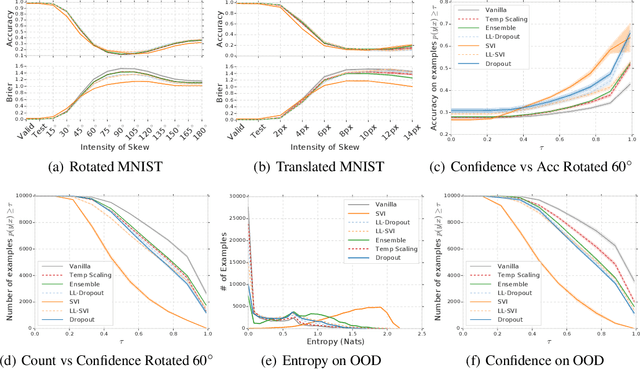
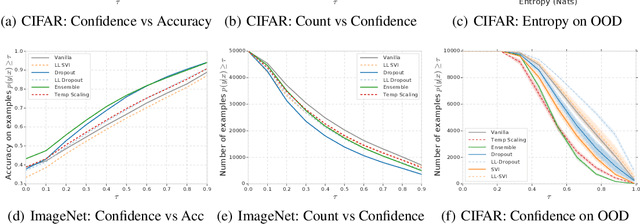
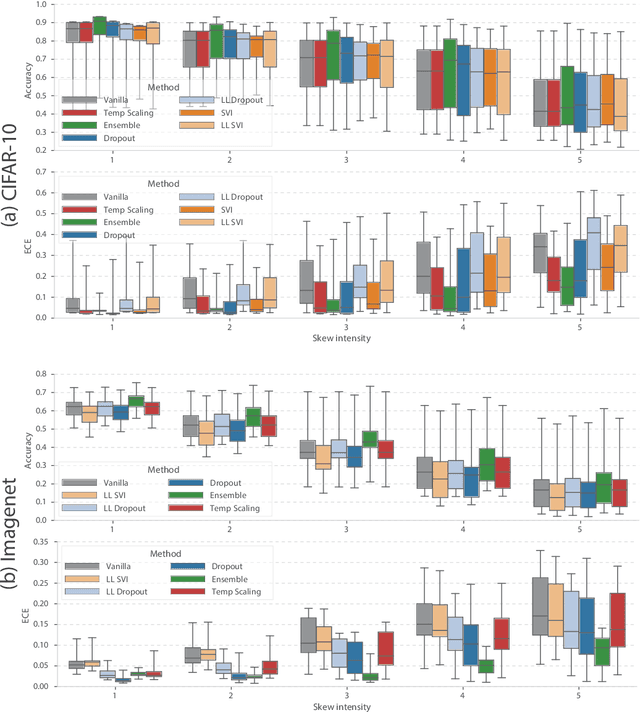
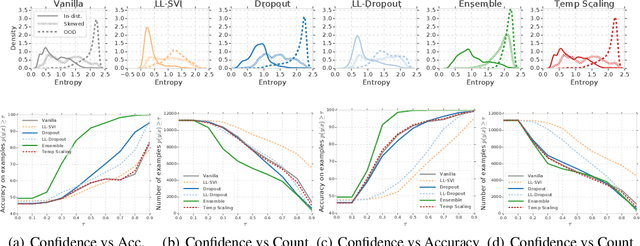
Modern machine learning methods including deep learning have achieved great success in predictive accuracy for supervised learning tasks, but may still fall short in giving useful estimates of their predictive {\em uncertainty}. Quantifying uncertainty is especially critical in real-world settings, which often involve input distributions that are shifted from the training distribution due to a variety of factors including sample bias and non-stationarity. In such settings, well calibrated uncertainty estimates convey information about when a model's output should (or should not) be trusted. Many probabilistic deep learning methods, including Bayesian-and non-Bayesian methods, have been proposed in the literature for quantifying predictive uncertainty, but to our knowledge there has not previously been a rigorous large-scale empirical comparison of these methods under dataset shift. We present a large-scale benchmark of existing state-of-the-art methods on classification problems and investigate the effect of dataset shift on accuracy and calibration. We find that traditional post-hoc calibration does indeed fall short, as do several other previous methods. However, some methods that marginalize over models give surprisingly strong results across a broad spectrum of tasks.
Hybrid Models with Deep and Invertible Features
Feb 07, 2019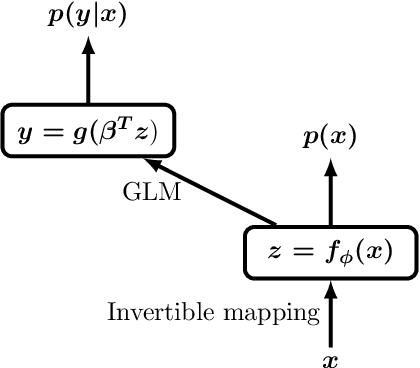
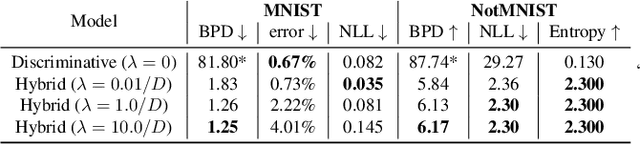
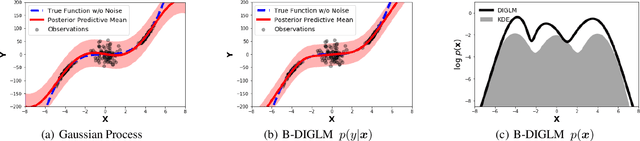
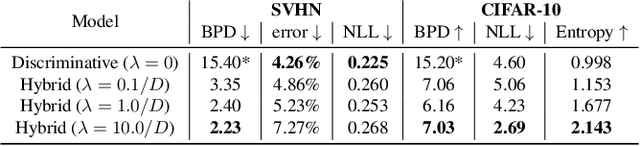
We propose a neural hybrid model consisting of a linear model defined on a set of features computed by a deep, invertible transformation (i.e. a normalizing flow). An attractive property of our model is that both p(features), the features' density, and p(targets | features), the predictive distribution, can be computed exactly in a single feed-forward pass. We show that our hybrid model, despite the invertibility constraints, achieves similar accuracy to purely predictive models. Yet the generative component remains a good model of the input features despite the hybrid optimization objective. This offers additional capabilities such as detection of out-of-distribution inputs and enabling semi-supervised learning. The availability of the exact joint density p(targets, features) also allows us to compute many quantities readily, making our hybrid model a useful building block for downstream applications of probabilistic deep learning.
Adapting Auxiliary Losses Using Gradient Similarity
Dec 05, 2018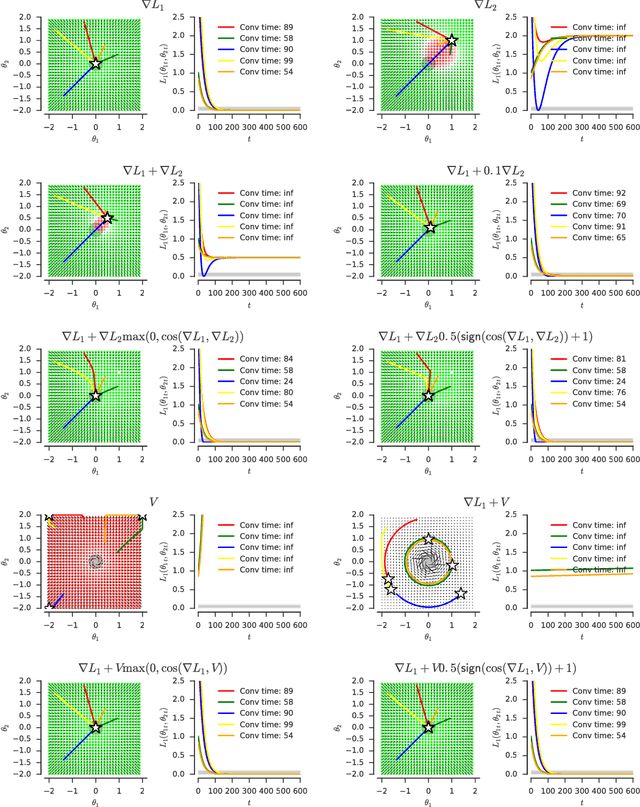
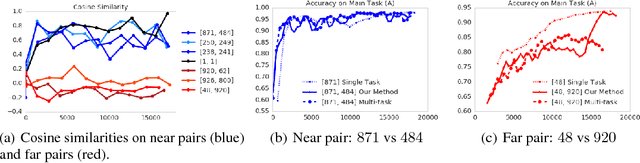
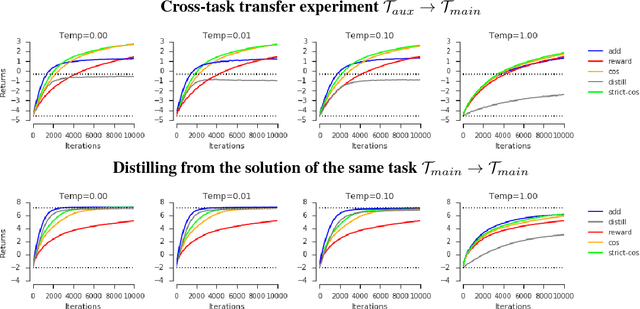
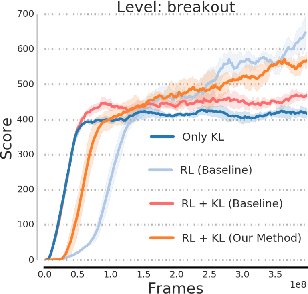
One approach to deal with the statistical inefficiency of neural networks is to rely on auxiliary losses that help to build useful representations. However, it is not always trivial to know if an auxiliary task will be helpful for the main task and when it could start hurting. We propose to use the cosine similarity between gradients of tasks as an adaptive weight to detect when an auxiliary loss is helpful to the main loss. We show that our approach is guaranteed to converge to critical points of the main task and demonstrate the practical usefulness of the proposed algorithm in a few domains: multi-task supervised learning on subsets of ImageNet, reinforcement learning on gridworld, and reinforcement learning on Atari games.
Do Deep Generative Models Know What They Don't Know?
Oct 22, 2018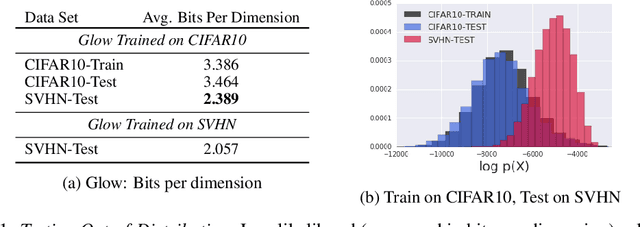
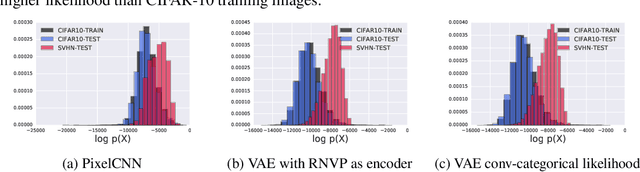
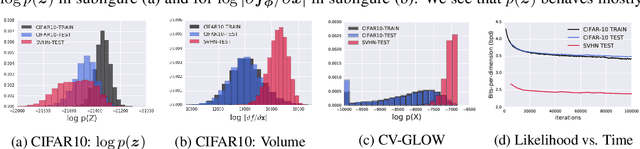
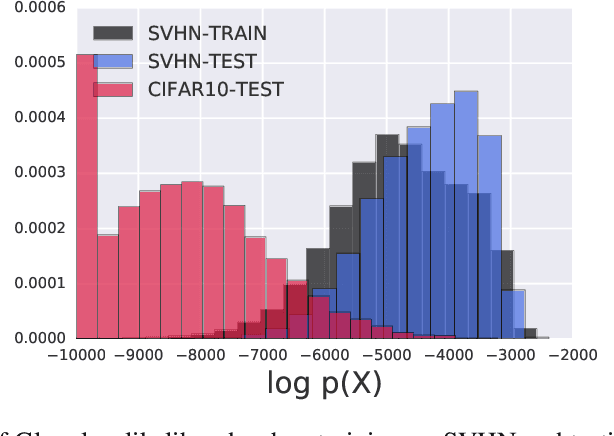
A neural network deployed in the wild may be asked to make predictions for inputs that were drawn from a different distribution than that of the training data. A plethora of work has demonstrated that it is easy to find or synthesize inputs for which a neural network is highly confident yet wrong. Generative models are widely viewed to be robust to such mistaken confidence as modeling the density of the input features can be used to detect novel, out-of-distribution inputs. In this paper we challenge this assumption. We find that the model density from flow-based models, VAEs and PixelCNN cannot distinguish images of common objects such as dogs, trucks, and horses (i.e. CIFAR-10) from those of house numbers (i.e. SVHN), assigning a higher likelihood to the latter when the model is trained on the former. We focus our analysis on flow-based generative models in particular since they are trained and evaluated via the exact marginal likelihood. We find such behavior persists even when we restrict the flow models to constant-volume transformations. These transformations admit some theoretical analysis, and we show that the difference in likelihoods can be explained by the location and variances of the data and the model curvature, which shows that such behavior is more general and not just restricted to the pairs of datasets used in our experiments. Our results caution against using the density estimates from deep generative models to identify inputs similar to the training distribution, until their behavior on out-of-distribution inputs is better understood.
Learning from Delayed Outcomes with Intermediate Observations
Jul 24, 2018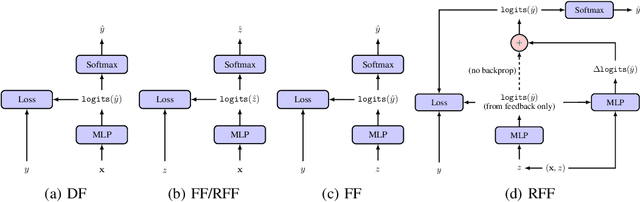

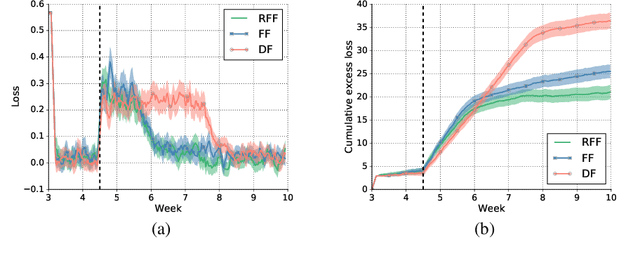
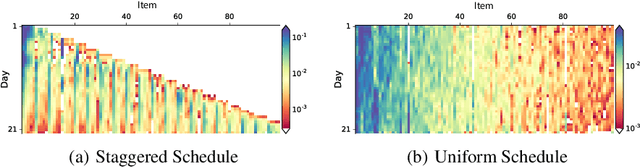
Optimizing for long term value is desirable in many practical applications, e.g. recommender systems. The most common approach for long term value optimization is supervised learning using long term value as the target. Unfortunately, long term metrics take a long time to measure (e.g., will customers finish reading an ebook?), and vanilla forecasters cannot learn from examples until the outcome is observed. In practical systems where new items arrive frequently, such delay can increase the training-serving skew, thereby negatively affecting the model's predictions for new products. We argue that intermediate observations (e.g., if customers read a third of the book in 24 hours) can improve a model's predictions. We formalize the problem as a semi-stochastic model, where instances are selected by an adversary but, given an instance, the intermediate observation and the outcome are sampled from a factored joint distribution. We propose an algorithm that exploits intermediate observations and theoretically quantify how much it can outperform any prediction method that ignores the intermediate observations. Motivated by the theoretical analysis, we propose two neural network architectures: Factored Forecaster (FF) which is ideal if our assumptions are satisfied, and Residual Factored Forecaster (RFF) that is more robust to model mis-specification. Experiments on two real world datasets, a dataset derived from GitHub repositories and another dataset from a popular marketplace, show that RFF outperforms both FF as well as an algorithm that ignores intermediate observations.
Distribution Matching in Variational Inference
Jun 12, 2018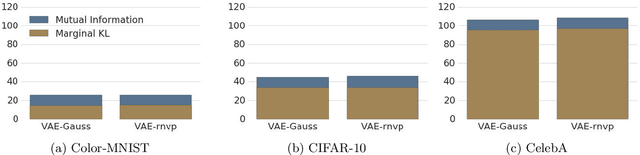


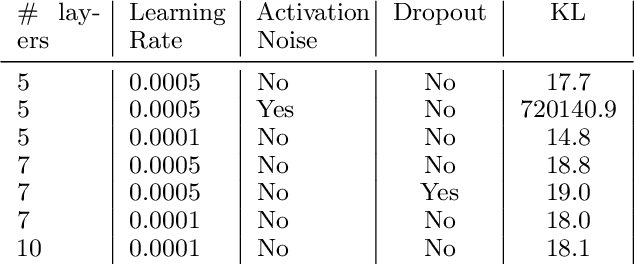
We show that Variational Autoencoders consistently fail to learn marginal distributions in latent and visible space. We ask whether this is a consequence of matching conditional distributions, or a limitation of explicit model and posterior distributions. We explore alternatives provided by marginal distribution matching and implicit distributions through the use of Generative Adversarial Networks in variational inference. We perform a large-scale evaluation of several VAE-GAN hybrids and explore the implications of class probability estimation for learning distributions. We conclude that at present VAE-GAN hybrids have limited applicability: they are harder to scale, evaluate, and use for inference compared to VAEs; and they do not improve over the generation quality of GANs.
Many Paths to Equilibrium: GANs Do Not Need to Decrease a Divergence At Every Step
Feb 20, 2018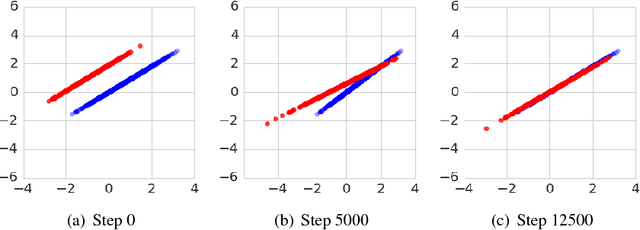
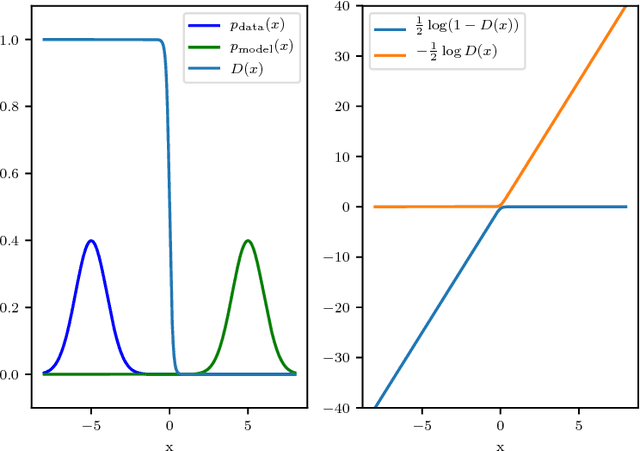
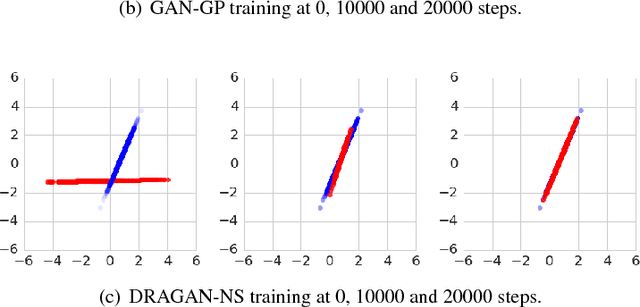
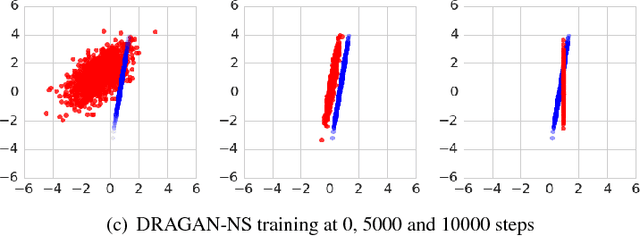
Generative adversarial networks (GANs) are a family of generative models that do not minimize a single training criterion. Unlike other generative models, the data distribution is learned via a game between a generator (the generative model) and a discriminator (a teacher providing training signal) that each minimize their own cost. GANs are designed to reach a Nash equilibrium at which each player cannot reduce their cost without changing the other players' parameters. One useful approach for the theory of GANs is to show that a divergence between the training distribution and the model distribution obtains its minimum value at equilibrium. Several recent research directions have been motivated by the idea that this divergence is the primary guide for the learning process and that every step of learning should decrease the divergence. We show that this view is overly restrictive. During GAN training, the discriminator provides learning signal in situations where the gradients of the divergences between distributions would not be useful. We provide empirical counterexamples to the view of GAN training as divergence minimization. Specifically, we demonstrate that GANs are able to learn distributions in situations where the divergence minimization point of view predicts they would fail. We also show that gradient penalties motivated from the divergence minimization perspective are equally helpful when applied in other contexts in which the divergence minimization perspective does not predict they would be helpful. This contributes to a growing body of evidence that GAN training may be more usefully viewed as approaching Nash equilibria via trajectories that do not necessarily minimize a specific divergence at each step.
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles
Nov 04, 2017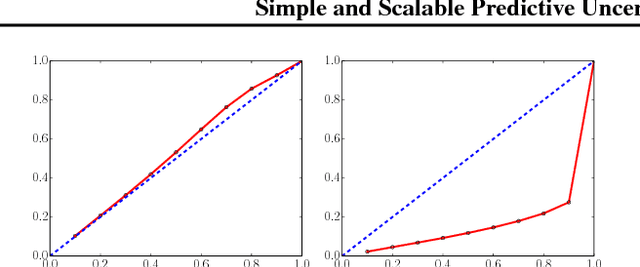
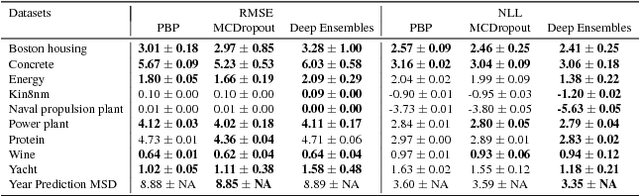

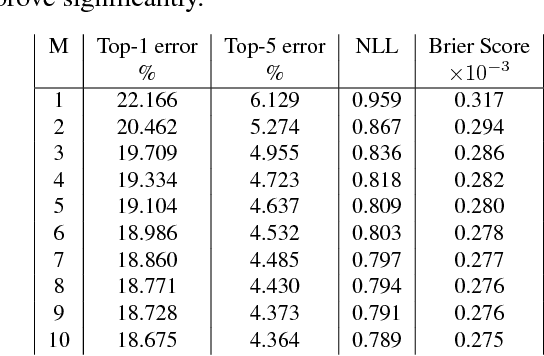
Deep neural networks (NNs) are powerful black box predictors that have recently achieved impressive performance on a wide spectrum of tasks. Quantifying predictive uncertainty in NNs is a challenging and yet unsolved problem. Bayesian NNs, which learn a distribution over weights, are currently the state-of-the-art for estimating predictive uncertainty; however these require significant modifications to the training procedure and are computationally expensive compared to standard (non-Bayesian) NNs. We propose an alternative to Bayesian NNs that is simple to implement, readily parallelizable, requires very little hyperparameter tuning, and yields high quality predictive uncertainty estimates. Through a series of experiments on classification and regression benchmarks, we demonstrate that our method produces well-calibrated uncertainty estimates which are as good or better than approximate Bayesian NNs. To assess robustness to dataset shift, we evaluate the predictive uncertainty on test examples from known and unknown distributions, and show that our method is able to express higher uncertainty on out-of-distribution examples. We demonstrate the scalability of our method by evaluating predictive uncertainty estimates on ImageNet.
Variational Approaches for Auto-Encoding Generative Adversarial Networks
Oct 21, 2017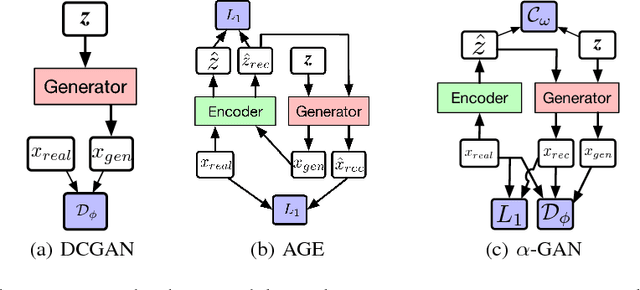

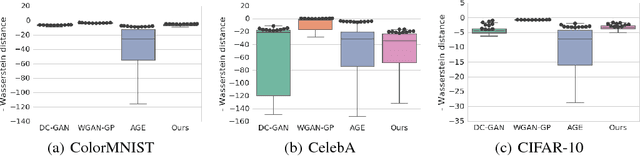

Auto-encoding generative adversarial networks (GANs) combine the standard GAN algorithm, which discriminates between real and model-generated data, with a reconstruction loss given by an auto-encoder. Such models aim to prevent mode collapse in the learned generative model by ensuring that it is grounded in all the available training data. In this paper, we develop a principle upon which auto-encoders can be combined with generative adversarial networks by exploiting the hierarchical structure of the generative model. The underlying principle shows that variational inference can be used a basic tool for learning, but with the in- tractable likelihood replaced by a synthetic likelihood, and the unknown posterior distribution replaced by an implicit distribution; both synthetic likelihoods and implicit posterior distributions can be learned using discriminators. This allows us to develop a natural fusion of variational auto-encoders and generative adversarial networks, combining the best of both these methods. We describe a unified objective for optimization, discuss the constraints needed to guide learning, connect to the wide range of existing work, and use a battery of tests to systematically and quantitatively assess the performance of our method.
Distributed Bayesian Learning with Stochastic Natural-gradient Expectation Propagation and the Posterior Server
Sep 07, 2017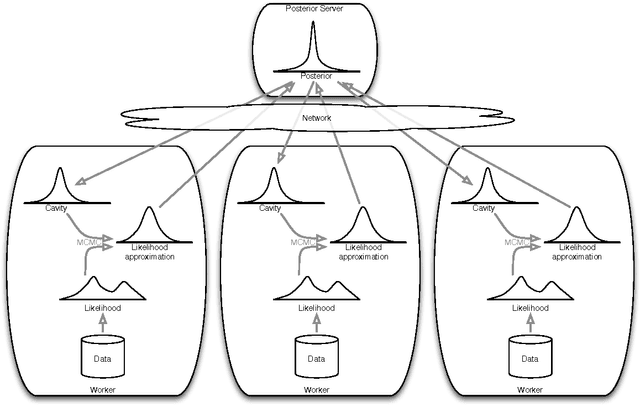
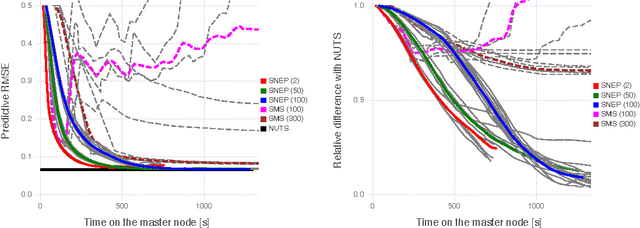
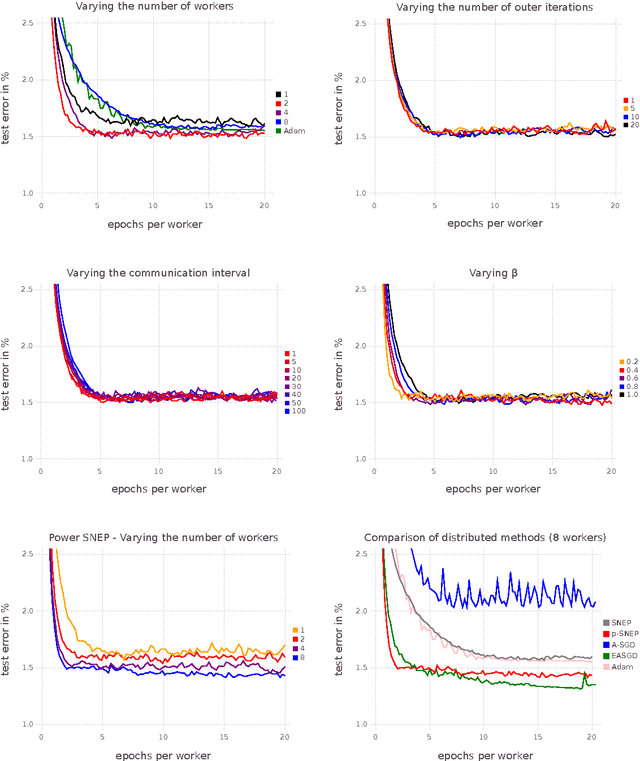
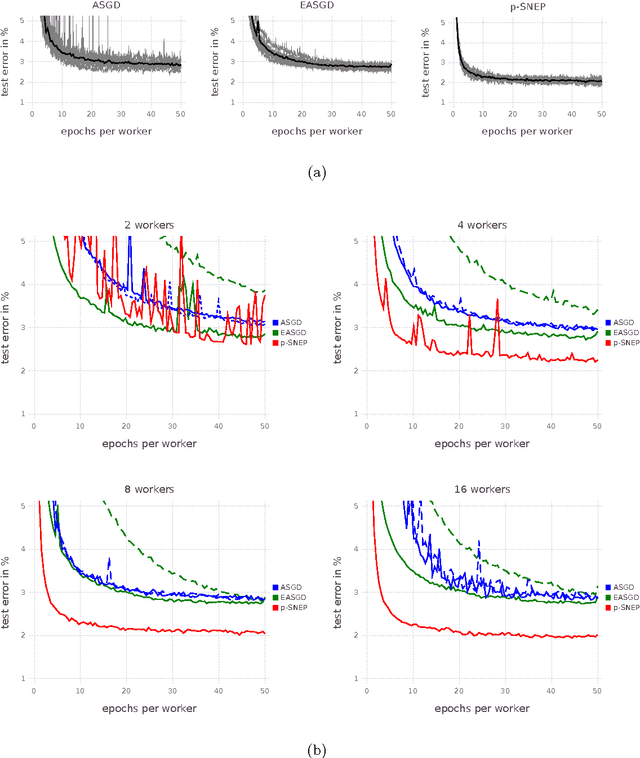
This paper makes two contributions to Bayesian machine learning algorithms. Firstly, we propose stochastic natural gradient expectation propagation (SNEP), a novel alternative to expectation propagation (EP), a popular variational inference algorithm. SNEP is a black box variational algorithm, in that it does not require any simplifying assumptions on the distribution of interest, beyond the existence of some Monte Carlo sampler for estimating the moments of the EP tilted distributions. Further, as opposed to EP which has no guarantee of convergence, SNEP can be shown to be convergent, even when using Monte Carlo moment estimates. Secondly, we propose a novel architecture for distributed Bayesian learning which we call the posterior server. The posterior server allows scalable and robust Bayesian learning in cases where a data set is stored in a distributed manner across a cluster, with each compute node containing a disjoint subset of data. An independent Monte Carlo sampler is run on each compute node, with direct access only to the local data subset, but which targets an approximation to the global posterior distribution given all data across the whole cluster. This is achieved by using a distributed asynchronous implementation of SNEP to pass messages across the cluster. We demonstrate SNEP and the posterior server on distributed Bayesian learning of logistic regression and neural networks. Keywords: Distributed Learning, Large Scale Learning, Deep Learning, Bayesian Learn- ing, Variational Inference, Expectation Propagation, Stochastic Approximation, Natural Gradient, Markov chain Monte Carlo, Parameter Server, Posterior Server.
* 37 pages, 7 figures