 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAngela Yao
Leveraging Action Affinity and Continuity for Semi-supervised Temporal Action Segmentation
Jul 18, 2022
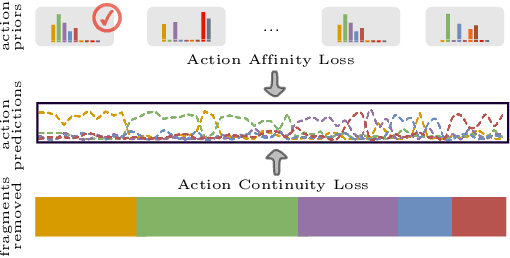
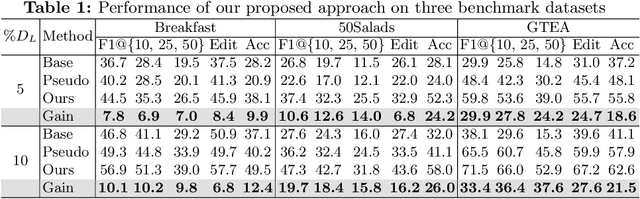
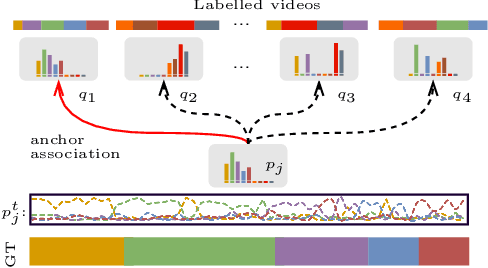

We present a semi-supervised learning approach to the temporal action segmentation task. The goal of the task is to temporally detect and segment actions in long, untrimmed procedural videos, where only a small set of videos are densely labelled, and a large collection of videos are unlabelled. To this end, we propose two novel loss functions for the unlabelled data: an action affinity loss and an action continuity loss. The action affinity loss guides the unlabelled samples learning by imposing the action priors induced from the labelled set. Action continuity loss enforces the temporal continuity of actions, which also provides frame-wise classification supervision. In addition, we propose an Adaptive Boundary Smoothing (ABS) approach to build coarser action boundaries for more robust and reliable learning. The proposed loss functions and ABS were evaluated on three benchmarks. Results show that they significantly improved action segmentation performance with a low amount (5% and 10%) of labelled data and achieved comparable results to full supervision with 50% labelled data. Furthermore, ABS succeeded in boosting performance when integrated into fully-supervised learning.
A Closer Look at Branch Classifiers of Multi-exit Architectures
Apr 28, 2022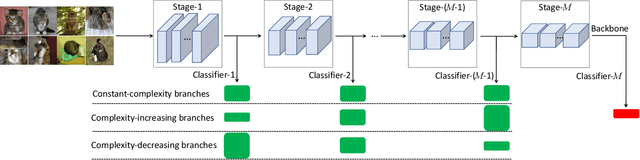
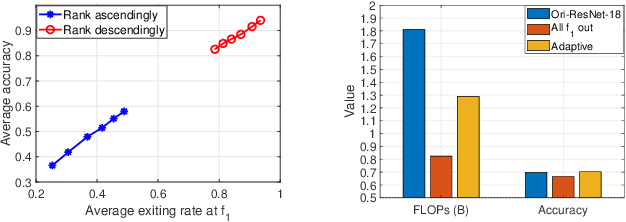

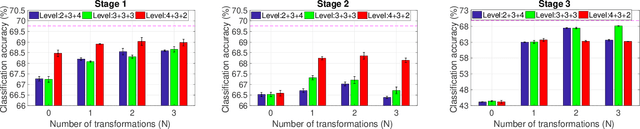
Multi-exit architectures consist of a backbone and branch classifiers that offer shortened inference pathways to reduce the run-time of deep neural networks. In this paper, we analyze different branching patterns that vary in their allocation of computational complexity for the branch classifiers. Constant-complexity branching keeps all branches the same, while complexity-increasing and complexity-decreasing branching place more complex branches later or earlier in the backbone respectively. Through extensive experimentation on multiple backbones and datasets, we find that complexity-decreasing branches are more effective than constant-complexity or complexity-increasing branches, which achieve the best accuracy-cost trade-off. We investigate a cause by using knowledge consistency to probe the effect of adding branches onto a backbone. Our findings show that complexity-decreasing branching yields the least disruption to the feature abstraction hierarchy of the backbone, which explains the effectiveness of the branching patterns.
TemporalUV: Capturing Loose Clothing with Temporally Coherent UV Coordinates
Apr 07, 2022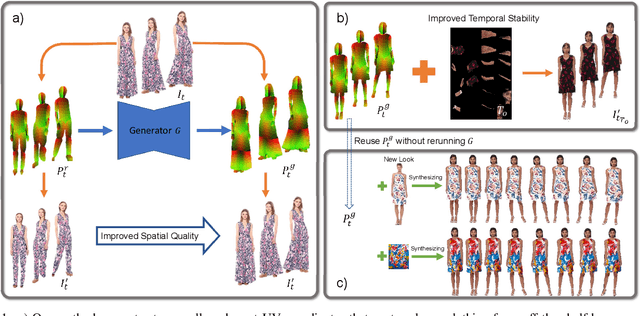
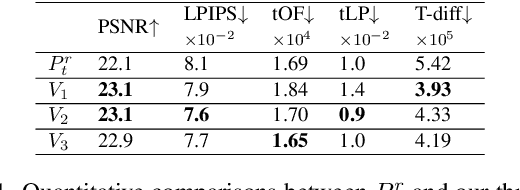
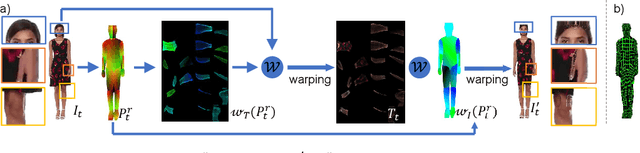
We propose a novel approach to generate temporally coherent UV coordinates for loose clothing. Our method is not constrained by human body outlines and can capture loose garments and hair. We implemented a differentiable pipeline to learn UV mapping between a sequence of RGB inputs and textures via UV coordinates. Instead of treating the UV coordinates of each frame separately, our data generation approach connects all UV coordinates via feature matching for temporal stability. Subsequently, a generative model is trained to balance the spatial quality and temporal stability. It is driven by supervised and unsupervised losses in both UV and image spaces. Our experiments show that the trained models output high-quality UV coordinates and generalize to new poses. Once a sequence of UV coordinates has been inferred by our model, it can be used to flexibly synthesize new looks and modified visual styles. Compared to existing methods, our approach reduces the computational workload to animate new outfits by several orders of magnitude.
Multi-Scale Memory-Based Video Deblurring
Apr 06, 2022

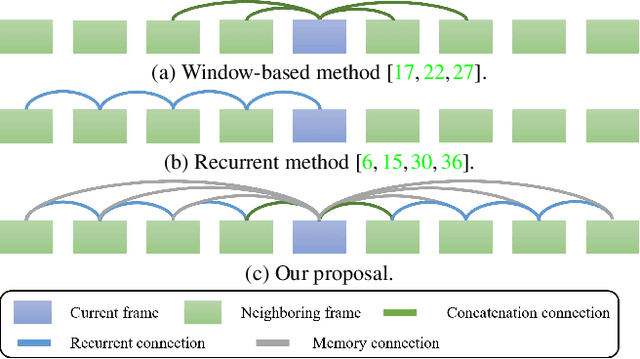

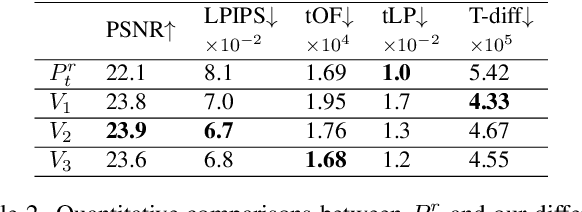
Video deblurring has achieved remarkable progress thanks to the success of deep neural networks. Most methods solve for the deblurring end-to-end with limited information propagation from the video sequence. However, different frame regions exhibit different characteristics and should be provided with corresponding relevant information. To achieve fine-grained deblurring, we designed a memory branch to memorize the blurry-sharp feature pairs in the memory bank, thus providing useful information for the blurry query input. To enrich the memory of our memory bank, we further designed a bidirectional recurrency and multi-scale strategy based on the memory bank. Experimental results demonstrate that our model outperforms other state-of-the-art methods while keeping the model complexity and inference time low. The code is available at https://github.com/jibo27/MemDeblur.
Assembly101: A Large-Scale Multi-View Video Dataset for Understanding Procedural Activities
Mar 28, 2022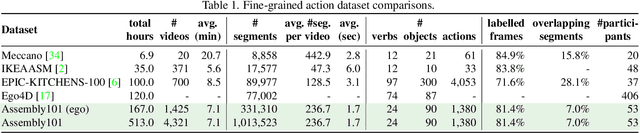

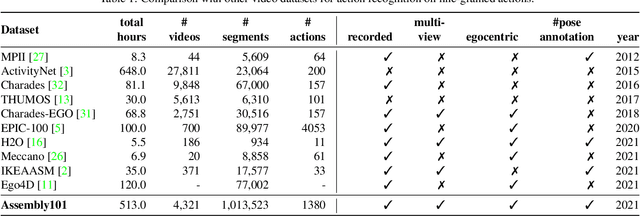

Assembly101 is a new procedural activity dataset featuring 4321 videos of people assembling and disassembling 101 "take-apart" toy vehicles. Participants work without fixed instructions, and the sequences feature rich and natural variations in action ordering, mistakes, and corrections. Assembly101 is the first multi-view action dataset, with simultaneous static (8) and egocentric (4) recordings. Sequences are annotated with more than 100K coarse and 1M fine-grained action segments, and 18M 3D hand poses. We benchmark on three action understanding tasks: recognition, anticipation and temporal segmentation. Additionally, we propose a novel task of detecting mistakes. The unique recording format and rich set of annotations allow us to investigate generalization to new toys, cross-view transfer, long-tailed distributions, and pose vs. appearance. We envision that Assembly101 will serve as a new challenge to investigate various activity understanding problems.
DropIT: Dropping Intermediate Tensors for Memory-Efficient DNN Training
Feb 28, 2022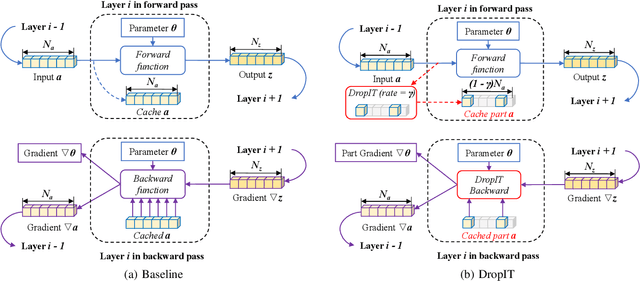
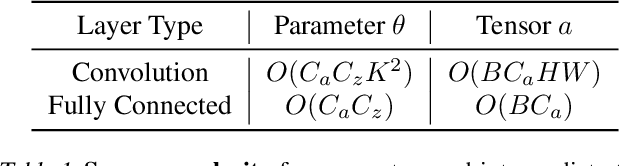
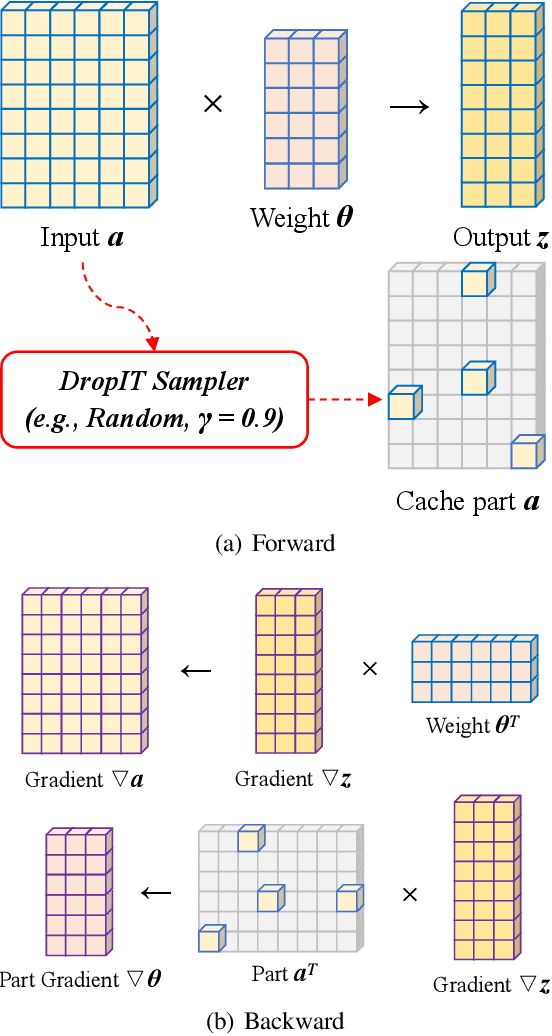
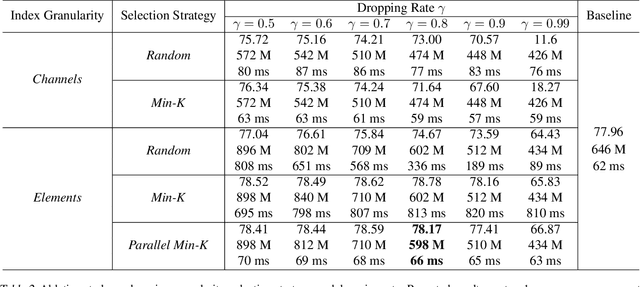
A standard hardware bottleneck when training deep neural networks is GPU memory. The bulk of memory is occupied by caching intermediate tensors for gradient computation in the backward pass. We propose a novel method to reduce this footprint by selecting and caching part of intermediate tensors for gradient computation. Our Intermediate Tensor Drop method (DropIT) adaptively drops components of the intermediate tensors and recovers sparsified tensors from the remaining elements in the backward pass to compute the gradient. Experiments show that we can drop up to 90% of the elements of the intermediate tensors in convolutional and fully-connected layers, saving 20% GPU memory during training while achieving higher test accuracy for standard backbones such as ResNet and Vision Transformer. Our code is available at https://github.com/ChenJoya/dropit.
Local and Global Point Cloud Reconstruction for 3D Hand Pose Estimation
Dec 13, 2021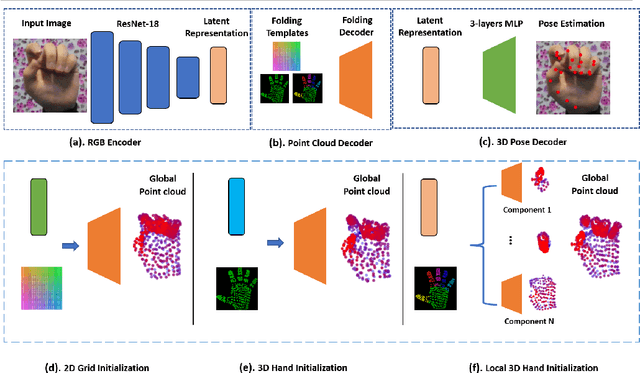
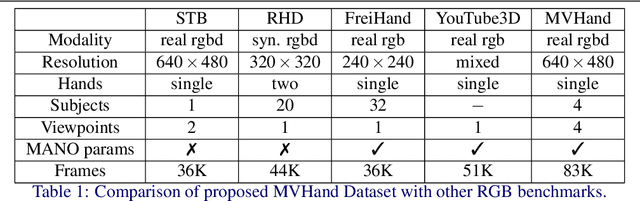
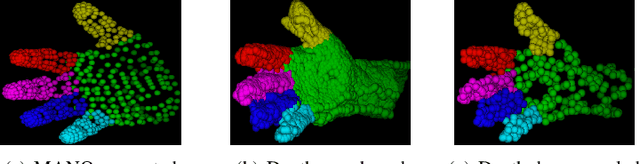
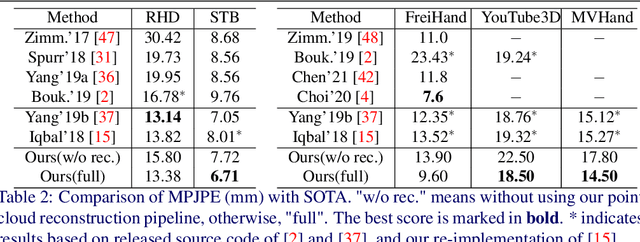
This paper addresses the 3D point cloud reconstruction and 3D pose estimation of the human hand from a single RGB image. To that end, we present a novel pipeline for local and global point cloud reconstruction using a 3D hand template while learning a latent representation for pose estimation. To demonstrate our method, we introduce a new multi-view hand posture dataset to obtain complete 3D point clouds of the hand in the real world. Experiments on our newly proposed dataset and four public benchmarks demonstrate the model's strengths. Our method outperforms competitors in 3D pose estimation while reconstructing realistic-looking complete 3D hand point clouds.
Video as Conditional Graph Hierarchy for Multi-Granular Question Answering
Dec 12, 2021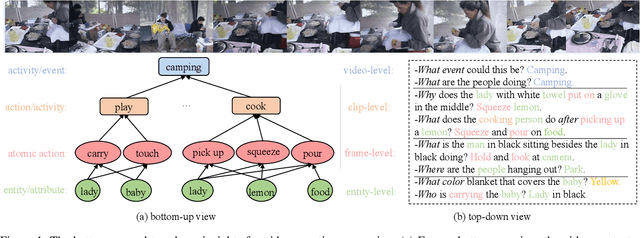
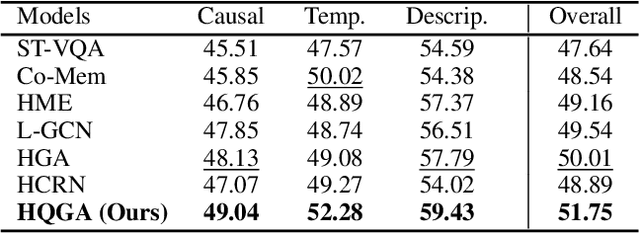
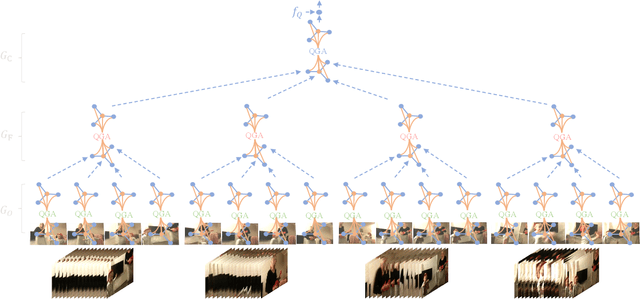
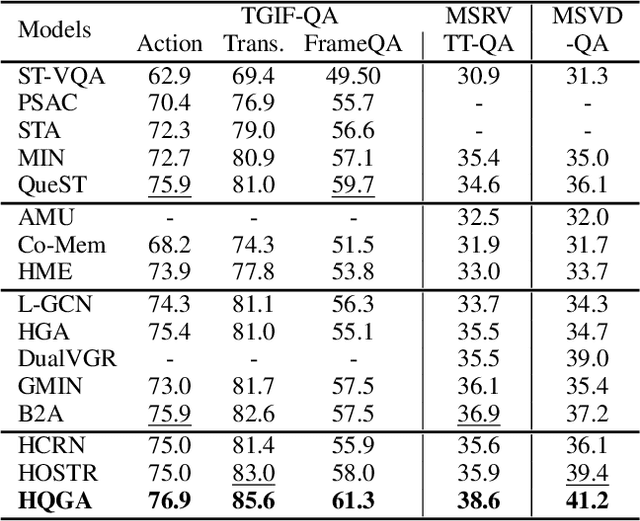
Video question answering requires models to understand and reason about both complex video and language data to correctly derive answers. Existing efforts focus on designing sophisticated cross-modal interactions to fuse the information from two modalities, while encoding the video and question holistically as frame and word sequences. Despite their success, these methods are essentially revolving around the sequential nature of video- and question-contents, providing little insight to the problem of question-answering and lacking interpretability as well. In this work, we argue that while video is presented in frame sequence, the visual elements (eg, objects, actions, activities and events) are not sequential but rather hierarchical in semantic space. To align with the multi-granular essence of linguistic concepts in language queries, we propose to model video as a conditional graph hierarchy which weaves together visual facts of different granularity in a level-wise manner, with the guidance of corresponding textual cues. Despite the simplicity, our extensive experiments demonstrate the superiority of such conditional hierarchical graph architecture, with clear performance improvements over prior methods and also better generalization across different type of questions. Further analyses also consolidate the model's reliability as it shows meaningful visual-textual evidences for the predicted answers.
Iterative Contrast-Classify For Semi-supervised Temporal Action Segmentation
Dec 08, 2021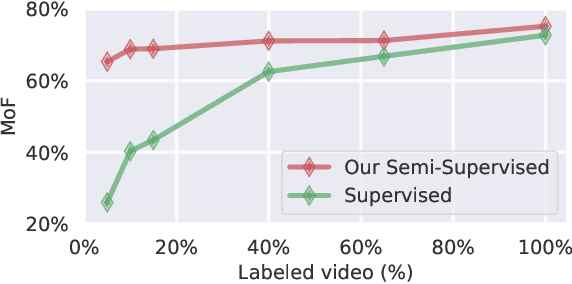
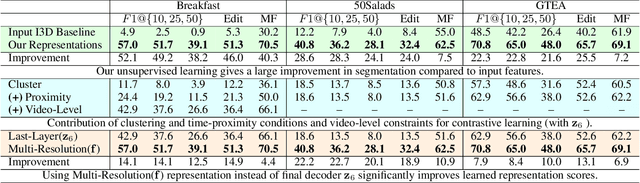
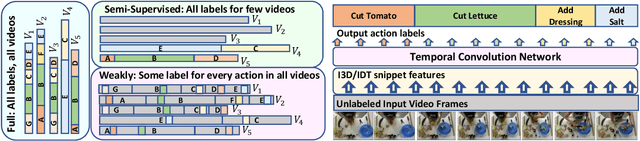
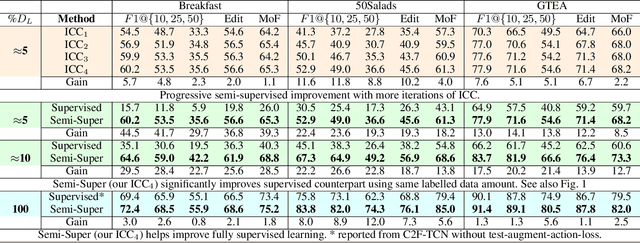
Temporal action segmentation classifies the action of each frame in (long) video sequences. Due to the high cost of frame-wise labeling, we propose the first semi-supervised method for temporal action segmentation. Our method hinges on unsupervised representation learning, which, for temporal action segmentation, poses unique challenges. Actions in untrimmed videos vary in length and have unknown labels and start/end times. Ordering of actions across videos may also vary. We propose a novel way to learn frame-wise representations from temporal convolutional networks (TCNs) by clustering input features with added time-proximity condition and multi-resolution similarity. By merging representation learning with conventional supervised learning, we develop an "Iterative-Contrast-Classify (ICC)" semi-supervised learning scheme. With more labelled data, ICC progressively improves in performance; ICC semi-supervised learning, with 40% labelled videos, performs similar to fully-supervised counterparts. Our ICC improves MoF by {+1.8, +5.6, +2.5}% on Breakfast, 50Salads and GTEA respectively for 100% labelled videos.
Iterative Frame-Level Representation Learning And Classification For Semi-Supervised Temporal Action Segmentation
Dec 02, 2021Temporal action segmentation classifies the action of each frame in (long) video sequences. Due to the high cost of frame-wise labeling, we propose the first semi-supervised method for temporal action segmentation. Our method hinges on unsupervised representation learning, which, for temporal action segmentation, poses unique challenges. Actions in untrimmed videos vary in length and have unknown labels and start/end times. Ordering of actions across videos may also vary. We propose a novel way to learn frame-wise representations from temporal convolutional networks (TCNs) by clustering input features with added time-proximity condition and multi-resolution similarity. By merging representation learning with conventional supervised learning, we develop an "Iterative-Contrast-Classify (ICC)" semi-supervised learning scheme. With more labelled data, ICC progressively improves in performance; ICC semi-supervised learning, with 40% labelled videos, performs similar to fully-supervised counterparts. Our ICC improves MoF by {+1.8, +5.6, +2.5}% on Breakfast, 50Salads and GTEA respectively for 100% labelled videos.