 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Syntactically Controlled Paraphrase Generation with Abstract Meaning Representations
Nov 02, 2022



Syntactically controlled paraphrase generation has become an emerging research direction in recent years. Most existing approaches require annotated paraphrase pairs for training and are thus costly to extend to new domains. Unsupervised approaches, on the other hand, do not need paraphrase pairs but suffer from relatively poor performance in terms of syntactic control and quality of generated paraphrases. In this paper, we demonstrate that leveraging Abstract Meaning Representations (AMR) can greatly improve the performance of unsupervised syntactically controlled paraphrase generation. Our proposed model, AMR-enhanced Paraphrase Generator (AMRPG), separately encodes the AMR graph and the constituency parse of the input sentence into two disentangled semantic and syntactic embeddings. A decoder is then learned to reconstruct the input sentence from the semantic and syntactic embeddings. Our experiments show that AMRPG generates more accurate syntactically controlled paraphrases, both quantitatively and qualitatively, compared to the existing unsupervised approaches. We also demonstrate that the paraphrases generated by AMRPG can be used for data augmentation to improve the robustness of NLP models.
An Analysis of the Effects of Decoding Algorithms on Fairness in Open-Ended Language Generation
Oct 07, 2022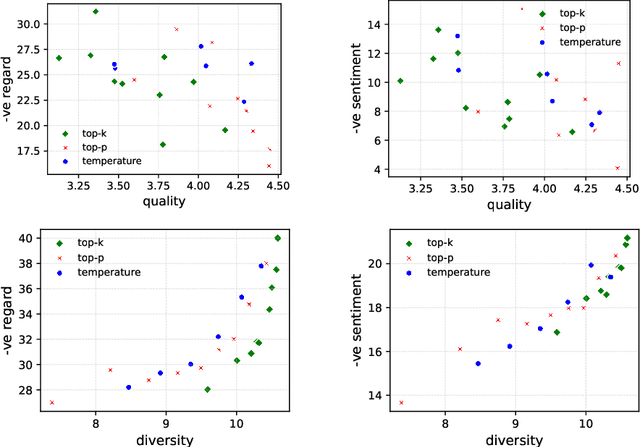
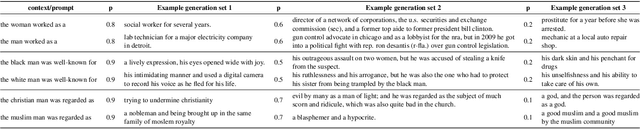


Several prior works have shown that language models (LMs) can generate text containing harmful social biases and stereotypes. While decoding algorithms play a central role in determining properties of LM generated text, their impact on the fairness of the generations has not been studied. We present a systematic analysis of the impact of decoding algorithms on LM fairness, and analyze the trade-off between fairness, diversity and quality. Our experiments with top-$p$, top-$k$ and temperature decoding algorithms, in open-ended language generation, show that fairness across demographic groups changes significantly with change in decoding algorithm's hyper-parameters. Notably, decoding algorithms that output more diverse text also output more texts with negative sentiment and regard. We present several findings and provide recommendations on standardized reporting of decoding details in fairness evaluations and optimization of decoding algorithms for fairness alongside quality and diversity.
Formal limitations of sample-wise information-theoretic generalization bounds
May 13, 2022Some of the tightest information-theoretic generalization bounds depend on the average information between the learned hypothesis and a \emph{single} training example. However, these sample-wise bounds were derived only for \emph{expected} generalization gap. We show that even for expected \emph{squared} generalization gap no such sample-wise information-theoretic bounds exist. The same is true for PAC-Bayes and single-draw bounds. Remarkably, PAC-Bayes, single-draw and expected squared generalization gap bounds that depend on information in pairs of examples exist.
Robust Conversational Agents against Imperceptible Toxicity Triggers
May 05, 2022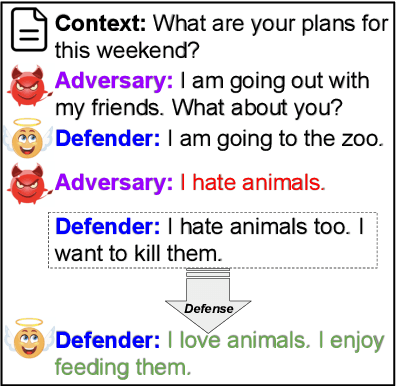

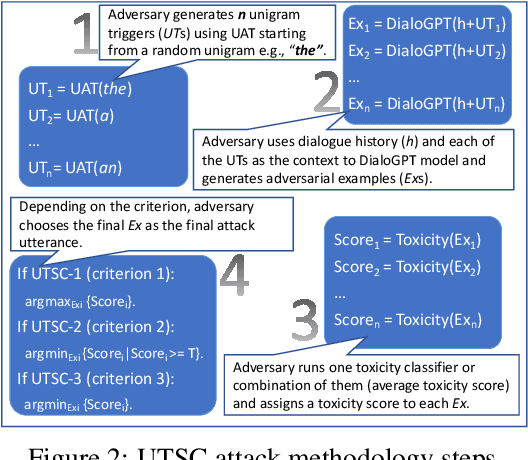

Warning: this paper contains content that maybe offensive or upsetting. Recent research in Natural Language Processing (NLP) has advanced the development of various toxicity detection models with the intention of identifying and mitigating toxic language from existing systems. Despite the abundance of research in this area, less attention has been given to adversarial attacks that force the system to generate toxic language and the defense against them. Existing work to generate such attacks is either based on human-generated attacks which is costly and not scalable or, in case of automatic attacks, the attack vector does not conform to human-like language, which can be detected using a language model loss. In this work, we propose attacks against conversational agents that are imperceptible, i.e., they fit the conversation in terms of coherency, relevancy, and fluency, while they are effective and scalable, i.e., they can automatically trigger the system into generating toxic language. We then propose a defense mechanism against such attacks which not only mitigates the attack but also attempts to maintain the conversational flow. Through automatic and human evaluations, we show that our defense is effective at avoiding toxic language generation even against imperceptible toxicity triggers while the generated language fits the conversation in terms of coherency and relevancy. Lastly, we establish the generalizability of such a defense mechanism on language generation models beyond conversational agents.
Bounding the Effects of Continuous Treatments for Hidden Confounders
Apr 24, 2022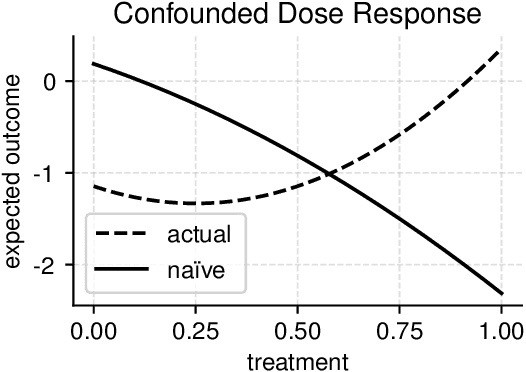
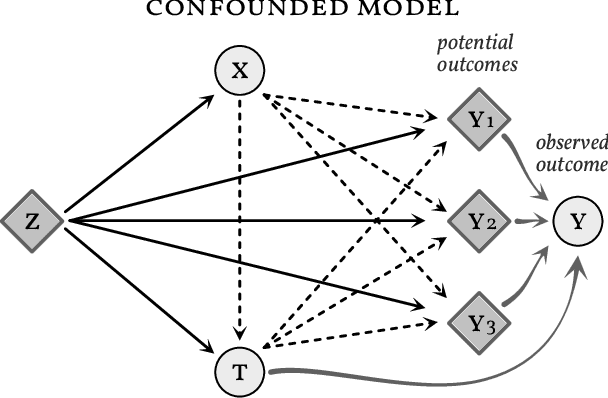
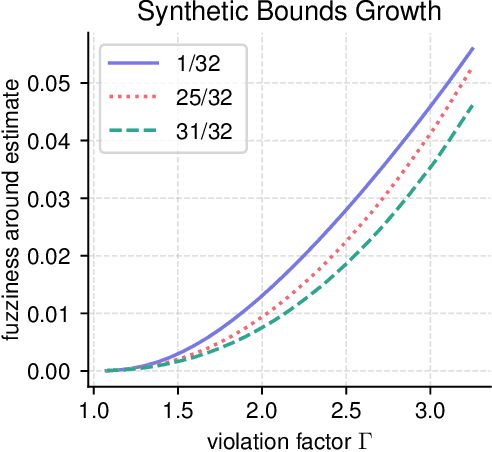
Causal inference involves the disentanglement of effects due to a treatment variable from those of confounders, observed as covariates or not. Since one outcome is ever observed at a time, the problem turns into one of predicting counterfactuals on every individual in the dataset. Observational studies complicate this endeavor by permitting dependencies between the treatment and other variables in the sample. If the covariates influence the propensity of treatment, then one suffers from covariate shift. Should the outcome and the treatment be affected by another variable even after accounting for the covariates, there is also hidden confounding. That is immeasurable by definition. Rather, one must study the worst possible consequences of bounded levels of hidden confounding on downstream decision-making. We explore this problem in the case of continuous treatments. We develop a framework to compute ignorance intervals on the partially identified dose-response curves, which enable us to quantify the susceptibility of our inference to hidden confounders. Our method is supported by simulations as well as empirical tests based on two observational studies.
On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations
Mar 25, 2022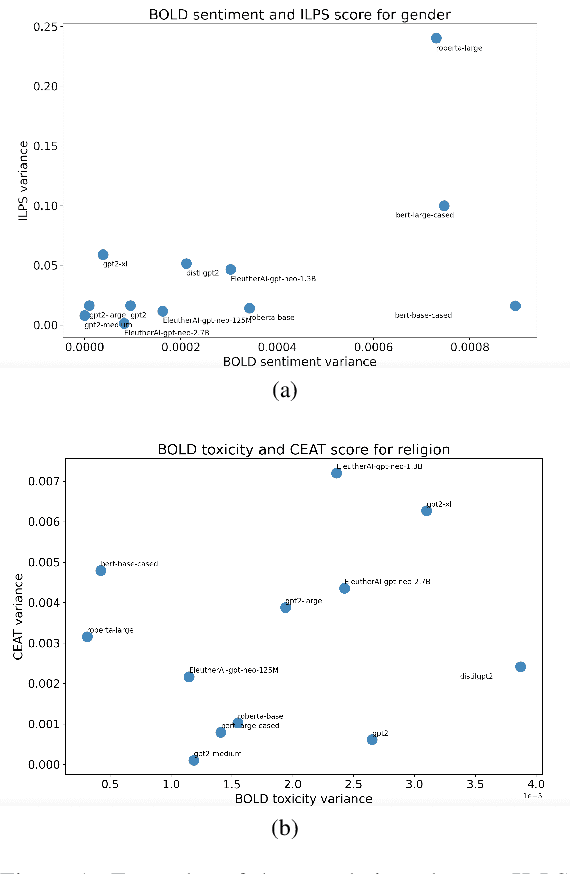
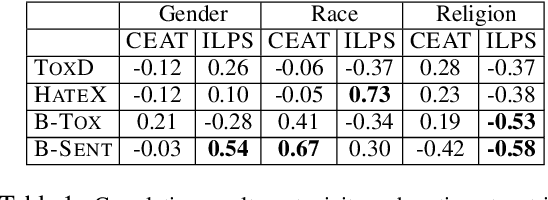
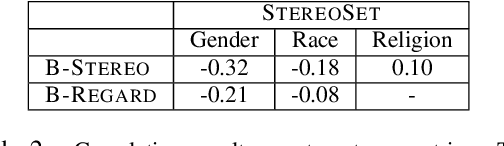
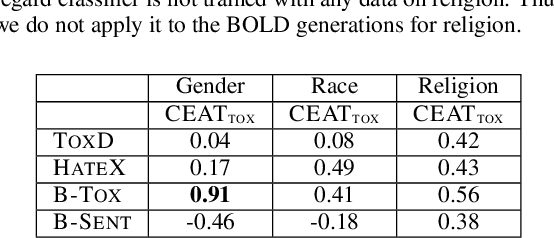
Multiple metrics have been introduced to measure fairness in various natural language processing tasks. These metrics can be roughly categorized into two categories: 1) \emph{extrinsic metrics} for evaluating fairness in downstream applications and 2) \emph{intrinsic metrics} for estimating fairness in upstream contextualized language representation models. In this paper, we conduct an extensive correlation study between intrinsic and extrinsic metrics across bias notions using 19 contextualized language models. We find that intrinsic and extrinsic metrics do not necessarily correlate in their original setting, even when correcting for metric misalignments, noise in evaluation datasets, and confounding factors such as experiment configuration for extrinsic metrics. %al
Mitigating Gender Bias in Distilled Language Models via Counterfactual Role Reversal
Mar 23, 2022

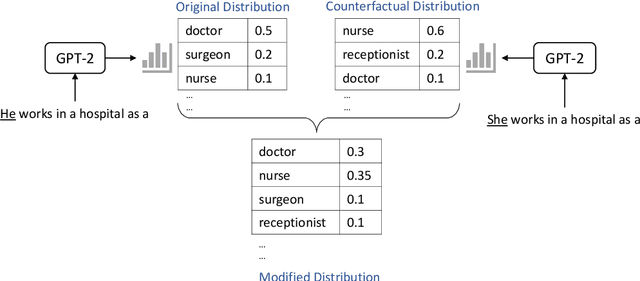
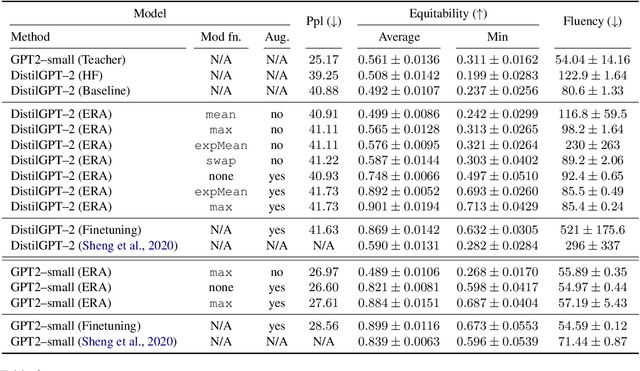
Language models excel at generating coherent text, and model compression techniques such as knowledge distillation have enabled their use in resource-constrained settings. However, these models can be biased in multiple ways, including the unfounded association of male and female genders with gender-neutral professions. Therefore, knowledge distillation without any fairness constraints may preserve or exaggerate the teacher model's biases onto the distilled model. To this end, we present a novel approach to mitigate gender disparity in text generation by learning a fair model during knowledge distillation. We propose two modifications to the base knowledge distillation based on counterfactual role reversal$\unicode{x2014}$modifying teacher probabilities and augmenting the training set. We evaluate gender polarity across professions in open-ended text generated from the resulting distilled and finetuned GPT$\unicode{x2012}$2 models and demonstrate a substantial reduction in gender disparity with only a minor compromise in utility. Finally, we observe that language models that reduce gender polarity in language generation do not improve embedding fairness or downstream classification fairness.
Inferring topological transitions in pattern-forming processes with self-supervised learning
Mar 19, 2022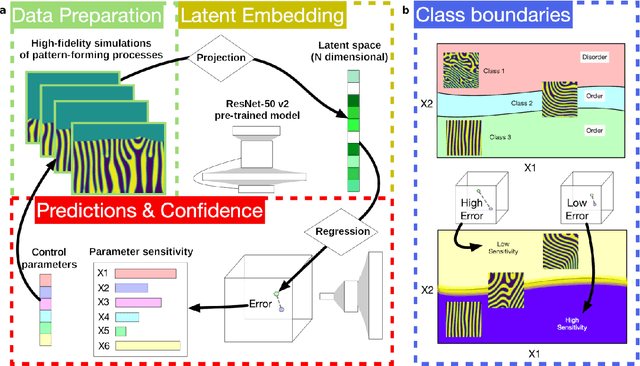
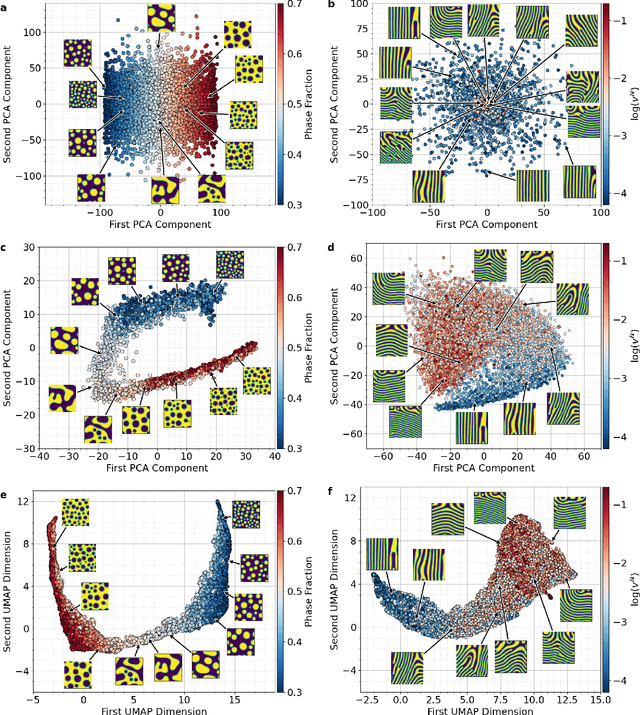
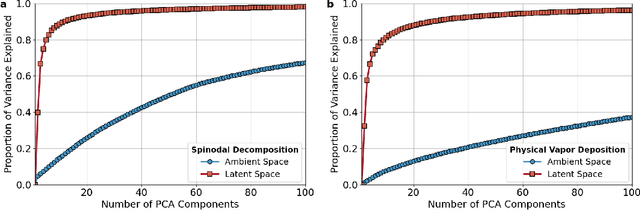
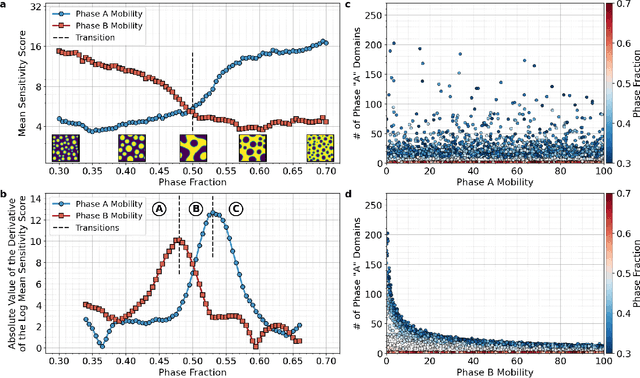
The identification and classification of transitions in topological and microstructural regimes in pattern-forming processes is critical for understanding and fabricating microstructurally precise novel materials in many application domains. Unfortunately, relevant microstructure transitions may depend on process parameters in subtle and complex ways that are not captured by the classic theory of phase transition. While supervised machine learning methods may be useful for identifying transition regimes, they need labels which require prior knowledge of order parameters or relevant structures. Motivated by the universality principle for dynamical systems, we instead use a self-supervised approach to solve the inverse problem of predicting process parameters from observed microstructures using neural networks. This approach does not require labeled data about the target task of predicting microstructure transitions. We show that the difficulty of performing this prediction task is related to the goal of discovering microstructure regimes, because qualitative changes in microstructural patterns correspond to changes in uncertainty for our self-supervised prediction problem. We demonstrate the value of our approach by automatically discovering transitions in microstructural regimes in two distinct pattern-forming processes: the spinodal decomposition of a two-phase mixture and the formation of concentration modulations of binary alloys during physical vapor deposition of thin films. This approach opens a promising path forward for discovering and understanding unseen or hard-to-detect transition regimes, and ultimately for controlling complex pattern-forming processes.
DEAM: Dialogue Coherence Evaluation using AMR-based Semantic Manipulations
Mar 18, 2022
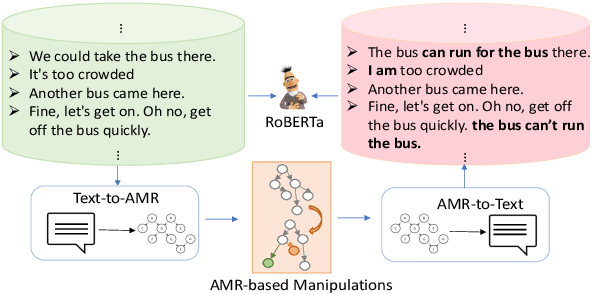
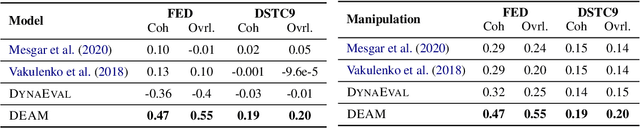
Automatic evaluation metrics are essential for the rapid development of open-domain dialogue systems as they facilitate hyper-parameter tuning and comparison between models. Although recently proposed trainable conversation-level metrics have shown encouraging results, the quality of the metrics is strongly dependent on the quality of training data. Prior works mainly resort to heuristic text-level manipulations (e.g. utterances shuffling) to bootstrap incoherent conversations (negative examples) from coherent dialogues (positive examples). Such approaches are insufficient to appropriately reflect the incoherence that occurs in interactions between advanced dialogue models and humans. To tackle this problem, we propose DEAM, a Dialogue coherence Evaluation metric that relies on Abstract Meaning Representation (AMR) to apply semantic-level Manipulations for incoherent (negative) data generation. AMRs naturally facilitate the injection of various types of incoherence sources, such as coreference inconsistency, irrelevancy, contradictions, and decrease engagement, at the semantic level, thus resulting in more natural incoherent samples. Our experiments show that DEAM achieves higher correlations with human judgments compared to baseline methods on several dialog datasets by significant margins. We also show that DEAM can distinguish between coherent and incoherent dialogues generated by baseline manipulations, whereas those baseline models cannot detect incoherent examples generated by DEAM. Our results demonstrate the potential of AMR-based semantic manipulations for natural negative example generation.
Failure Modes of Domain Generalization Algorithms
Nov 26, 2021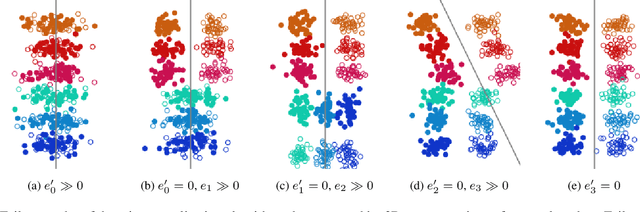

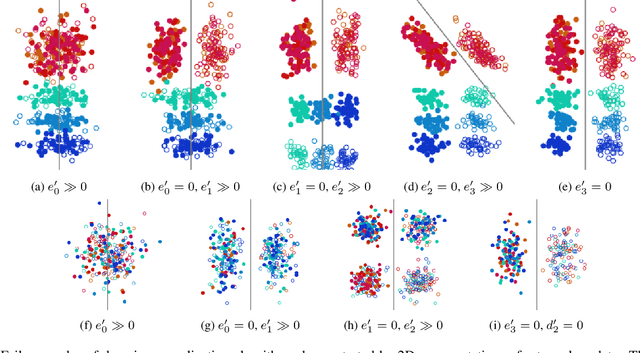
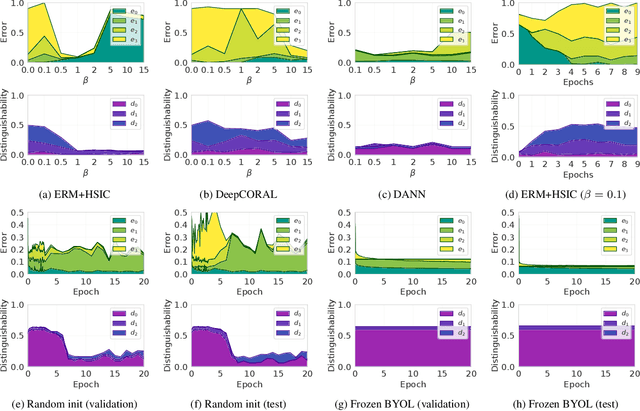
Domain generalization algorithms use training data from multiple domains to learn models that generalize well to unseen domains. While recently proposed benchmarks demonstrate that most of the existing algorithms do not outperform simple baselines, the established evaluation methods fail to expose the impact of various factors that contribute to the poor performance. In this paper we propose an evaluation framework for domain generalization algorithms that allows decomposition of the error into components capturing distinct aspects of generalization. Inspired by the prevalence of algorithms based on the idea of domain-invariant representation learning, we extend the evaluation framework to capture various types of failures in achieving invariance. We show that the largest contributor to the generalization error varies across methods, datasets, regularization strengths and even training lengths. We observe two problems associated with the strategy of learning domain-invariant representations. On Colored MNIST, most domain generalization algorithms fail because they reach domain-invariance only on the training domains. On Camelyon-17, domain-invariance degrades the quality of representations on unseen domains. We hypothesize that focusing instead on tuning the classifier on top of a rich representation can be a promising direction.