 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootsTAP: Bootstrapped Training for Tracking-Any-Point
Feb 01, 2024



To endow models with greater understanding of physics and motion, it is useful to enable them to perceive how solid surfaces move and deform in real scenes. This can be formalized as Tracking-Any-Point (TAP), which requires the algorithm to be able to track any point corresponding to a solid surface in a video, potentially densely in space and time. Large-scale ground-truth training data for TAP is only available in simulation, which currently has limited variety of objects and motion. In this work, we demonstrate how large-scale, unlabeled, uncurated real-world data can improve a TAP model with minimal architectural changes, using a self-supervised student-teacher setup. We demonstrate state-of-the-art performance on the TAP-Vid benchmark surpassing previous results by a wide margin: for example, TAP-Vid-DAVIS performance improves from 61.3% to 66.4%, and TAP-Vid-Kinetics from 57.2% to 61.5%.
Helping Hands: An Object-Aware Ego-Centric Video Recognition Model
Aug 15, 2023We introduce an object-aware decoder for improving the performance of spatio-temporal representations on ego-centric videos. The key idea is to enhance object-awareness during training by tasking the model to predict hand positions, object positions, and the semantic label of the objects using paired captions when available. At inference time the model only requires RGB frames as inputs, and is able to track and ground objects (although it has not been trained explicitly for this). We demonstrate the performance of the object-aware representations learnt by our model, by: (i) evaluating it for strong transfer, i.e. through zero-shot testing, on a number of downstream video-text retrieval and classification benchmarks; and (ii) by using the representations learned as input for long-term video understanding tasks (e.g. Episodic Memory in Ego4D). In all cases the performance improves over the state of the art -- even compared to networks trained with far larger batch sizes. We also show that by using noisy image-level detection as pseudo-labels in training, the model learns to provide better bounding boxes using video consistency, as well as grounding the words in the associated text descriptions. Overall, we show that the model can act as a drop-in replacement for an ego-centric video model to improve performance through visual-text grounding.
TAPIR: Tracking Any Point with per-frame Initialization and temporal Refinement
Jun 14, 2023We present a novel model for Tracking Any Point (TAP) that effectively tracks any queried point on any physical surface throughout a video sequence. Our approach employs two stages: (1) a matching stage, which independently locates a suitable candidate point match for the query point on every other frame, and (2) a refinement stage, which updates both the trajectory and query features based on local correlations. The resulting model surpasses all baseline methods by a significant margin on the TAP-Vid benchmark, as demonstrated by an approximate 20% absolute average Jaccard (AJ) improvement on DAVIS. Our model facilitates fast inference on long and high-resolution video sequences. On a modern GPU, our implementation has the capacity to track points faster than real-time. Visualizations, source code, and pretrained models can be found on our project webpage.
Perception Test: A Diagnostic Benchmark for Multimodal Video Models
May 23, 2023



We propose a novel multimodal video benchmark - the Perception Test - to evaluate the perception and reasoning skills of pre-trained multimodal models (e.g. Flamingo, BEiT-3, or GPT-4). Compared to existing benchmarks that focus on computational tasks (e.g. classification, detection or tracking), the Perception Test focuses on skills (Memory, Abstraction, Physics, Semantics) and types of reasoning (descriptive, explanatory, predictive, counterfactual) across video, audio, and text modalities, to provide a comprehensive and efficient evaluation tool. The benchmark probes pre-trained models for their transfer capabilities, in a zero-shot / few-shot or limited finetuning regime. For these purposes, the Perception Test introduces 11.6k real-world videos, 23s average length, designed to show perceptually interesting situations, filmed by around 100 participants worldwide. The videos are densely annotated with six types of labels (multiple-choice and grounded video question-answers, object and point tracks, temporal action and sound segments), enabling both language and non-language evaluations. The fine-tuning and validation splits of the benchmark are publicly available (CC-BY license), in addition to a challenge server with a held-out test split. Human baseline results compared to state-of-the-art video QA models show a significant gap in performance (91.4% vs 43.6%), suggesting that there is significant room for improvement in multimodal video understanding. Dataset, baselines code, and challenge server are available at https://github.com/deepmind/perception_test
SuS-X: Training-Free Name-Only Transfer of Vision-Language Models
Nov 28, 2022Contrastive Language-Image Pre-training (CLIP) has emerged as a simple yet effective way to train large-scale vision-language models. CLIP demonstrates impressive zero-shot classification and retrieval on diverse downstream tasks. However, to leverage its full potential, fine-tuning still appears to be necessary. Fine-tuning the entire CLIP model can be resource-intensive and unstable. Moreover, recent methods that aim to circumvent this need for fine-tuning still require access to images from the target distribution. In this paper, we pursue a different approach and explore the regime of training-free "name-only transfer" in which the only knowledge we possess about the downstream task comprises the names of downstream target categories. We propose a novel method, SuS-X, consisting of two key building blocks -- SuS and TIP-X, that requires neither intensive fine-tuning nor costly labelled data. SuS-X achieves state-of-the-art zero-shot classification results on 19 benchmark datasets. We further show the utility of TIP-X in the training-free few-shot setting, where we again achieve state-of-the-art results over strong training-free baselines. Code is available at https://github.com/vishaal27/SuS-X.
TAP-Vid: A Benchmark for Tracking Any Point in a Video
Nov 07, 2022Generic motion understanding from video involves not only tracking objects, but also perceiving how their surfaces deform and move. This information is useful to make inferences about 3D shape, physical properties and object interactions. While the problem of tracking arbitrary physical points on surfaces over longer video clips has received some attention, no dataset or benchmark for evaluation existed, until now. In this paper, we first formalize the problem, naming it tracking any point (TAP). We introduce a companion benchmark, TAP-Vid, which is composed of both real-world videos with accurate human annotations of point tracks, and synthetic videos with perfect ground-truth point tracks. Central to the construction of our benchmark is a novel semi-automatic crowdsourced pipeline which uses optical flow estimates to compensate for easier, short-term motion like camera shake, allowing annotators to focus on harder sections of video. We validate our pipeline on synthetic data and propose a simple end-to-end point tracking model TAP-Net, showing that it outperforms all prior methods on our benchmark when trained on synthetic data.
Is an Object-Centric Video Representation Beneficial for Transfer?
Jul 20, 2022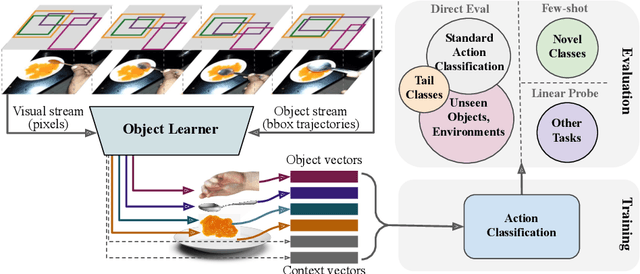
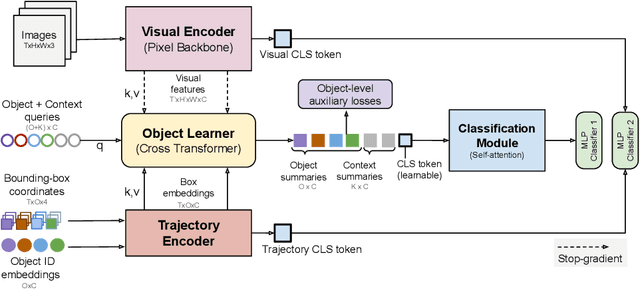
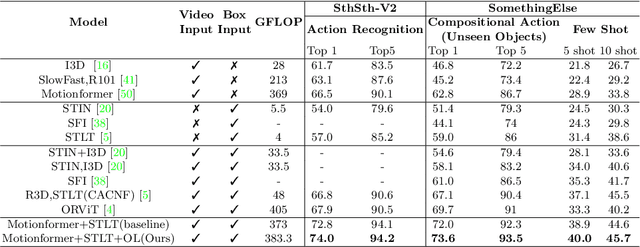
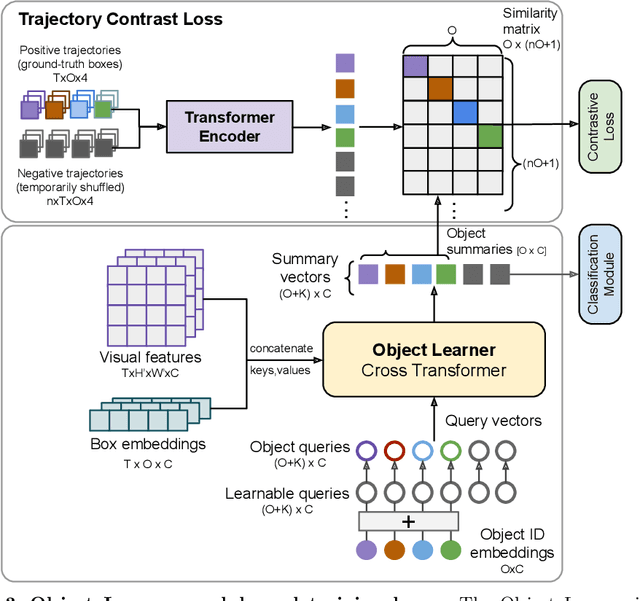
The objective of this work is to learn an object-centric video representation, with the aim of improving transferability to novel tasks, i.e., tasks different from the pre-training task of action classification. To this end, we introduce a new object-centric video recognition model based on a transformer architecture. The model learns a set of object-centric summary vectors for the video, and uses these vectors to fuse the visual and spatio-temporal trajectory `modalities' of the video clip. We also introduce a novel trajectory contrast loss to further enhance objectness in these summary vectors. With experiments on four datasets -- SomethingSomething-V2, SomethingElse, Action Genome and EpicKitchens -- we show that the object-centric model outperforms prior video representations (both object-agnostic and object-aware), when: (1) classifying actions on unseen objects and unseen environments; (2) low-shot learning to novel classes; (3) linear probe to other downstream tasks; as well as (4) for standard action classification.
Temporal Query Networks for Fine-grained Video Understanding
Apr 19, 2021

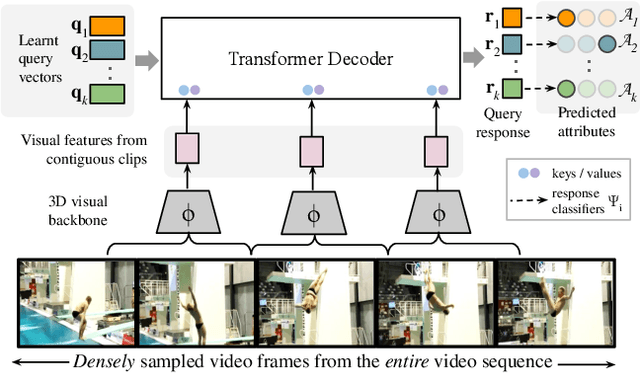

Our objective in this work is fine-grained classification of actions in untrimmed videos, where the actions may be temporally extended or may span only a few frames of the video. We cast this into a query-response mechanism, where each query addresses a particular question, and has its own response label set. We make the following four contributions: (I) We propose a new model - a Temporal Query Network - which enables the query-response functionality, and a structural understanding of fine-grained actions. It attends to relevant segments for each query with a temporal attention mechanism, and can be trained using only the labels for each query. (ii) We propose a new way - stochastic feature bank update - to train a network on videos of various lengths with the dense sampling required to respond to fine-grained queries. (iii) We compare the TQN to other architectures and text supervision methods, and analyze their pros and cons. Finally, (iv) we evaluate the method extensively on the FineGym and Diving48 benchmarks for fine-grained action classification and surpass the state-of-the-art using only RGB features.
Representation Matters: Improving Perception and Exploration for Robotics
Nov 03, 2020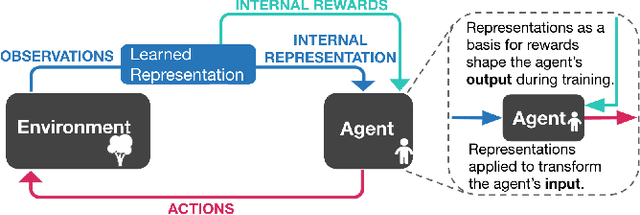
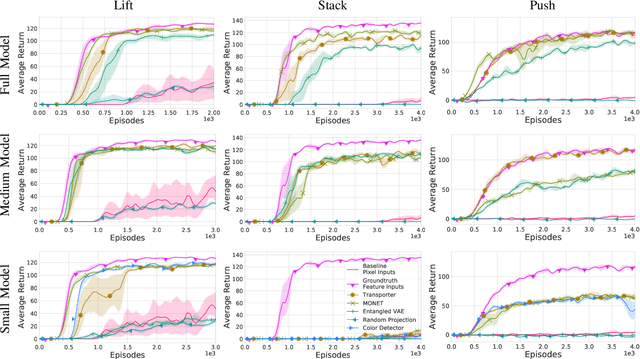
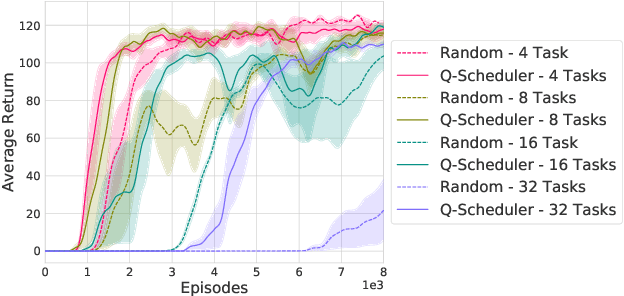

Projecting high-dimensional environment observations into lower-dimensional structured representations can considerably improve data-efficiency for reinforcement learning in domains with limited data such as robotics. Can a single generally useful representation be found? In order to answer this question, it is important to understand how the representation will be used by the agent and what properties such a 'good' representation should have. In this paper we systematically evaluate a number of common learnt and hand-engineered representations in the context of three robotics tasks: lifting, stacking and pushing of 3D blocks. The representations are evaluated in two use-cases: as input to the agent, or as a source of auxiliary tasks. Furthermore, the value of each representation is evaluated in terms of three properties: dimensionality, observability and disentanglement. We can significantly improve performance in both use-cases and demonstrate that some representations can perform commensurate to simulator states as agent inputs. Finally, our results challenge common intuitions by demonstrating that: 1) dimensionality strongly matters for task generation, but is negligible for inputs, 2) observability of task-relevant aspects mostly affects the input representation use-case, and 3) disentanglement leads to better auxiliary tasks, but has only limited benefits for input representations. This work serves as a step towards a more systematic understanding of what makes a 'good' representation for control in robotics, enabling practitioners to make more informed choices for developing new learned or hand-engineered representations.
Adaptive Text Recognition through Visual Matching
Sep 14, 2020
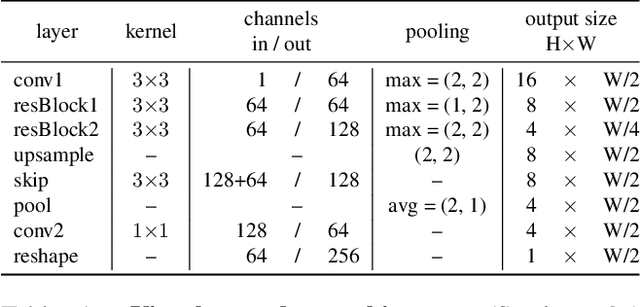
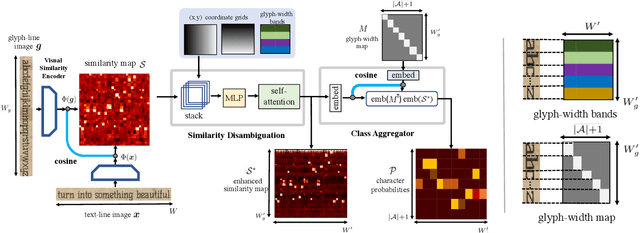
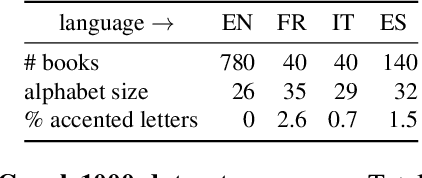
In this work, our objective is to address the problems of generalization and flexibility for text recognition in documents. We introduce a new model that exploits the repetitive nature of characters in languages, and decouples the visual representation learning and linguistic modelling stages. By doing this, we turn text recognition into a shape matching problem, and thereby achieve generalization in appearance and flexibility in classes. We evaluate the new model on both synthetic and real datasets across different alphabets and show that it can handle challenges that traditional architectures are not able to solve without expensive retraining, including: (i) it can generalize to unseen fonts without new exemplars from them; (ii) it can flexibly change the number of classes, simply by changing the exemplars provided; and (iii) it can generalize to new languages and new characters that it has not been trained for by providing a new glyph set. We show significant improvements over state-of-the-art models for all these cases.