 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucinative Topological Memory for Zero-Shot Visual Planning
Feb 27, 2020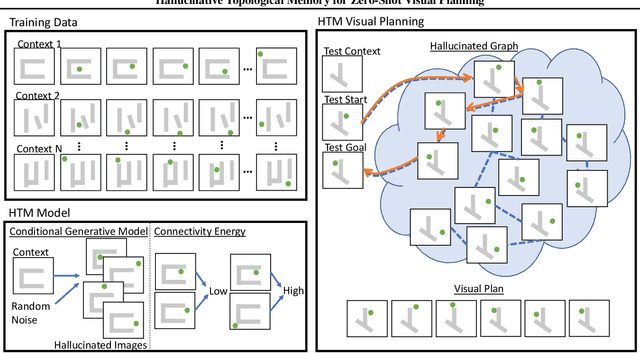
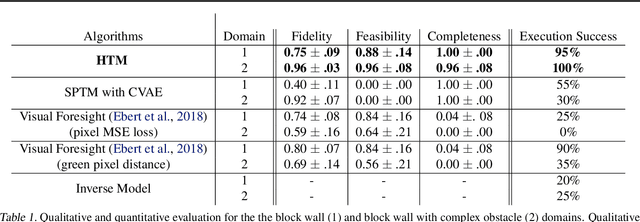
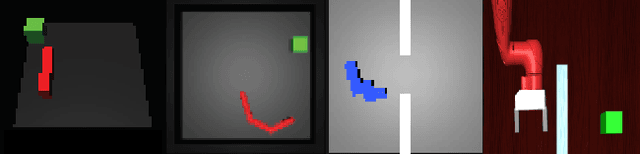
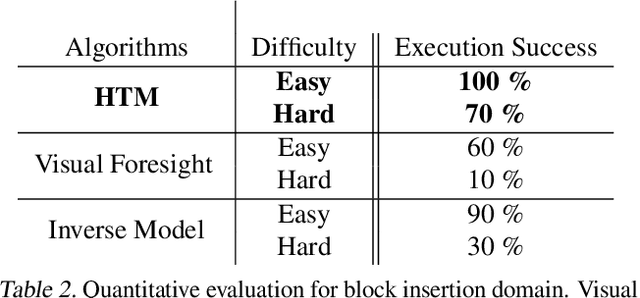
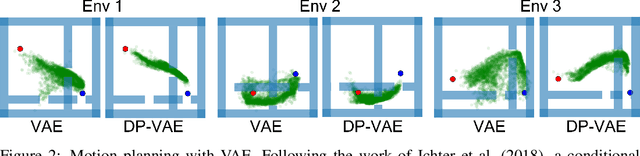
In visual planning (VP), an agent learns to plan goal-directed behavior from observations of a dynamical system obtained offline, e.g., images obtained from self-supervised robot interaction. Most previous works on VP approached the problem by planning in a learned latent space, resulting in low-quality visual plans, and difficult training algorithms. Here, instead, we propose a simple VP method that plans directly in image space and displays competitive performance. We build on the semi-parametric topological memory (SPTM) method: image samples are treated as nodes in a graph, the graph connectivity is learned from image sequence data, and planning can be performed using conventional graph search methods. We propose two modifications on SPTM. First, we train an energy-based graph connectivity function using contrastive predictive coding that admits stable training. Second, to allow zero-shot planning in new domains, we learn a conditional VAE model that generates images given a context of the domain, and use these hallucinated samples for building the connectivity graph and planning. We show that this simple approach significantly outperform the state-of-the-art VP methods, in terms of both plan interpretability and success rate when using the plan to guide a trajectory-following controller. Interestingly, our method can pick up non-trivial visual properties of objects, such as their geometry, and account for it in the plans.
Sub-Goal Trees -- a Framework for Goal-Based Reinforcement Learning
Feb 27, 2020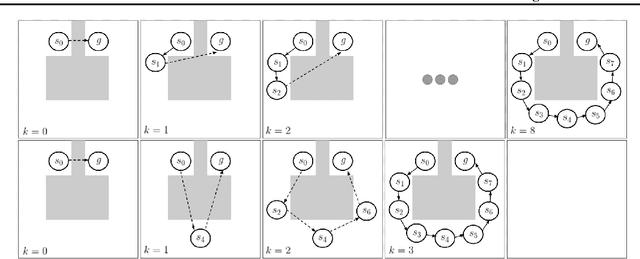
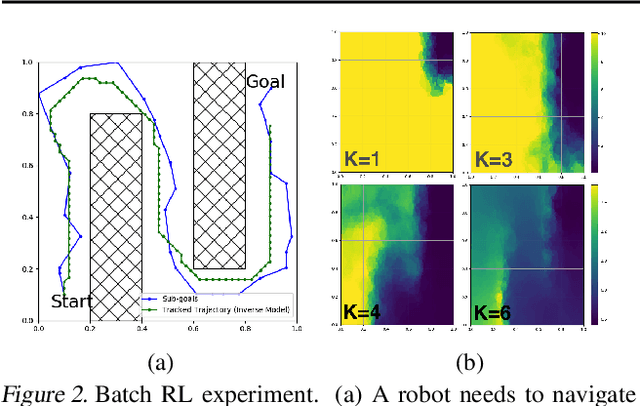
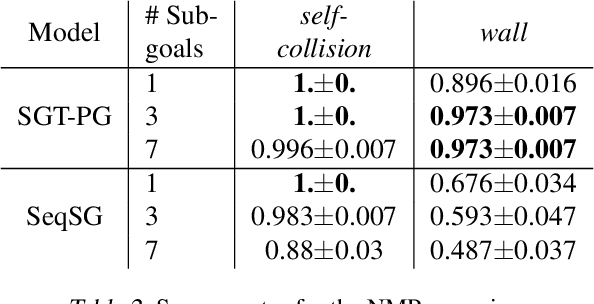
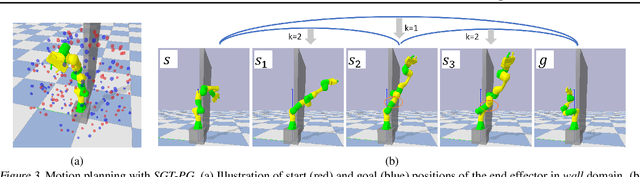
Many AI problems, in robotics and other domains, are goal-based, essentially seeking trajectories leading to various goal states. Reinforcement learning (RL), building on Bellman's optimality equation, naturally optimizes for a single goal, yet can be made multi-goal by augmenting the state with the goal. Instead, we propose a new RL framework, derived from a dynamic programming equation for the all pairs shortest path (APSP) problem, which naturally solves multi-goal queries. We show that this approach has computational benefits for both standard and approximate dynamic programming. Interestingly, our formulation prescribes a novel protocol for computing a trajectory: instead of predicting the next state given its predecessor, as in standard RL, a goal-conditioned trajectory is constructed by first predicting an intermediate state between start and goal, partitioning the trajectory into two. Then, recursively, predicting intermediate points on each sub-segment, until a complete trajectory is obtained. We call this trajectory structure a sub-goal tree. Building on it, we additionally extend the policy gradient methodology to recursively predict sub-goals, resulting in novel goal-based algorithms. Finally, we apply our method to neural motion planning, where we demonstrate significant improvements compared to standard RL on navigating a 7-DoF robot arm between obstacles.
Deep Residual Flow for Novelty Detection
Jan 15, 2020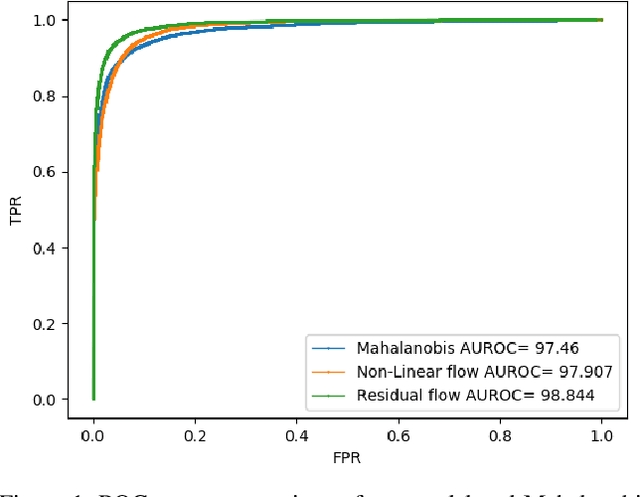
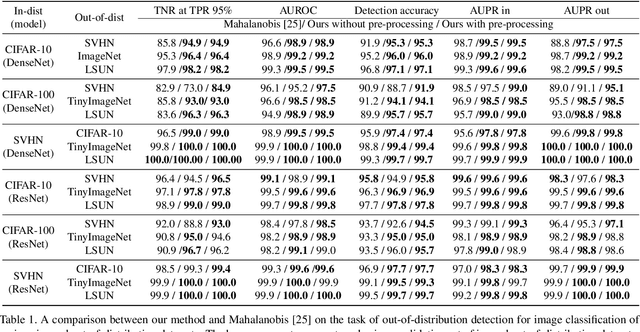
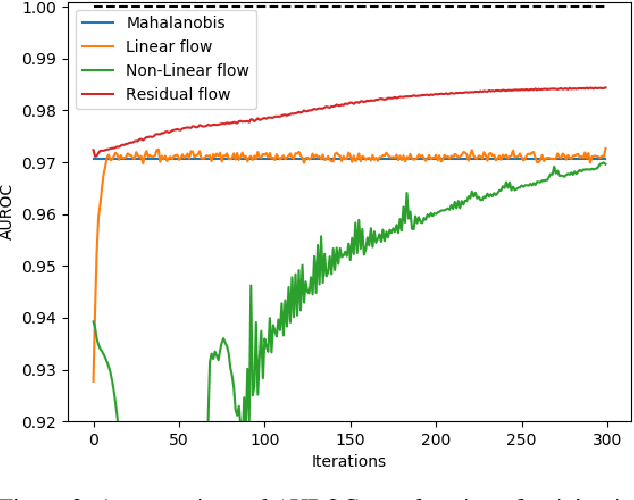
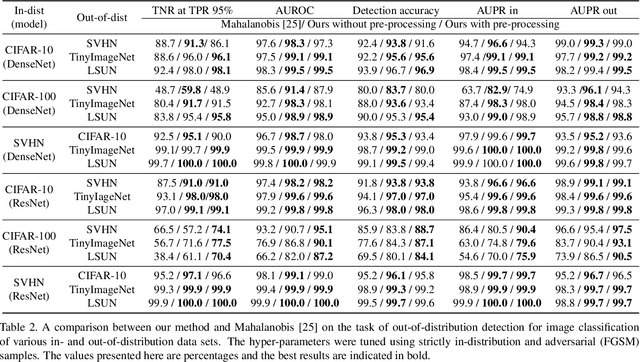
The effective application of neural networks in the real-world relies on proficiently detecting out-of-distribution examples. Contemporary methods seek to model the distribution of feature activations in the training data for adequately distinguishing abnormalities, and the state-of-the-art method uses Gaussian distribution models. In this work, we present a novel approach that improves upon the state-of-the-art by leveraging an expressive density model based on normalizing flows. We introduce the residual flow, a novel flow architecture that learns the residual distribution from a base Gaussian distribution. Our model is general, and can be applied to any data that is approximately Gaussian. For novelty detection in image datasets, our approach provides a principled improvement over the state-of-the-art. Specifically, we demonstrate the effectiveness of our method in ResNet and DenseNet architectures trained on various image datasets. For example, on a ResNet trained on CIFAR-100 and evaluated on detection of out-of-distribution samples from the ImageNet dataset, holding the true positive rate (TPR) at $95\%$, we improve the true negative rate (TNR) from $56.7\%$ (current state-of-the-art) to $77.5\%$ (ours).
Deep Variational Semi-Supervised Novelty Detection
Nov 12, 2019
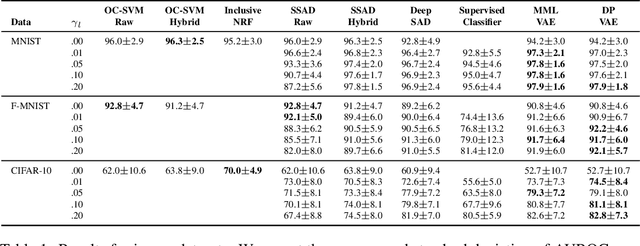

In anomaly detection (AD), one seeks to identify whether a test sample is abnormal, given a data set of normal samples. A recent and promising approach to AD relies on deep generative models, such as variational autoencoders (VAEs), for unsupervised learning of the normal data distribution. In semi-supervised AD (SSAD), the data also includes a small sample of labeled anomalies. In this work, we propose two variational methods for training VAEs for SSAD. The intuitive idea in both methods is to train the encoder to `separate' between latent vectors for normal and outlier data. We show that this idea can be derived from principled probabilistic formulations of the problem, and propose simple and effective algorithms. Our methods can be applied to various data types, as we demonstrate on SSAD datasets ranging from natural images to astronomy and medicine, and can be combined with any VAE model architecture. When comparing to state-of-the-art SSAD methods that are not specific to particular data types, we obtain marked improvement in outlier detection.
Bayesian Relational Memory for Semantic Visual Navigation
Sep 10, 2019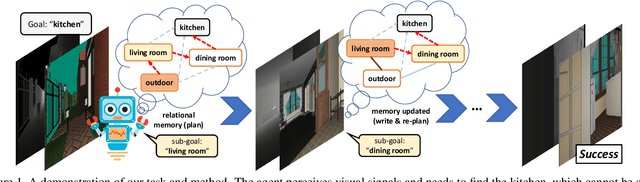
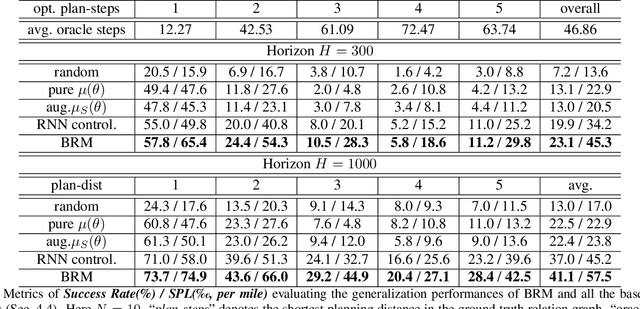
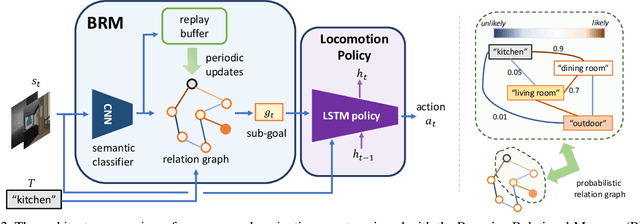
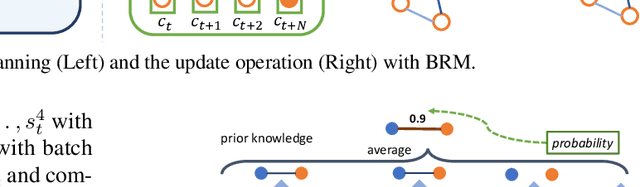
We introduce a new memory architecture, Bayesian Relational Memory (BRM), to improve the generalization ability for semantic visual navigation agents in unseen environments, where an agent is given a semantic target to navigate towards. BRM takes the form of a probabilistic relation graph over semantic entities (e.g., room types), which allows (1) capturing the layout prior from training environments, i.e., prior knowledge, (2) estimating posterior layout at test time, i.e., memory update, and (3) efficient planning for navigation, altogether. We develop a BRM agent consisting of a BRM module for producing sub-goals and a goal-conditioned locomotion module for control. When testing in unseen environments, the BRM agent outperforms baselines that do not explicitly utilize the probabilistic relational memory structure
Sub-Goal Trees -- a Framework for Goal-Directed Trajectory Prediction and Optimization
Jun 12, 2019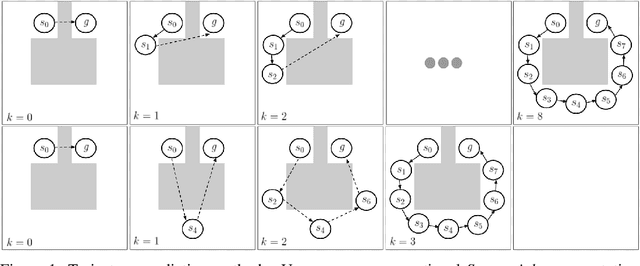
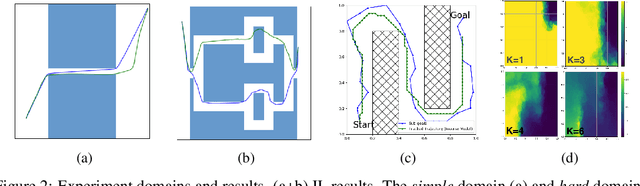

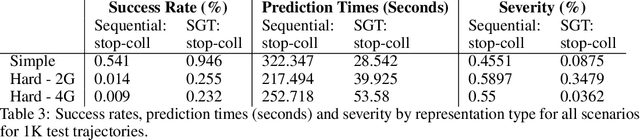
Many AI problems, in robotics and other domains, are goal-directed, essentially seeking a trajectory leading to some goal state. In such problems, the way we choose to represent a trajectory underlies algorithms for trajectory prediction and optimization. Interestingly, most all prior work in imitation and reinforcement learning builds on a sequential trajectory representation -- calculating the next state in the trajectory given its predecessors. We propose a different perspective: a goal-conditioned trajectory can be represented by first selecting an intermediate state between start and goal, partitioning the trajectory into two. Then, recursively, predicting intermediate points on each sub-segment, until a complete trajectory is obtained. We call this representation a sub-goal tree, and building on it, we develop new methods for trajectory prediction, learning, and optimization. We show that in a supervised learning setting, sub-goal trees better account for trajectory variability, and can predict trajectories exponentially faster at test time by leveraging a concurrent computation. Then, for optimization, we derive a new dynamic programming equation for sub-goal trees, and use it to develop new planning and reinforcement learning algorithms. These algorithms, which are not based on the standard Bellman equation, naturally account for hierarchical sub-goal structure in a task. Empirical results on motion planning domains show that the sub-goal tree framework significantly improves both accuracy and prediction time.
Harnessing Reinforcement Learning for Neural Motion Planning
Jun 01, 2019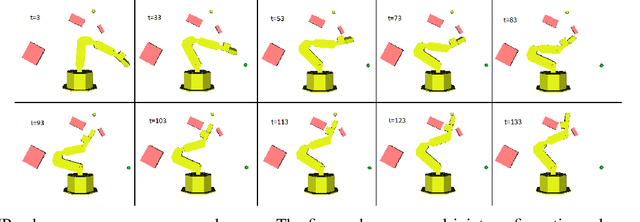

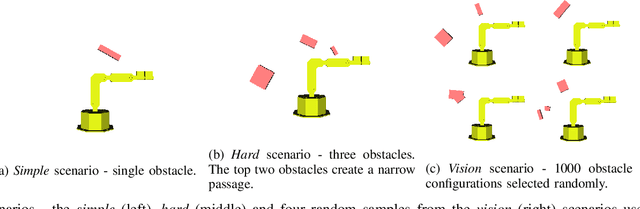
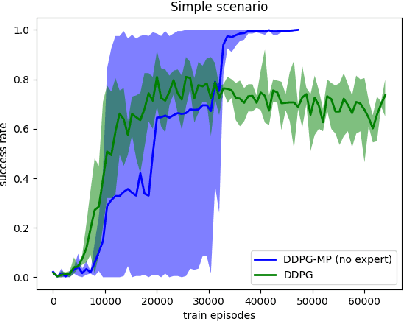
Motion planning is an essential component in most of today's robotic applications. In this work, we consider the learning setting, where a set of solved motion planning problems is used to improve the efficiency of motion planning on different, yet similar problems. This setting is important in applications with rapidly changing environments such as in e-commerce, among others. We investigate a general deep learning based approach, where a neural network is trained to map an image of the domain, the current robot state, and a goal robot state to the next robot state in the plan. We focus on the learning algorithm, and compare supervised learning methods with reinforcement learning (RL) algorithms. We first establish that supervised learning approaches are inferior in their accuracy due to insufficient data on the boundary of the obstacles, an issue that RL methods mitigate by actively exploring the domain. We then propose a modification of the popular DDPG RL algorithm that is tailored to motion planning domains, by exploiting the known model in the problem and the set of solved plans in the data. We show that our algorithm, dubbed DDPG-MP, significantly improves the accuracy of the learned motion planning policy. Finally, we show that given enough training data, our method can plan significantly faster on novel domains than off-the-shelf sampling based motion planners. Results of our experiments are shown in https://youtu.be/wHQ4Y4mBRb8.
Learning Robotic Manipulation through Visual Planning and Acting
May 11, 2019
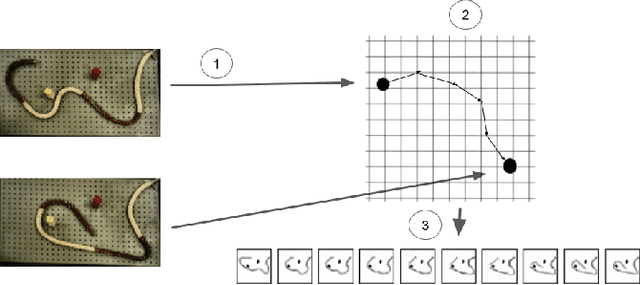
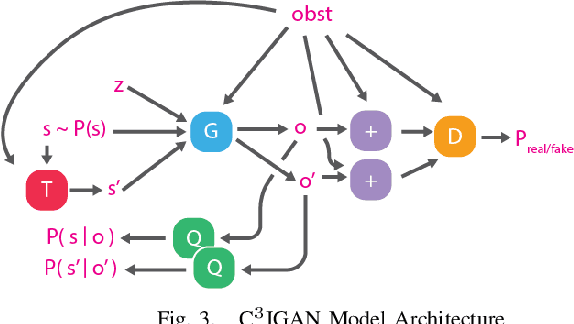
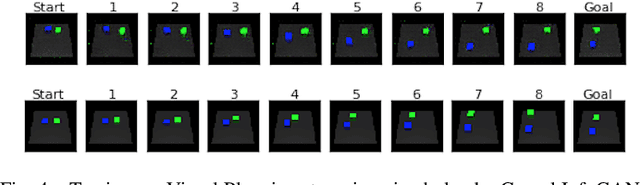
Planning for robotic manipulation requires reasoning about the changes a robot can affect on objects. When such interactions can be modelled analytically, as in domains with rigid objects, efficient planning algorithms exist. However, in both domestic and industrial domains, the objects of interest can be soft, or deformable, and hard to model analytically. For such cases, we posit that a data-driven modelling approach is more suitable. In recent years, progress in deep generative models has produced methods that learn to `imagine' plausible images from data. Building on the recent Causal InfoGAN generative model, in this work we learn to imagine goal-directed object manipulation directly from raw image data of self-supervised interaction of the robot with the object. After learning, given a goal observation of the system, our model can generate an imagined plan -- a sequence of images that transition the object into the desired goal. To execute the plan, we use it as a reference trajectory to track with a visual servoing controller, which we also learn from the data as an inverse dynamics model. In a simulated manipulation task, we show that separating the problem into visual planning and visual tracking control is more sample efficient and more interpretable than alternative data-driven approaches. We further demonstrate our approach on learning to imagine and execute in 3 environments, the final of which is deformable rope manipulation on a PR2 robot.
Reinforcement Learning on Variable Impedance Controller for High-Precision Robotic Assembly
Mar 20, 2019

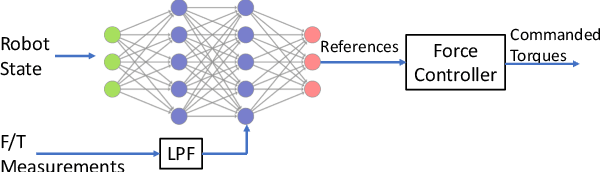

Precise robotic manipulation skills are desirable in many industrial settings, reinforcement learning (RL) methods hold the promise of acquiring these skills autonomously. In this paper, we explicitly consider incorporating operational space force/torque information into reinforcement learning; this is motivated by humans heuristically mapping perceived forces to control actions, which results in completing high-precision tasks in a fairly easy manner. Our approach combines RL with force/torque information by incorporating a proper operational space force controller; where we also exploit different ablations on processing this information. Moreover, we propose a neural network architecture that generalizes to reasonable variations of the environment. We evaluate our method on the open-source Siemens Robot Learning Challenge, which requires precise and delicate force-controlled behavior to assemble a tight-fit gear wheel set.
Domain Randomization for Active Pose Estimation
Mar 10, 2019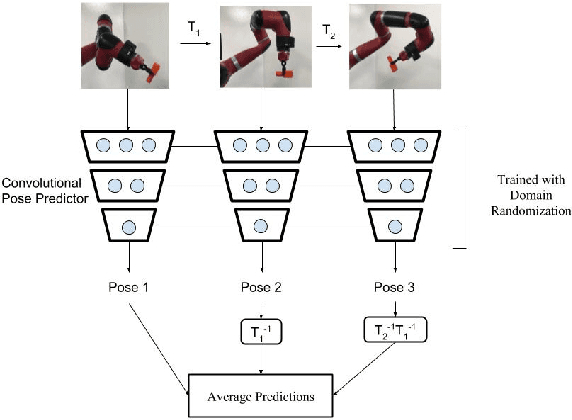



Accurate state estimation is a fundamental component of robotic control. In robotic manipulation tasks, as is our focus in this work, state estimation is essential for identifying the positions of objects in the scene, forming the basis of the manipulation plan. However, pose estimation typically requires expensive 3D cameras or additional instrumentation such as fiducial markers to perform accurately. Recently, Tobin et al.~introduced an approach to pose estimation based on domain randomization, where a neural network is trained to predict pose directly from a 2D image of the scene. The network is trained on computer-generated images with a high variation in textures and lighting, thereby generalizing to real-world images. In this work, we investigate how to improve the accuracy of domain randomization based pose estimation. Our main idea is that active perception -- moving the robot to get a better estimate of pose -- can be trained in simulation and transferred to real using domain randomization. In our approach, the robot trains in a domain-randomized simulation how to estimate pose from a \emph{sequence} of images. We show that our approach can significantly improve the accuracy of standard pose estimation in several scenarios: when the robot holding an object moves, when reference objects are moved in the scene, or when the camera is moved around the object.