 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-SAUR: Hypothesize, Simulate, Act, Update, and Repeat for Understanding Object Articulations from Interactions
Oct 22, 2022



The world is filled with articulated objects that are difficult to determine how to use from vision alone, e.g., a door might open inwards or outwards. Humans handle these objects with strategic trial-and-error: first pushing a door then pulling if that doesn't work. We enable these capabilities in autonomous agents by proposing "Hypothesize, Simulate, Act, Update, and Repeat" (H-SAUR), a probabilistic generative framework that simultaneously generates a distribution of hypotheses about how objects articulate given input observations, captures certainty over hypotheses over time, and infer plausible actions for exploration and goal-conditioned manipulation. We compare our model with existing work in manipulating objects after a handful of exploration actions, on the PartNet-Mobility dataset. We further propose a novel PuzzleBoxes benchmark that contains locked boxes that require multiple steps to solve. We show that the proposed model significantly outperforms the current state-of-the-art articulated object manipulation framework, despite using zero training data. We further improve the test-time efficiency of H-SAUR by integrating a learned prior from learning-based vision models.
AVLEN: Audio-Visual-Language Embodied Navigation in 3D Environments
Oct 14, 2022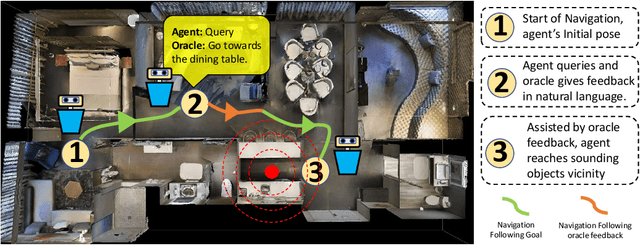
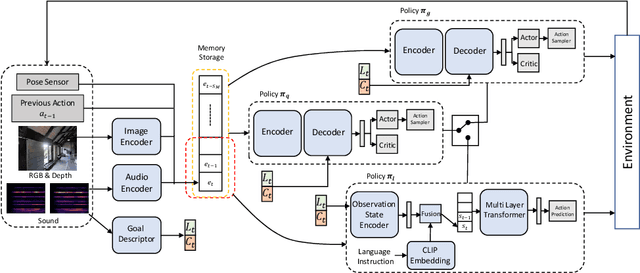
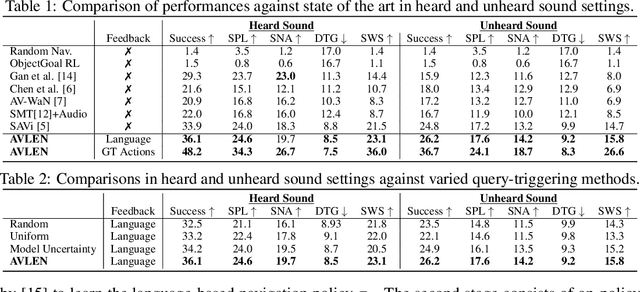

Recent years have seen embodied visual navigation advance in two distinct directions: (i) in equipping the AI agent to follow natural language instructions, and (ii) in making the navigable world multimodal, e.g., audio-visual navigation. However, the real world is not only multimodal, but also often complex, and thus in spite of these advances, agents still need to understand the uncertainty in their actions and seek instructions to navigate. To this end, we present AVLEN~ -- an interactive agent for Audio-Visual-Language Embodied Navigation. Similar to audio-visual navigation tasks, the goal of our embodied agent is to localize an audio event via navigating the 3D visual world; however, the agent may also seek help from a human (oracle), where the assistance is provided in free-form natural language. To realize these abilities, AVLEN uses a multimodal hierarchical reinforcement learning backbone that learns: (a) high-level policies to choose either audio-cues for navigation or to query the oracle, and (b) lower-level policies to select navigation actions based on its audio-visual and language inputs. The policies are trained via rewarding for the success on the navigation task while minimizing the number of queries to the oracle. To empirically evaluate AVLEN, we present experiments on the SoundSpaces framework for semantic audio-visual navigation tasks. Our results show that equipping the agent to ask for help leads to a clear improvement in performance, especially in challenging cases, e.g., when the sound is unheard during training or in the presence of distractor sounds.
D Spatio-Temporal Scene Graphs for Video Question Answering
Feb 18, 2022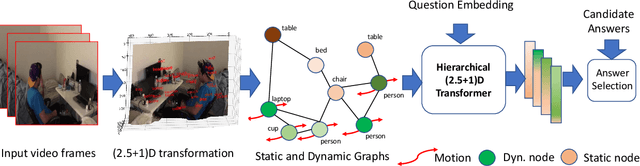
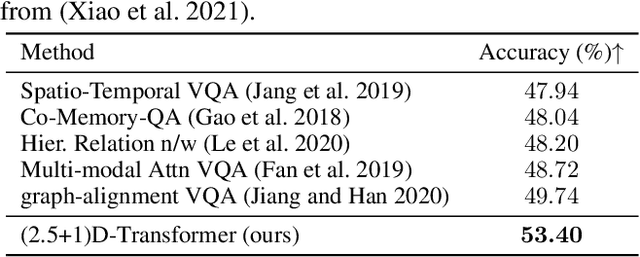
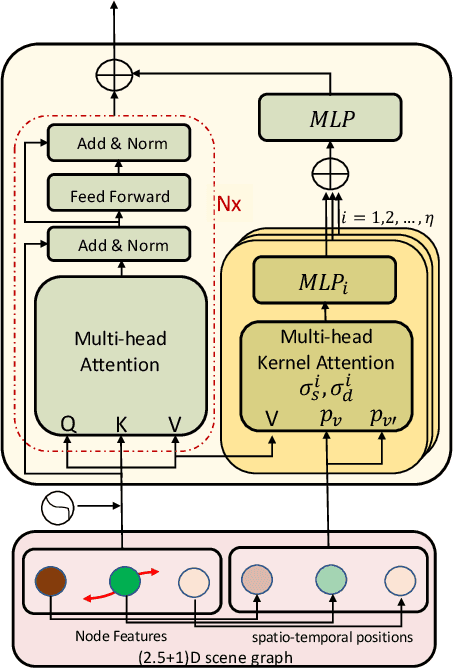
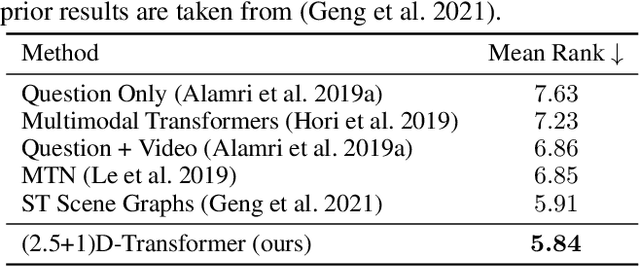
Spatio-temporal scene-graph approaches to video-based reasoning tasks such as video question-answering (QA) typically construct such graphs for every video frame. Such approaches often ignore the fact that videos are essentially sequences of 2D "views" of events happening in a 3D space, and that the semantics of the 3D scene can thus be carried over from frame to frame. Leveraging this insight, we propose a (2.5+1)D scene graph representation to better capture the spatio-temporal information flows inside the videos. Specifically, we first create a 2.5D (pseudo-3D) scene graph by transforming every 2D frame to have an inferred 3D structure using an off-the-shelf 2D-to-3D transformation module, following which we register the video frames into a shared (2.5+1)D spatio-temporal space and ground each 2D scene graph within it. Such a (2.5+1)D graph is then segregated into a static sub-graph and a dynamic sub-graph, corresponding to whether the objects within them usually move in the world. The nodes in the dynamic graph are enriched with motion features capturing their interactions with other graph nodes. Next, for the video QA task, we present a novel transformer-based reasoning pipeline that embeds the (2.5+1)D graph into a spatio-temporal hierarchical latent space, where the sub-graphs and their interactions are captured at varied granularity. To demonstrate the effectiveness of our approach, we present experiments on the NExT-QA and AVSD-QA datasets. Our results show that our proposed (2.5+1)D representation leads to faster training and inference, while our hierarchical model showcases superior performance on the video QA task versus the state of the art.
Max-Margin Contrastive Learning
Dec 21, 2021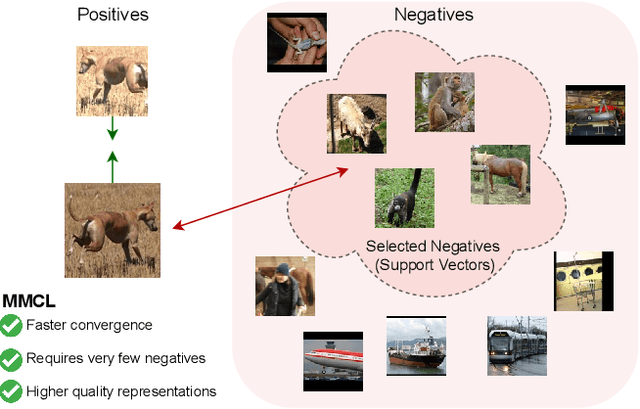
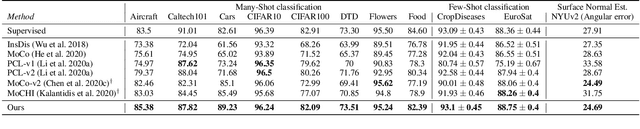
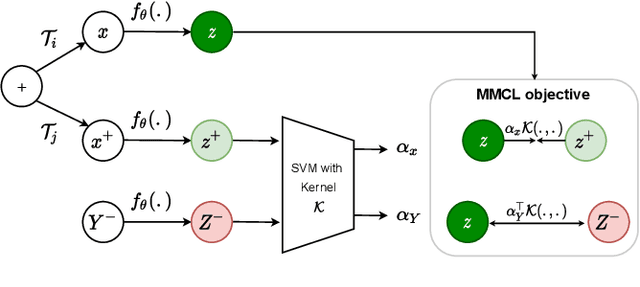
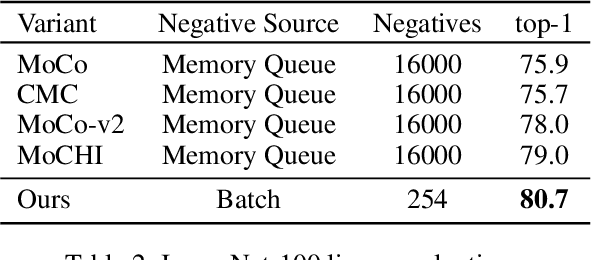
Standard contrastive learning approaches usually require a large number of negatives for effective unsupervised learning and often exhibit slow convergence. We suspect this behavior is due to the suboptimal selection of negatives used for offering contrast to the positives. We counter this difficulty by taking inspiration from support vector machines (SVMs) to present max-margin contrastive learning (MMCL). Our approach selects negatives as the sparse support vectors obtained via a quadratic optimization problem, and contrastiveness is enforced by maximizing the decision margin. As SVM optimization can be computationally demanding, especially in an end-to-end setting, we present simplifications that alleviate the computational burden. We validate our approach on standard vision benchmark datasets, demonstrating better performance in unsupervised representation learning over state-of-the-art, while having better empirical convergence properties.
MOST-GAN: 3D Morphable StyleGAN for Disentangled Face Image Manipulation
Nov 01, 2021

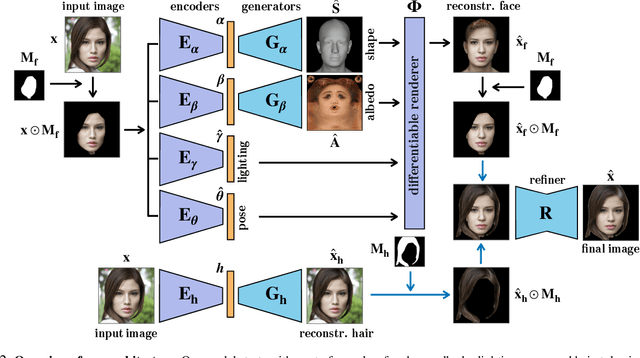

Recent advances in generative adversarial networks (GANs) have led to remarkable achievements in face image synthesis. While methods that use style-based GANs can generate strikingly photorealistic face images, it is often difficult to control the characteristics of the generated faces in a meaningful and disentangled way. Prior approaches aim to achieve such semantic control and disentanglement within the latent space of a previously trained GAN. In contrast, we propose a framework that a priori models physical attributes of the face such as 3D shape, albedo, pose, and lighting explicitly, thus providing disentanglement by design. Our method, MOST-GAN, integrates the expressive power and photorealism of style-based GANs with the physical disentanglement and flexibility of nonlinear 3D morphable models, which we couple with a state-of-the-art 2D hair manipulation network. MOST-GAN achieves photorealistic manipulation of portrait images with fully disentangled 3D control over their physical attributes, enabling extreme manipulation of lighting, facial expression, and pose variations up to full profile view.
Audio-Visual Scene-Aware Dialog and Reasoning using Audio-Visual Transformers with Joint Student-Teacher Learning
Oct 13, 2021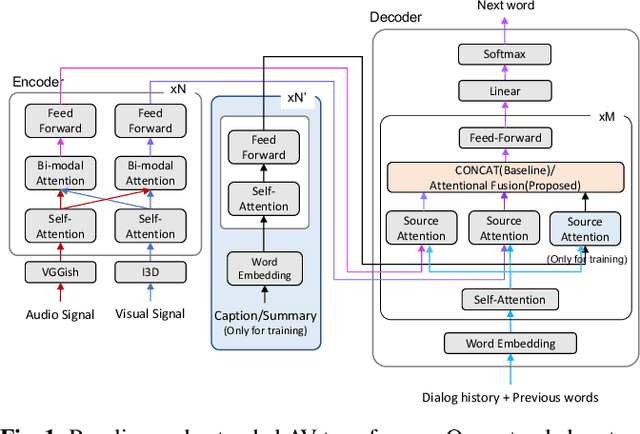
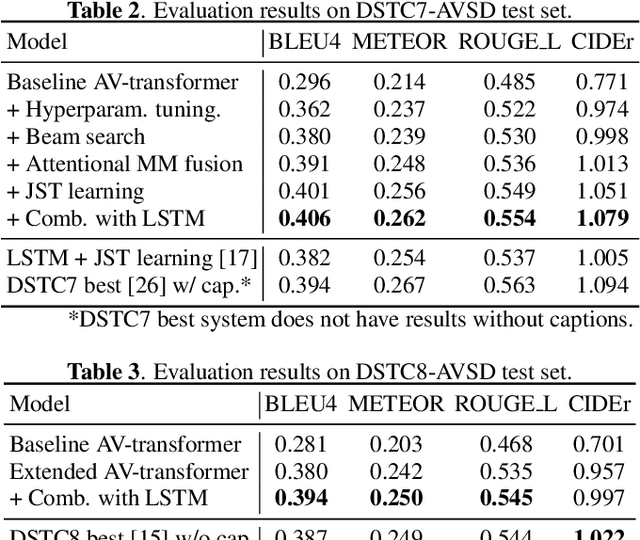
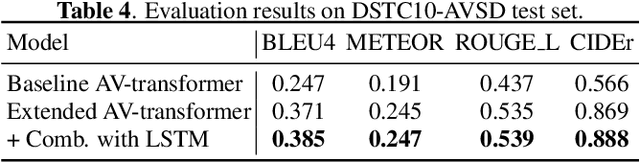
In previous work, we have proposed the Audio-Visual Scene-Aware Dialog (AVSD) task, collected an AVSD dataset, developed AVSD technologies, and hosted an AVSD challenge track at both the 7th and 8th Dialog System Technology Challenges (DSTC7, DSTC8). In these challenges, the best-performing systems relied heavily on human-generated descriptions of the video content, which were available in the datasets but would be unavailable in real-world applications. To promote further advancements for real-world applications, we proposed a third AVSD challenge, at DSTC10, with two modifications: 1) the human-created description is unavailable at inference time, and 2) systems must demonstrate temporal reasoning by finding evidence from the video to support each answer. This paper introduces the new task that includes temporal reasoning and our new extension of the AVSD dataset for DSTC10, for which we collected human-generated temporal reasoning data. We also introduce a baseline system built using an AV-transformer, which we released along with the new dataset. Finally, this paper introduces a new system that extends our baseline system with attentional multimodal fusion, joint student-teacher learning (JSTL), and model combination techniques, achieving state-of-the-art performances on the AVSD datasets for DSTC7, DSTC8, and DSTC10. We also propose two temporal reasoning methods for AVSD: one attention-based, and one based on a time-domain region proposal network.
A Hierarchical Variational Neural Uncertainty Model for Stochastic Video Prediction
Oct 06, 2021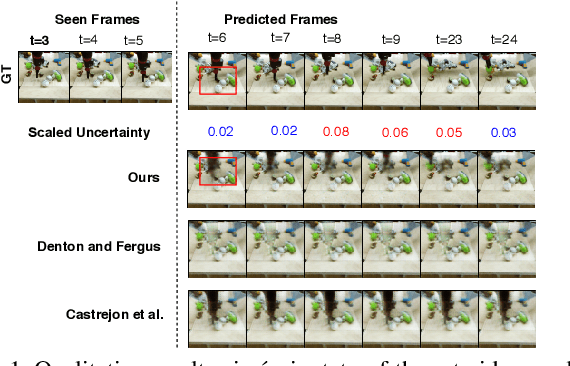
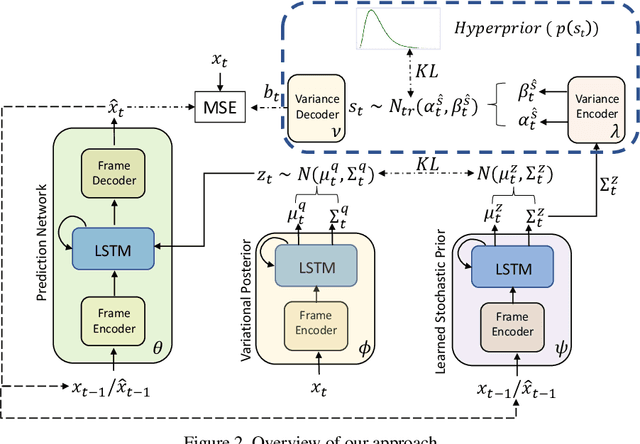
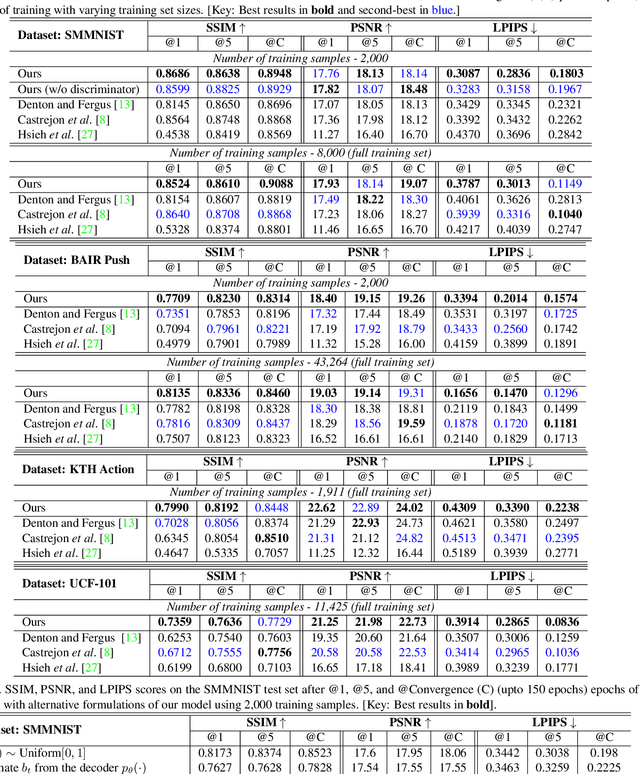
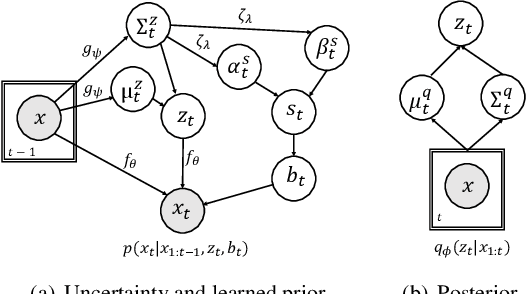
Predicting the future frames of a video is a challenging task, in part due to the underlying stochastic real-world phenomena. Prior approaches to solve this task typically estimate a latent prior characterizing this stochasticity, however do not account for the predictive uncertainty of the (deep learning) model. Such approaches often derive the training signal from the mean-squared error (MSE) between the generated frame and the ground truth, which can lead to sub-optimal training, especially when the predictive uncertainty is high. Towards this end, we introduce Neural Uncertainty Quantifier (NUQ) - a stochastic quantification of the model's predictive uncertainty, and use it to weigh the MSE loss. We propose a hierarchical, variational framework to derive NUQ in a principled manner using a deep, Bayesian graphical model. Our experiments on four benchmark stochastic video prediction datasets show that our proposed framework trains more effectively compared to the state-of-the-art models (especially when the training sets are small), while demonstrating better video generation quality and diversity against several evaluation metrics.
Visual Scene Graphs for Audio Source Separation
Sep 24, 2021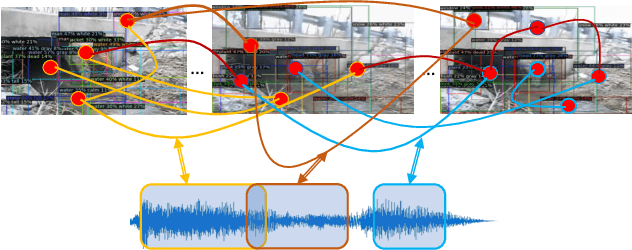
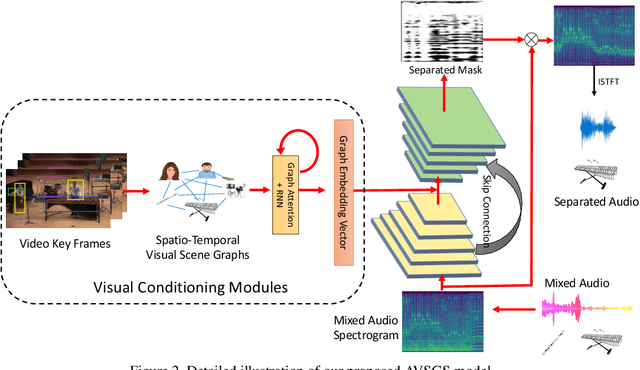
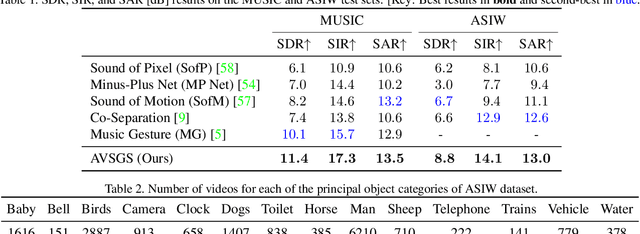
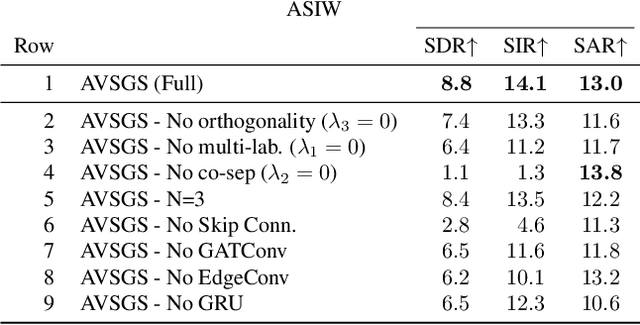
State-of-the-art approaches for visually-guided audio source separation typically assume sources that have characteristic sounds, such as musical instruments. These approaches often ignore the visual context of these sound sources or avoid modeling object interactions that may be useful to better characterize the sources, especially when the same object class may produce varied sounds from distinct interactions. To address this challenging problem, we propose Audio Visual Scene Graph Segmenter (AVSGS), a novel deep learning model that embeds the visual structure of the scene as a graph and segments this graph into subgraphs, each subgraph being associated with a unique sound obtained by co-segmenting the audio spectrogram. At its core, AVSGS uses a recursive neural network that emits mutually-orthogonal sub-graph embeddings of the visual graph using multi-head attention. These embeddings are used for conditioning an audio encoder-decoder towards source separation. Our pipeline is trained end-to-end via a self-supervised task consisting of separating audio sources using the visual graph from artificially mixed sounds. In this paper, we also introduce an "in the wild'' video dataset for sound source separation that contains multiple non-musical sources, which we call Audio Separation in the Wild (ASIW). This dataset is adapted from the AudioCaps dataset, and provides a challenging, natural, and daily-life setting for source separation. Thorough experiments on the proposed ASIW and the standard MUSIC datasets demonstrate state-of-the-art sound separation performance of our method against recent prior approaches.
InSeGAN: A Generative Approach to Segmenting Identical Instances in Depth Images
Aug 31, 2021
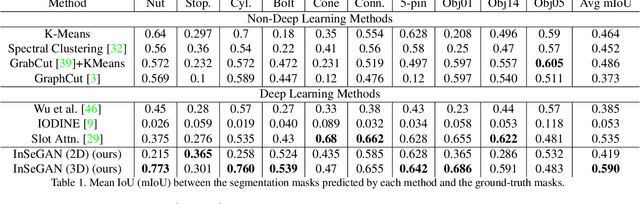
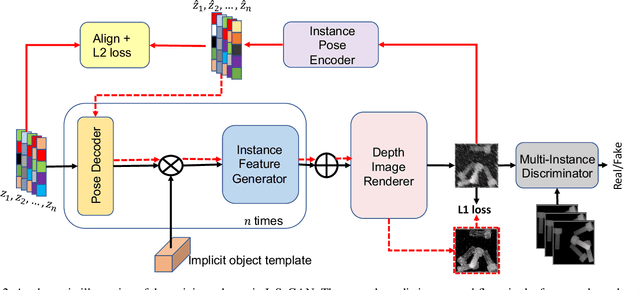
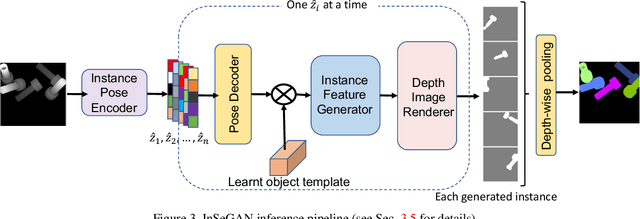
In this paper, we present InSeGAN, an unsupervised 3D generative adversarial network (GAN) for segmenting (nearly) identical instances of rigid objects in depth images. Using an analysis-by-synthesis approach, we design a novel GAN architecture to synthesize a multiple-instance depth image with independent control over each instance. InSeGAN takes in a set of code vectors (e.g., random noise vectors), each encoding the 3D pose of an object that is represented by a learned implicit object template. The generator has two distinct modules. The first module, the instance feature generator, uses each encoded pose to transform the implicit template into a feature map representation of each object instance. The second module, the depth image renderer, aggregates all of the single-instance feature maps output by the first module and generates a multiple-instance depth image. A discriminator distinguishes the generated multiple-instance depth images from the distribution of true depth images. To use our model for instance segmentation, we propose an instance pose encoder that learns to take in a generated depth image and reproduce the pose code vectors for all of the object instances. To evaluate our approach, we introduce a new synthetic dataset, "Insta-10", consisting of 100,000 depth images, each with 5 instances of an object from one of 10 classes. Our experiments on Insta-10, as well as on real-world noisy depth images, show that InSeGAN achieves state-of-the-art performance, often outperforming prior methods by large margins.
Generalized One-Class Learning Using Pairs of Complementary Classifiers
Jun 24, 2021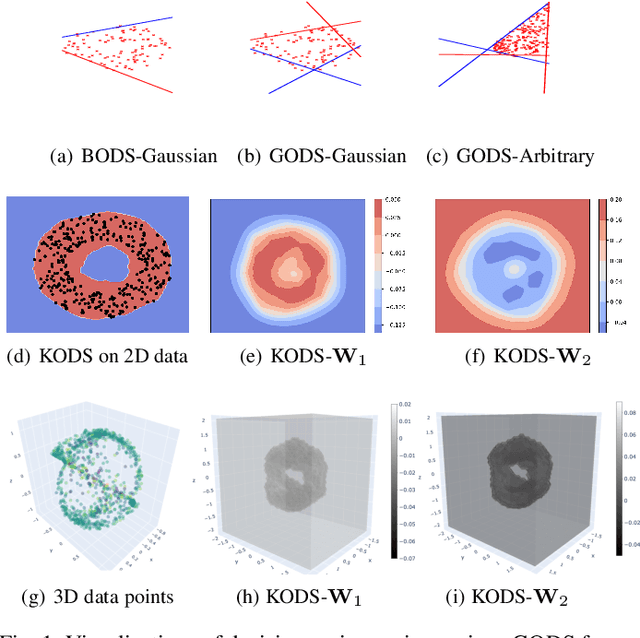
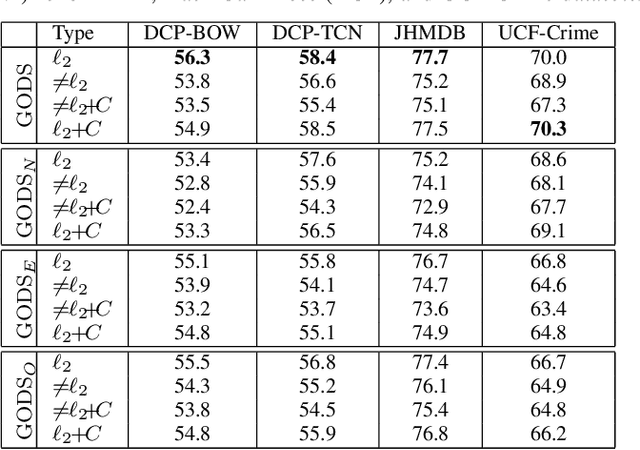
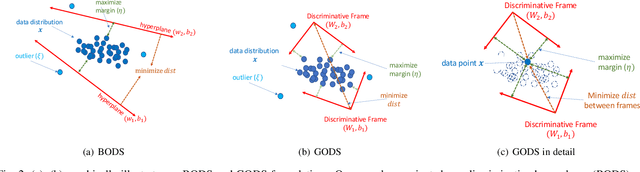
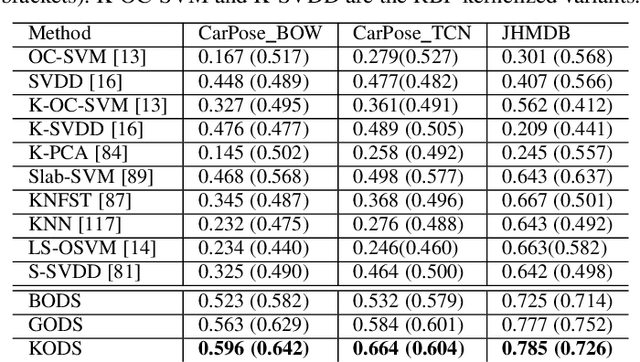
One-class learning is the classic problem of fitting a model to the data for which annotations are available only for a single class. In this paper, we explore novel objectives for one-class learning, which we collectively refer to as Generalized One-class Discriminative Subspaces (GODS). Our key idea is to learn a pair of complementary classifiers to flexibly bound the one-class data distribution, where the data belongs to the positive half-space of one of the classifiers in the complementary pair and to the negative half-space of the other. To avoid redundancy while allowing non-linearity in the classifier decision surfaces, we propose to design each classifier as an orthonormal frame and seek to learn these frames via jointly optimizing for two conflicting objectives, namely: i) to minimize the distance between the two frames, and ii) to maximize the margin between the frames and the data. The learned orthonormal frames will thus characterize a piecewise linear decision surface that allows for efficient inference, while our objectives seek to bound the data within a minimal volume that maximizes the decision margin, thereby robustly capturing the data distribution. We explore several variants of our formulation under different constraints on the constituent classifiers, including kernelized feature maps. We demonstrate the empirical benefits of our approach via experiments on data from several applications in computer vision, such as anomaly detection in video sequences, human poses, and human activities. We also explore the generality and effectiveness of GODS for non-vision tasks via experiments on several UCI datasets, demonstrating state-of-the-art results.