 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Common Rationale to Improve Self-Supervised Representation for Fine-Grained Visual Recognition Problems
Mar 03, 2023



Self-supervised learning (SSL) strategies have demonstrated remarkable performance in various recognition tasks. However, both our preliminary investigation and recent studies suggest that they may be less effective in learning representations for fine-grained visual recognition (FGVR) since many features helpful for optimizing SSL objectives are not suitable for characterizing the subtle differences in FGVR. To overcome this issue, we propose learning an additional screening mechanism to identify discriminative clues commonly seen across instances and classes, dubbed as common rationales in this paper. Intuitively, common rationales tend to correspond to the discriminative patterns from the key parts of foreground objects. We show that a common rationale detector can be learned by simply exploiting the GradCAM induced from the SSL objective without using any pre-trained object parts or saliency detectors, making it seamlessly to be integrated with the existing SSL process. Specifically, we fit the GradCAM with a branch with limited fitting capacity, which allows the branch to capture the common rationales and discard the less common discriminative patterns. At the test stage, the branch generates a set of spatial weights to selectively aggregate features representing an instance. Extensive experimental results on four visual tasks demonstrate that the proposed method can lead to a significant improvement in different evaluation settings.
Program Generation from Diverse Video Demonstrations
Feb 01, 2023



The ability to use inductive reasoning to extract general rules from multiple observations is a vital indicator of intelligence. As humans, we use this ability to not only interpret the world around us, but also to predict the outcomes of the various interactions we experience. Generalising over multiple observations is a task that has historically presented difficulties for machines to grasp, especially when requiring computer vision. In this paper, we propose a model that can extract general rules from video demonstrations by simultaneously performing summarisation and translation. Our approach differs from prior works by framing the problem as a multi-sequence-to-sequence task, wherein summarisation is learnt by the model. This allows our model to utilise edge cases that would otherwise be suppressed or discarded by traditional summarisation techniques. Additionally, we show that our approach can handle noisy specifications without the need for additional filtering methods. We evaluate our model by synthesising programs from video demonstrations in the Vizdoom environment achieving state-of-the-art results with a relative increase of 11.75% program accuracy on prior works
Understanding and Improving the Role of Projection Head in Self-Supervised Learning
Dec 22, 2022



Self-supervised learning (SSL) aims to produce useful feature representations without access to any human-labeled data annotations. Due to the success of recent SSL methods based on contrastive learning, such as SimCLR, this problem has gained popularity. Most current contrastive learning approaches append a parametrized projection head to the end of some backbone network to optimize the InfoNCE objective and then discard the learned projection head after training. This raises a fundamental question: Why is a learnable projection head required if we are to discard it after training? In this work, we first perform a systematic study on the behavior of SSL training focusing on the role of the projection head layers. By formulating the projection head as a parametric component for the InfoNCE objective rather than a part of the network, we present an alternative optimization scheme for training contrastive learning based SSL frameworks. Our experimental study on multiple image classification datasets demonstrates the effectiveness of the proposed approach over alternatives in the SSL literature.
Weight-variant Latent Causal Models
Aug 30, 2022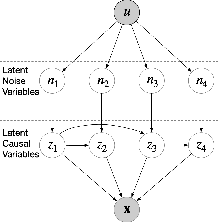
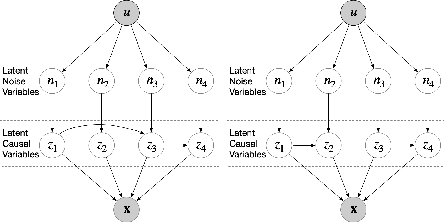
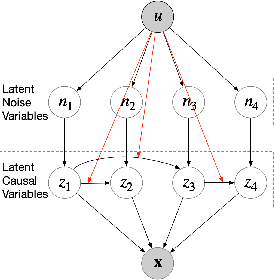
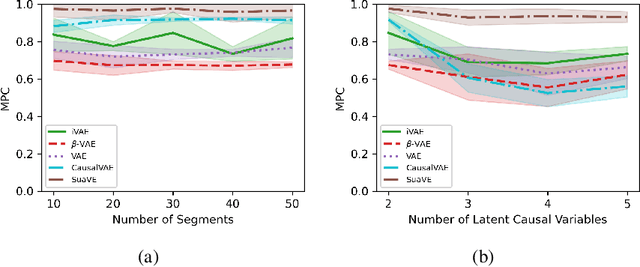
Causal representation learning exposes latent high-level causal variables behind low-level observations, which has enormous potential for a set of downstream tasks of interest. Despite this, identifying the true latent causal representation from observed data is a great challenge. In this work we focus on identifying latent causal variables. To this end, we analysis three intrinsic properties in latent space, including transitivity, permutation and scaling. We show that the transitivity severely hinders the identifiability of latent causal variables, while permutation and scaling guide the direction of identifying latent causal variable. To break the transitivity, we assume the underlying latent causal relations to be linear Gaussian models, in which the weights, mean and variance of Gaussian noise are modulated by an additionally observed variable. Under these assumptions we theoretically show that the latent causal variables can be identifiable up to trivial permutation and scaling. Built on this theoretical result, we propose a novel method, termed Structural caUsAl Variational autoEncoder, which directly learns latent causal variables, together with the mapping from the latent causal variables to the observed ones. Experimental results on synthetic and real data demonstrate the identifiable result and the ability of the proposed method for learning latent causal variables.
ClusTR: Exploring Efficient Self-attention via Clustering for Vision Transformers
Aug 28, 2022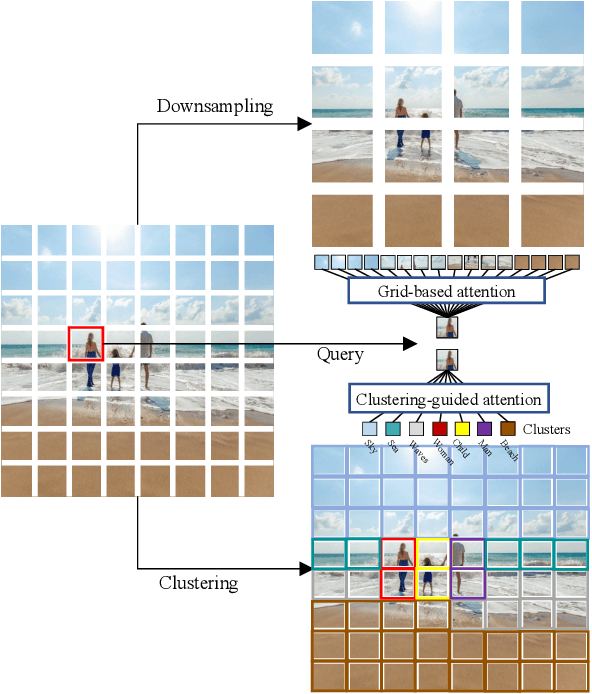

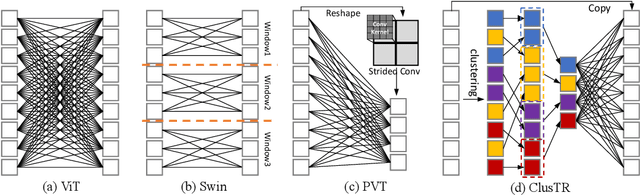

Although Transformers have successfully transitioned from their language modelling origins to image-based applications, their quadratic computational complexity remains a challenge, particularly for dense prediction. In this paper we propose a content-based sparse attention method, as an alternative to dense self-attention, aiming to reduce the computation complexity while retaining the ability to model long-range dependencies. Specifically, we cluster and then aggregate key and value tokens, as a content-based method of reducing the total token count. The resulting clustered-token sequence retains the semantic diversity of the original signal, but can be processed at a lower computational cost. Besides, we further extend the clustering-guided attention from single-scale to multi-scale, which is conducive to dense prediction tasks. We label the proposed Transformer architecture ClusTR, and demonstrate that it achieves state-of-the-art performance on various vision tasks but at lower computational cost and with fewer parameters. For instance, our ClusTR small model with 22.7M parameters achieves 83.2\% Top-1 accuracy on ImageNet. Source code and ImageNet models will be made publicly available.
EBMs vs. CL: Exploring Self-Supervised Visual Pretraining for Visual Question Answering
Jun 29, 2022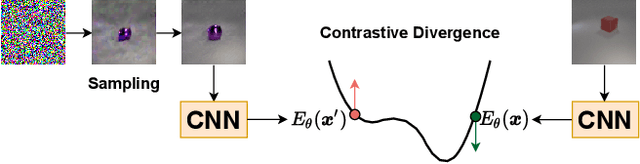
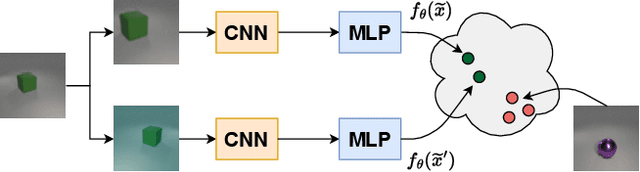
The availability of clean and diverse labeled data is a major roadblock for training models on complex tasks such as visual question answering (VQA). The extensive work on large vision-and-language models has shown that self-supervised learning is effective for pretraining multimodal interactions. In this technical report, we focus on visual representations. We review and evaluate self-supervised methods to leverage unlabeled images and pretrain a model, which we then fine-tune on a custom VQA task that allows controlled evaluation and diagnosis. We compare energy-based models (EBMs) with contrastive learning (CL). While EBMs are growing in popularity, they lack an evaluation on downstream tasks. We find that both EBMs and CL can learn representations from unlabeled images that enable training a VQA model on very little annotated data. In a simple setting similar to CLEVR, we find that CL representations also improve systematic generalization, and even match the performance of representations from a larger, supervised, ImageNet-pretrained model. However, we find EBMs to be difficult to train because of instabilities and high variability in their results. Although EBMs prove useful for OOD detection, other results on supervised energy-based training and uncertainty calibration are largely negative. Overall, CL currently seems a preferable option over EBMs.
Confident Sinkhorn Allocation for Pseudo-Labeling
Jun 13, 2022
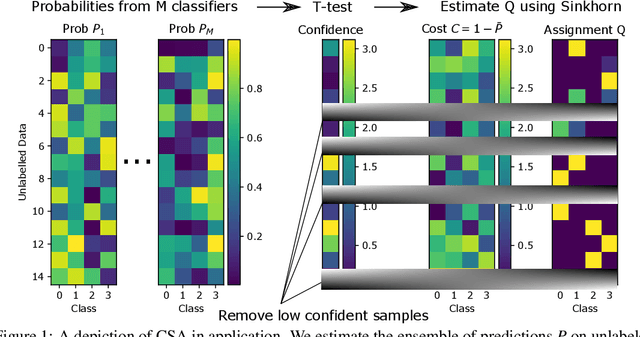
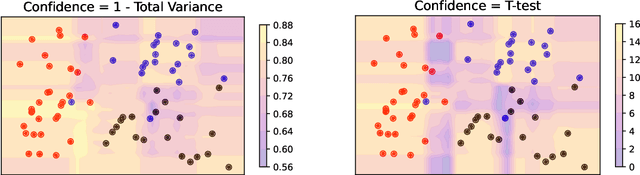
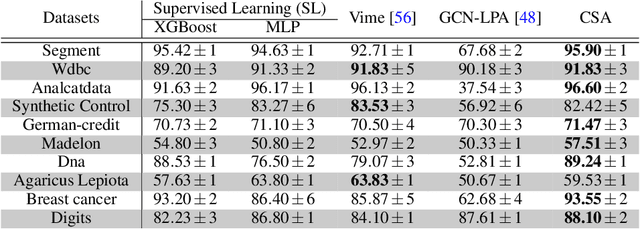
Semi-supervised learning is a critical tool in reducing machine learning's dependence on labeled data. It has, however, been applied primarily to image and language data, by exploiting the inherent spatial and semantic structure therein. These methods do not apply to tabular data because these domain structures are not available. Existing pseudo-labeling (PL) methods can be effective for tabular data but are vulnerable to noise samples and to greedy assignments given a predefined threshold which is unknown. This paper addresses this problem by proposing a Confident Sinkhorn Allocation (CSA), which assigns labels to only samples with high confidence scores and learns the best label allocation via optimal transport. CSA outperforms the current state-of-the-art in this practically important area.
PointInst3D: Segmenting 3D Instances by Points
Apr 25, 2022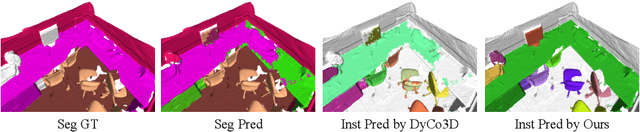

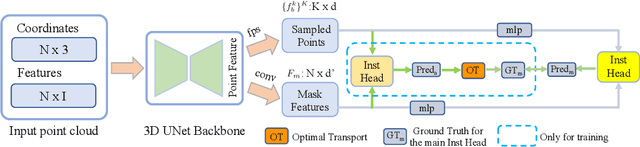
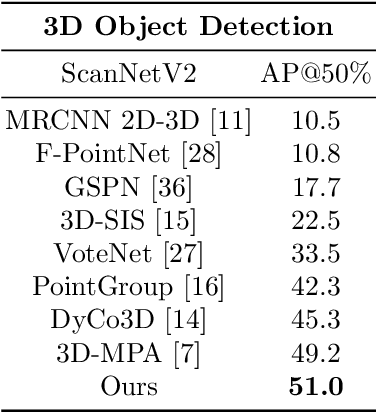
The current state-of-the-art methods in 3D instance segmentation typically involve a clustering step, despite the tendency towards heuristics, greedy algorithms, and a lack of robustness to the changes in data statistics. In contrast, we propose a fully-convolutional 3D point cloud instance segmentation method that works in a per-point prediction fashion. In doing so it avoids the challenges that clustering-based methods face: introducing dependencies among different tasks of the model. We find the key to its success is assigning a suitable target to each sampled point. Instead of the commonly used static or distance-based assignment strategies, we propose to use an Optimal Transport approach to optimally assign target masks to the sampled points according to the dynamic matching costs. Our approach achieves promising results on both ScanNet and S3DIS benchmarks. The proposed approach removes intertask dependencies and thus represents a simpler and more flexible 3D instance segmentation framework than other competing methods, while achieving improved segmentation accuracy.
CNN Attention Guidance for Improved Orthopedics Radiographic Fracture Classification
Mar 21, 2022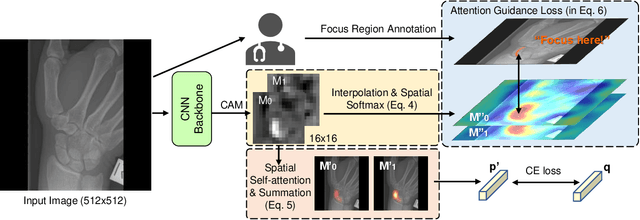
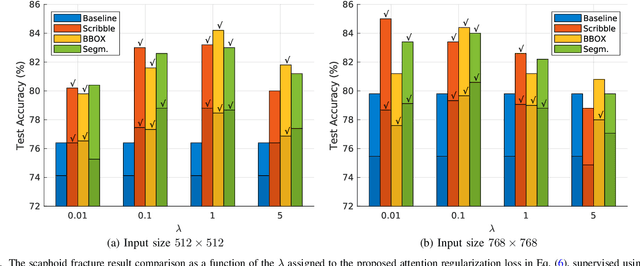
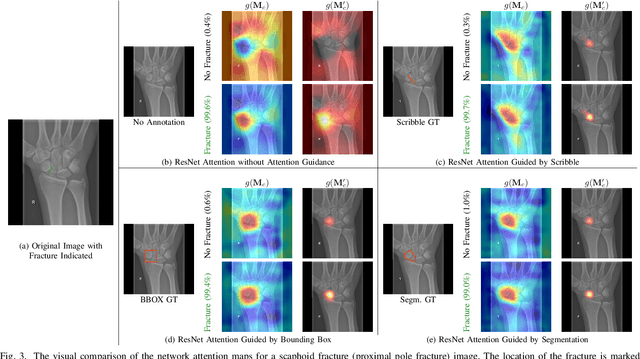
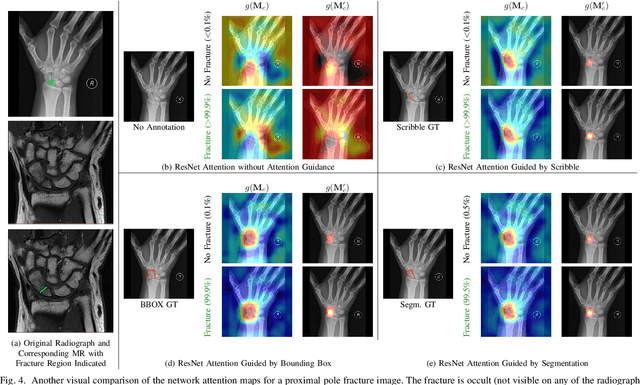
Convolutional neural networks (CNNs) have gained significant popularity in orthopedic imaging in recent years due to their ability to solve fracture classification problems. A common criticism of CNNs is their opaque learning and reasoning process, making it difficult to trust machine diagnosis and the subsequent adoption of such algorithms in clinical setting. This is especially true when the CNN is trained with limited amount of medical data, which is a common issue as curating sufficiently large amount of annotated medical imaging data is a long and costly process. While interest has been devoted to explaining CNN learnt knowledge by visualizing network attention, the utilization of the visualized attention to improve network learning has been rarely investigated. This paper explores the effectiveness of regularizing CNN network with human-provided attention guidance on where in the image the network should look for answering clues. On two orthopedics radiographic fracture classification datasets, through extensive experiments we demonstrate that explicit human-guided attention indeed can direct correct network attention and consequently significantly improve classification performance. The development code for the proposed attention guidance is publicly available on GitHub.
Active Learning by Feature Mixing
Mar 14, 2022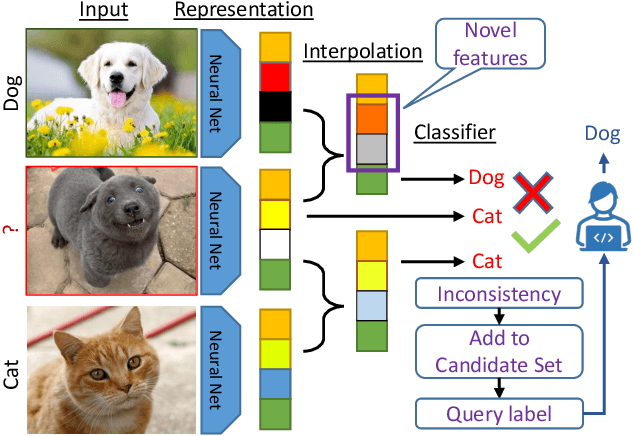
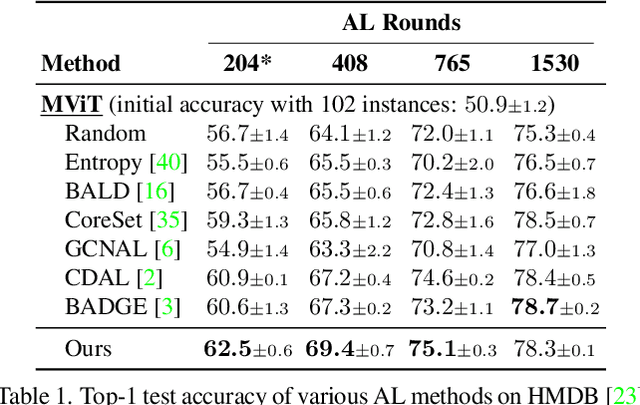
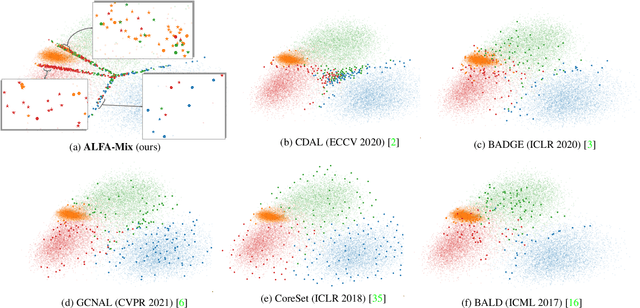
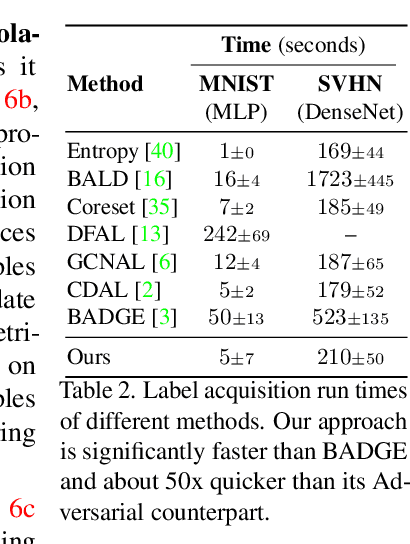
The promise of active learning (AL) is to reduce labelling costs by selecting the most valuable examples to annotate from a pool of unlabelled data. Identifying these examples is especially challenging with high-dimensional data (e.g. images, videos) and in low-data regimes. In this paper, we propose a novel method for batch AL called ALFA-Mix. We identify unlabelled instances with sufficiently-distinct features by seeking inconsistencies in predictions resulting from interventions on their representations. We construct interpolations between representations of labelled and unlabelled instances then examine the predicted labels. We show that inconsistencies in these predictions help discovering features that the model is unable to recognise in the unlabelled instances. We derive an efficient implementation based on a closed-form solution to the optimal interpolation causing changes in predictions. Our method outperforms all recent AL approaches in 30 different settings on 12 benchmarks of images, videos, and non-visual data. The improvements are especially significant in low-data regimes and on self-trained vision transformers, where ALFA-Mix outperforms the state-of-the-art in 59% and 43% of the experiments respectively.