 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Multi-Target Tracking Using Recurrent Neural Networks
Dec 07, 2016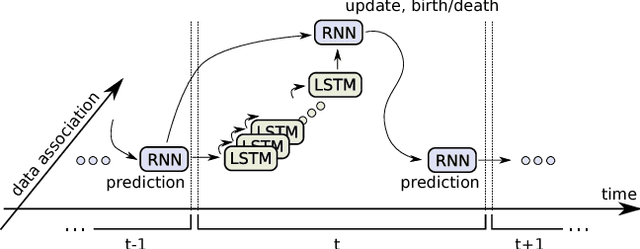

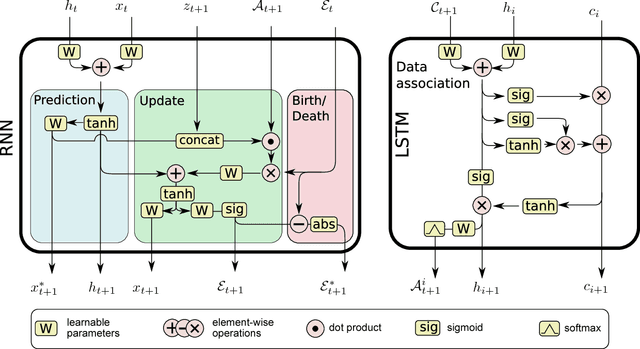

We present a novel approach to online multi-target tracking based on recurrent neural networks (RNNs). Tracking multiple objects in real-world scenes involves many challenges, including a) an a-priori unknown and time-varying number of targets, b) a continuous state estimation of all present targets, and c) a discrete combinatorial problem of data association. Most previous methods involve complex models that require tedious tuning of parameters. Here, we propose for the first time, an end-to-end learning approach for online multi-target tracking. Existing deep learning methods are not designed for the above challenges and cannot be trivially applied to the task. Our solution addresses all of the above points in a principled way. Experiments on both synthetic and real data show promising results obtained at ~300 Hz on a standard CPU, and pave the way towards future research in this direction.
Infinite Variational Autoencoder for Semi-Supervised Learning
Nov 24, 2016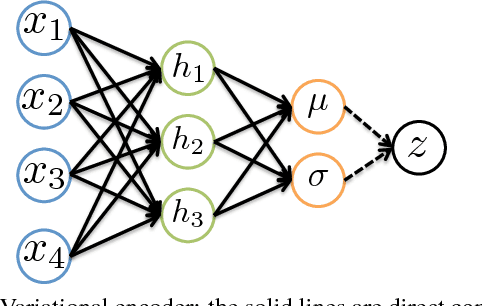
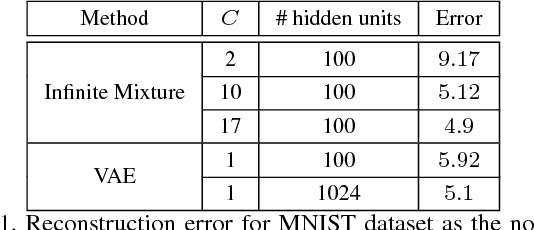
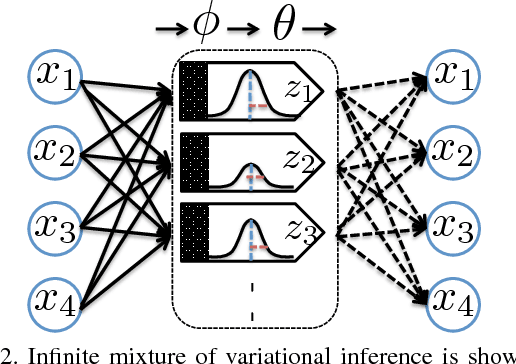
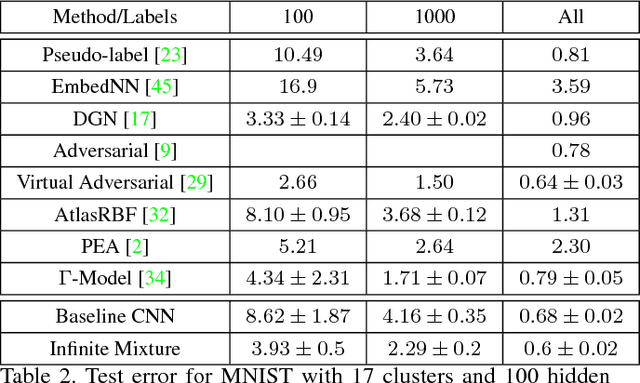
This paper presents an infinite variational autoencoder (VAE) whose capacity adapts to suit the input data. This is achieved using a mixture model where the mixing coefficients are modeled by a Dirichlet process, allowing us to integrate over the coefficients when performing inference. Critically, this then allows us to automatically vary the number of autoencoders in the mixture based on the data. Experiments show the flexibility of our method, particularly for semi-supervised learning, where only a small number of training samples are available.
Visual Question Answering: A Survey of Methods and Datasets
Jul 20, 2016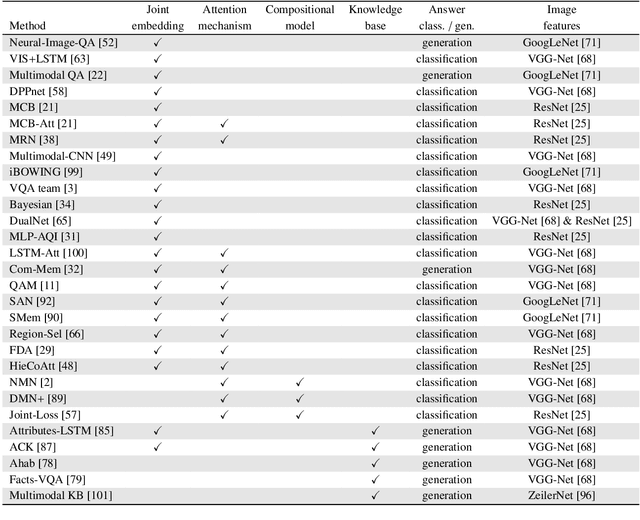
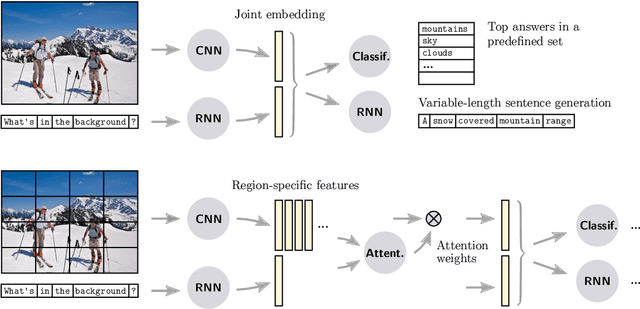
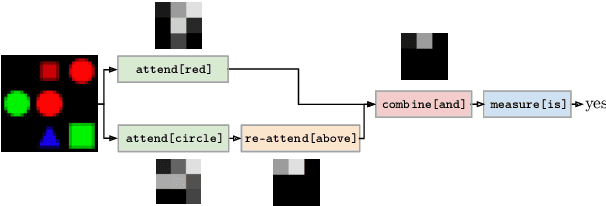
Visual Question Answering (VQA) is a challenging task that has received increasing attention from both the computer vision and the natural language processing communities. Given an image and a question in natural language, it requires reasoning over visual elements of the image and general knowledge to infer the correct answer. In the first part of this survey, we examine the state of the art by comparing modern approaches to the problem. We classify methods by their mechanism to connect the visual and textual modalities. In particular, we examine the common approach of combining convolutional and recurrent neural networks to map images and questions to a common feature space. We also discuss memory-augmented and modular architectures that interface with structured knowledge bases. In the second part of this survey, we review the datasets available for training and evaluating VQA systems. The various datatsets contain questions at different levels of complexity, which require different capabilities and types of reasoning. We examine in depth the question/answer pairs from the Visual Genome project, and evaluate the relevance of the structured annotations of images with scene graphs for VQA. Finally, we discuss promising future directions for the field, in particular the connection to structured knowledge bases and the use of natural language processing models.
What value do explicit high level concepts have in vision to language problems?
Apr 28, 2016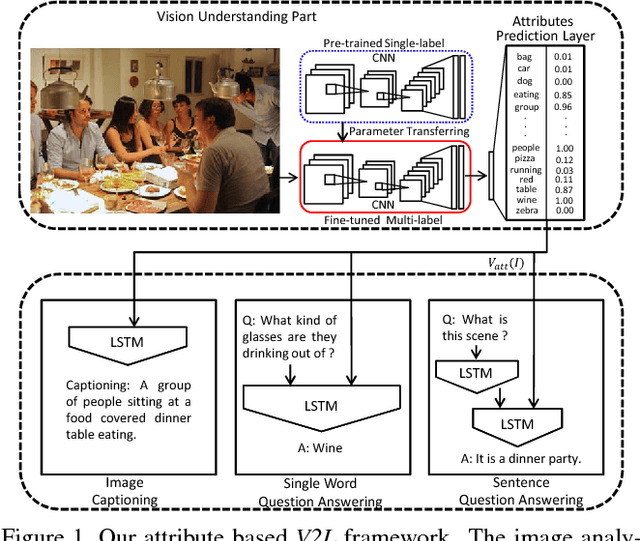
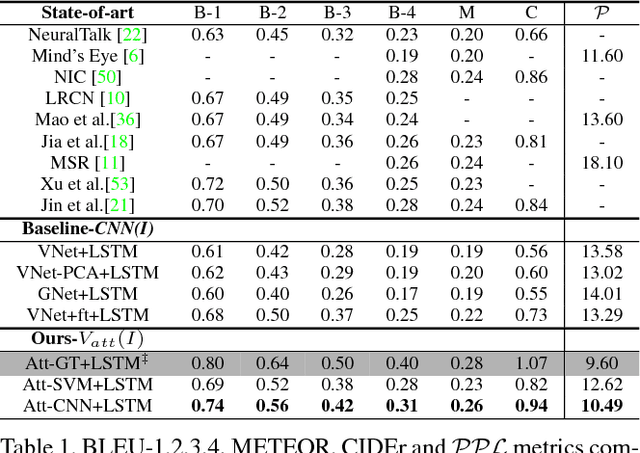
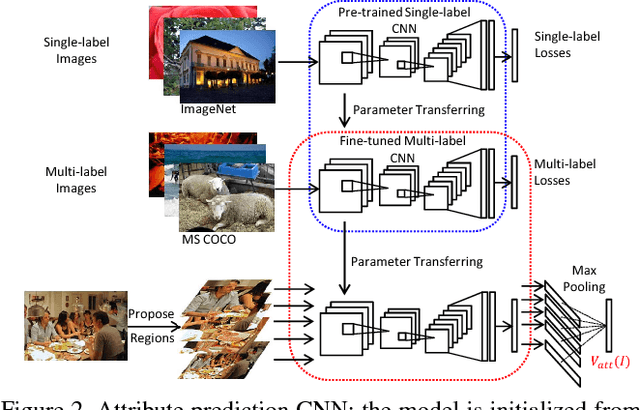
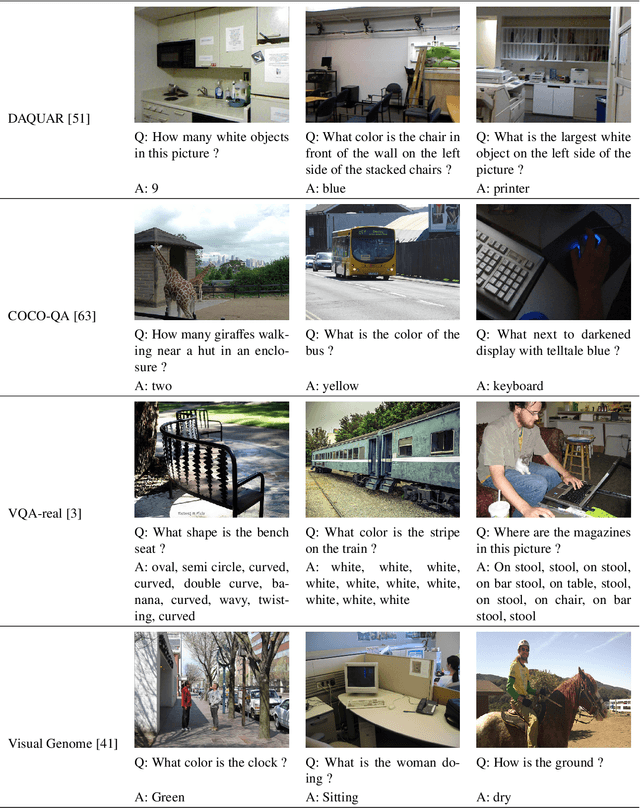
Much of the recent progress in Vision-to-Language (V2L) problems has been achieved through a combination of Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). This approach does not explicitly represent high-level semantic concepts, but rather seeks to progress directly from image features to text. We propose here a method of incorporating high-level concepts into the very successful CNN-RNN approach, and show that it achieves a significant improvement on the state-of-the-art performance in both image captioning and visual question answering. We also show that the same mechanism can be used to introduce external semantic information and that doing so further improves performance. In doing so we provide an analysis of the value of high level semantic information in V2L problems.
Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources
Apr 14, 2016

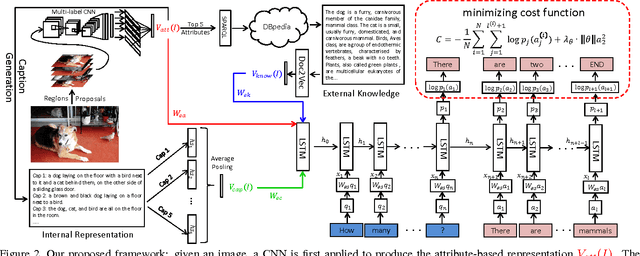
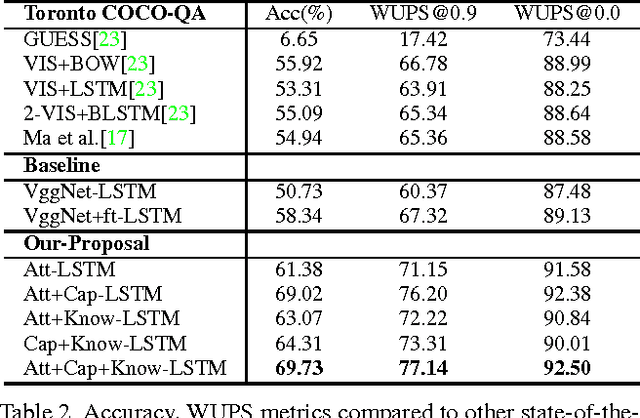
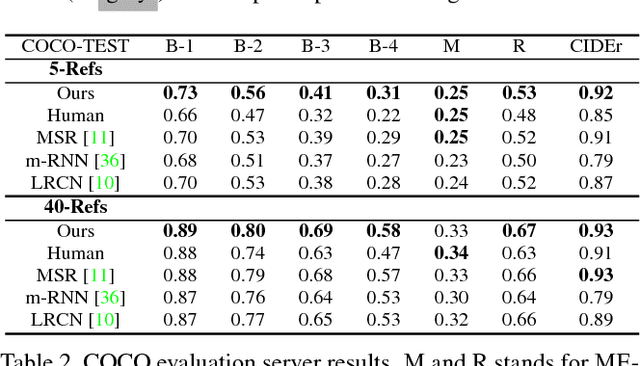
We propose a method for visual question answering which combines an internal representation of the content of an image with information extracted from a general knowledge base to answer a broad range of image-based questions. This allows more complex questions to be answered using the predominant neural network-based approach than has previously been possible. It particularly allows questions to be asked about the contents of an image, even when the image itself does not contain the whole answer. The method constructs a textual representation of the semantic content of an image, and merges it with textual information sourced from a knowledge base, to develop a deeper understanding of the scene viewed. Priming a recurrent neural network with this combined information, and the submitted question, leads to a very flexible visual question answering approach. We are specifically able to answer questions posed in natural language, that refer to information not contained in the image. We demonstrate the effectiveness of our model on two publicly available datasets, Toronto COCO-QA and MS COCO-VQA and show that it produces the best reported results in both cases.
Explicit Knowledge-based Reasoning for Visual Question Answering
Nov 12, 2015
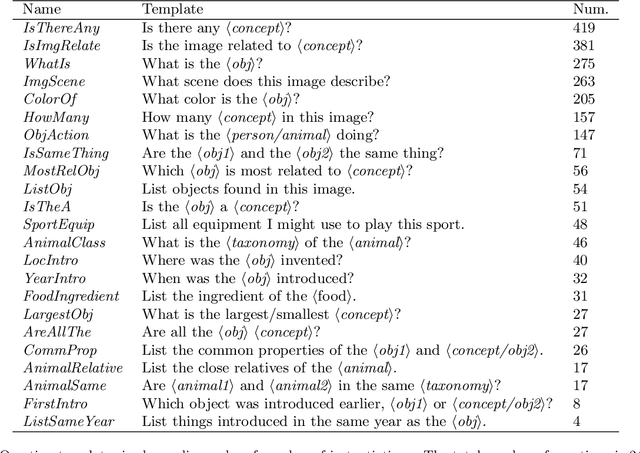
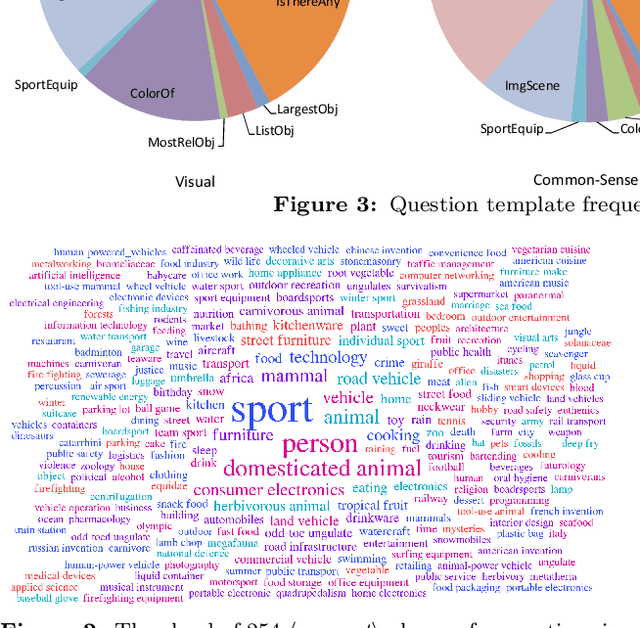
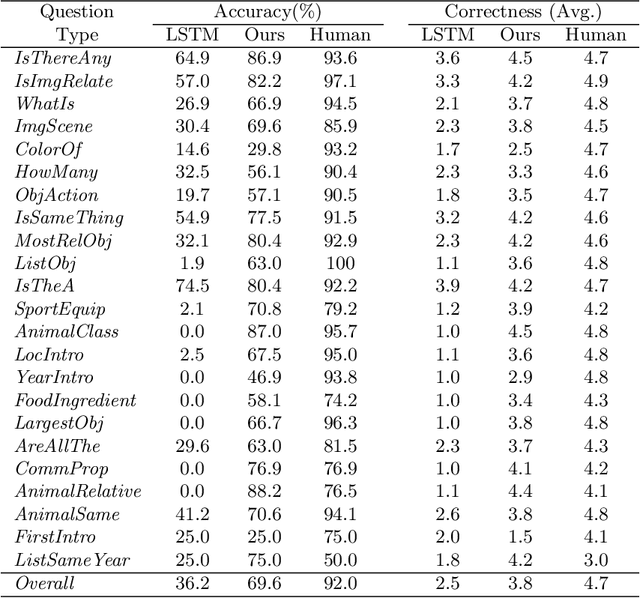
We describe a method for visual question answering which is capable of reasoning about contents of an image on the basis of information extracted from a large-scale knowledge base. The method not only answers natural language questions using concepts not contained in the image, but can provide an explanation of the reasoning by which it developed its answer. The method is capable of answering far more complex questions than the predominant long short-term memory-based approach, and outperforms it significantly in the testing. We also provide a dataset and a protocol by which to evaluate such methods, thus addressing one of the key issues in general visual ques- tion answering.
Online Metric-Weighted Linear Representations for Robust Visual Tracking
Jul 21, 2015

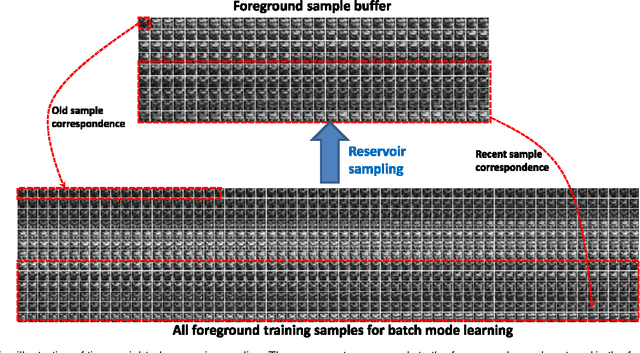

In this paper, we propose a visual tracker based on a metric-weighted linear representation of appearance. In order to capture the interdependence of different feature dimensions, we develop two online distance metric learning methods using proximity comparison information and structured output learning. The learned metric is then incorporated into a linear representation of appearance. We show that online distance metric learning significantly improves the robustness of the tracker, especially on those sequences exhibiting drastic appearance changes. In order to bound growth in the number of training samples, we design a time-weighted reservoir sampling method. Moreover, we enable our tracker to automatically perform object identification during the process of object tracking, by introducing a collection of static template samples belonging to several object classes of interest. Object identification results for an entire video sequence are achieved by systematically combining the tracking information and visual recognition at each frame. Experimental results on challenging video sequences demonstrate the effectiveness of the method for both inter-frame tracking and object identification.
Deconstruction of compound objects from image sets
Feb 26, 2014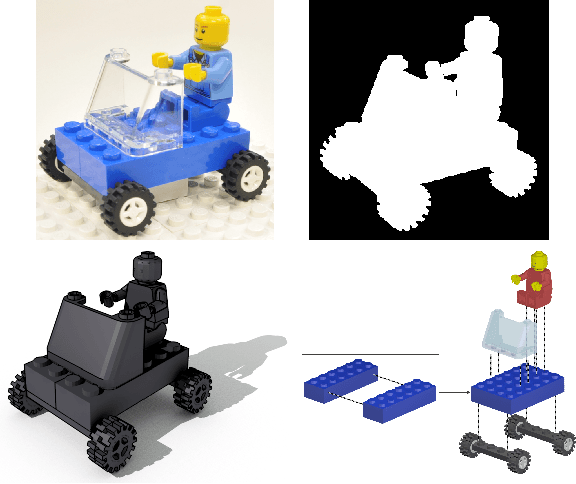
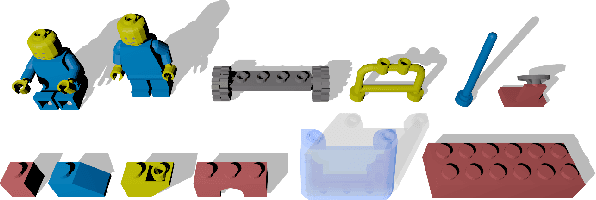

We propose a method to recover the structure of a compound object from multiple silhouettes. Structure is expressed as a collection of 3D primitives chosen from a pre-defined library, each with an associated pose. This has several advantages over a volume or mesh representation both for estimation and the utility of the recovered model. The main challenge in recovering such a model is the combinatorial number of possible arrangements of parts. We address this issue by exploiting the sparse nature of the problem, and show that our method scales to objects constructed from large libraries of parts.
Context-Aware Hypergraph Construction for Robust Spectral Clustering
Jan 04, 2014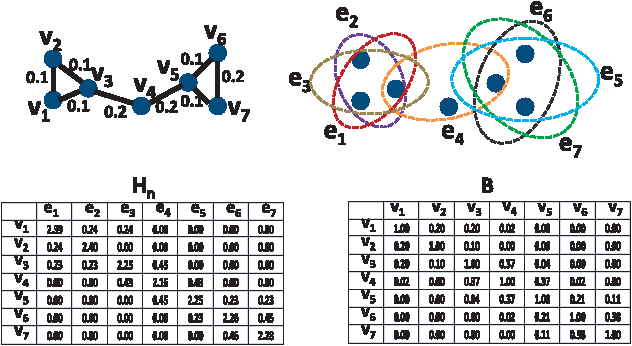
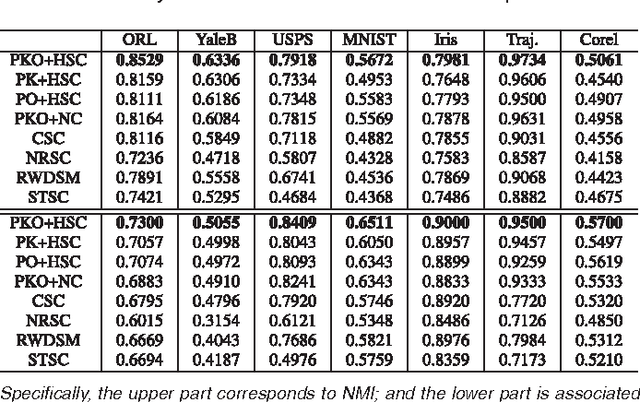

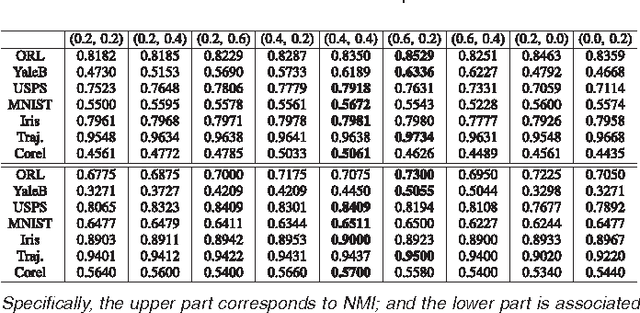
Spectral clustering is a powerful tool for unsupervised data analysis. In this paper, we propose a context-aware hypergraph similarity measure (CAHSM), which leads to robust spectral clustering in the case of noisy data. We construct three types of hypergraph---the pairwise hypergraph, the k-nearest-neighbor (kNN) hypergraph, and the high-order over-clustering hypergraph. The pairwise hypergraph captures the pairwise similarity of data points; the kNN hypergraph captures the neighborhood of each point; and the clustering hypergraph encodes high-order contexts within the dataset. By combining the affinity information from these three hypergraphs, the CAHSM algorithm is able to explore the intrinsic topological information of the dataset. Therefore, data clustering using CAHSM tends to be more robust. Considering the intra-cluster compactness and the inter-cluster separability of vertices, we further design a discriminative hypergraph partitioning criterion (DHPC). Using both CAHSM and DHPC, a robust spectral clustering algorithm is developed. Theoretical analysis and experimental evaluation demonstrate the effectiveness and robustness of the proposed algorithm.
Contextual Hypergraph Modelling for Salient Object Detection
Oct 22, 2013

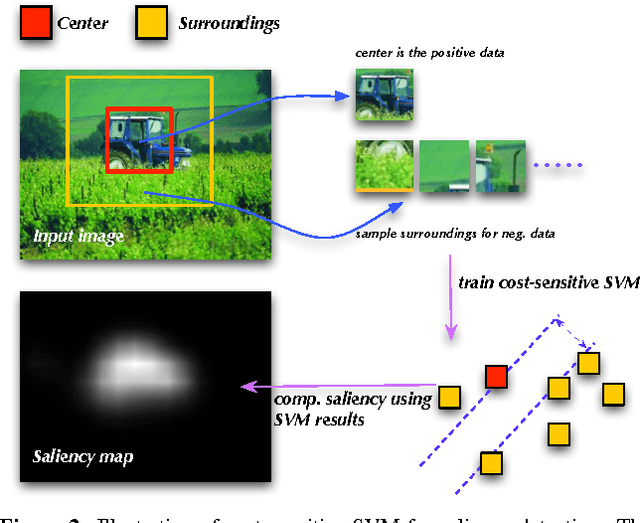
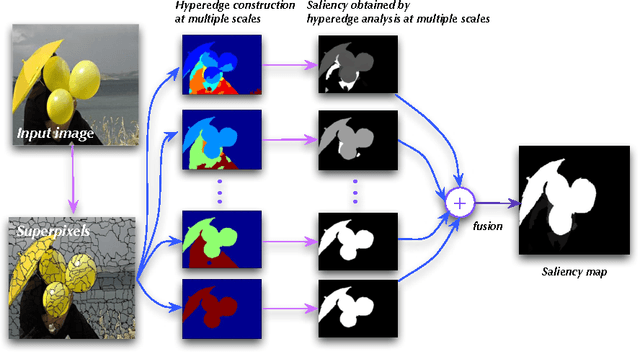
Salient object detection aims to locate objects that capture human attention within images. Previous approaches often pose this as a problem of image contrast analysis. In this work, we model an image as a hypergraph that utilizes a set of hyperedges to capture the contextual properties of image pixels or regions. As a result, the problem of salient object detection becomes one of finding salient vertices and hyperedges in the hypergraph. The main advantage of hypergraph modeling is that it takes into account each pixel's (or region's) affinity with its neighborhood as well as its separation from image background. Furthermore, we propose an alternative approach based on center-versus-surround contextual contrast analysis, which performs salient object detection by optimizing a cost-sensitive support vector machine (SVM) objective function. Experimental results on four challenging datasets demonstrate the effectiveness of the proposed approaches against the state-of-the-art approaches to salient object detection.