 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnh Nguyen
The effectiveness of feature attribution methods and its correlation with automatic evaluation scores
Jun 23, 2021
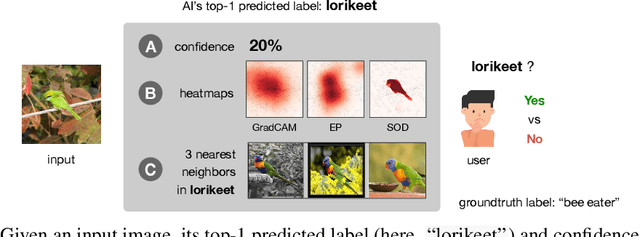

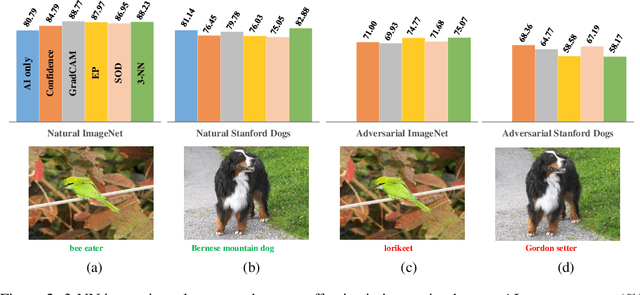

Explaining the decisions of an Artificial Intelligence (AI) model is increasingly critical in many real-world, high-stake applications. Hundreds of papers have either proposed new feature attribution methods, discussed or harnessed these tools in their work. However, despite humans being the target end-users, most attribution methods were only evaluated on proxy automatic-evaluation metrics. In this paper, we conduct the first, large-scale user study on 320 lay and 11 expert users to shed light on the effectiveness of state-of-the-art attribution methods in assisting humans in ImageNet classification, Stanford Dogs fine-grained classification, and these two tasks but when the input image contains adversarial perturbations. We found that, in overall, feature attribution is surprisingly not more effective than showing humans nearest training-set examples. On a hard task of fine-grained dog categorization, presenting attribution maps to humans does not help, but instead hurts the performance of human-AI teams compared to AI alone. Importantly, we found automatic attribution-map evaluation measures to correlate poorly with the actual human-AI team performance. Our findings encourage the community to rigorously test their methods on the downstream human-in-the-loop applications and to rethink the existing evaluation metrics.
The DEformer: An Order-Agnostic Distribution Estimating Transformer
Jun 13, 2021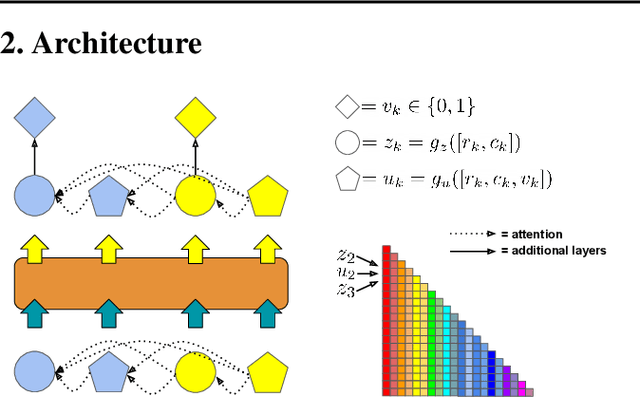
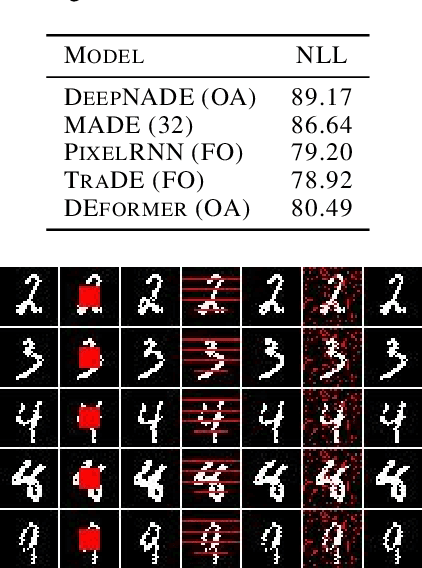
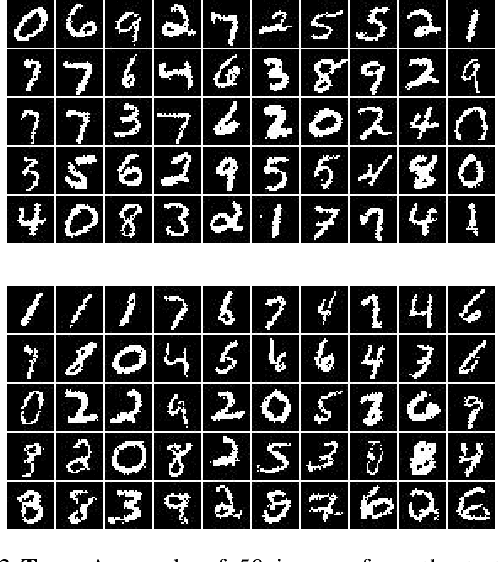
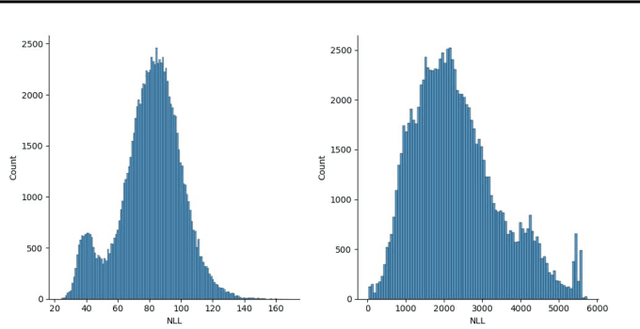
Order-agnostic autoregressive distribution estimation (OADE), i.e., autoregressive distribution estimation where the features can occur in an arbitrary order, is a challenging problem in generative machine learning. Prior work on OADE has encoded feature identity (e.g., pixel location) by assigning each feature to a distinct fixed position in an input vector. As a result, architectures built for these inputs must strategically mask either the input or model weights to learn the various conditional distributions necessary for inferring the full joint distribution of the dataset in an order-agnostic way. In this paper, we propose an alternative approach for encoding feature identities, where each feature's identity is included alongside its value in the input. This feature identity encoding strategy allows neural architectures designed for sequential data to be applied to the OADE task without modification. As a proof of concept, we show that a Transformer trained on this input (which we refer to as "the DEformer", i.e., the distribution estimating Transformer) can effectively model binarized-MNIST, approaching the average negative log-likelihood of fixed order autoregressive distribution estimating algorithms while still being entirely order-agnostic.
Inverting Adversarially Robust Networks for Image Synthesis
Jun 13, 2021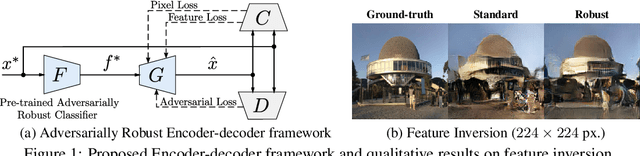
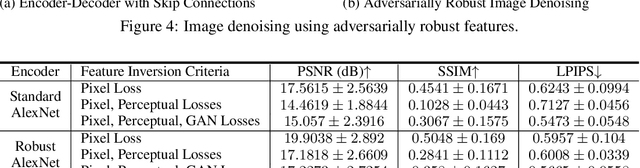
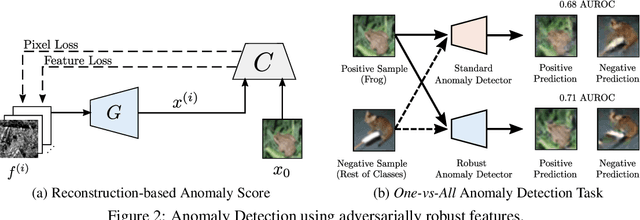
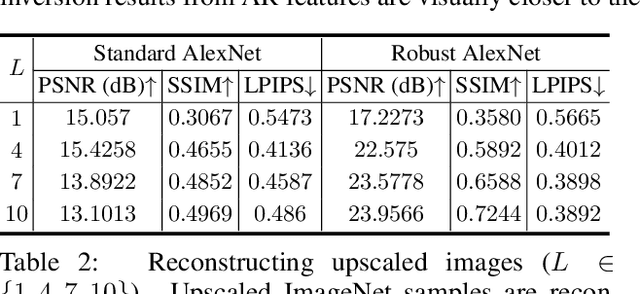
Recent research in adversarially robust classifiers suggests their representations tend to be aligned with human perception, which makes them attractive for image synthesis and restoration applications. Despite favorable empirical results on a few downstream tasks, their advantages are limited to slow and sensitive optimization-based techniques. Moreover, their use on generative models remains unexplored. This work proposes the use of robust representations as a perceptual primitive for feature inversion models, and show its benefits with respect to standard non-robust image features. We empirically show that adopting robust representations as an image prior significantly improves the reconstruction accuracy of CNN-based feature inversion models. Furthermore, it allows reconstructing images at multiple scales out-of-the-box. Following these findings, we propose an encoding-decoding network based on robust representations and show its advantages for applications such as anomaly detection, style transfer and image denoising.
Multiple Meta-model Quantifying for Medical Visual Question Answering
May 19, 2021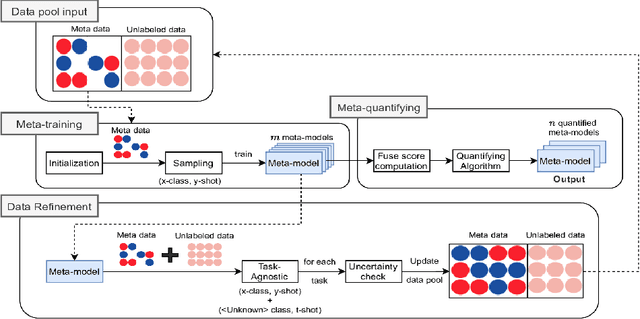
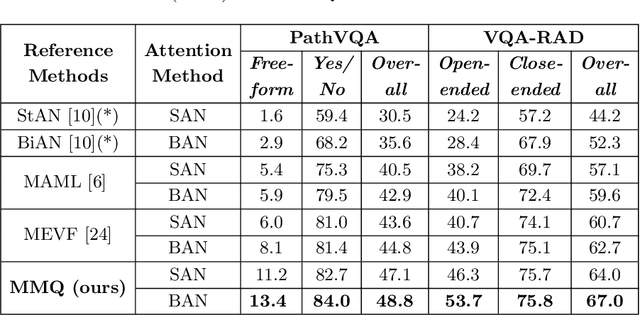
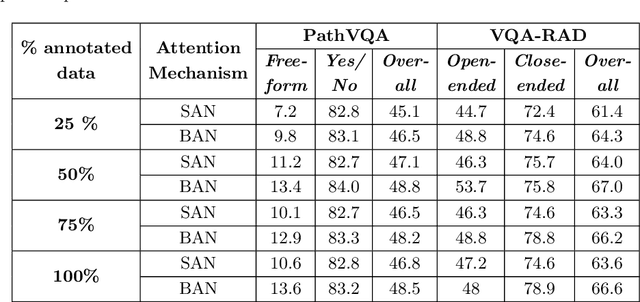
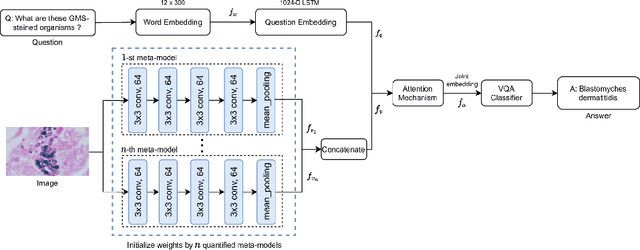
Transfer learning is an important step to extract meaningful features and overcome the data limitation in the medical Visual Question Answering (VQA) task. However, most of the existing medical VQA methods rely on external data for transfer learning, while the meta-data within the dataset is not fully utilized. In this paper, we present a new multiple meta-model quantifying method that effectively learns meta-annotation and leverages meaningful features to the medical VQA task. Our proposed method is designed to increase meta-data by auto-annotation, deal with noisy labels, and output meta-models which provide robust features for medical VQA tasks. Extensively experimental results on two public medical VQA datasets show that our approach achieves superior accuracy in comparison with other state-of-the-art methods, while does not require external data to train meta-models.
baller2vec++: A Look-Ahead Multi-Entity Transformer For Modeling Coordinated Agents
Apr 24, 2021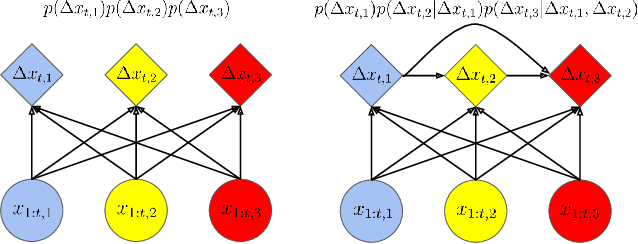
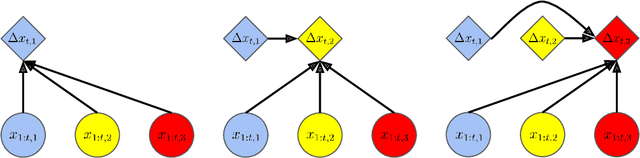
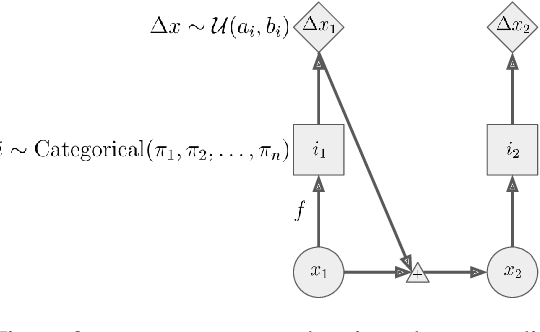
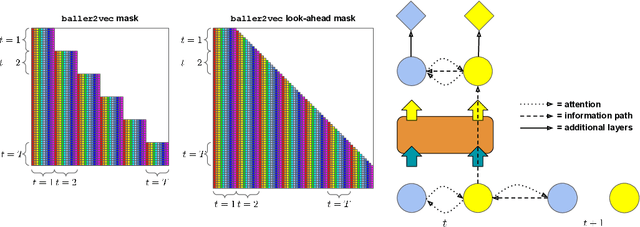
In many multi-agent spatiotemporal systems, the agents are under the influence of shared, unobserved variables (e.g., the play a team is executing in a game of basketball). As a result, the trajectories of the agents are often statistically dependent at any given time step; however, almost universally, multi-agent models implicitly assume the agents' trajectories are statistically independent at each time step. In this paper, we introduce baller2vec++, a multi-entity Transformer that can effectively model coordinated agents. Specifically, baller2vec++ applies a specially designed self-attention mask to a mixture of location and "look-ahead" trajectory sequences to learn the distributions of statistically dependent agent trajectories. We show that, unlike baller2vec (baller2vec++'s predecessor), baller2vec++ can learn to emulate the behavior of perfectly coordinated agents in a simulated toy dataset. Additionally, when modeling the trajectories of professional basketball players, baller2vec++ outperforms baller2vec by a wide margin.
Graph-based Person Signature for Person Re-Identifications
Apr 17, 2021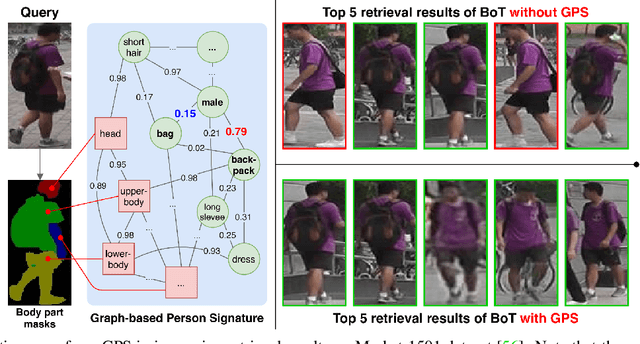

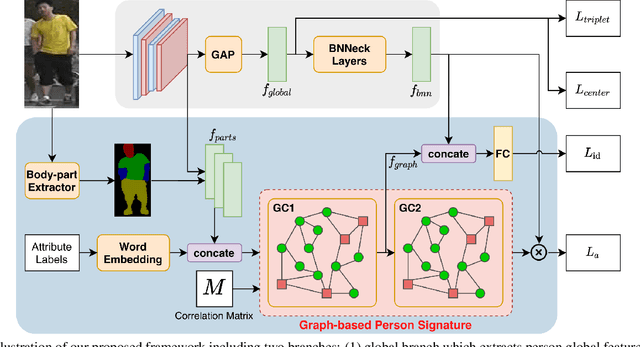
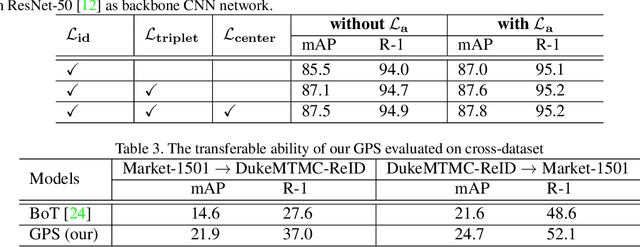
The task of person re-identification (ReID) is to match images of the same person over multiple non-overlapping camera views. Due to the variations in visual factors, previous works have investigated how the person identity, body parts, and attributes benefit the person ReID problem. However, the correlations between attributes, body parts, and within each attribute are not fully utilized. In this paper, we propose a new method to effectively aggregate detailed person descriptions (attributes labels) and visual features (body parts and global features) into a graph, namely Graph-based Person Signature, and utilize Graph Convolutional Networks to learn the topological structure of the visual signature of a person. The graph is integrated into a multi-branch multi-task framework for person re-identification. The extensive experiments are conducted to demonstrate the effectiveness of our proposed approach on two large-scale datasets, including Market-1501 and DukeMTMC-ReID. Our approach achieves competitive results among the state of the art and outperforms other attribute-based or mask-guided methods.
An Analysis of State-of-the-art Activation Functions For Supervised Deep Neural Network
Apr 05, 2021
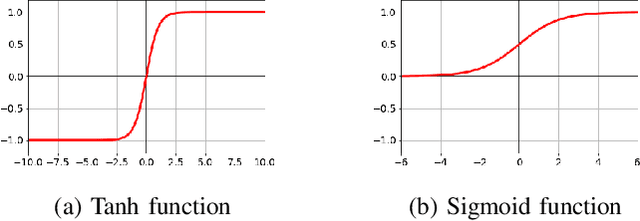
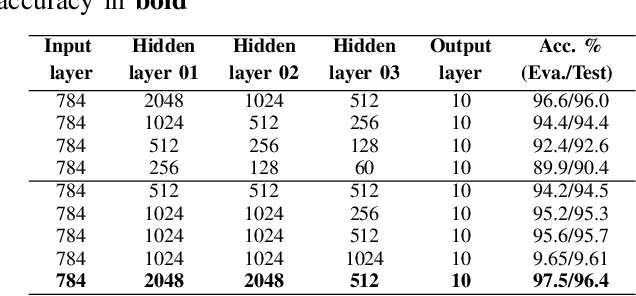
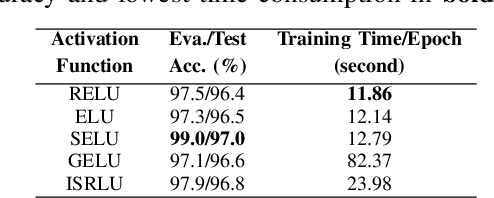
This paper provides an analysis of state-of-the-art activation functions with respect to supervised classification of deep neural network. These activation functions comprise of Rectified Linear Units (ReLU), Exponential Linear Unit (ELU), Scaled Exponential Linear Unit (SELU), Gaussian Error Linear Unit (GELU), and the Inverse Square Root Linear Unit (ISRLU). To evaluate, experiments over two deep learning network architectures integrating these activation functions are conducted. The first model, basing on Multilayer Perceptron (MLP), is evaluated with MNIST dataset to perform these activation functions. Meanwhile, the second model, likely VGGish-based architecture, is applied for Acoustic Scene Classification (ASC) Task 1A in DCASE 2018 challenge, thus evaluate whether these activation functions work well in different datasets as well as different network architectures.
Speech Emotion Recognition using Semantic Information
Mar 04, 2021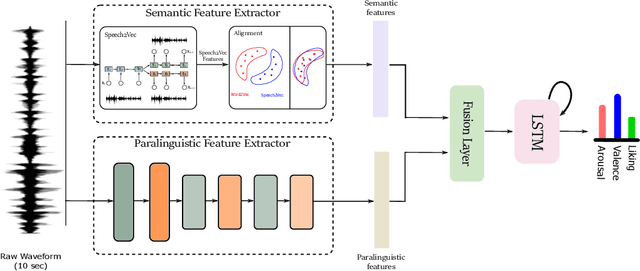

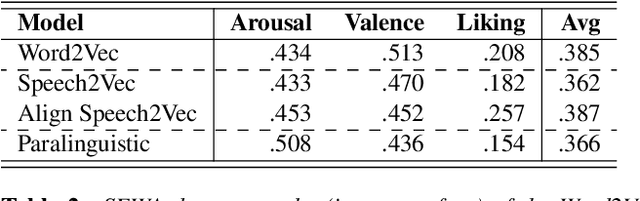

Speech emotion recognition is a crucial problem manifesting in a multitude of applications such as human computer interaction and education. Although several advancements have been made in the recent years, especially with the advent of Deep Neural Networks (DNN), most of the studies in the literature fail to consider the semantic information in the speech signal. In this paper, we propose a novel framework that can capture both the semantic and the paralinguistic information in the signal. In particular, our framework is comprised of a semantic feature extractor, that captures the semantic information, and a paralinguistic feature extractor, that captures the paralinguistic information. Both semantic and paraliguistic features are then combined to a unified representation using a novel attention mechanism. The unified feature vector is passed through a LSTM to capture the temporal dynamics in the signal, before the final prediction. To validate the effectiveness of our framework, we use the popular SEWA dataset of the AVEC challenge series and compare with the three winning papers. Our model provides state-of-the-art results in the valence and liking dimensions.