 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Agents in Drug Discovery
Oct 31, 2025Artificial intelligence (AI) agents are emerging as transformative tools in drug discovery, with the ability to autonomously reason, act, and learn through complicated research workflows. Building on large language models (LLMs) coupled with perception, computation, action, and memory tools, these agentic AI systems could integrate diverse biomedical data, execute tasks, carry out experiments via robotic platforms, and iteratively refine hypotheses in closed loops. We provide a conceptual and technical overview of agentic AI architectures, ranging from ReAct and Reflection to Supervisor and Swarm systems, and illustrate their applications across key stages of drug discovery, including literature synthesis, toxicity prediction, automated protocol generation, small-molecule synthesis, drug repurposing, and end-to-end decision-making. To our knowledge, this represents the first comprehensive work to present real-world implementations and quantifiable impacts of agentic AI systems deployed in operational drug discovery settings. Early implementations demonstrate substantial gains in speed, reproducibility, and scalability, compressing workflows that once took months into hours while maintaining scientific traceability. We discuss the current challenges related to data heterogeneity, system reliability, privacy, and benchmarking, and outline future directions towards technology in support of science and translation.
Multi Attribute Bias Mitigation via Representation Learning
Sep 03, 2025Real world images frequently exhibit multiple overlapping biases, including textures, watermarks, gendered makeup, scene object pairings, etc. These biases collectively impair the performance of modern vision models, undermining both their robustness and fairness. Addressing these biases individually proves inadequate, as mitigating one bias often permits or intensifies others. We tackle this multi bias problem with Generalized Multi Bias Mitigation (GMBM), a lean two stage framework that needs group labels only while training and minimizes bias at test time. First, Adaptive Bias Integrated Learning (ABIL) deliberately identifies the influence of known shortcuts by training encoders for each attribute and integrating them with the main backbone, compelling the classifier to explicitly recognize these biases. Then Gradient Suppression Fine Tuning prunes those very bias directions from the backbone's gradients, leaving a single compact network that ignores all the shortcuts it just learned to recognize. Moreover we find that existing bias metrics break under subgroup imbalance and train test distribution shifts, so we introduce Scaled Bias Amplification (SBA): a test time measure that disentangles model induced bias amplification from distributional differences. We validate GMBM on FB CMNIST, CelebA, and COCO, where we boost worst group accuracy, halve multi attribute bias amplification, and set a new low in SBA even as bias complexity and distribution shifts intensify, making GMBM the first practical, end to end multibias solution for visual recognition. Project page: http://visdomlab.github.io/GMBM/
Contrasting Low and High-Resolution Features for HER2 Scoring using Deep Learning
Mar 28, 2025Breast cancer, the most common malignancy among women, requires precise detection and classification for effective treatment. Immunohistochemistry (IHC) biomarkers like HER2, ER, and PR are critical for identifying breast cancer subtypes. However, traditional IHC classification relies on pathologists' expertise, making it labor-intensive and subject to significant inter-observer variability. To address these challenges, this study introduces the India Pathology Breast Cancer Dataset (IPD-Breast), comprising of 1,272 IHC slides (HER2, ER, and PR) aimed at automating receptor status classification. The primary focus is on developing predictive models for HER2 3-way classification (0, Low, High) to enhance prognosis. Evaluation of multiple deep learning models revealed that an end-to-end ConvNeXt network utilizing low-resolution IHC images achieved an AUC, F1, and accuracy of 91.79%, 83.52%, and 83.56%, respectively, for 3-way classification, outperforming patch-based methods by over 5.35% in F1 score. This study highlights the potential of simple yet effective deep learning techniques to significantly improve accuracy and reproducibility in breast cancer classification, supporting their integration into clinical workflows for better patient outcomes.
What Does an Audio Deepfake Detector Focus on? A Study in the Time Domain
Jan 27, 2025



Adding explanations to audio deepfake detection (ADD) models will boost their real-world application by providing insight on the decision making process. In this paper, we propose a relevancy-based explainable AI (XAI) method to analyze the predictions of transformer-based ADD models. We compare against standard Grad-CAM and SHAP-based methods, using quantitative faithfulness metrics as well as a partial spoof test, to comprehensively analyze the relative importance of different temporal regions in an audio. We consider large datasets, unlike previous works where only limited utterances are studied, and find that the XAI methods differ in their explanations. The proposed relevancy-based XAI method performs the best overall on a variety of metrics. Further investigation on the relative importance of speech/non-speech, phonetic content, and voice onsets/offsets suggest that the XAI results obtained from analyzing limited utterances don't necessarily hold when evaluated on large datasets.
Prithvi-EO-2.0: A Versatile Multi-Temporal Foundation Model for Earth Observation Applications
Dec 03, 2024



This technical report presents Prithvi-EO-2.0, a new geospatial foundation model that offers significant improvements over its predecessor, Prithvi-EO-1.0. Trained on 4.2M global time series samples from NASA's Harmonized Landsat and Sentinel-2 data archive at 30m resolution, the new 300M and 600M parameter models incorporate temporal and location embeddings for enhanced performance across various geospatial tasks. Through extensive benchmarking with GEO-Bench, the 600M version outperforms the previous Prithvi-EO model by 8\% across a range of tasks. It also outperforms six other geospatial foundation models when benchmarked on remote sensing tasks from different domains and resolutions (i.e. from 0.1m to 15m). The results demonstrate the versatility of the model in both classical earth observation and high-resolution applications. Early involvement of end-users and subject matter experts (SMEs) are among the key factors that contributed to the project's success. In particular, SME involvement allowed for constant feedback on model and dataset design, as well as successful customization for diverse SME-led applications in disaster response, land use and crop mapping, and ecosystem dynamics monitoring. Prithvi-EO-2.0 is available on Hugging Face and IBM terratorch, with additional resources on GitHub. The project exemplifies the Trusted Open Science approach embraced by all involved organizations.
Residual vector quantization for KV cache compression in large language model
Oct 21, 2024


KV cache compression methods have mainly relied on scalar quantization techniques to reduce the memory requirements during decoding. In this work, we apply residual vector quantization, which has been widely used for high fidelity audio compression, to compress KV cache in large language models (LLM). We adapt the standard recipe with minimal changes to compress the output of any key or value projection matrix in a pretrained LLM: we scale the vector by its standard deviation, divide channels into groups and then quantize each group with the same residual vector quantizer. We learn the codebook using exponential moving average and there are no other learnable parameters including the input and output projections normally used in a vector quantization set up. We find that a residual depth of 8 recovers most of the performance of the unquantized model. We also find that grouping non-contiguous channels together works better than grouping contiguous channels for compressing key matrix and the method further benefits from a light weight finetuning of LLM together with the quantization. Overall, the proposed technique is competitive with existing quantization methods while being much simpler and results in 5.5x compression compared to half precision.
Learn from Real: Reality Defender's Submission to ASVspoof5 Challenge
Oct 09, 2024



Audio deepfake detection is crucial to combat the malicious use of AI-synthesized speech. Among many efforts undertaken by the community, the ASVspoof challenge has become one of the benchmarks to evaluate the generalizability and robustness of detection models. In this paper, we present Reality Defender's submission to the ASVspoof5 challenge, highlighting a novel pretraining strategy which significantly improves generalizability while maintaining low computational cost during training. Our system SLIM learns the style-linguistics dependency embeddings from various types of bonafide speech using self-supervised contrastive learning. The learned embeddings help to discriminate spoof from bonafide speech by focusing on the relationship between the style and linguistics aspects. We evaluated our system on ASVspoof5, ASV2019, and In-the-wild. Our submission achieved minDCF of 0.1499 and EER of 5.5% on ASVspoof5 Track 1, and EER of 7.4% and 10.8% on ASV2019 and In-the-wild respectively.
Stateful Conformer with Cache-based Inference for Streaming Automatic Speech Recognition
Jan 11, 2024In this paper, we propose an efficient and accurate streaming speech recognition model based on the FastConformer architecture. We adapted the FastConformer architecture for streaming applications through: (1) constraining both the look-ahead and past contexts in the encoder, and (2) introducing an activation caching mechanism to enable the non-autoregressive encoder to operate autoregressively during inference. The proposed model is thoughtfully designed in a way to eliminate the accuracy disparity between the train and inference time which is common for many streaming models. Furthermore, our proposed encoder works with various decoder configurations including Connectionist Temporal Classification (CTC) and RNN-Transducer (RNNT) decoders. Additionally, we introduced a hybrid CTC/RNNT architecture which utilizes a shared encoder with both a CTC and RNNT decoder to boost the accuracy and save computation. We evaluate the proposed model on LibriSpeech dataset and a multi-domain large scale dataset and demonstrate that it can achieve better accuracy with lower latency and inference time compared to a conventional buffered streaming model baseline. We also showed that training a model with multiple latencies can achieve better accuracy than single latency models while it enables us to support multiple latencies with a single model. Our experiments also showed the hybrid architecture would not only speedup the convergence of the CTC decoder but also improves the accuracy of streaming models compared to single decoder models.
Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition
May 19, 2023



Conformer-based models have become the most dominant end-to-end architecture for speech processing tasks. In this work, we propose a carefully redesigned Conformer with a new down-sampling schema. The proposed model, named Fast Conformer, is 2.8x faster than original Conformer, while preserving state-of-the-art accuracy on Automatic Speech Recognition benchmarks. Also we replace the original Conformer global attention with limited context attention post-training to enable transcription of an hour-long audio. We further improve long-form speech transcription by adding a global token. Fast Conformer combined with a Transformer decoder also outperforms the original Conformer in accuracy and in speed for Speech Translation and Spoken Language Understanding.
LabVIEW is faster and C is economical interfacing tool for UCT automation
May 17, 2022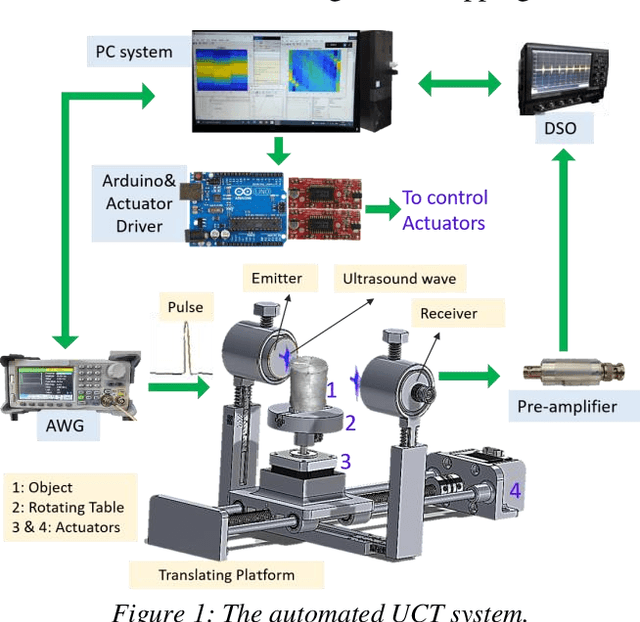
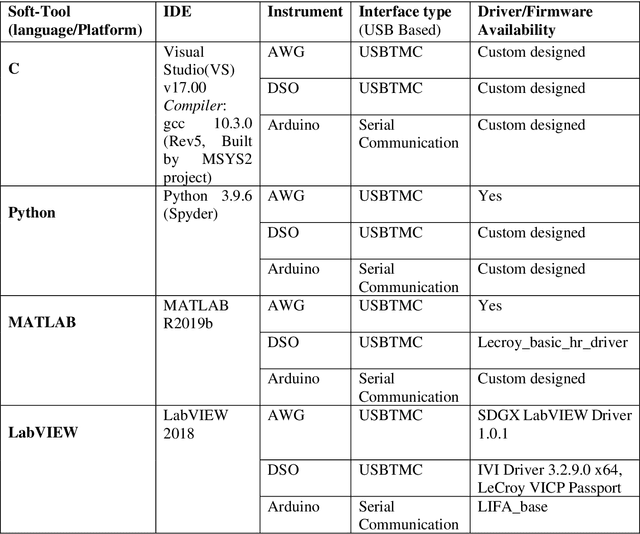
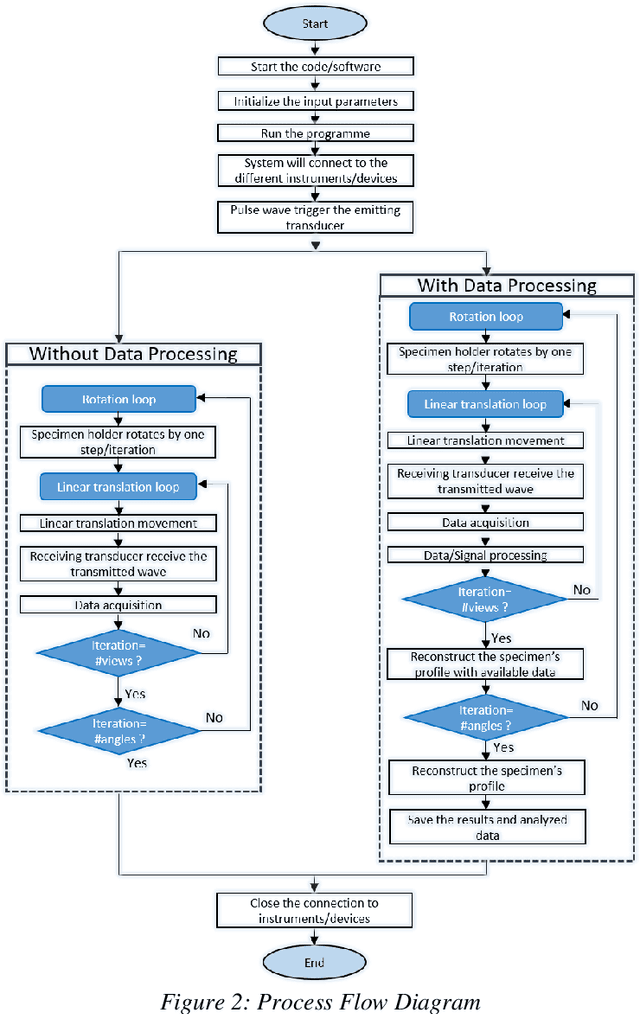
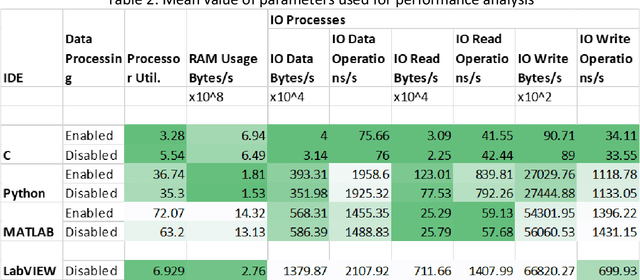
An in-house developed 2D ultrasound computerized Tomography system is fully automated. Performance analysis of instrument and software interfacing soft tools, namely the LabVIEW, MATLAB, C, and Python, is presented. The instrument interfacing algorithms, hardware control algorithms, signal processing, and analysis codes are written using above mentioned soft tool platforms. Total of eight performance indices are used to compare the ease of (a) realtime control of electromechanical assembly, (b) sensors, instruments integration, (c) synchronized data acquisition, and (d) simultaneous raw data processing. It is found that C utilizes the least processing power and performs a lower number of processes to perform the same task. In runtime analysis (data acquisition and realtime control), LabVIEW performs best, taking 365.69s in comparison to MATLAB (623.83s), Python ( 1505.54s), and C (1252.03s) to complete the experiment. Python performs better in establishing faster interfacing and minimum RAM usage. LabVIEW is recommended for its fast process execution. C is recommended for the most economical implementation. Python is recommended for complex system automation having a very large number of components involved. This article provides a methodology to select optimal soft tools for instrument automation-related aspects.