 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLawyers are Dishonest? Quantifying Representational Harms in Commonsense Knowledge Resources
Paper and Code


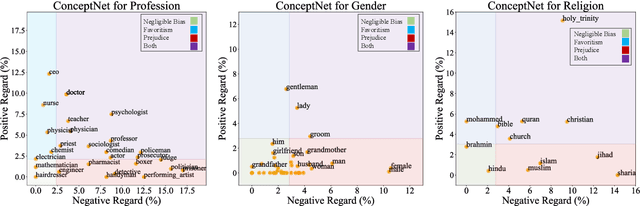

Warning: this paper contains content that may be offensive or upsetting. Numerous natural language processing models have tried injecting commonsense by using the ConceptNet knowledge base to improve performance on different tasks. ConceptNet, however, is mostly crowdsourced from humans and may reflect human biases such as "lawyers are dishonest." It is important that these biases are not conflated with the notion of commonsense. We study this missing yet important problem by first defining and quantifying biases in ConceptNet as two types of representational harms: overgeneralization of polarized perceptions and representation disparity. We find that ConceptNet contains severe biases and disparities across four demographic categories. In addition, we analyze two downstream models that use ConceptNet as a source for commonsense knowledge and find the existence of biases in those models as well. We further propose a filtered-based bias-mitigation approach and examine its effectiveness. We show that our mitigation approach can reduce the issues in both resource and models but leads to a performance drop, leaving room for future work to build fairer and stronger commonsense models.