 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeader Stochastic Gradient Descent for Distributed Training of Deep Learning Models
May 24, 2019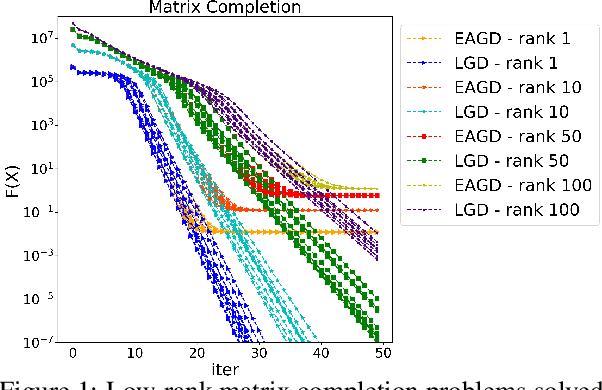
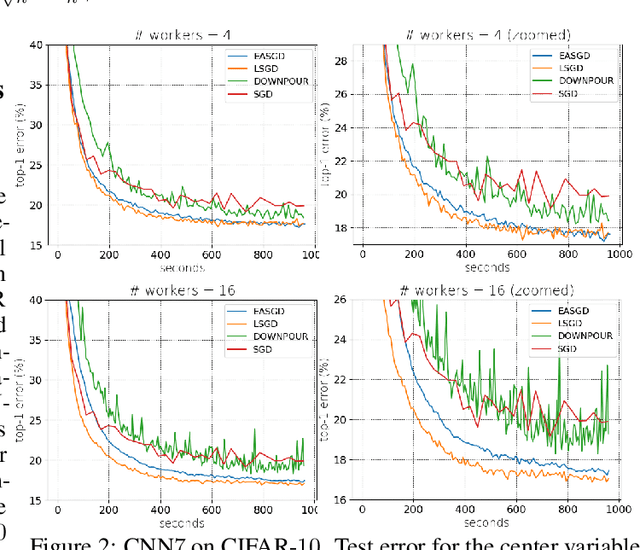


We consider distributed optimization under communication constraints for training deep learning models. We propose a new algorithm, whose parameter updates rely on two forces: a regular gradient step, and a corrective direction dictated by the currently best-performing worker (leader). Our method differs from the parameter-averaging scheme EASGD in a number of ways: (i) our objective formulation does not change the location of stationary points compared to the original optimization problem; (ii) we avoid convergence decelerations caused by pulling local workers descending to different local minima to each other (i.e. to the average of their parameters); (iii) our update by design breaks the curse of symmetry (the phenomenon of being trapped in poorly generalizing sub-optimal solutions in symmetric non-convex landscapes); and (iv) our approach is more communication efficient since it broadcasts only parameters of the leader rather than all workers. We provide theoretical analysis of the batch version of the proposed algorithm, which we call Leader Gradient Descent (LGD), and its stochastic variant (LSGD). Finally, we implement an asynchronous version of our algorithm and extend it to the multi-leader setting, where we form groups of workers, each represented by its own local leader (the best performer in a group), and update each worker with a corrective direction comprised of two attractive forces: one to the local, and one to the global leader (the best performer among all workers). The multi-leader setting is well-aligned with current hardware architecture, where local workers forming a group lie within a single computational node and different groups correspond to different nodes. For training convolutional neural networks, we empirically demonstrate that our approach compares favorably to state-of-the-art baselines.
Skin Lesion Segmentation and Classification with Deep Learning System
Feb 16, 2019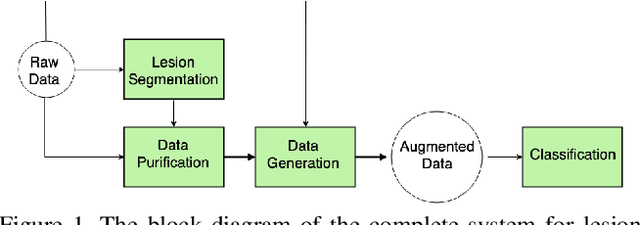
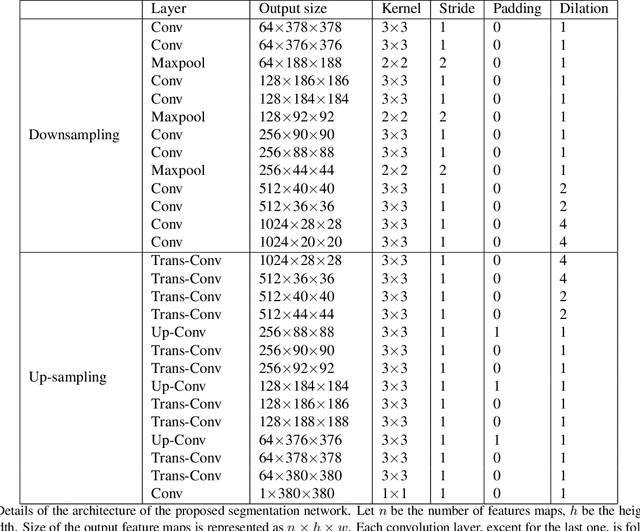
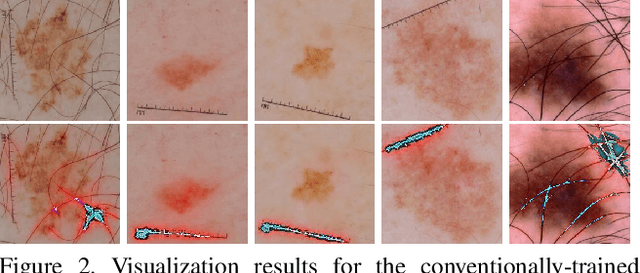
Melanoma is one of the ten most common cancers in the US. Early detection is crucial for survival, but often the cancer is diagnosed in the fatal stage. Deep learning has the potential to improve cancer detection rates, but its applicability to melanoma detection is compromised by the limitations of the available skin lesion databases, which are small, heavily imbalanced, and contain images with occlusions. We propose a complete deep learning system for lesion segmentation and classification that utilizes networks specialized in data purification and augmentation. It contains the processing unit for removing image occlusions and the data generation unit for populating scarce lesion classes, or equivalently creating virtual patients with pre-defined types of lesions. We empirically verify our approach and show superior performance over common baselines.
Adversarial Learning-Based On-Line Anomaly Monitoring for Assured Autonomy
Nov 12, 2018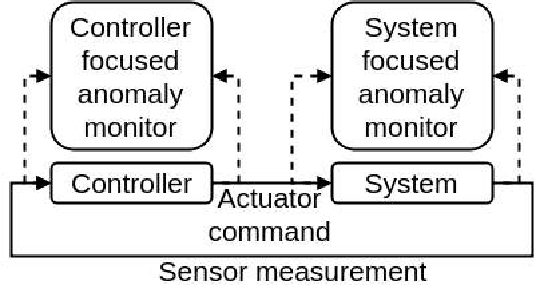
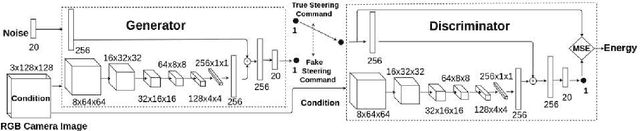
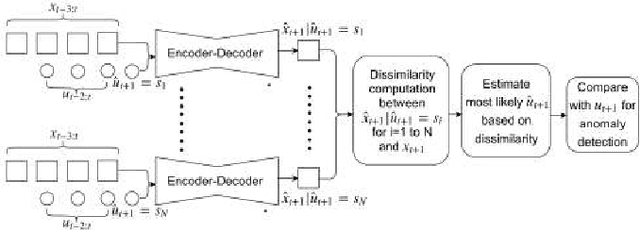
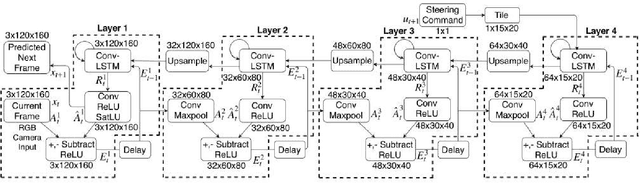
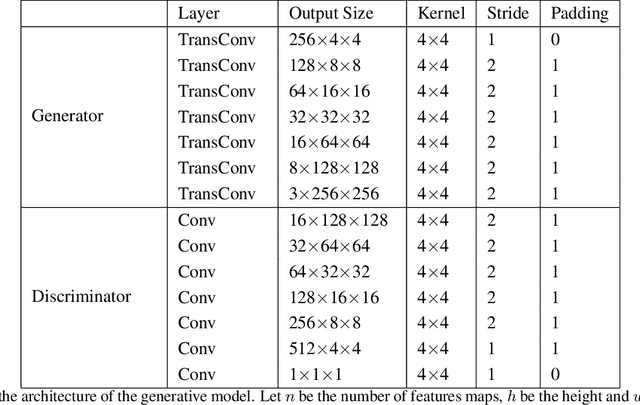
The paper proposes an on-line monitoring framework for continuous real-time safety/security in learning-based control systems (specifically application to a unmanned ground vehicle). We monitor validity of mappings from sensor inputs to actuator commands, controller-focused anomaly detection (CFAM), and from actuator commands to sensor inputs, system-focused anomaly detection (SFAM). CFAM is an image conditioned energy based generative adversarial network (EBGAN) in which the energy based discriminator distinguishes between proper and anomalous actuator commands. SFAM is based on an action condition video prediction framework to detect anomalies between predicted and observed temporal evolution of sensor data. We demonstrate the effectiveness of the approach on our autonomous ground vehicle for indoor environments and on Udacity dataset for outdoor environments.
Beyond Backprop: Online Alternating Minimization with Auxiliary Variables
Oct 24, 2018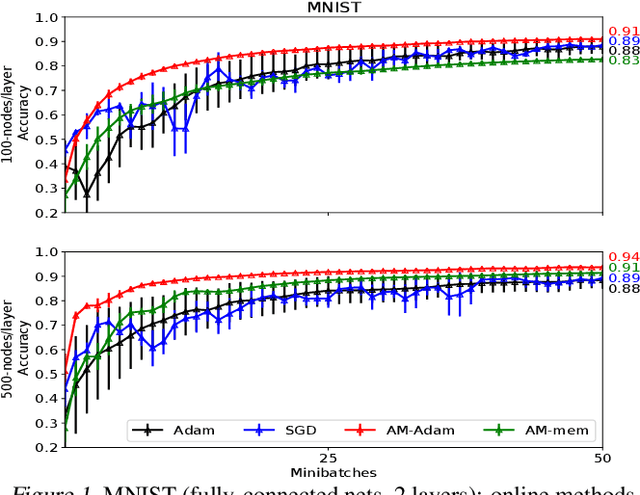
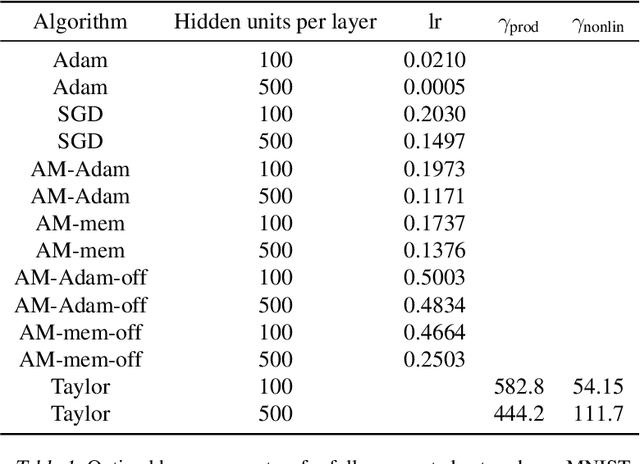
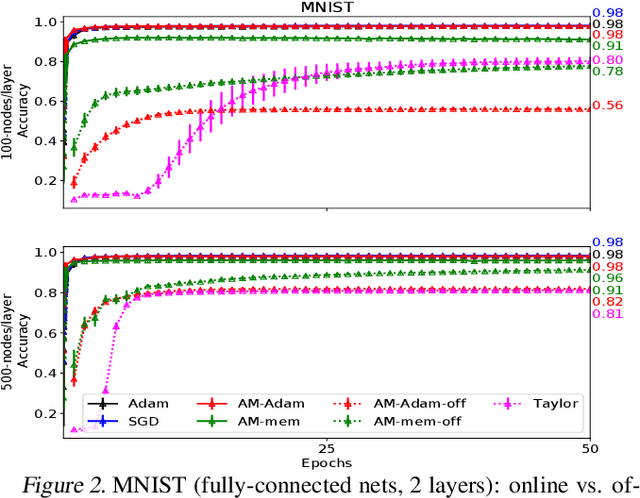
We propose a novel online alternating minimization (AltMin) algorithm for training deep neural networks, provide theoretical convergence guarantees and demonstrate its advantages on several classification tasks as compared both to standard backpropagation with stochastic gradient descent (backprop-SGD) and to offline alternating minimization. The key difference from backpropagation is an explicit optimization over hidden activations, which eliminates gradient chain computation in backprop, and breaks the weight training problem into independent, local optimization subproblems; this allows to avoid vanishing gradient issues, simplify handling non-differentiable nonlinearities, and perform parallel weight updates across the layers. Moreover, parallel local synaptic weight optimization with explicit activation propagation is a step closer to a more biologically plausible learning model than backpropagation, whose biological implausibility has been frequently criticized. Finally, the online nature of our approach allows to handle very large datasets, as well as continual, lifelong learning, which is our key contribution on top of recently proposed offline alternating minimization schemes (e.g., (Carreira-Perpinan andWang 2014), (Taylor et al. 2016)).
VisualBackProp for learning using privileged information with CNNs
May 24, 2018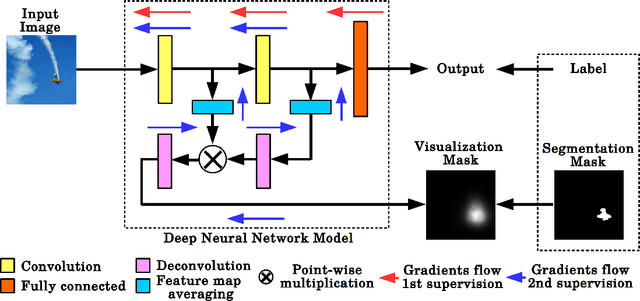
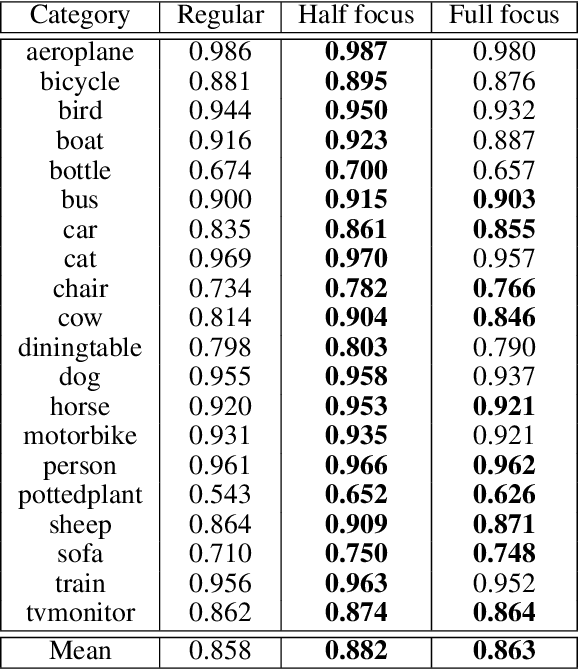

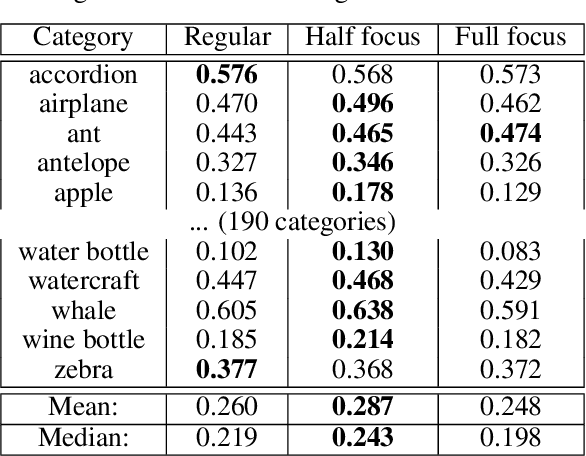
In many machine learning applications, from medical diagnostics to autonomous driving, the availability of prior knowledge can be used to improve the predictive performance of learning algorithms and incorporate `physical,' `domain knowledge,' or `common sense' concepts into training of machine learning systems as well as verify constraints/properties of the systems. We explore the learning using privileged information paradigm and show how to incorporate the privileged information, such as segmentation mask available along with the classification label of each example, into the training stage of convolutional neural networks. This is done by augmenting the CNN model with an architectural component that effectively focuses model's attention on the desired region of the input image during the training process and that is transparent to the network's label prediction mechanism at testing. This component effectively corresponds to the visualization strategy for identifying the parts of the input, often referred to as visualization mask, that most contribute to the prediction, yet uses this strategy in reverse to the classical setting in order to enforce the desired visualization mask instead. We verify our proposed algorithms through exhaustive experiments on benchmark ImageNet and PASCAL VOC data sets and achieve improvements in the performance of $2.4\%$ and $2.7\%$ over standard single-supervision model training. Finally, we confirm the effectiveness of our approach on skin lesion classification problem.
A Deep Unsupervised Learning Approach Toward MTBI Identification Using Diffusion MRI
Apr 11, 2018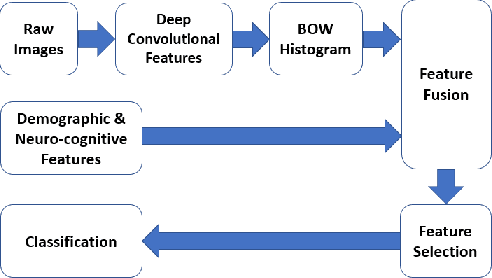
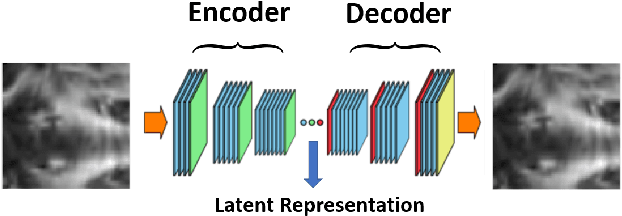
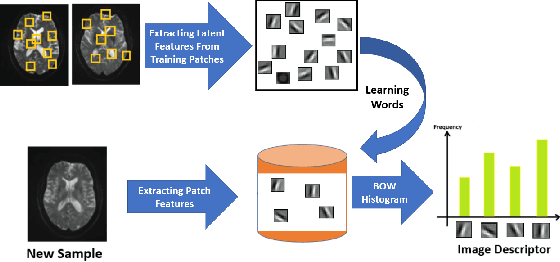
Mild traumatic brain injury is a growing public health problem with an estimated incidence of over 1.7 million people annually in US. Diagnosis is based on clinical history and symptoms, and accurate, concrete measures of injury are lacking. This work aims to directly use diffusion MR images obtained within one month of trauma to detect injury, by incorporating deep learning techniques. To overcome the challenge due to limited training data, we describe each brain region using the bag of word representation, which specifies the distribution of representative patch patterns. We apply a convolutional auto-encoder to learn the patch-level features, from overlapping image patches extracted from the MR images, to learn features from diffusion MR images of brain using an unsupervised approach. Our experimental results show that the bag of word representation using patch level features learnt by the auto encoder provides similar performance as that using the raw patch patterns, both significantly outperform earlier work relying on the mean values of MR metrics in selected brain regions.
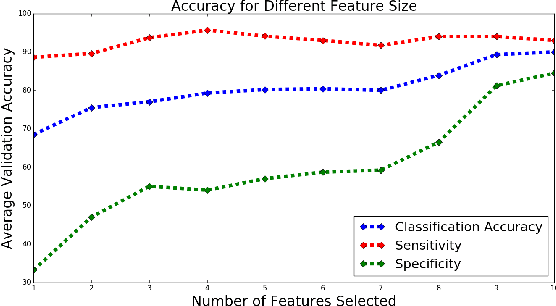
LSALSA: efficient sparse coding in single and multiple dictionary settings
Feb 13, 2018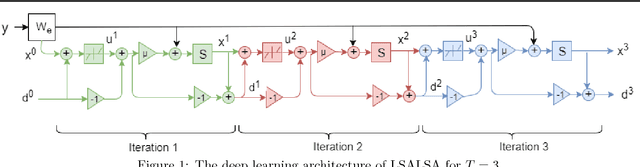
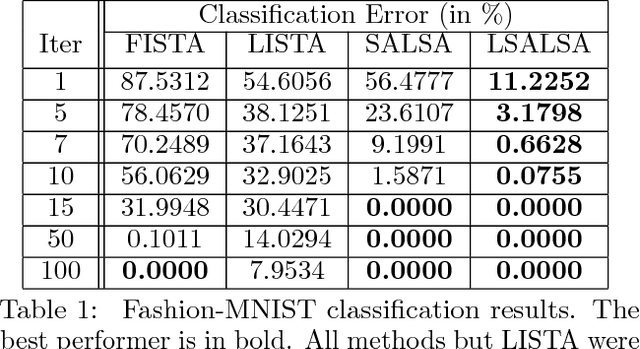
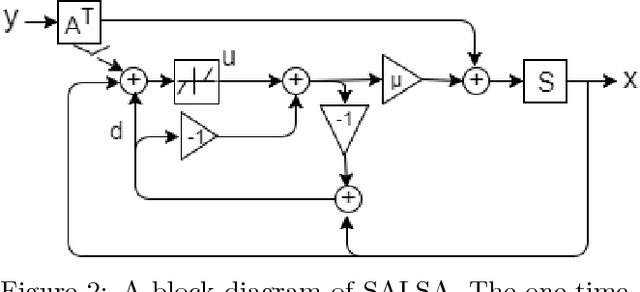
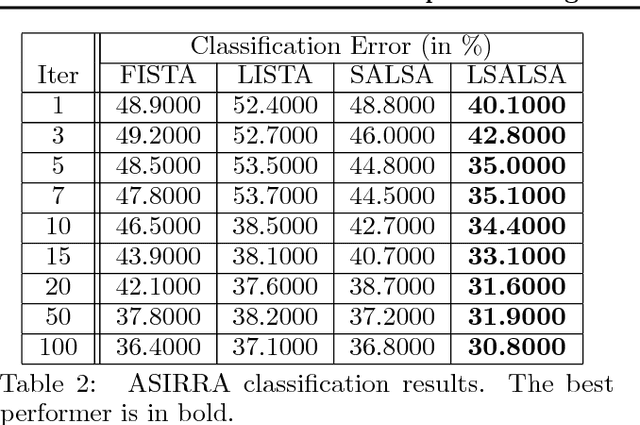
We propose an efficient sparse coding (SC) framework for obtaining sparse representation of data. The proposed framework is very general and applies to both the single dictionary setting, where each data point is represented as a sparse combination of the columns of one dictionary matrix, as well as the multiple dictionary setting as given in morphological component analysis (MCA), where the goal is to separate the data into additive parts such that each part has distinct sparse representation within an appropriately chosen corresponding dictionary. Both tasks have been cast as $\ell_1$-regularized optimization problems of minimizing quadratic reconstruction error. In an effort to accelerate traditional acquisition of sparse codes, we propose a deep learning architecture that constitutes a trainable time-unfolded version of the Split Augmented Lagrangian Shrinkage Algorithm (SALSA), a special case of the alternating direction method of multipliers (ADMM). We empirically validate both variants of the algorithm on image vision tasks and demonstrate that at inference our networks achieve improvements in terms of the running time and the quality of estimated sparse codes on both classic SC and MCA problems over more common baselines. We finally demonstrate the visual advantage of our technique on the task of source separation.
Invertible Autoencoder for domain adaptation
Feb 10, 2018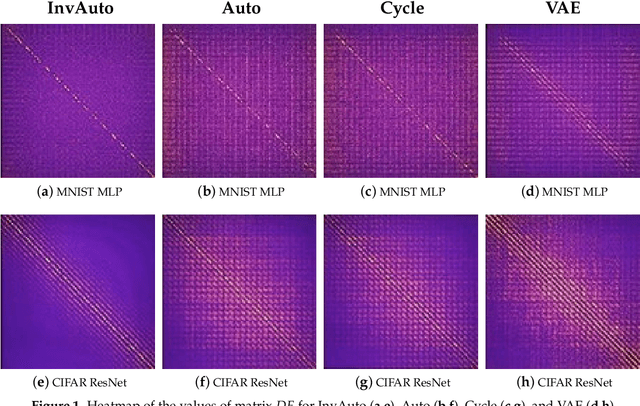
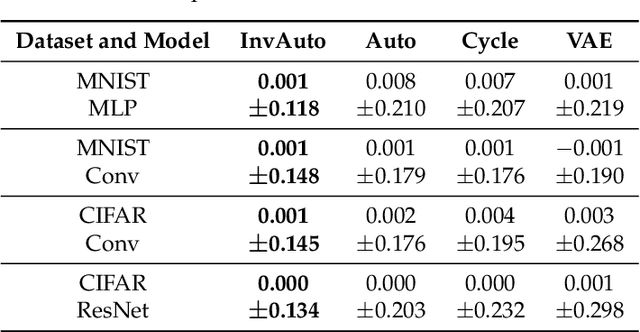
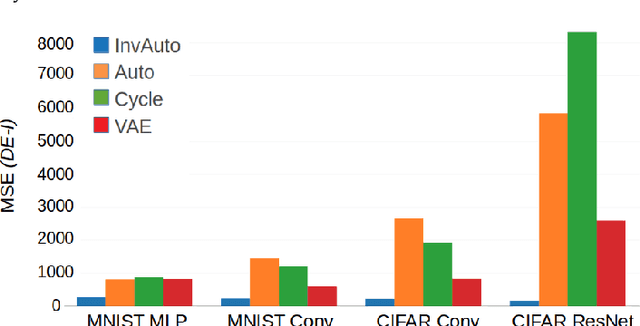
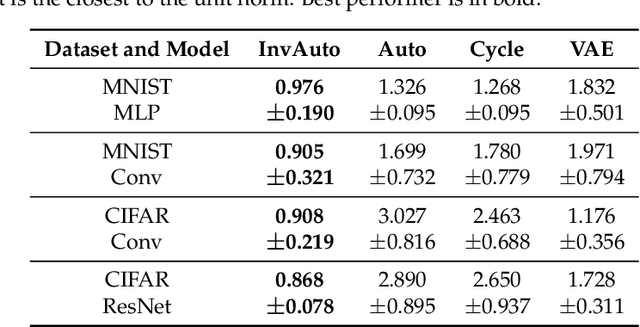
The unsupervised image-to-image translation aims at finding a mapping between the source ($A$) and target ($B$) image domains, where in many applications aligned image pairs are not available at training. This is an ill-posed learning problem since it requires inferring the joint probability distribution from marginals. Joint learning of coupled mappings $F_{AB}: A \rightarrow B$ and $F_{BA}: B \rightarrow A$ is commonly used by the state-of-the-art methods, like CycleGAN [Zhu et al., 2017], to learn this translation by introducing cycle consistency requirement to the learning problem, i.e. $F_{AB}(F_{BA}(B)) \approx B$ and $F_{BA}(F_{AB}(A)) \approx A$. Cycle consistency enforces the preservation of the mutual information between input and translated images. However, it does not explicitly enforce $F_{BA}$ to be an inverse operation to $F_{AB}$. We propose a new deep architecture that we call invertible autoencoder (InvAuto) to explicitly enforce this relation. This is done by forcing an encoder to be an inverted version of the decoder, where corresponding layers perform opposite mappings and share parameters. The mappings are constrained to be orthonormal. The resulting architecture leads to the reduction of the number of trainable parameters (up to $2$ times). We present image translation results on benchmark data sets and demonstrate state-of-the art performance of our approach. Finally, we test the proposed domain adaptation method on the task of road video conversion. We demonstrate that the videos converted with InvAuto have high quality and show that the NVIDIA neural-network-based end-to-end learning system for autonomous driving, known as PilotNet, trained on real road videos performs well when tested on the converted ones.
VisualBackProp: efficient visualization of CNNs
May 19, 2017
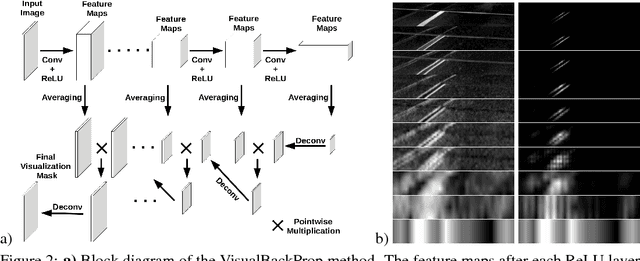
This paper proposes a new method, that we call VisualBackProp, for visualizing which sets of pixels of the input image contribute most to the predictions made by the convolutional neural network (CNN). The method heavily hinges on exploring the intuition that the feature maps contain less and less irrelevant information to the prediction decision when moving deeper into the network. The technique we propose was developed as a debugging tool for CNN-based systems for steering self-driving cars and is therefore required to run in real-time, i.e. it was designed to require less computations than a forward propagation. This makes the presented visualization method a valuable debugging tool which can be easily used during both training and inference. We furthermore justify our approach with theoretical arguments and theoretically confirm that the proposed method identifies sets of input pixels, rather than individual pixels, that collaboratively contribute to the prediction. Our theoretical findings stand in agreement with the experimental results. The empirical evaluation shows the plausibility of the proposed approach on the road video data as well as in other applications and reveals that it compares favorably to the layer-wise relevance propagation approach, i.e. it obtains similar visualization results and simultaneously achieves order of magnitude speed-ups.
Explaining How a Deep Neural Network Trained with End-to-End Learning Steers a Car
Apr 25, 2017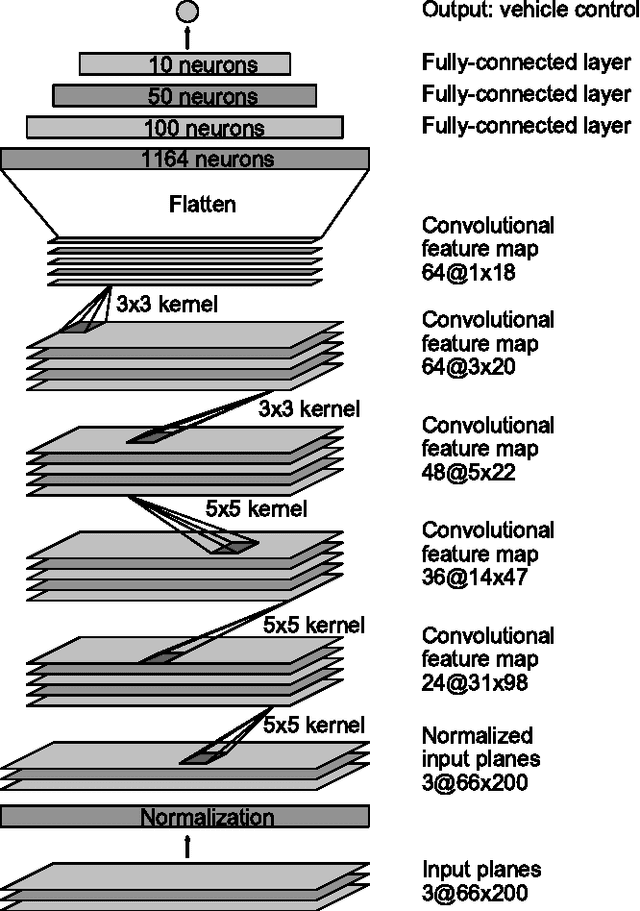
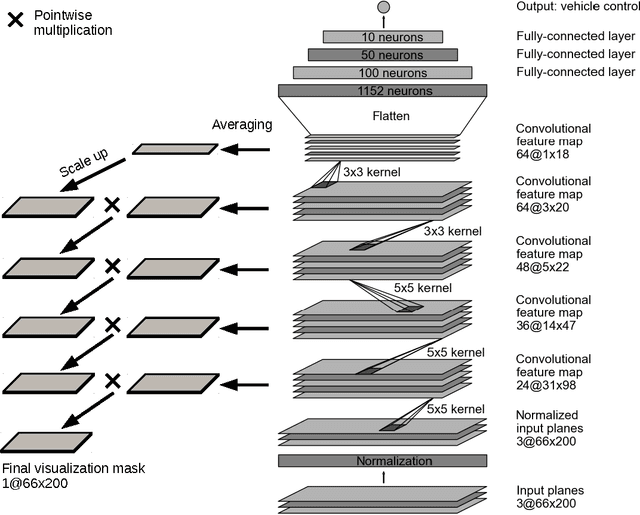

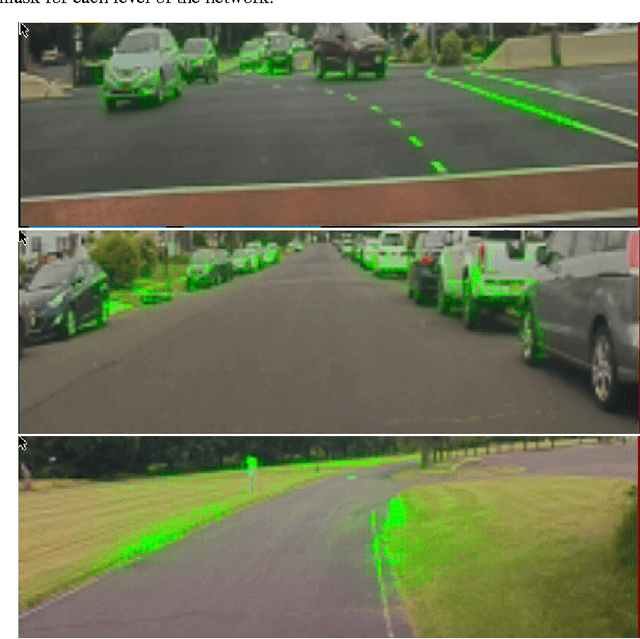
As part of a complete software stack for autonomous driving, NVIDIA has created a neural-network-based system, known as PilotNet, which outputs steering angles given images of the road ahead. PilotNet is trained using road images paired with the steering angles generated by a human driving a data-collection car. It derives the necessary domain knowledge by observing human drivers. This eliminates the need for human engineers to anticipate what is important in an image and foresee all the necessary rules for safe driving. Road tests demonstrated that PilotNet can successfully perform lane keeping in a wide variety of driving conditions, regardless of whether lane markings are present or not. The goal of the work described here is to explain what PilotNet learns and how it makes its decisions. To this end we developed a method for determining which elements in the road image most influence PilotNet's steering decision. Results show that PilotNet indeed learns to recognize relevant objects on the road. In addition to learning the obvious features such as lane markings, edges of roads, and other cars, PilotNet learns more subtle features that would be hard to anticipate and program by engineers, for example, bushes lining the edge of the road and atypical vehicle classes.