 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL with Learnable Textual Feedback: A Bilevel Approach
May 23, 2026Reinforcement learning with verifiable rewards can improve LLM reasoning, but learning remains sample-inefficient when terminal rewards are sparse. This has motivated a growing line of work on RL with textual feedback, where a critic model generates natural language feedback to guide a reasoning model (the actor), augmenting scalar rewards with richer learning signals. However, existing methods typically treat feedback as fixed or auxiliary, which misses a key property: feedback should not merely be correct, but should improve the policy (actor model) when provided in context. This motivates a paradigm of learnable textual feedback for RL. Yet the learnability and usefulness of feedback depend on the policy's ability to learn from it, making RL with learnable feedback an inherently bilevel problem. We formalize this coupling as a Stackelberg bilevel program and derive Bilevel Natural Language Actor-Critic (Bi-NAC), which jointly trains a critic to generate reward-improving feedback and an actor to exploit it. Across MATH-500, MBPP, and GPQA, Bi-NAC improves sample and parameter efficiency over RL and fixed-critic baselines: our 2B model outperforms the 3B GRPO baseline, achieving 46.6% versus 41.4% on MATH-500, while our 6B model surpasses the 7B GRPO baseline, achieving 49.3% versus 43.6% on GPQA.
MIRA: Towards Mitigating Reward Hacking in Inference-Time Alignment of T2I Diffusion Models
Oct 02, 2025Diffusion models excel at generating images conditioned on text prompts, but the resulting images often do not satisfy user-specific criteria measured by scalar rewards such as Aesthetic Scores. This alignment typically requires fine-tuning, which is computationally demanding. Recently, inference-time alignment via noise optimization has emerged as an efficient alternative, modifying initial input noise to steer the diffusion denoising process towards generating high-reward images. However, this approach suffers from reward hacking, where the model produces images that score highly, yet deviate significantly from the original prompt. We show that noise-space regularization is insufficient and that preventing reward hacking requires an explicit image-space constraint. To this end, we propose MIRA (MItigating Reward hAcking), a training-free, inference-time alignment method. MIRA introduces an image-space, score-based KL surrogate that regularizes the sampling trajectory with a frozen backbone, constraining the output distribution so reward can increase without off-distribution drift (reward hacking). We derive a tractable approximation to KL using diffusion scores. Across SDv1.5 and SDXL, multiple rewards (Aesthetic, HPSv2, PickScore), and public datasets (e.g., Animal-Animal, HPDv2), MIRA achieves >60\% win rate vs. strong baselines while preserving prompt adherence; mechanism plots show reward gains with near-zero drift, whereas DNO drifts as compute increases. We further introduce MIRA-DPO, mapping preference optimization to inference time with a frozen backbone, extending MIRA to non-differentiable rewards without fine-tuning.
Hierarchical Preference Optimization: Learning to achieve goals via feasible subgoals prediction
Nov 01, 2024



This work introduces Hierarchical Preference Optimization (HPO), a novel approach to hierarchical reinforcement learning (HRL) that addresses non-stationarity and infeasible subgoal generation issues when solving complex robotic control tasks. HPO leverages maximum entropy reinforcement learning combined with token-level Direct Preference Optimization (DPO), eliminating the need for pre-trained reference policies that are typically unavailable in challenging robotic scenarios. Mathematically, we formulate HRL as a bi-level optimization problem and transform it into a primitive-regularized DPO formulation, ensuring feasible subgoal generation and avoiding degenerate solutions. Extensive experiments on challenging robotic navigation and manipulation tasks demonstrate impressive performance of HPO, where it shows an improvement of up to 35% over the baselines. Furthermore, ablation studies validate our design choices, and quantitative analyses confirm the ability of HPO to mitigate non-stationarity and infeasible subgoal generation issues in HRL.
DIPPER: Direct Preference Optimization to Accelerate Primitive-Enabled Hierarchical Reinforcement Learning
Jun 16, 2024Learning control policies to perform complex robotics tasks from human preference data presents significant challenges. On the one hand, the complexity of such tasks typically requires learning policies to perform a variety of subtasks, then combining them to achieve the overall goal. At the same time, comprehensive, well-engineered reward functions are typically unavailable in such problems, while limited human preference data often is; making efficient use of such data to guide learning is therefore essential. Methods for learning to perform complex robotics tasks from human preference data must overcome both these challenges simultaneously. In this work, we introduce DIPPER: Direct Preference Optimization to Accelerate Primitive-Enabled Hierarchical Reinforcement Learning, an efficient hierarchical approach that leverages direct preference optimization to learn a higher-level policy and reinforcement learning to learn a lower-level policy. DIPPER enjoys improved computational efficiency due to its use of direct preference optimization instead of standard preference-based approaches such as reinforcement learning from human feedback, while it also mitigates the well-known hierarchical reinforcement learning issues of non-stationarity and infeasible subgoal generation due to our use of primitive-informed regularization inspired by a novel bi-level optimization formulation of the hierarchical reinforcement learning problem. To validate our approach, we perform extensive experimental analysis on a variety of challenging robotics tasks, demonstrating that DIPPER outperforms hierarchical and non-hierarchical baselines, while ameliorating the non-stationarity and infeasible subgoal generation issues of hierarchical reinforcement learning.
LGR2: Language Guided Reward Relabeling for Accelerating Hierarchical Reinforcement Learning
Jun 09, 2024Developing interactive systems that leverage natural language instructions to solve complex robotic control tasks has been a long-desired goal in the robotics community. Large Language Models (LLMs) have demonstrated exceptional abilities in handling complex tasks, including logical reasoning, in-context learning, and code generation. However, predicting low-level robotic actions using LLMs poses significant challenges. Additionally, the complexity of such tasks usually demands the acquisition of policies to execute diverse subtasks and combine them to attain the ultimate objective. Hierarchical Reinforcement Learning (HRL) is an elegant approach for solving such tasks, which provides the intuitive benefits of temporal abstraction and improved exploration. However, HRL faces the recurring issue of non-stationarity due to unstable lower primitive behaviour. In this work, we propose LGR2, a novel HRL framework that leverages language instructions to generate a stationary reward function for the higher-level policy. Since the language-guided reward is unaffected by the lower primitive behaviour, LGR2 mitigates non-stationarity and is thus an elegant method for leveraging language instructions to solve robotic control tasks. To analyze the efficacy of our approach, we perform empirical analysis and demonstrate that LGR2 effectively alleviates non-stationarity in HRL. Our approach attains success rates exceeding 70$\%$ in challenging, sparse-reward robotic navigation and manipulation environments where the baselines fail to achieve any significant progress. Additionally, we conduct real-world robotic manipulation experiments and demonstrate that CRISP shows impressive generalization in real-world scenarios.
PIPER: Primitive-Informed Preference-based Hierarchical Reinforcement Learning via Hindsight Relabeling
Apr 20, 2024In this work, we introduce PIPER: Primitive-Informed Preference-based Hierarchical reinforcement learning via Hindsight Relabeling, a novel approach that leverages preference-based learning to learn a reward model, and subsequently uses this reward model to relabel higher-level replay buffers. Since this reward is unaffected by lower primitive behavior, our relabeling-based approach is able to mitigate non-stationarity, which is common in existing hierarchical approaches, and demonstrates impressive performance across a range of challenging sparse-reward tasks. Since obtaining human feedback is typically impractical, we propose to replace the human-in-the-loop approach with our primitive-in-the-loop approach, which generates feedback using sparse rewards provided by the environment. Moreover, in order to prevent infeasible subgoal prediction and avoid degenerate solutions, we propose primitive-informed regularization that conditions higher-level policies to generate feasible subgoals for lower-level policies. We perform extensive experiments to show that PIPER mitigates non-stationarity in hierarchical reinforcement learning and achieves greater than 50$\%$ success rates in challenging, sparse-reward robotic environments, where most other baselines fail to achieve any significant progress.
PEAR: Primitive enabled Adaptive Relabeling for boosting Hierarchical Reinforcement Learning
Jun 10, 2023Hierarchical reinforcement learning (HRL) has the potential to solve complex long horizon tasks using temporal abstraction and increased exploration. However, hierarchical agents are difficult to train as they suffer from inherent non-stationarity due to continuously changing low level primitive. We present primitive enabled adaptive relabeling (PEAR), a two-phase approach where firstly we perform adaptive relabeling on a few expert demonstrations to generate subgoal supervision dataset, and then employ imitation learning for regularizing HRL agents. We bound the sub-optimality of our method using theoretical bounds and devise a practical HRL algorithm for solving complex robotic tasks. We perform experiments on challenging robotic tasks: maze navigation, pick and place, rope manipulation and kitchen environments, and demonstrate that the proposed approach is able to solve complex tasks that require long term decision making. Since our method uses a handful of expert demonstrations and makes minimal limiting assumptions on task structure, it can be easily integrated with typical model free reinforcement learning algorithms to solve most robotic tasks. We empirically show that our approach outperforms previous hierarchical and non-hierarchical baselines, and exhibits better sample efficiency. We also perform real world robotic experiments by deploying the learned policy on a real robotic rope manipulation task and demonstrate that PEAR consistently outperforms the baselines. Here is the link for supplementary video: \url{https://tinyurl.com/pearOverview}
CRISP: Curriculum inducing Primitive Informed Subgoal Prediction for Hierarchical Reinforcement Learning
Apr 07, 2023Hierarchical reinforcement learning is a promising approach that uses temporal abstraction to solve complex long horizon problems. However, simultaneously learning a hierarchy of policies is unstable as it is challenging to train higher-level policy when the lower-level primitive is non-stationary. In this paper, we propose a novel hierarchical algorithm by generating a curriculum of achievable subgoals for evolving lower-level primitives using reinforcement learning and imitation learning. The lower level primitive periodically performs data relabeling on a handful of expert demonstrations using our primitive informed parsing approach. We provide expressions to bound the sub-optimality of our method and develop a practical algorithm for hierarchical reinforcement learning. Since our approach uses a handful of expert demonstrations, it is suitable for most robotic control tasks. Experimental evaluation on complex maze navigation and robotic manipulation environments show that inducing hierarchical curriculum learning significantly improves sample efficiency, and results in efficient goal conditioned policies for solving temporally extended tasks.
InfoRL: Interpretable Reinforcement Learning using Information Maximization
May 24, 2019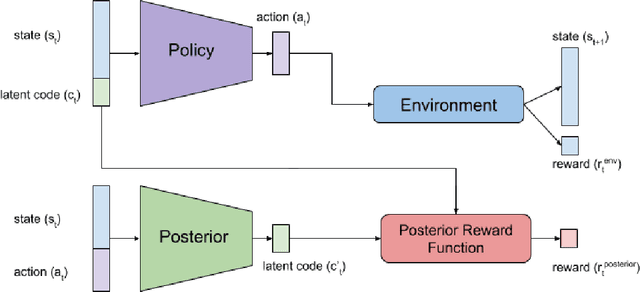

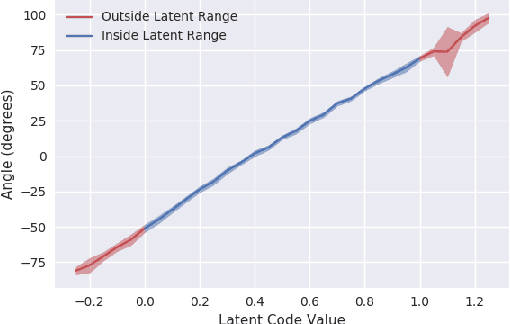
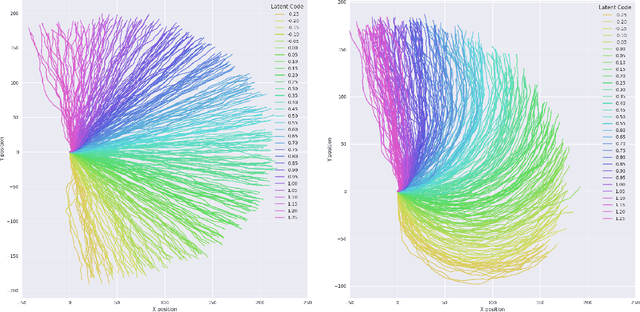
Recent advances in reinforcement learning have proved that given an environment we can learn to perform a task in that environment if we have access to some form of a reward function (dense, sparse or derived from IRL). But most of the algorithms focus on learning a single best policy to perform a given set of tasks. In this paper, we focus on an algorithm that learns to not just perform a task but different ways to perform the same task. As we know when the environment is complex enough there always exists multiple ways to perform a task. We show that using the concept of information maximization it is possible to learn latent codes for discovering multiple ways to perform any given task in an environment.