 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualBackProp: efficient visualization of CNNs
Paper and Code

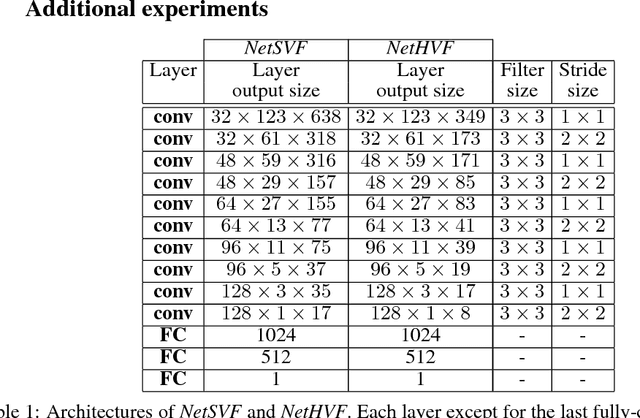
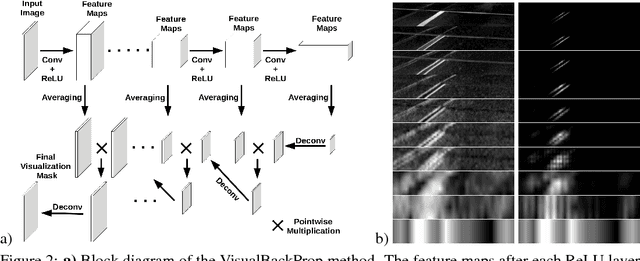
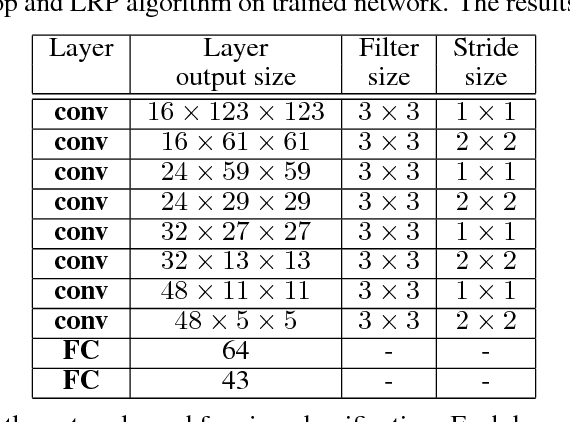
This paper proposes a new method, that we call VisualBackProp, for visualizing which sets of pixels of the input image contribute most to the predictions made by the convolutional neural network (CNN). The method heavily hinges on exploring the intuition that the feature maps contain less and less irrelevant information to the prediction decision when moving deeper into the network. The technique we propose was developed as a debugging tool for CNN-based systems for steering self-driving cars and is therefore required to run in real-time, i.e. it was designed to require less computations than a forward propagation. This makes the presented visualization method a valuable debugging tool which can be easily used during both training and inference. We furthermore justify our approach with theoretical arguments and theoretically confirm that the proposed method identifies sets of input pixels, rather than individual pixels, that collaboratively contribute to the prediction. Our theoretical findings stand in agreement with the experimental results. The empirical evaluation shows the plausibility of the proposed approach on the road video data as well as in other applications and reveals that it compares favorably to the layer-wise relevance propagation approach, i.e. it obtains similar visualization results and simultaneously achieves order of magnitude speed-ups.