 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-MoE: Towards Cross-Domain Generalization in 3D Semantic Segmentation via Mixture-of-Experts
May 29, 2025While scaling laws have transformed natural language processing and computer vision, 3D point cloud understanding has yet to reach that stage. This can be attributed to both the comparatively smaller scale of 3D datasets, as well as the disparate sources of the data itself. Point clouds are captured by diverse sensors (e.g., depth cameras, LiDAR) across varied domains (e.g., indoor, outdoor), each introducing unique scanning patterns, sampling densities, and semantic biases. Such domain heterogeneity poses a major barrier towards training unified models at scale, especially under the realistic constraint that domain labels are typically inaccessible at inference time. In this work, we propose Point-MoE, a Mixture-of-Experts architecture designed to enable large-scale, cross-domain generalization in 3D perception. We show that standard point cloud backbones degrade significantly in performance when trained on mixed-domain data, whereas Point-MoE with a simple top-k routing strategy can automatically specialize experts, even without access to domain labels. Our experiments demonstrate that Point-MoE not only outperforms strong multi-domain baselines but also generalizes better to unseen domains. This work highlights a scalable path forward for 3D understanding: letting the model discover structure in diverse 3D data, rather than imposing it via manual curation or domain supervision.
DocTr: Document Transformer for Structured Information Extraction in Documents
Jul 16, 2023We present a new formulation for structured information extraction (SIE) from visually rich documents. It aims to address the limitations of existing IOB tagging or graph-based formulations, which are either overly reliant on the correct ordering of input text or struggle with decoding a complex graph. Instead, motivated by anchor-based object detectors in vision, we represent an entity as an anchor word and a bounding box, and represent entity linking as the association between anchor words. This is more robust to text ordering, and maintains a compact graph for entity linking. The formulation motivates us to introduce 1) a DOCument TRansformer (DocTr) that aims at detecting and associating entity bounding boxes in visually rich documents, and 2) a simple pre-training strategy that helps learn entity detection in the context of language. Evaluations on three SIE benchmarks show the effectiveness of the proposed formulation, and the overall approach outperforms existing solutions.
SurFit: Learning to Fit Surfaces Improves Few Shot Learning on Point Clouds
Dec 27, 2021

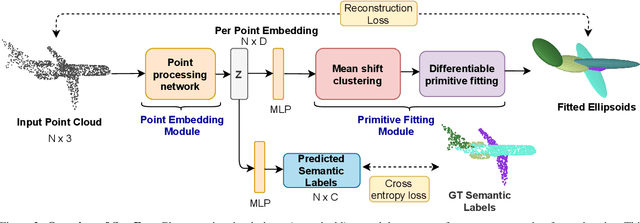
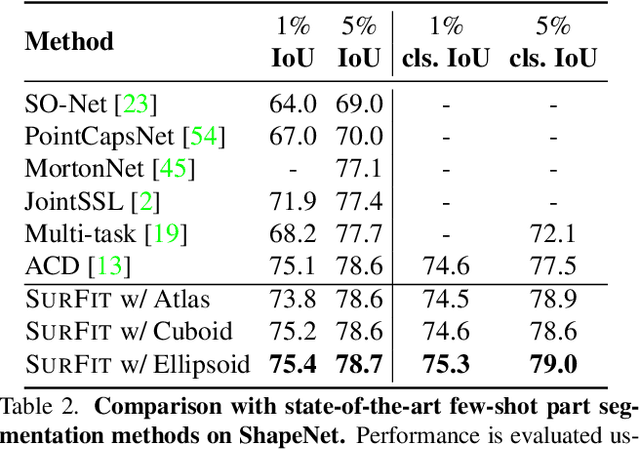
We present SurFit, a simple approach for label efficient learning of 3D shape segmentation networks. SurFit is based on a self-supervised task of decomposing the surface of a 3D shape into geometric primitives. It can be readily applied to existing network architectures for 3D shape segmentation and improves their performance in the few-shot setting, as we demonstrate in the widely used ShapeNet and PartNet benchmarks. SurFit outperforms the prior state-of-the-art in this setting, suggesting that decomposability into primitives is a useful prior for learning representations predictive of semantic parts. We present a number of experiments varying the choice of geometric primitives and downstream tasks to demonstrate the effectiveness of the method.
Improving Face Recognition by Clustering Unlabeled Faces in the Wild
Jul 15, 2020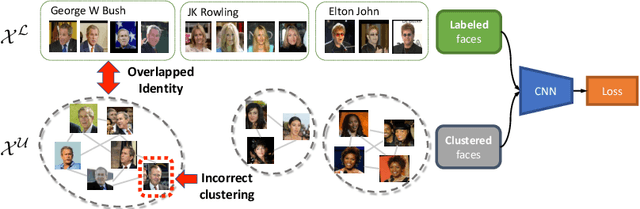
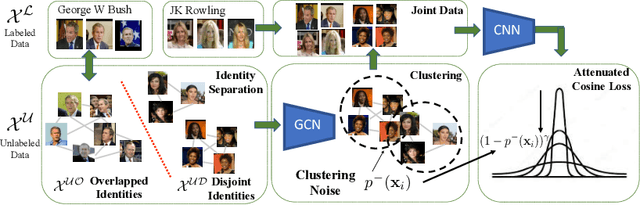
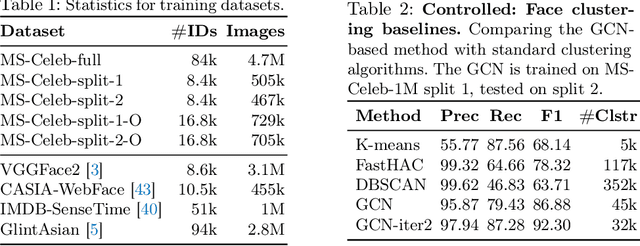
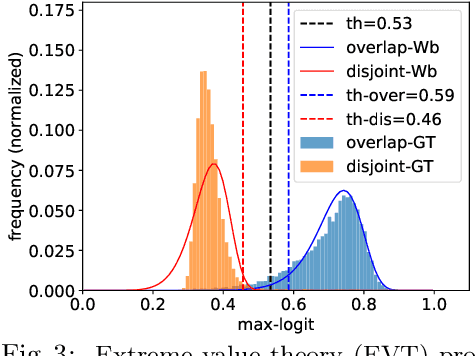
While deep face recognition has benefited significantly from large-scale labeled data, current research is focused on leveraging unlabeled data to further boost performance, reducing the cost of human annotation. Prior work has mostly been in controlled settings, where the labeled and unlabeled data sets have no overlapping identities by construction. This is not realistic in large-scale face recognition, where one must contend with such overlaps, the frequency of which increases with the volume of data. Ignoring identity overlap leads to significant labeling noise, as data from the same identity is split into multiple clusters. To address this, we propose a novel identity separation method based on extreme value theory. It is formulated as an out-of-distribution detection algorithm, and greatly reduces the problems caused by overlapping-identity label noise. Considering cluster assignments as pseudo-labels, we must also overcome the labeling noise from clustering errors. We propose a modulation of the cosine loss, where the modulation weights correspond to an estimate of clustering uncertainty. Extensive experiments on both controlled and real settings demonstrate our method's consistent improvements over supervised baselines, e.g., 11.6% improvement on IJB-A verification.
Label-Efficient Learning on Point Clouds using Approximate Convex Decompositions
Mar 30, 2020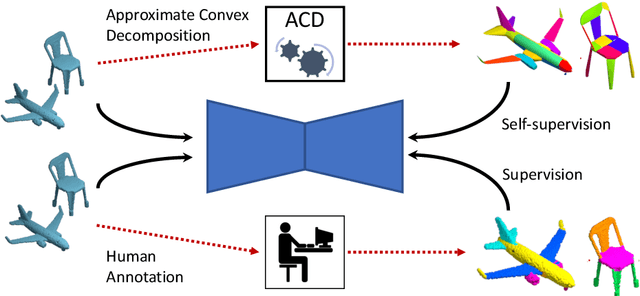
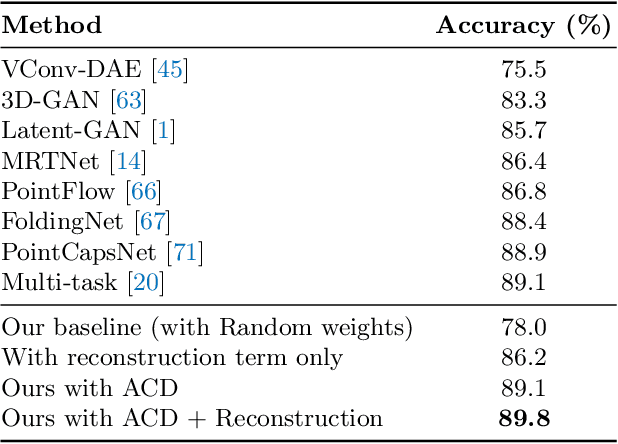


The problems of shape classification and part segmentation from 3D point clouds have garnered increasing attention in the last few years. But both of these problems suffer from relatively small training sets, creating the need for statistically efficient methods to learn 3D shape representations. In this work, we investigate the use of Approximate Convex Decompositions (ACD) as a self-supervisory signal for label-efficient learning of point cloud representations. Decomposing a 3D shape into simpler constituent parts or primitives is a fundamental problem in geometrical shape processing. There has been extensive work on such decompositions, where the criterion for simplicity of a constituent shape is often defined in terms of convexity for solid primitives. In this paper, we show that using the results of ACD to approximate a ground truth segmentation provides excellent self-supervision for learning 3D point cloud representations that are highly effective on downstream tasks. We report improvements over the state-of-theart in unsupervised representation learning on the ModelNet40 shape classification dataset and significant gains in few-shot part segmentation on the ShapeNetPart dataset. Code available at https://github.com/matheusgadelha/PointCloudLearningACD
Automatic adaptation of object detectors to new domains using self-training
Apr 15, 2019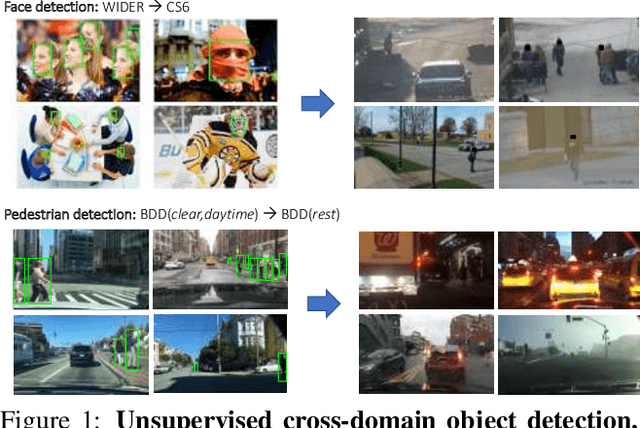
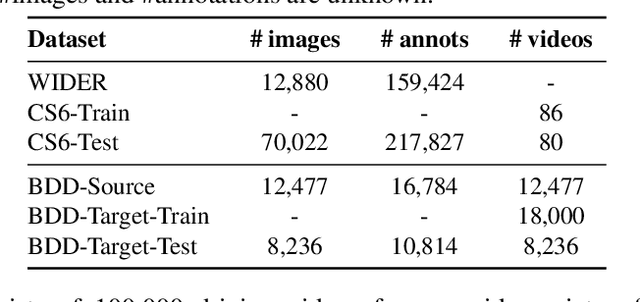

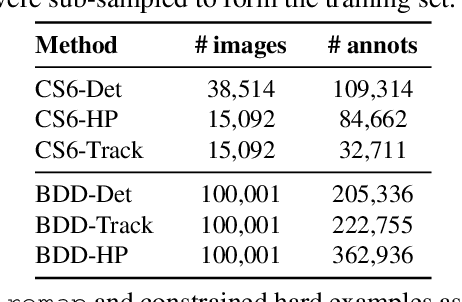
This work addresses the unsupervised adaptation of an existing object detector to a new target domain. We assume that a large number of unlabeled videos from this domain are readily available. We automatically obtain labels on the target data by using high-confidence detections from the existing detector, augmented with hard (misclassified) examples acquired by exploiting temporal cues using a tracker. These automatically-obtained labels are then used for re-training the original model. A modified knowledge distillation loss is proposed, and we investigate several ways of assigning soft-labels to the training examples from the target domain. Our approach is empirically evaluated on challenging face and pedestrian detection tasks: a face detector trained on WIDER-Face, which consists of high-quality images crawled from the web, is adapted to a large-scale surveillance data set; a pedestrian detector trained on clear, daytime images from the BDD-100K driving data set is adapted to all other scenarios such as rainy, foggy, night-time. Our results demonstrate the usefulness of incorporating hard examples obtained from tracking, the advantage of using soft-labels via distillation loss versus hard-labels, and show promising performance as a simple method for unsupervised domain adaptation of object detectors, with minimal dependence on hyper-parameters.
Unsupervised Hard Example Mining from Videos for Improved Object Detection
Aug 13, 2018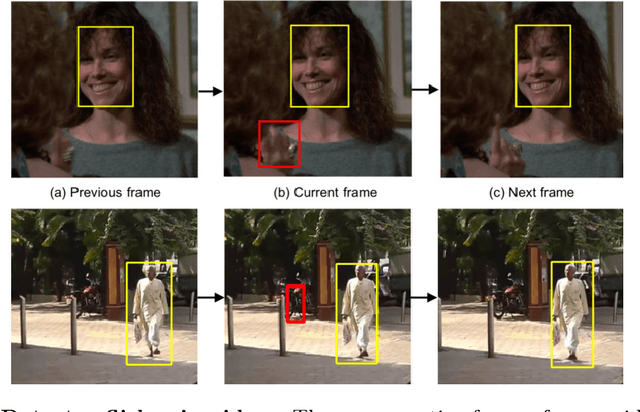


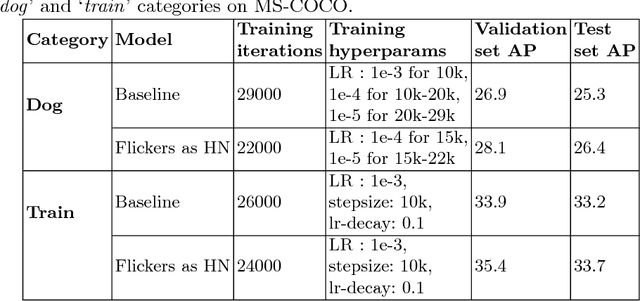
Important gains have recently been obtained in object detection by using training objectives that focus on {\em hard negative} examples, i.e., negative examples that are currently rated as positive or ambiguous by the detector. These examples can strongly influence parameters when the network is trained to correct them. Unfortunately, they are often sparse in the training data, and are expensive to obtain. In this work, we show how large numbers of hard negatives can be obtained {\em automatically} by analyzing the output of a trained detector on video sequences. In particular, detections that are {\em isolated in time}, i.e., that have no associated preceding or following detections, are likely to be hard negatives. We describe simple procedures for mining large numbers of such hard negatives (and also hard {\em positives}) from unlabeled video data. Our experiments show that retraining detectors on these automatically obtained examples often significantly improves performance. We present experiments on multiple architectures and multiple data sets, including face detection, pedestrian detection and other object categories.
Bilinear CNNs for Fine-grained Visual Recognition
Jun 01, 2017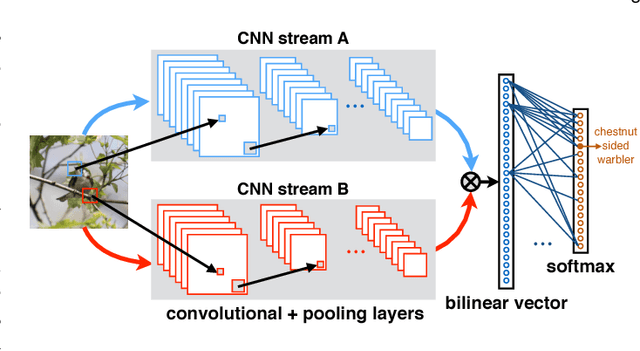
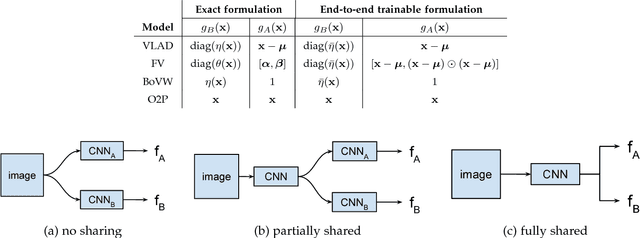
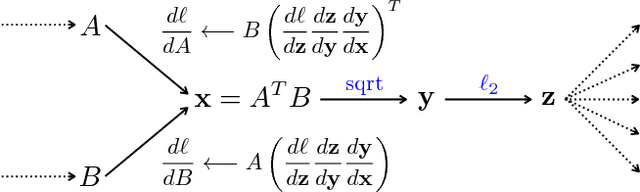
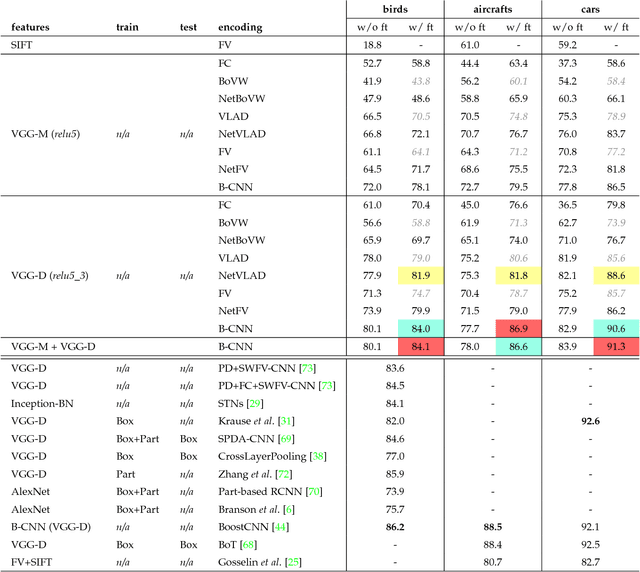
We present a simple and effective architecture for fine-grained visual recognition called Bilinear Convolutional Neural Networks (B-CNNs). These networks represent an image as a pooled outer product of features derived from two CNNs and capture localized feature interactions in a translationally invariant manner. B-CNNs belong to the class of orderless texture representations but unlike prior work they can be trained in an end-to-end manner. Our most accurate model obtains 84.1%, 79.4%, 86.9% and 91.3% per-image accuracy on the Caltech-UCSD birds [67], NABirds [64], FGVC aircraft [42], and Stanford cars [33] dataset respectively and runs at 30 frames-per-second on a NVIDIA Titan X GPU. We then present a systematic analysis of these networks and show that (1) the bilinear features are highly redundant and can be reduced by an order of magnitude in size without significant loss in accuracy, (2) are also effective for other image classification tasks such as texture and scene recognition, and (3) can be trained from scratch on the ImageNet dataset offering consistent improvements over the baseline architecture. Finally, we present visualizations of these models on various datasets using top activations of neural units and gradient-based inversion techniques. The source code for the complete system is available at http://vis-www.cs.umass.edu/bcnn.
One-to-many face recognition with bilinear CNNs
Mar 28, 2016
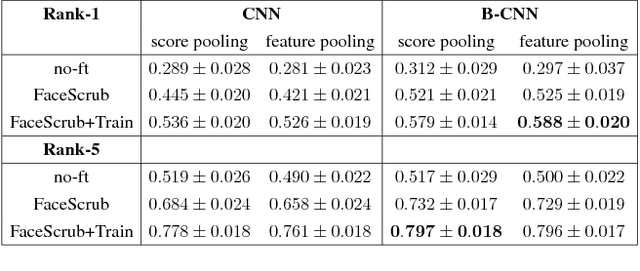

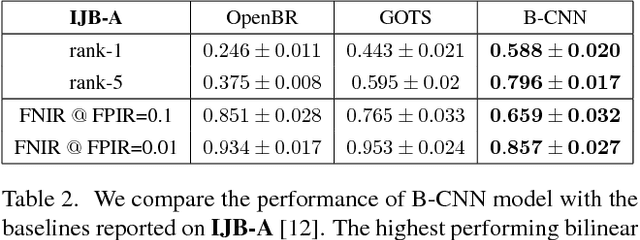
The recent explosive growth in convolutional neural network (CNN) research has produced a variety of new architectures for deep learning. One intriguing new architecture is the bilinear CNN (B-CNN), which has shown dramatic performance gains on certain fine-grained recognition problems [15]. We apply this new CNN to the challenging new face recognition benchmark, the IARPA Janus Benchmark A (IJB-A) [12]. It features faces from a large number of identities in challenging real-world conditions. Because the face images were not identified automatically using a computerized face detection system, it does not have the bias inherent in such a database. We demonstrate the performance of the B-CNN model beginning from an AlexNet-style network pre-trained on ImageNet. We then show results for fine-tuning using a moderate-sized and public external database, FaceScrub [17]. We also present results with additional fine-tuning on the limited training data provided by the protocol. In each case, the fine-tuned bilinear model shows substantial improvements over the standard CNN. Finally, we demonstrate how a standard CNN pre-trained on a large face database, the recently released VGG-Face model [20], can be converted into a B-CNN without any additional feature training. This B-CNN improves upon the CNN performance on the IJB-A benchmark, achieving 89.5% rank-1 recall.