 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynchronization is All You Need: Exocentric-to-Egocentric Transfer for Temporal Action Segmentation with Unlabeled Synchronized Video Pairs
Dec 05, 2023



We consider the problem of transferring a temporal action segmentation system initially designed for exocentric (fixed) cameras to an egocentric scenario, where wearable cameras capture video data. The conventional supervised approach requires the collection and labeling of a new set of egocentric videos to adapt the model, which is costly and time-consuming. Instead, we propose a novel methodology which performs the adaptation leveraging existing labeled exocentric videos and a new set of unlabeled, synchronized exocentric-egocentric video pairs, for which temporal action segmentation annotations do not need to be collected. We implement the proposed methodology with an approach based on knowledge distillation, which we investigate both at the feature and model level. To evaluate our approach, we introduce a new benchmark based on the Assembly101 dataset. Results demonstrate the feasibility and effectiveness of the proposed method against classic unsupervised domain adaptation and temporal sequence alignment approaches. Remarkably, without bells and whistles, our best model performs on par with supervised approaches trained on labeled egocentric data, without ever seeing a single egocentric label, achieving a +15.99% (28.59% vs 12.60%) improvement in the edit score on the Assembly101 dataset compared to a baseline model trained solely on exocentric data.
Are Synthetic Data Useful for Egocentric Hand-Object Interaction Detection? An Investigation and the HOI-Synth Domain Adaptation Benchmark
Dec 05, 2023In this study, we investigate the effectiveness of synthetic data in enhancing hand-object interaction detection within the egocentric vision domain. We introduce a simulator able to generate synthetic images of hand-object interactions automatically labeled with hand-object contact states, bounding boxes, and pixel-wise segmentation masks. Through comprehensive experiments and comparative analyses on three egocentric datasets, VISOR, EgoHOS, and ENIGMA-51, we demonstrate that the use of synthetic data and domain adaptation techniques allows for comparable performance to conventional supervised methods while requiring annotations on only a fraction of the real data. When tested with in-domain synthetic data generated from 3D models of real target environments and objects, our best models show consistent performance improvements with respect to standard fully supervised approaches based on labeled real data only. Our study also sets a new benchmark of domain adaptation for egocentric hand-object interaction detection (HOI-Synth) and provides baseline results to encourage the community to engage in this challenging task. We release the generated data, code, and the simulator at the following link: https://iplab.dmi.unict.it/HOI-Synth/.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
ENIGMA-51: Towards a Fine-Grained Understanding of Human-Object Interactions in Industrial Scenarios
Sep 26, 2023ENIGMA-51 is a new egocentric dataset acquired in a real industrial domain by 19 subjects who followed instructions to complete the repair of electrical boards using industrial tools (e.g., electric screwdriver) and electronic instruments (e.g., oscilloscope). The 51 sequences are densely annotated with a rich set of labels that enable the systematic study of human-object interactions in the industrial domain. We provide benchmarks on four tasks related to human-object interactions: 1) untrimmed action detection, 2) egocentric human-object interaction detection, 3) short-term object interaction anticipation and 4) natural language understanding of intents and entities. Baseline results show that the ENIGMA-51 dataset poses a challenging benchmark to study human-object interactions in industrial scenarios. We publicly release the dataset at: https://iplab.dmi.unict.it/ENIGMA-51/.
An Outlook into the Future of Egocentric Vision
Aug 14, 2023



What will the future be? We wonder! In this survey, we explore the gap between current research in egocentric vision and the ever-anticipated future, where wearable computing, with outward facing cameras and digital overlays, is expected to be integrated in our every day lives. To understand this gap, the article starts by envisaging the future through character-based stories, showcasing through examples the limitations of current technology. We then provide a mapping between this future and previously defined research tasks. For each task, we survey its seminal works, current state-of-the-art methodologies and available datasets, then reflect on shortcomings that limit its applicability to future research. Note that this survey focuses on software models for egocentric vision, independent of any specific hardware. The paper concludes with recommendations for areas of immediate explorations so as to unlock our path to the future always-on, personalised and life-enhancing egocentric vision.
Streaming egocentric action anticipation: An evaluation scheme and approach
Jun 29, 2023



Egocentric action anticipation aims to predict the future actions the camera wearer will perform from the observation of the past. While predictions about the future should be available before the predicted events take place, most approaches do not pay attention to the computational time required to make such predictions. As a result, current evaluation schemes assume that predictions are available right after the input video is observed, i.e., presuming a negligible runtime, which may lead to overly optimistic evaluations. We propose a streaming egocentric action evaluation scheme which assumes that predictions are performed online and made available only after the model has processed the current input segment, which depends on its runtime. To evaluate all models considering the same prediction horizon, we hence propose that slower models should base their predictions on temporal segments sampled ahead of time. Based on the observation that model runtime can affect performance in the considered streaming evaluation scenario, we further propose a lightweight action anticipation model based on feed-forward 3D CNNs which is optimized using knowledge distillation techniques with a novel past-to-future distillation loss. Experiments on the three popular datasets EPIC-KITCHENS-55, EPIC-KITCHENS-100 and EGTEA Gaze+ show that (i) the proposed evaluation scheme induces a different ranking on state-of-the-art methods as compared to classic evaluations, (ii) lightweight approaches tend to outmatch more computationally expensive ones, and (iii) the proposed model based on feed-forward 3D CNNs and knowledge distillation outperforms current art in the streaming egocentric action anticipation scenario.
Exploiting Multimodal Synthetic Data for Egocentric Human-Object Interaction Detection in an Industrial Scenario
Jun 21, 2023



In this paper, we tackle the problem of Egocentric Human-Object Interaction (EHOI) detection in an industrial setting. To overcome the lack of public datasets in this context, we propose a pipeline and a tool for generating synthetic images of EHOIs paired with several annotations and data signals (e.g., depth maps or instance segmentation masks). Using the proposed pipeline, we present EgoISM-HOI a new multimodal dataset composed of synthetic EHOI images in an industrial environment with rich annotations of hands and objects. To demonstrate the utility and effectiveness of synthetic EHOI data produced by the proposed tool, we designed a new method that predicts and combines different multimodal signals to detect EHOIs in RGB images. Our study shows that exploiting synthetic data to pre-train the proposed method significantly improves performance when tested on real-world data. Moreover, the proposed approach outperforms state-of-the-art class-agnostic methods. To support research in this field, we publicly release the datasets, source code, and pre-trained models at https://iplab.dmi.unict.it/egoism-hoi.
StillFast: An End-to-End Approach for Short-Term Object Interaction Anticipation
Apr 08, 2023



Anticipation problem has been studied considering different aspects such as predicting humans' locations, predicting hands and objects trajectories, and forecasting actions and human-object interactions. In this paper, we studied the short-term object interaction anticipation problem from the egocentric point of view, proposing a new end-to-end architecture named StillFast. Our approach simultaneously processes a still image and a video detecting and localizing next-active objects, predicting the verb which describes the future interaction and determining when the interaction will start. Experiments on the large-scale egocentric dataset EGO4D show that our method outperformed state-of-the-art approaches on the considered task. Our method is ranked first in the public leaderboard of the EGO4D short term object interaction anticipation challenge 2022. Please see the project web page for code and additional details: https://iplab.dmi.unict.it/stillfast/.
A Multi Camera Unsupervised Domain Adaptation Pipeline for Object Detection in Cultural Sites through Adversarial Learning and Self-Training
Oct 03, 2022
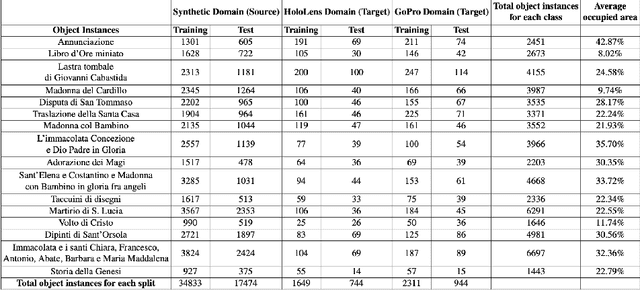

Object detection algorithms allow to enable many interesting applications which can be implemented in different devices, such as smartphones and wearable devices. In the context of a cultural site, implementing these algorithms in a wearable device, such as a pair of smart glasses, allow to enable the use of augmented reality (AR) to show extra information about the artworks and enrich the visitors' experience during their tour. However, object detection algorithms require to be trained on many well annotated examples to achieve reasonable results. This brings a major limitation since the annotation process requires human supervision which makes it expensive in terms of time and costs. A possible solution to reduce these costs consist in exploiting tools to automatically generate synthetic labeled images from a 3D model of the site. However, models trained with synthetic data do not generalize on real images acquired in the target scenario in which they are supposed to be used. Furthermore, object detectors should be able to work with different wearable devices or different mobile devices, which makes generalization even harder. In this paper, we present a new dataset collected in a cultural site to study the problem of domain adaptation for object detection in the presence of multiple unlabeled target domains corresponding to different cameras and a labeled source domain obtained considering synthetic images for training purposes. We present a new domain adaptation method which outperforms current state-of-the-art approaches combining the benefits of aligning the domains at the feature and pixel level with a self-training process. We release the dataset at the following link https://iplab.dmi.unict.it/OBJ-MDA/ and the code of the proposed architecture at https://github.com/fpv-iplab/STMDA-RetinaNet.
Visual Object Tracking in First Person Vision
Sep 27, 2022
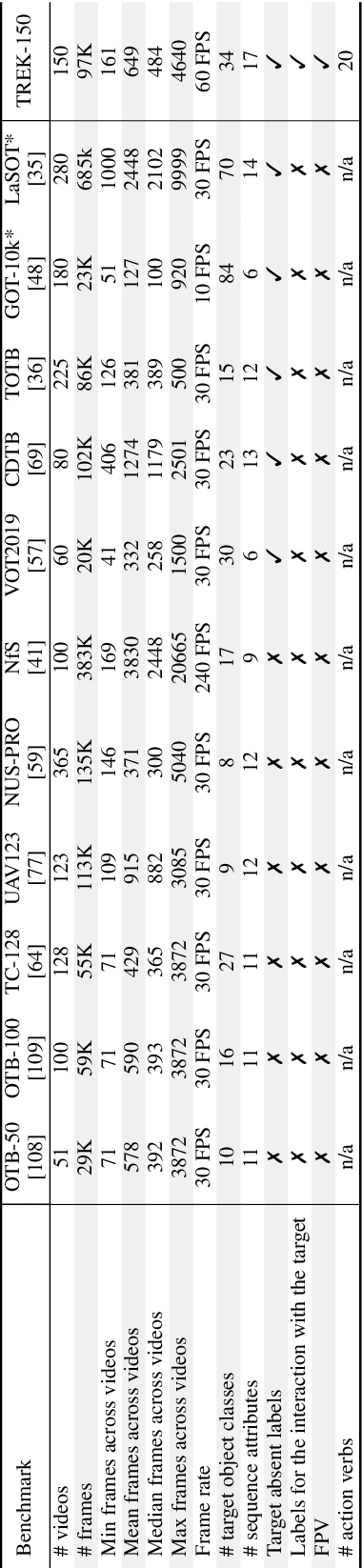
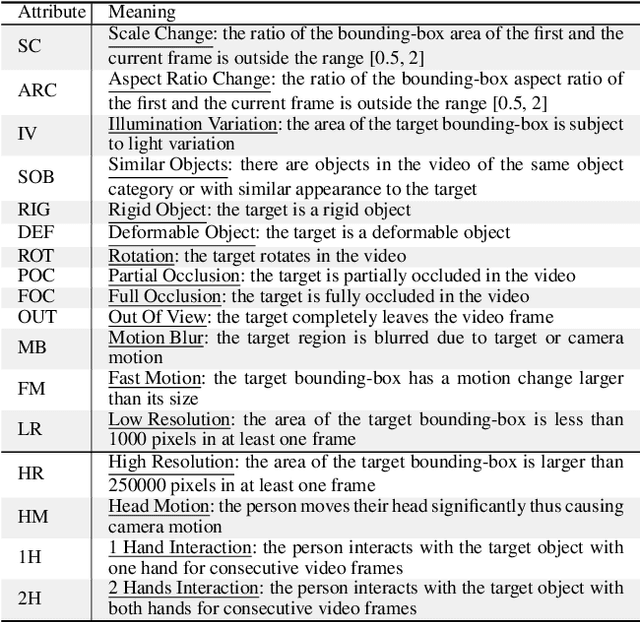
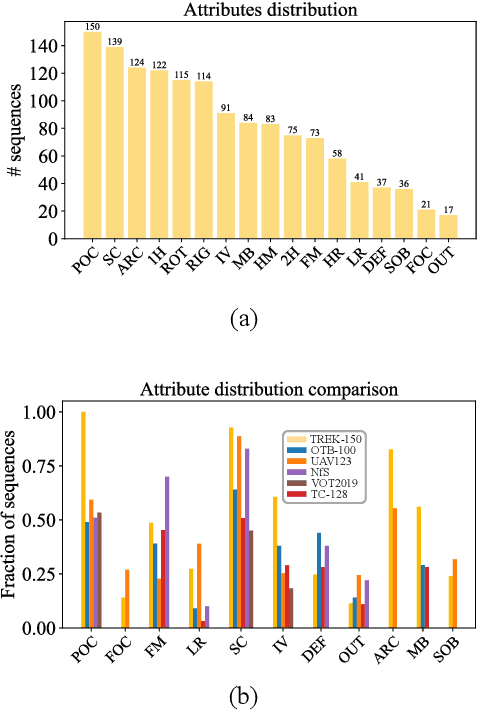
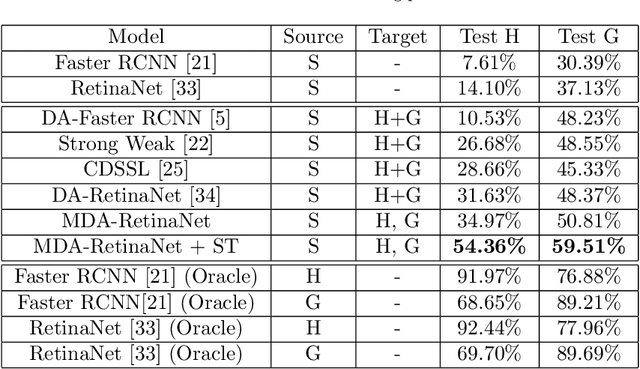
The understanding of human-object interactions is fundamental in First Person Vision (FPV). Visual tracking algorithms which follow the objects manipulated by the camera wearer can provide useful information to effectively model such interactions. In the last years, the computer vision community has significantly improved the performance of tracking algorithms for a large variety of target objects and scenarios. Despite a few previous attempts to exploit trackers in the FPV domain, a methodical analysis of the performance of state-of-the-art trackers is still missing. This research gap raises the question of whether current solutions can be used ``off-the-shelf'' or more domain-specific investigations should be carried out. This paper aims to provide answers to such questions. We present the first systematic investigation of single object tracking in FPV. Our study extensively analyses the performance of 42 algorithms including generic object trackers and baseline FPV-specific trackers. The analysis is carried out by focusing on different aspects of the FPV setting, introducing new performance measures, and in relation to FPV-specific tasks. The study is made possible through the introduction of TREK-150, a novel benchmark dataset composed of 150 densely annotated video sequences. Our results show that object tracking in FPV poses new challenges to current visual trackers. We highlight the factors causing such behavior and point out possible research directions. Despite their difficulties, we prove that trackers bring benefits to FPV downstream tasks requiring short-term object tracking. We expect that generic object tracking will gain popularity in FPV as new and FPV-specific methodologies are investigated.