 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedBC: Calibrating Global and Local Models via Federated Learning Beyond Consensus
Jun 26, 2022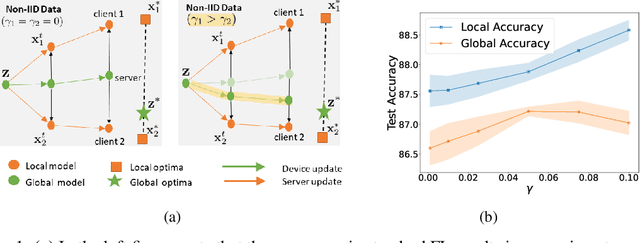
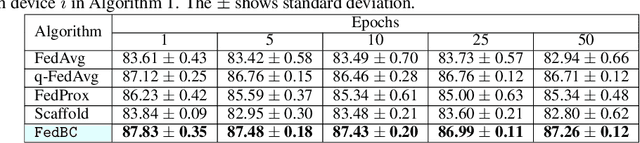
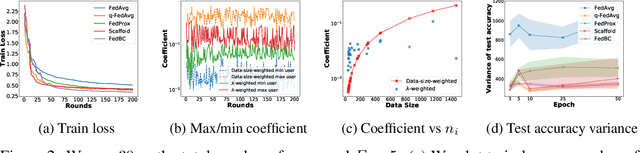
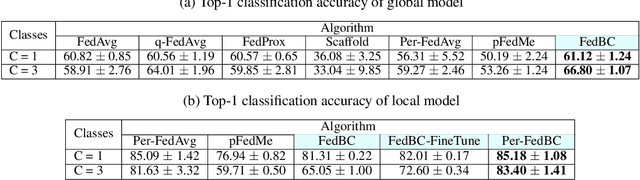
In federated learning (FL), the objective of collaboratively learning a global model through aggregation of model updates across devices tends to oppose the goal of personalization via local information. In this work, we calibrate this tradeoff in a quantitative manner through a multi-criterion optimization-based framework, which we cast as a constrained program: the objective for a device is its local objective, which it seeks to minimize while satisfying nonlinear constraints that quantify the proximity between the local and the global model. By considering the Lagrangian relaxation of this problem, we develop an algorithm that allows each node to minimize its local component of Lagrangian through queries to a first-order gradient oracle. Then, the server executes Lagrange multiplier ascent steps followed by a Lagrange multiplier-weighted averaging step. We call this instantiation of the primal-dual method Federated Learning Beyond Consensus ($\texttt{FedBC}$). Theoretically, we establish that $\texttt{FedBC}$ converges to a first-order stationary point at rates that matches the state of the art, up to an additional error term that depends on the tolerance parameter that arises due to the proximity constraints. Overall, the analysis is a novel characterization of primal-dual methods applied to non-convex saddle point problems with nonlinear constraints. Finally, we demonstrate that $\texttt{FedBC}$ balances the global and local model test accuracy metrics across a suite of datasets (Synthetic, MNIST, CIFAR-10, Shakespeare), achieving competitive performance with the state of the art.
Self-Aware Personalized Federated Learning
Apr 17, 2022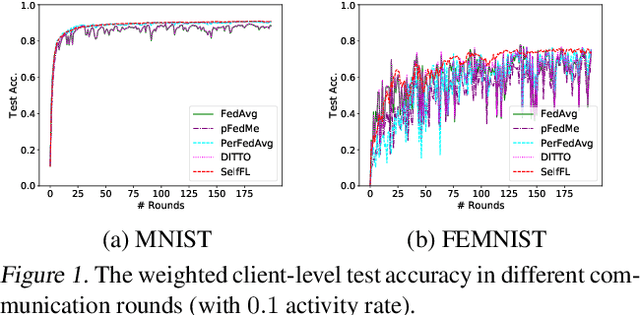
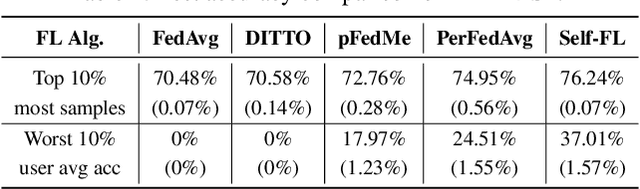
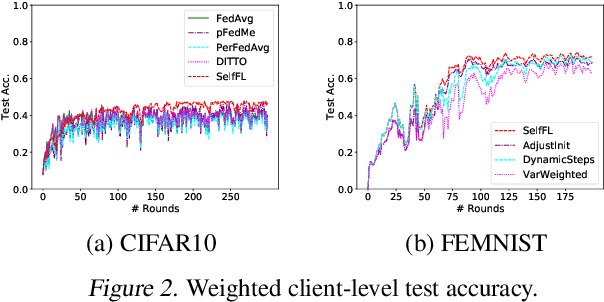
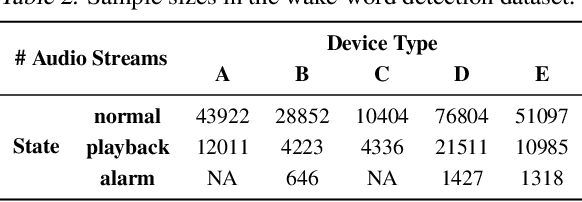
In the context of personalized federated learning (FL), the critical challenge is to balance local model improvement and global model tuning when the personal and global objectives may not be exactly aligned. Inspired by Bayesian hierarchical models, we develop a self-aware personalized FL method where each client can automatically balance the training of its local personal model and the global model that implicitly contributes to other clients' training. Such a balance is derived from the inter-client and intra-client uncertainty quantification. A larger inter-client variation implies more personalization is needed. Correspondingly, our method uses uncertainty-driven local training steps and aggregation rule instead of conventional local fine-tuning and sample size-based aggregation. With experimental studies on synthetic data, Amazon Alexa audio data, and public datasets such as MNIST, FEMNIST, CIFAR10, and Sent140, we show that our proposed method can achieve significantly improved personalization performance compared with the existing counterparts.
Nonlinear gradient mappings and stochastic optimization: A general framework with applications to heavy-tail noise
Apr 06, 2022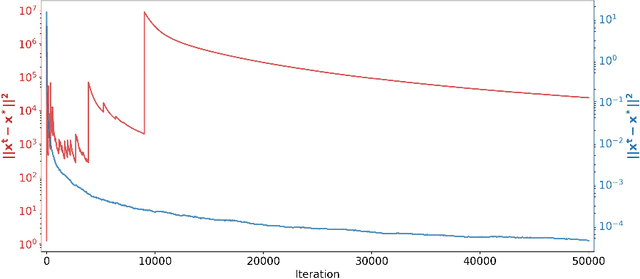
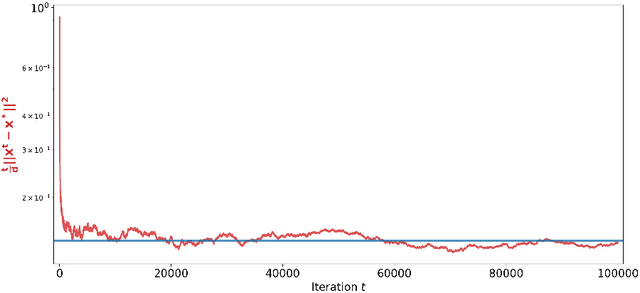
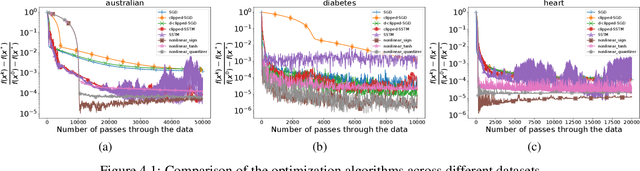
We introduce a general framework for nonlinear stochastic gradient descent (SGD) for the scenarios when gradient noise exhibits heavy tails. The proposed framework subsumes several popular nonlinearity choices, like clipped, normalized, signed or quantized gradient, but we also consider novel nonlinearity choices. We establish for the considered class of methods strong convergence guarantees assuming a strongly convex cost function with Lipschitz continuous gradients under very general assumptions on the gradient noise. Most notably, we show that, for a nonlinearity with bounded outputs and for the gradient noise that may not have finite moments of order greater than one, the nonlinear SGD's mean squared error (MSE), or equivalently, the expected cost function's optimality gap, converges to zero at rate~$O(1/t^\zeta)$, $\zeta \in (0,1)$. In contrast, for the same noise setting, the linear SGD generates a sequence with unbounded variances. Furthermore, for the nonlinearities that can be decoupled component wise, like, e.g., sign gradient or component-wise clipping, we show that the nonlinear SGD asymptotically (locally) achieves a $O(1/t)$ rate in the weak convergence sense and explicitly quantify the corresponding asymptotic variance. Experiments show that, while our framework is more general than existing studies of SGD under heavy-tail noise, several easy-to-implement nonlinearities from our framework are competitive with state of the art alternatives on real data sets with heavy tail noises.
Federated Learning Challenges and Opportunities: An Outlook
Feb 01, 2022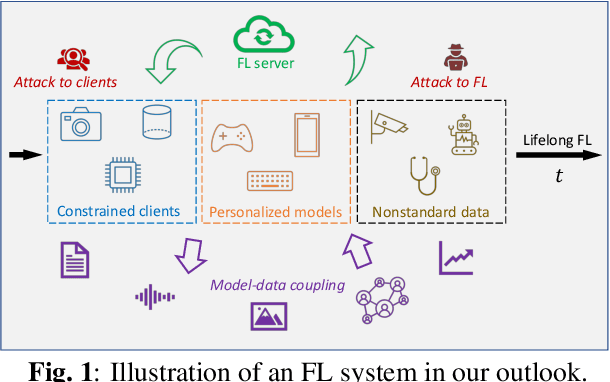
Federated learning (FL) has been developed as a promising framework to leverage the resources of edge devices, enhance customers' privacy, comply with regulations, and reduce development costs. Although many methods and applications have been developed for FL, several critical challenges for practical FL systems remain unaddressed. This paper provides an outlook on FL development, categorized into five emerging directions of FL, namely algorithm foundation, personalization, hardware and security constraints, lifelong learning, and nonstandard data. Our unique perspectives are backed by practical observations from large-scale federated systems for edge devices.
Partial Model Averaging in Federated Learning: Performance Guarantees and Benefits
Jan 11, 2022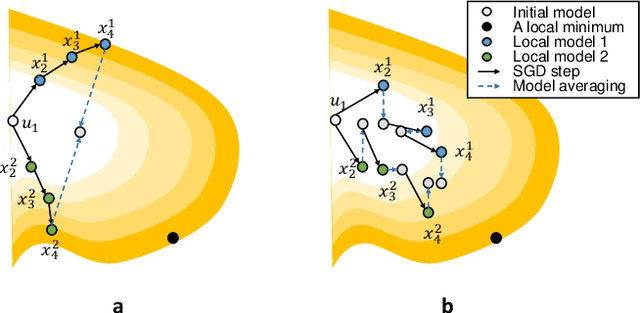
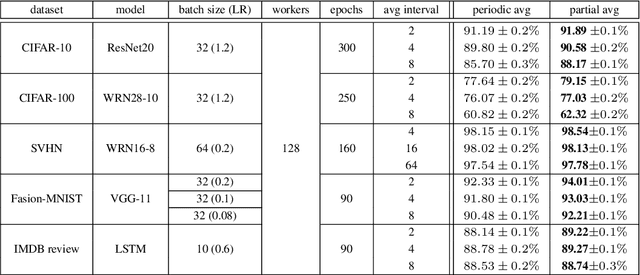
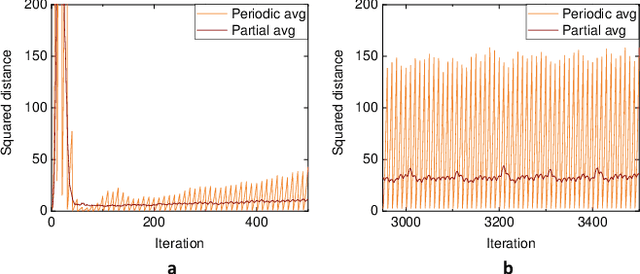

Local Stochastic Gradient Descent (SGD) with periodic model averaging (FedAvg) is a foundational algorithm in Federated Learning. The algorithm independently runs SGD on multiple workers and periodically averages the model across all the workers. When local SGD runs with many workers, however, the periodic averaging causes a significant model discrepancy across the workers making the global loss converge slowly. While recent advanced optimization methods tackle the issue focused on non-IID settings, there still exists the model discrepancy issue due to the underlying periodic model averaging. We propose a partial model averaging framework that mitigates the model discrepancy issue in Federated Learning. The partial averaging encourages the local models to stay close to each other on parameter space, and it enables to more effectively minimize the global loss. Given a fixed number of iterations and a large number of workers (128), the partial averaging achieves up to 2.2% higher validation accuracy than the periodic full averaging.
You Only Query Once: Effective Black Box Adversarial Attacks with Minimal Repeated Queries
Jan 29, 2021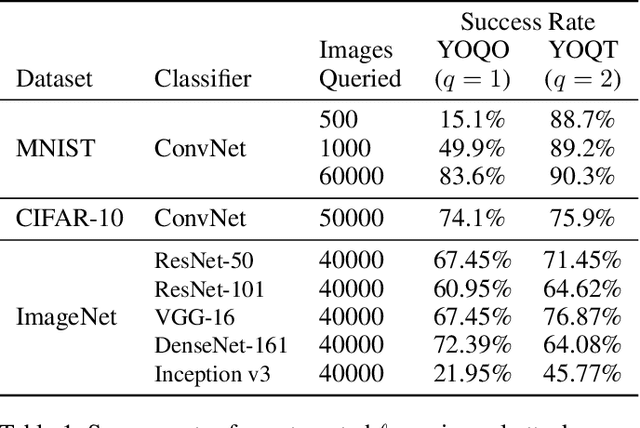



Researchers have repeatedly shown that it is possible to craft adversarial attacks on deep classifiers (small perturbations that significantly change the class label), even in the "black-box" setting where one only has query access to the classifier. However, all prior work in the black-box setting attacks the classifier by repeatedly querying the same image with minor modifications, usually thousands of times or more, making it easy for defenders to detect an ensuing attack. In this work, we instead show that it is possible to craft (universal) adversarial perturbations in the black-box setting by querying a sequence of different images only once. This attack prevents detection from high number of similar queries and produces a perturbation that causes misclassification when applied to any input to the classifier. In experiments, we show that attacks that adhere to this restriction can produce untargeted adversarial perturbations that fool the vast majority of MNIST and CIFAR-10 classifier inputs, as well as in excess of $60-70\%$ of inputs on ImageNet classifiers. In the targeted setting, we exhibit targeted black-box universal attacks on ImageNet classifiers with success rates above $20\%$ when only allowed one query per image, and $66\%$ when allowed two queries per image.
Gaussian MRF Covariance Modeling for Efficient Black-Box Adversarial Attacks
Oct 08, 2020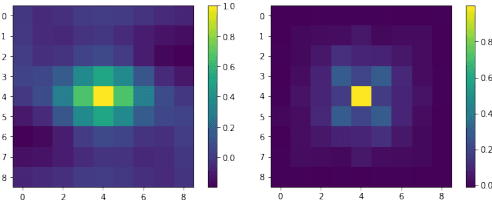
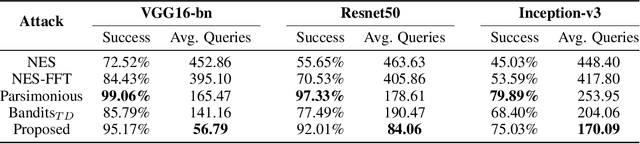
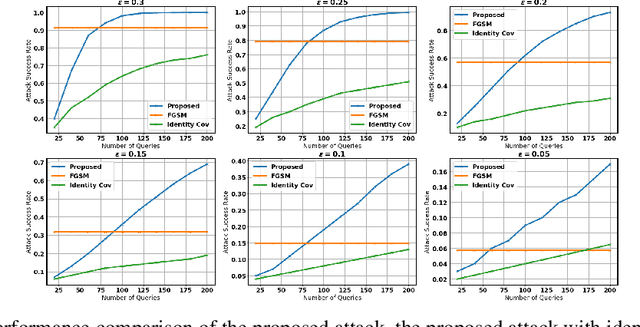
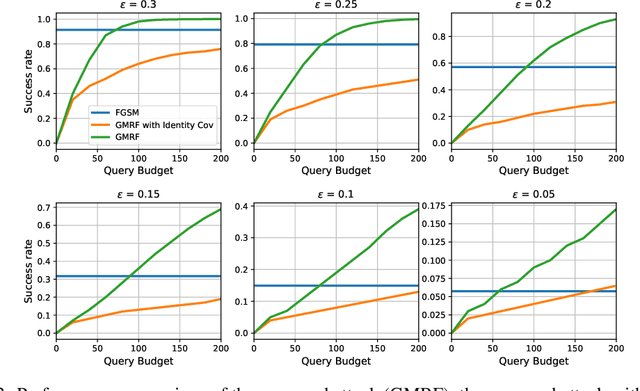
We study the problem of generating adversarial examples in a black-box setting, where we only have access to a zeroth order oracle, providing us with loss function evaluations. Although this setting has been investigated in previous work, most past approaches using zeroth order optimization implicitly assume that the gradients of the loss function with respect to the input images are \emph{unstructured}. In this work, we show that in fact substantial correlations exist within these gradients, and we propose to capture these correlations via a Gaussian Markov random field (GMRF). Given the intractability of the explicit covariance structure of the MRF, we show that the covariance structure can be efficiently represented using the Fast Fourier Transform (FFT), along with low-rank updates to perform exact posterior estimation under this model. We use this modeling technique to find fast one-step adversarial attacks, akin to a black-box version of the Fast Gradient Sign Method~(FGSM), and show that the method uses fewer queries and achieves higher attack success rates than the current state of the art. We also highlight the general applicability of this gradient modeling setup.
Hard Label Black-box Adversarial Attacks in Low Query Budget Regimes
Jul 13, 2020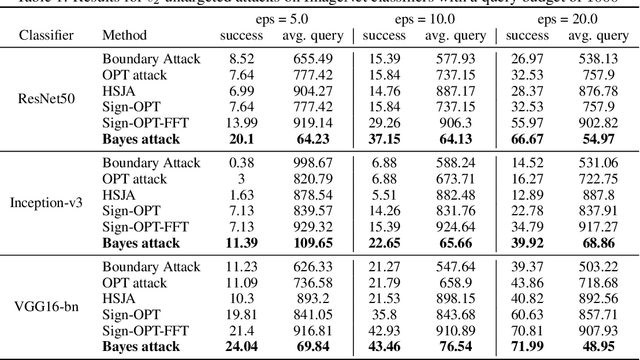
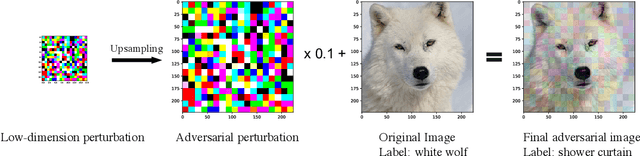

We focus on the problem of black-box adversarial attacks, where the aim is to generate adversarial examples for deep learning models solely based on information limited to output labels (hard label) to a queried data input. We use Bayesian optimization (BO) to specifically cater to scenarios involving low query budgets to develop efficient adversarial attacks. Issues with BO's performance in high dimensions are avoided by searching for adversarial examples in structured low-dimensional subspace. Our proposed approach achieves better performance to state of the art black-box adversarial attacks that require orders of magnitude more queries than ours.
FedDANE: A Federated Newton-Type Method
Jan 07, 2020
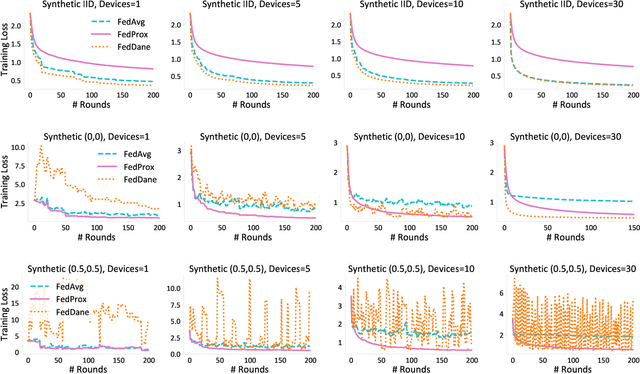
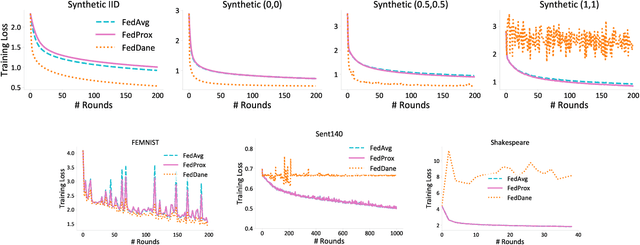
Federated learning aims to jointly learn statistical models over massively distributed remote devices. In this work, we propose FedDANE, an optimization method that we adapt from DANE, a method for classical distributed optimization, to handle the practical constraints of federated learning. We provide convergence guarantees for this method when learning over both convex and non-convex functions. Despite encouraging theoretical results, we find that the method has underwhelming performance empirically. In particular, through empirical simulations on both synthetic and real-world datasets, FedDANE consistently underperforms baselines of FedAvg and FedProx in realistic federated settings. We identify low device participation and statistical device heterogeneity as two underlying causes of this underwhelming performance, and conclude by suggesting several directions of future work.
Black-box Adversarial Attacks with Bayesian Optimization
Sep 30, 2019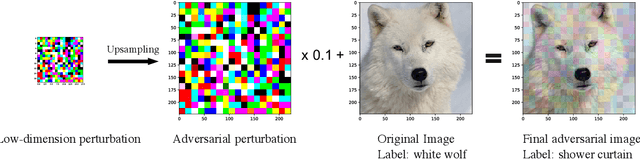
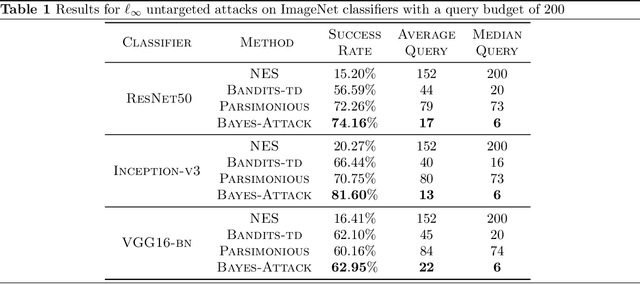
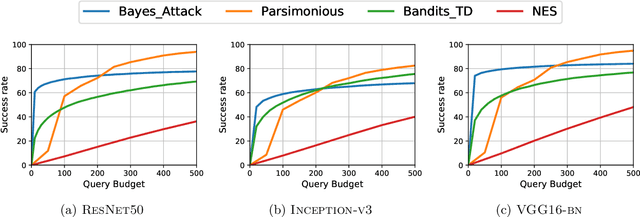
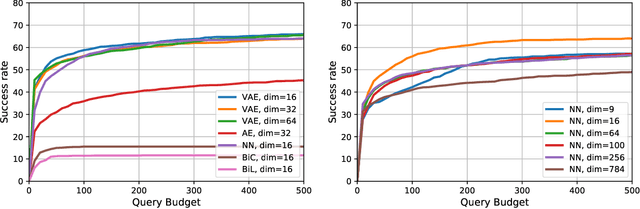
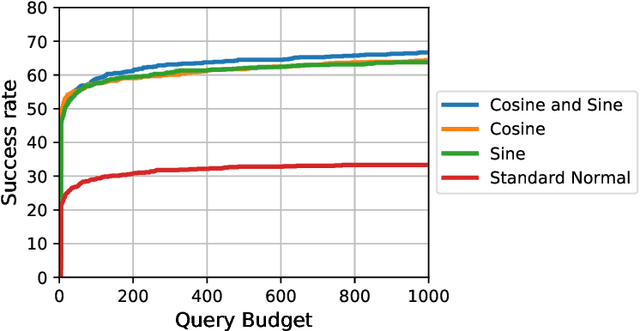
We focus on the problem of black-box adversarial attacks, where the aim is to generate adversarial examples using information limited to loss function evaluations of input-output pairs. We use Bayesian optimization~(BO) to specifically cater to scenarios involving low query budgets to develop query efficient adversarial attacks. We alleviate the issues surrounding BO in regards to optimizing high dimensional deep learning models by effective dimension upsampling techniques. Our proposed approach achieves performance comparable to the state of the art black-box adversarial attacks albeit with a much lower average query count. In particular, in low query budget regimes, our proposed method reduces the query count up to $80\%$ with respect to the state of the art methods.