 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Dimensional Gender Bias Classification
May 01, 2020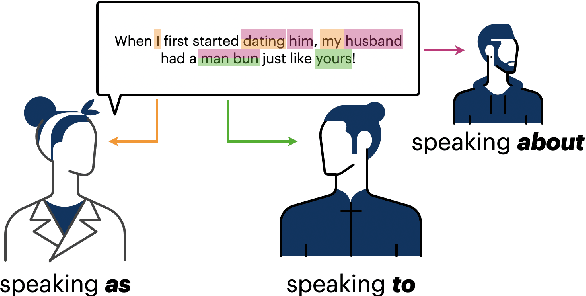
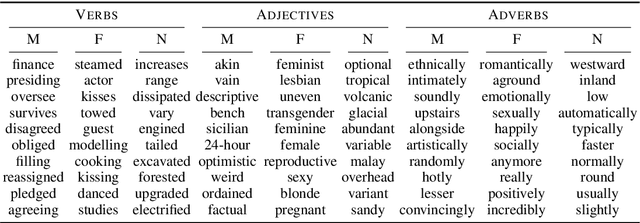
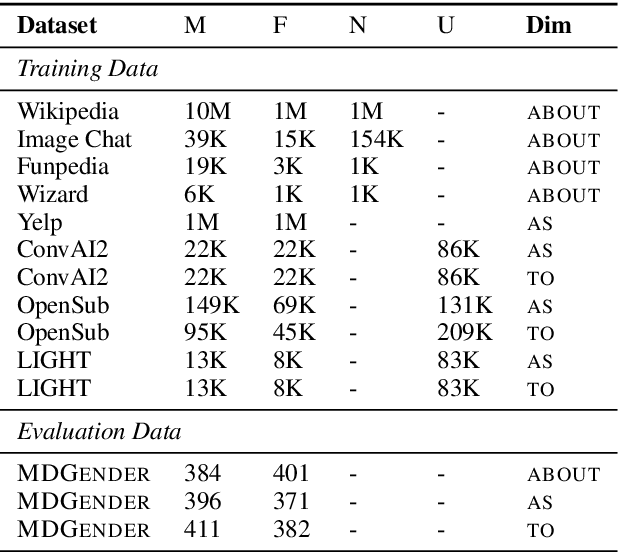
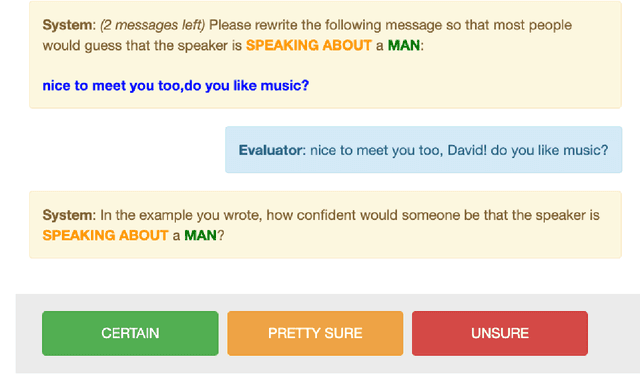
Machine learning models are trained to find patterns in data. NLP models can inadvertently learn socially undesirable patterns when training on gender biased text. In this work, we propose a general framework that decomposes gender bias in text along several pragmatic and semantic dimensions: bias from the gender of the person being spoken about, bias from the gender of the person being spoken to, and bias from the gender of the speaker. Using this fine-grained framework, we automatically annotate eight large scale datasets with gender information. In addition, we collect a novel, crowdsourced evaluation benchmark of utterance-level gender rewrites. Distinguishing between gender bias along multiple dimensions is important, as it enables us to train finer-grained gender bias classifiers. We show our classifiers prove valuable for a variety of important applications, such as controlling for gender bias in generative models, detecting gender bias in arbitrary text, and shed light on offensive language in terms of genderedness.
Multilingual Unsupervised Sentence Simplification
May 01, 2020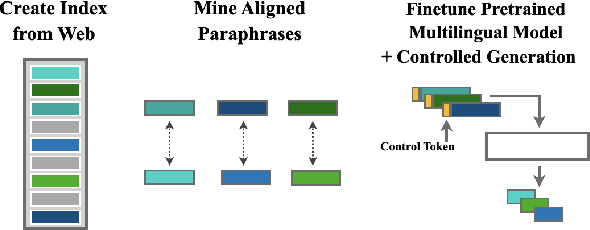

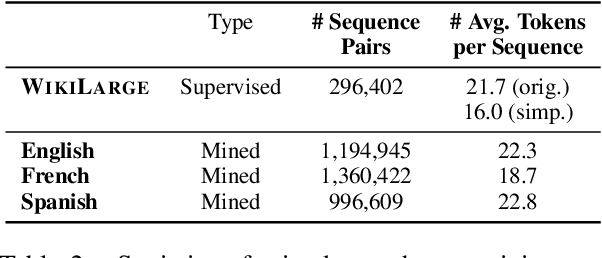
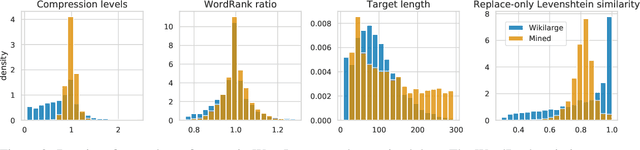
Progress in Sentence Simplification has been hindered by the lack of supervised data, particularly in languages other than English. Previous work has aligned sentences from original and simplified corpora such as English Wikipedia and Simple English Wikipedia, but this limits corpus size, domain, and language. In this work, we propose using unsupervised mining techniques to automatically create training corpora for simplification in multiple languages from raw Common Crawl web data. When coupled with a controllable generation mechanism that can flexibly adjust attributes such as length and lexical complexity, these mined paraphrase corpora can be used to train simplification systems in any language. We further incorporate multilingual unsupervised pretraining methods to create even stronger models and show that by training on mined data rather than supervised corpora, we outperform the previous best results. We evaluate our approach on English, French, and Spanish simplification benchmarks and reach state-of-the-art performance with a totally unsupervised approach. We will release our models and code to mine the data in any language included in Common Crawl.
Augmenting Transformers with KNN-Based Composite Memory for Dialogue
Apr 27, 2020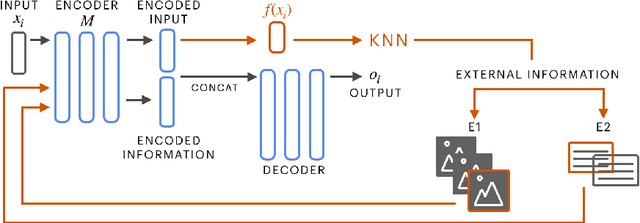
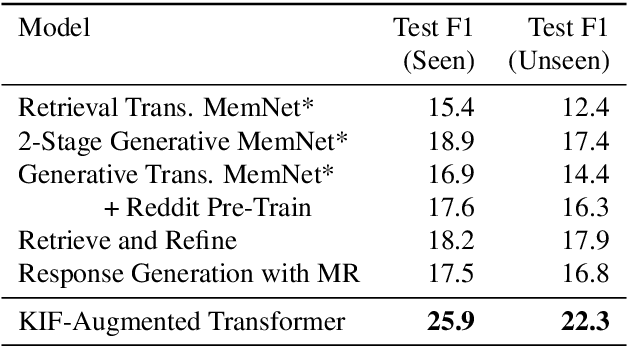
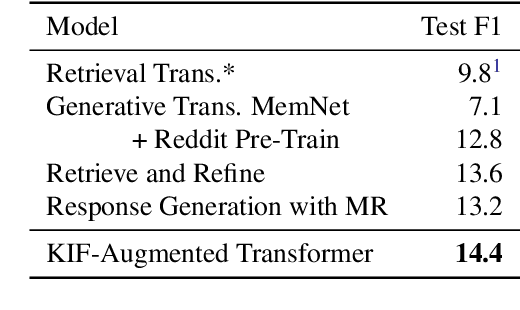
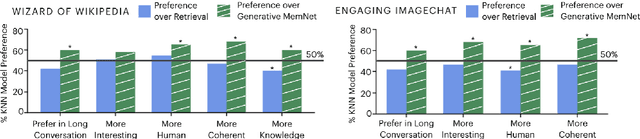
Various machine learning tasks can benefit from access to external information of different modalities, such as text and images. Recent work has focused on learning architectures with large memories capable of storing this knowledge. We propose augmenting generative Transformer neural networks with KNN-based Information Fetching (KIF) modules. Each KIF module learns a read operation to access fixed external knowledge. We apply these modules to generative dialogue modeling, a challenging task where information must be flexibly retrieved and incorporated to maintain the topic and flow of conversation. We demonstrate the effectiveness of our approach by identifying relevant knowledge from Wikipedia, images, and human-written dialogue utterances, and show that leveraging this retrieved information improves model performance, measured by automatic and human evaluation.
Training with Quantization Noise for Extreme Model Compression
Apr 17, 2020
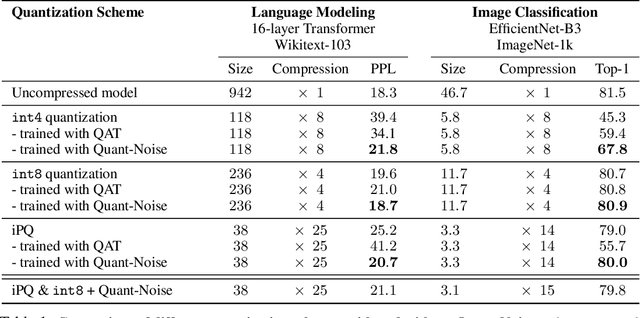
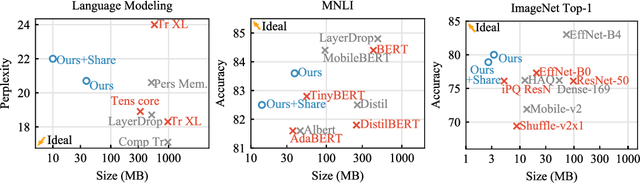
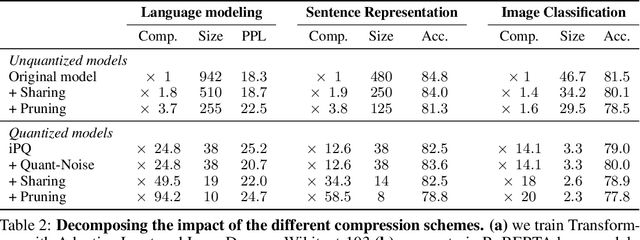
We tackle the problem of producing compact models, maximizing their accuracy for a given model size. A standard solution is to train networks with Quantization Aware Training, where the weights are quantized during training and the gradients approximated with the Straight-Through Estimator. In this paper, we extend this approach to work beyond int8 fixed-point quantization with extreme compression methods where the approximations introduced by STE are severe, such as Product Quantization. Our proposal is to only quantize a different random subset of weights during each forward, allowing for unbiased gradients to flow through the other weights. Controlling the amount of noise and its form allows for extreme compression rates while maintaining the performance of the original model. As a result we establish new state-of-the-art compromises between accuracy and model size both in natural language processing and image classification. For example, applying our method to state-of-the-art Transformer and ConvNet architectures, we can achieve 82.5% accuracy on MNLI by compressing RoBERTa to 14MB and 80.0 top-1 accuracy on ImageNet by compressing an EfficientNet-B3 to 3.3MB.
Accessing Higher-level Representations in Sequential Transformers with Feedback Memory
Mar 09, 2020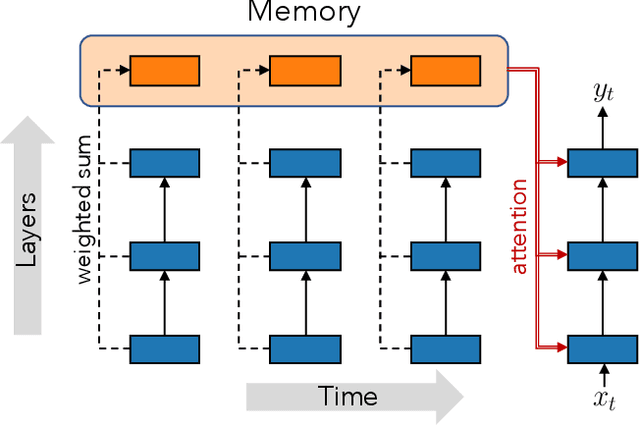
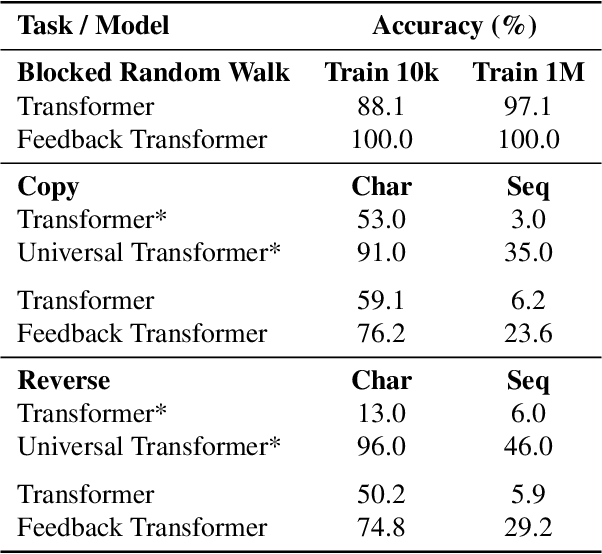
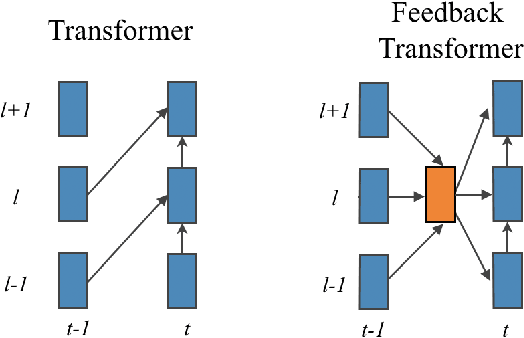
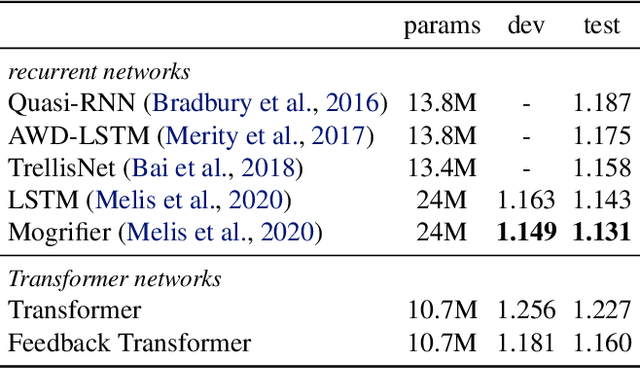
Transformers are feedforward networks that can process input tokens in parallel. While this parallelization makes them computationally efficient, it restricts the model from fully exploiting the sequential nature of the input - the representation at a given layer can only access representations from lower layers, rather than the higher level representations already built in previous time steps. In this work, we propose the Feedback Transformer architecture that exposes all previous representations to all future representations, meaning the lowest representation of the current timestep is formed from the highest-level abstract representation of the past. We demonstrate on a variety of benchmarks in language modeling, neural machine translation, summarization, and reinforcement learning that the increased representation capacity can improve over Transformer baselines.
Generating Interactive Worlds with Text
Dec 04, 2019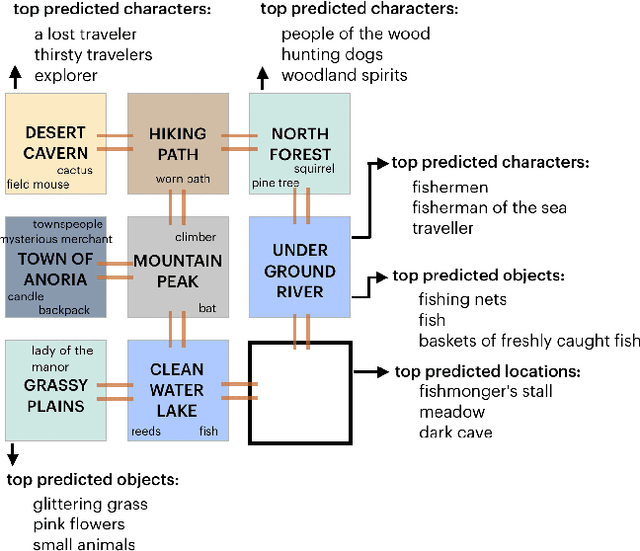
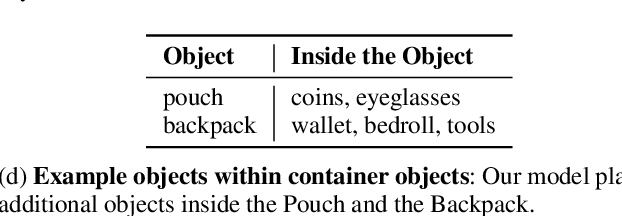
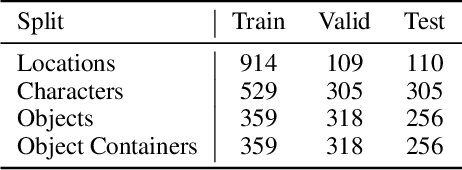
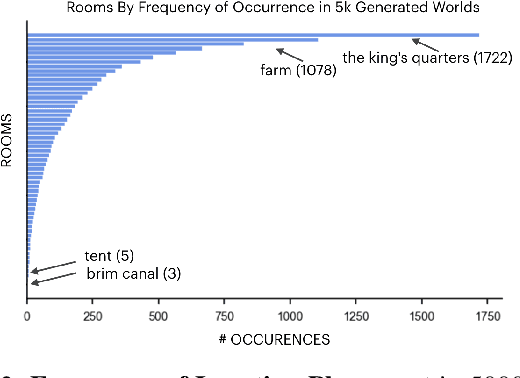
Procedurally generating cohesive and interesting game environments is challenging and time-consuming. In order for the relationships between the game elements to be natural, common-sense has to be encoded into arrangement of the elements. In this work, we investigate a machine learning approach for world creation using content from the multi-player text adventure game environment LIGHT. We introduce neural network based models to compositionally arrange locations, characters, and objects into a coherent whole. In addition to creating worlds based on existing elements, our models can generate new game content. Humans can also leverage our models to interactively aid in worldbuilding. We show that the game environments created with our approach are cohesive, diverse, and preferred by human evaluators compared to other machine learning based world construction algorithms.
Queens are Powerful too: Mitigating Gender Bias in Dialogue Generation
Nov 10, 2019
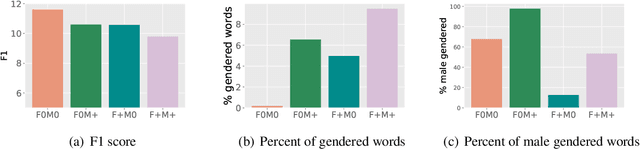
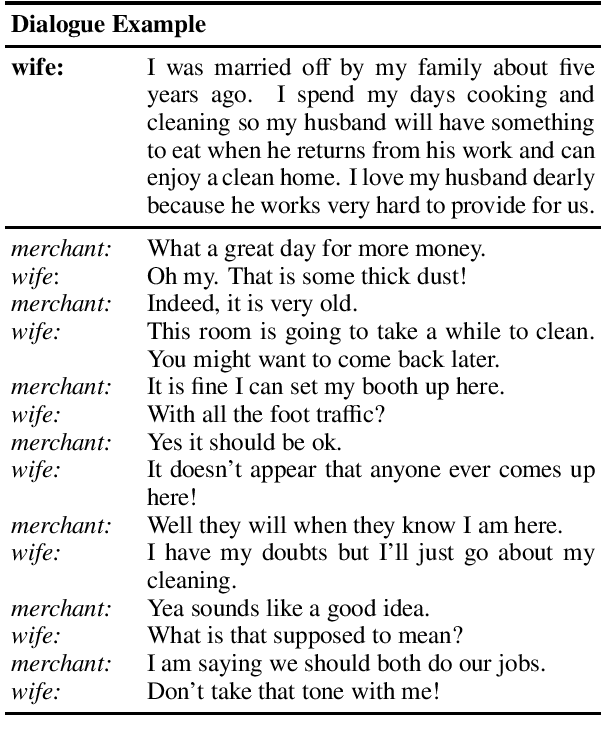
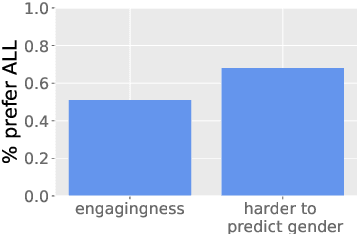
Models often easily learn biases present in the training data, and their predictions directly reflect this bias. We analyze the presence of gender bias in dialogue and examine the subsequent effect on generative chitchat dialogue models. Based on this analysis, we propose a combination of three techniques to mitigate bias: counterfactual data augmentation, targeted data collection, and conditional training. We focus on the multi-player text-based fantasy adventure dataset LIGHT as a testbed for our work. LIGHT contains gender imbalance between male and female characters with around 1.6 times as many male characters, likely because it is entirely collected by crowdworkers and reflects common biases that exist in fantasy or medieval settings. We show that (i) our proposed techniques mitigate gender bias by balancing the genderedness of generated dialogue utterances; and (ii) they work particularly well in combination. Further, we show through various metrics---such as quantity of gendered words, a dialogue safety classifier, and human evaluation---that our models generate less gendered, but still engaging chitchat responses.
Using Local Knowledge Graph Construction to Scale Seq2Seq Models to Multi-Document Inputs
Oct 18, 2019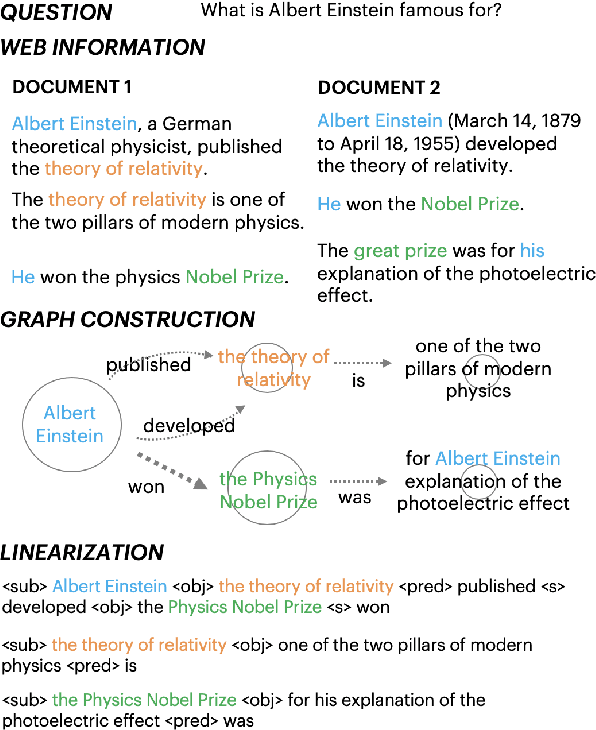

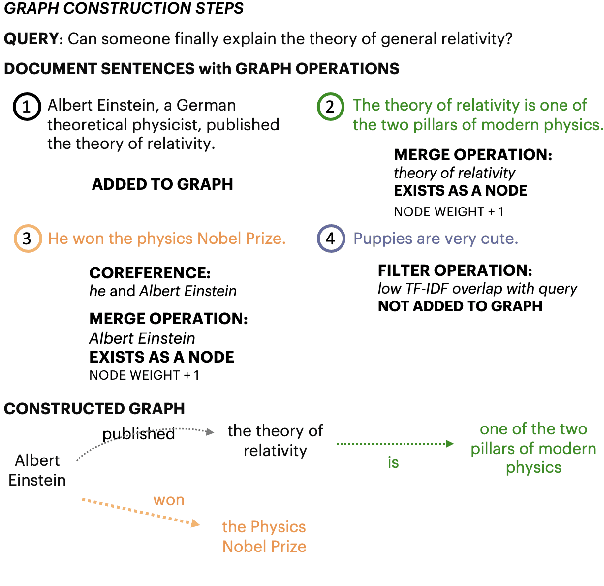
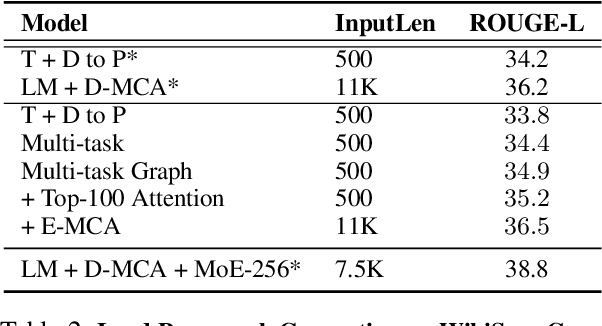
Query-based open-domain NLP tasks require information synthesis from long and diverse web results. Current approaches extractively select portions of web text as input to Sequence-to-Sequence models using methods such as TF-IDF ranking. We propose constructing a local graph structured knowledge base for each query, which compresses the web search information and reduces redundancy. We show that by linearizing the graph into a structured input sequence, models can encode the graph representations within a standard Sequence-to-Sequence setting. For two generative tasks with very long text input, long-form question answering and multi-document summarization, feeding graph representations as input can achieve better performance than using retrieved text portions.
Reducing Transformer Depth on Demand with Structured Dropout
Sep 25, 2019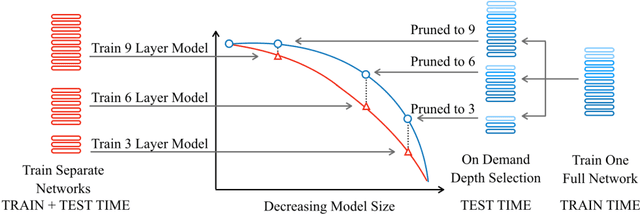
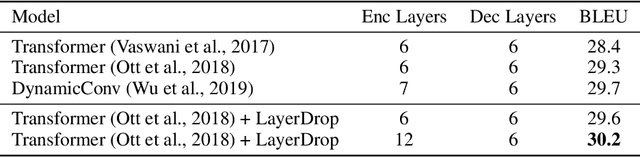

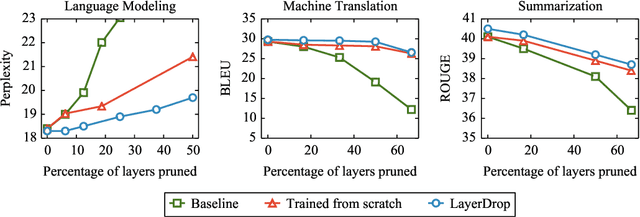
Overparameterized transformer networks have obtained state of the art results in various natural language processing tasks, such as machine translation, language modeling, and question answering. These models contain hundreds of millions of parameters, necessitating a large amount of computation and making them prone to overfitting. In this work, we explore LayerDrop, a form of structured dropout, which has a regularization effect during training and allows for efficient pruning at inference time. In particular, we show that it is possible to select sub-networks of any depth from one large network without having to finetune them and with limited impact on performance. We demonstrate the effectiveness of our approach by improving the state of the art on machine translation, language modeling, summarization, question answering, and language understanding benchmarks. Moreover, we show that our approach leads to small BERT-like models of higher quality compared to training from scratch or using distillation.
ELI5: Long Form Question Answering
Jul 22, 2019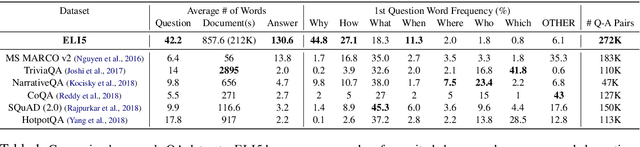


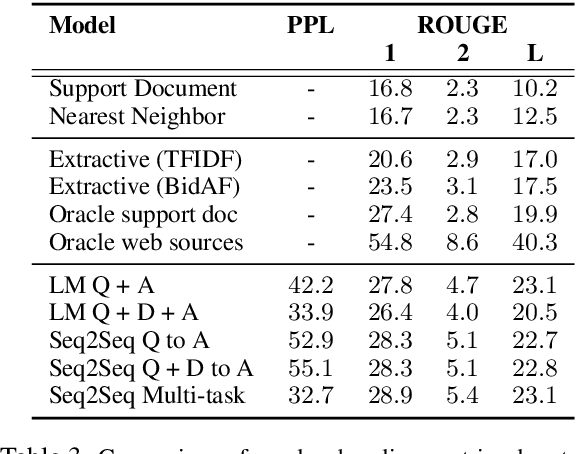
We introduce the first large-scale corpus for long-form question answering, a task requiring elaborate and in-depth answers to open-ended questions. The dataset comprises 270K threads from the Reddit forum ``Explain Like I'm Five'' (ELI5) where an online community provides answers to questions which are comprehensible by five year olds. Compared to existing datasets, ELI5 comprises diverse questions requiring multi-sentence answers. We provide a large set of web documents to help answer the question. Automatic and human evaluations show that an abstractive model trained with a multi-task objective outperforms conventional Seq2Seq, language modeling, as well as a strong extractive baseline. However, our best model is still far from human performance since raters prefer gold responses in over 86% of cases, leaving ample opportunity for future improvement.