 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified Per-Instance Unlearning Using Individual Sensitivity Bounds
Feb 17, 2026Certified machine unlearning can be achieved via noise injection leading to differential privacy guarantees, where noise is calibrated to worst-case sensitivity. Such conservative calibration often results in performance degradation, limiting practical applicability. In this work, we investigate an alternative approach based on adaptive per-instance noise calibration tailored to the individual contribution of each data point to the learned solution. This raises the following challenge: how can one establish formal unlearning guarantees when the mechanism depends on the specific point to be removed? To define individual data point sensitivities in noisy gradient dynamics, we consider the use of per-instance differential privacy. For ridge regression trained via Langevin dynamics, we derive high-probability per-instance sensitivity bounds, yielding certified unlearning with substantially less noise injection. We corroborate our theoretical findings through experiments in linear settings and provide further empirical evidence on the relevance of the approach in deep learning settings.
Generalized Leverage Score for Scalable Assessment of Privacy Vulnerability
Feb 17, 2026Can the privacy vulnerability of individual data points be assessed without retraining models or explicitly simulating attacks? We answer affirmatively by showing that exposure to membership inference attack (MIA) is fundamentally governed by a data point's influence on the learned model. We formalize this in the linear setting by establishing a theoretical correspondence between individual MIA risk and the leverage score, identifying it as a principled metric for vulnerability. This characterization explains how data-dependent sensitivity translates into exposure, without the computational burden of training shadow models. Building on this, we propose a computationally efficient generalization of the leverage score for deep learning. Empirical evaluations confirm a strong correlation between the proposed score and MIA success, validating this metric as a practical surrogate for individual privacy risk assessment.
On the MIA Vulnerability Gap Between Private GANs and Diffusion Models
Sep 03, 2025Generative Adversarial Networks (GANs) and diffusion models have emerged as leading approaches for high-quality image synthesis. While both can be trained under differential privacy (DP) to protect sensitive data, their sensitivity to membership inference attacks (MIAs), a key threat to data confidentiality, remains poorly understood. In this work, we present the first unified theoretical and empirical analysis of the privacy risks faced by differentially private generative models. We begin by showing, through a stability-based analysis, that GANs exhibit fundamentally lower sensitivity to data perturbations than diffusion models, suggesting a structural advantage in resisting MIAs. We then validate this insight with a comprehensive empirical study using a standardized MIA pipeline to evaluate privacy leakage across datasets and privacy budgets. Our results consistently reveal a marked privacy robustness gap in favor of GANs, even in strong DP regimes, highlighting that model type alone can critically shape privacy leakage.
Memorization in Fine-Tuned Large Language Models
Jul 28, 2025This study investigates the mechanisms and factors influencing memorization in fine-tuned large language models (LLMs), with a focus on the medical domain due to its privacy-sensitive nature. We examine how different aspects of the fine-tuning process affect a model's propensity to memorize training data, using the PHEE dataset of pharmacovigilance events. Our research employs two main approaches: a membership inference attack to detect memorized data, and a generation task with prompted prefixes to assess verbatim reproduction. We analyze the impact of adapting different weight matrices in the transformer architecture, the relationship between perplexity and memorization, and the effect of increasing the rank in low-rank adaptation (LoRA) fine-tuning. Key findings include: (1) Value and Output matrices contribute more significantly to memorization compared to Query and Key matrices; (2) Lower perplexity in the fine-tuned model correlates with increased memorization; (3) Higher LoRA ranks lead to increased memorization, but with diminishing returns at higher ranks. These results provide insights into the trade-offs between model performance and privacy risks in fine-tuned LLMs. Our findings have implications for developing more effective and responsible strategies for adapting large language models while managing data privacy concerns.
Optimal Classification under Performative Distribution Shift
Nov 04, 2024



Performative learning addresses the increasingly pervasive situations in which algorithmic decisions may induce changes in the data distribution as a consequence of their public deployment. We propose a novel view in which these performative effects are modelled as push-forward measures. This general framework encompasses existing models and enables novel performative gradient estimation methods, leading to more efficient and scalable learning strategies. For distribution shifts, unlike previous models which require full specification of the data distribution, we only assume knowledge of the shift operator that represents the performative changes. This approach can also be integrated into various change-of-variablebased models, such as VAEs or normalizing flows. Focusing on classification with a linear-in-parameters performative effect, we prove the convexity of the performative risk under a new set of assumptions. Notably, we do not limit the strength of performative effects but rather their direction, requiring only that classification becomes harder when deploying more accurate models. In this case, we also establish a connection with adversarially robust classification by reformulating the minimization of the performative risk as a min-max variational problem. Finally, we illustrate our approach on synthetic and real datasets.
Differentially Private Gradient Flow based on the Sliced Wasserstein Distance for Non-Parametric Generative Modeling
Dec 13, 2023



Safeguarding privacy in sensitive training data is paramount, particularly in the context of generative modeling. This is done through either differentially private stochastic gradient descent, or with a differentially private metric for training models or generators. In this paper, we introduce a novel differentially private generative modeling approach based on parameter-free gradient flows in the space of probability measures. The proposed algorithm is a new discretized flow which operates through a particle scheme, utilizing drift derived from the sliced Wasserstein distance and computed in a private manner. Our experiments show that compared to a generator-based model, our proposed model can generate higher-fidelity data at a low privacy budget, offering a viable alternative to generator-based approaches.
Towards Evading the Limits of Randomized Smoothing: A Theoretical Analysis
Jun 03, 2022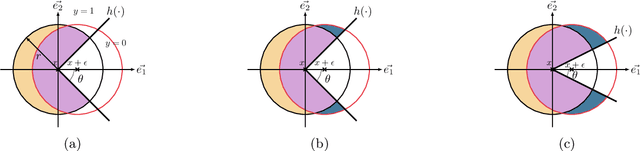
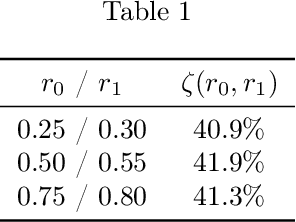
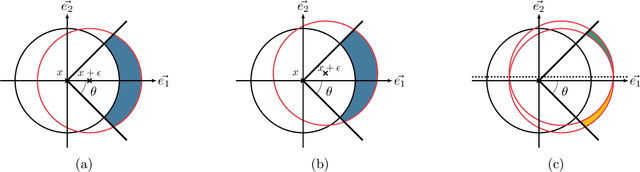
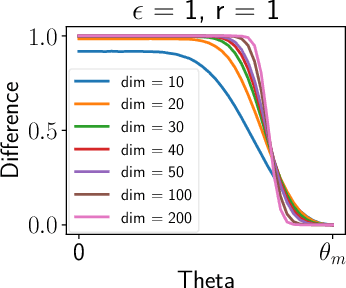
Randomized smoothing is the dominant standard for provable defenses against adversarial examples. Nevertheless, this method has recently been proven to suffer from important information theoretic limitations. In this paper, we argue that these limitations are not intrinsic, but merely a byproduct of current certification methods. We first show that these certificates use too little information about the classifier, and are in particular blind to the local curvature of the decision boundary. This leads to severely sub-optimal robustness guarantees as the dimension of the problem increases. We then show that it is theoretically possible to bypass this issue by collecting more information about the classifier. More precisely, we show that it is possible to approximate the optimal certificate with arbitrary precision, by probing the decision boundary with several noise distributions. Since this process is executed at certification time rather than at test time, it entails no loss in natural accuracy while enhancing the quality of the certificates. This result fosters further research on classifier-specific certification and demonstrates that randomized smoothing is still worth investigating. Although classifier-specific certification may induce more computational cost, we also provide some theoretical insight on how to mitigate it.
Towards Consistency in Adversarial Classification
May 20, 2022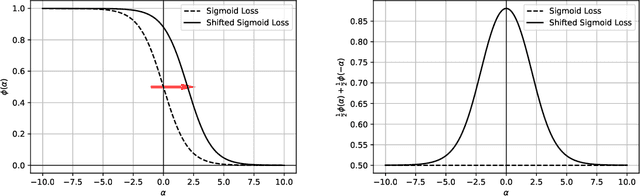
In this paper, we study the problem of consistency in the context of adversarial examples. Specifically, we tackle the following question: can surrogate losses still be used as a proxy for minimizing the $0/1$ loss in the presence of an adversary that alters the inputs at test-time? Different from the standard classification task, this question cannot be reduced to a point-wise minimization problem, and calibration needs not to be sufficient to ensure consistency. In this paper, we expose some pathological behaviors specific to the adversarial problem, and show that no convex surrogate loss can be consistent or calibrated in this context. It is therefore necessary to design another class of surrogate functions that can be used to solve the adversarial consistency issue. As a first step towards designing such a class, we identify sufficient and necessary conditions for a surrogate loss to be calibrated in both the adversarial and standard settings. Finally, we give some directions for building a class of losses that could be consistent in the adversarial framework.
Non parametric estimation of causal populations in a counterfactual scenario
Dec 08, 2021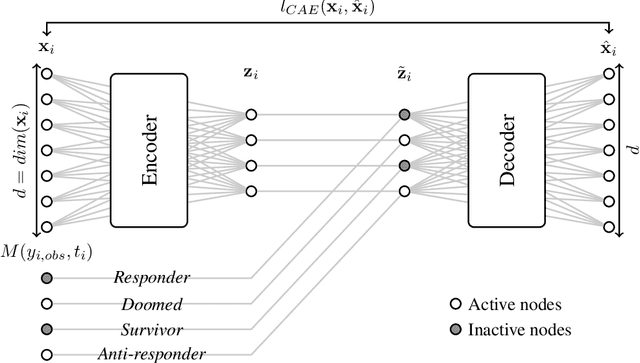
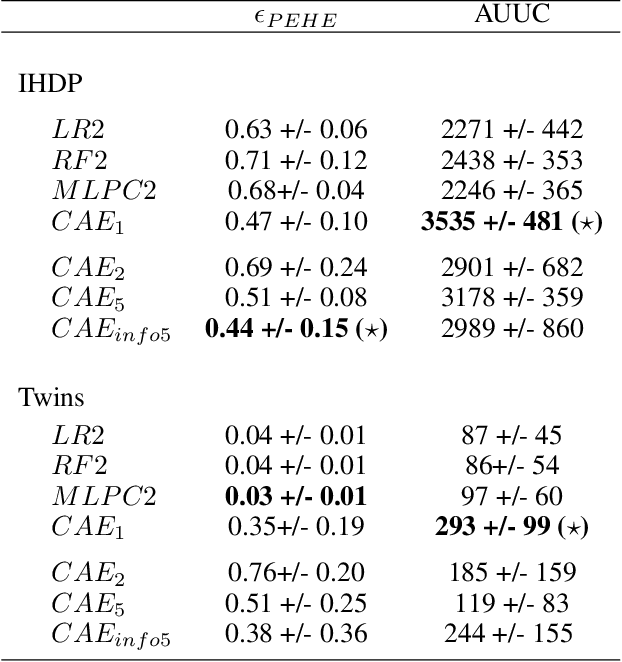
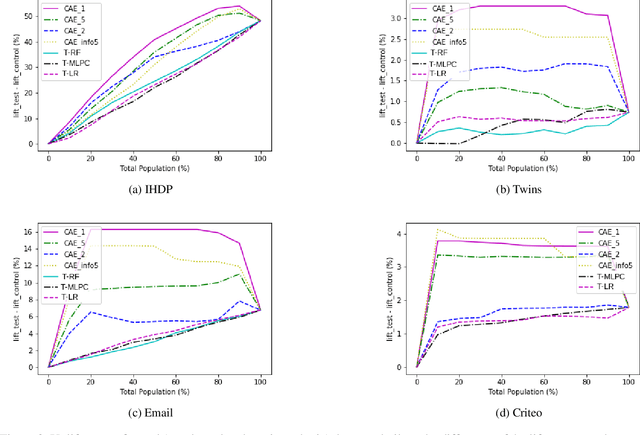
In causality, estimating the effect of a treatment without confounding inference remains a major issue because requires to assess the outcome in both case with and without treatment. Not being able to observe simultaneously both of them, the estimation of potential outcome remains a challenging task. We propose an innovative approach where the problem is reformulated as a missing data model. The aim is to estimate the hidden distribution of \emph{causal populations}, defined as a function of treatment and outcome. A Causal Auto-Encoder (CAE), enhanced by a prior dependent on treatment and outcome information, assimilates the latent space to the probability distribution of the target populations. The features are reconstructed after being reduced to a latent space and constrained by a mask introduced in the intermediate layer of the network, containing treatment and outcome information.
Two-sided fairness in rankings via Lorenz dominance
Oct 28, 2021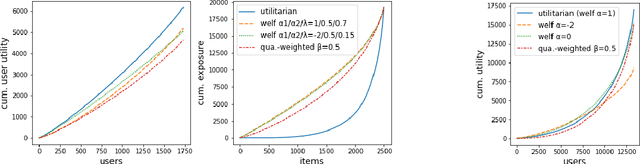
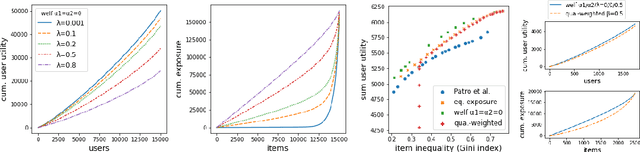
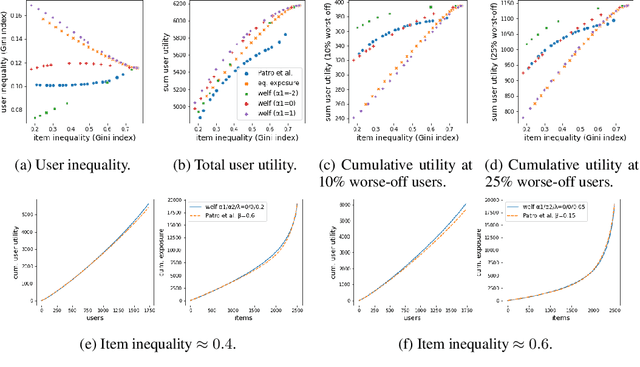
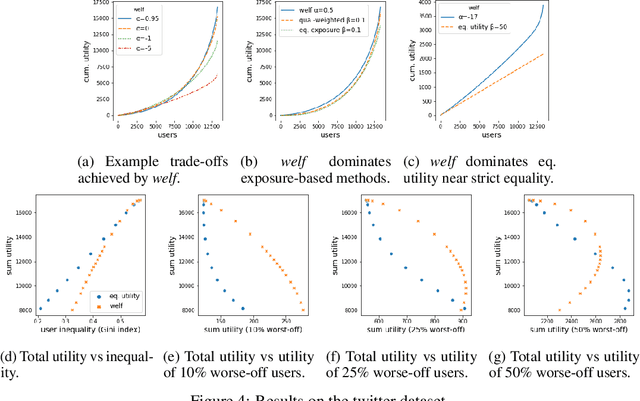
We consider the problem of generating rankings that are fair towards both users and item producers in recommender systems. We address both usual recommendation (e.g., of music or movies) and reciprocal recommendation (e.g., dating). Following concepts of distributive justice in welfare economics, our notion of fairness aims at increasing the utility of the worse-off individuals, which we formalize using the criterion of Lorenz efficiency. It guarantees that rankings are Pareto efficient, and that they maximally redistribute utility from better-off to worse-off, at a given level of overall utility. We propose to generate rankings by maximizing concave welfare functions, and develop an efficient inference procedure based on the Frank-Wolfe algorithm. We prove that unlike existing approaches based on fairness constraints, our approach always produces fair rankings. Our experiments also show that it increases the utility of the worse-off at lower costs in terms of overall utility.