 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Reinforcement Learning in the Algorithmic Trading Problem
Feb 26, 2020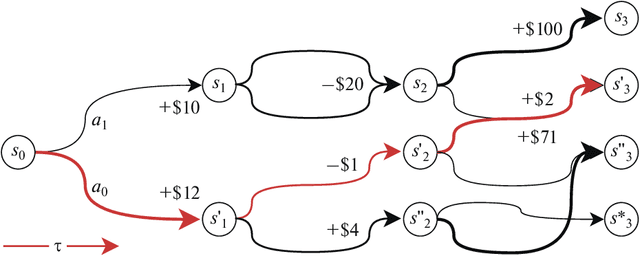
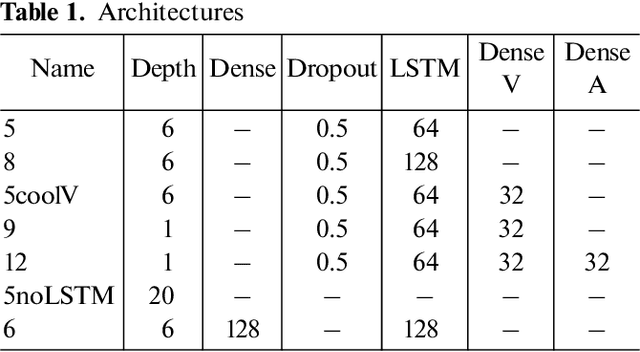
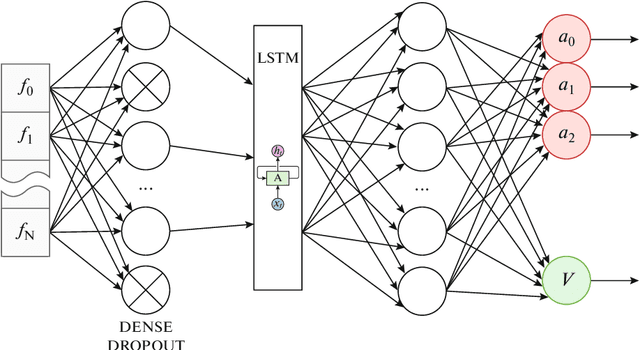
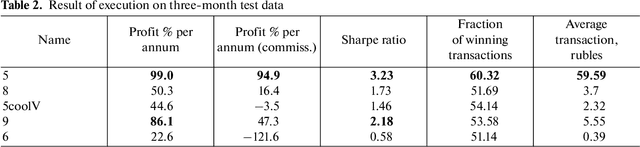
The development of reinforced learning methods has extended application to many areas including algorithmic trading. In this paper trading on the stock exchange is interpreted into a game with a Markov property consisting of states, actions, and rewards. A system for trading the fixed volume of a financial instrument is proposed and experimentally tested; this is based on the asynchronous advantage actor-critic method with the use of several neural network architectures. The application of recurrent layers in this approach is investigated. The experiments were performed on real anonymized data. The best architecture demonstrated a trading strategy for the RTS Index futures (MOEX:RTSI) with a profitability of 66% per annum accounting for commission. The project source code is available via the following link: http://github.com/evgps/a3c_trading.
Block Hankel Tensor ARIMA for Multiple Short Time Series Forecasting
Feb 25, 2020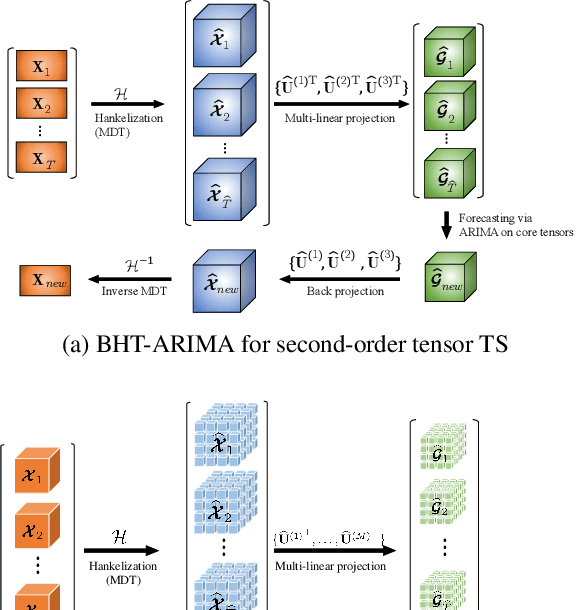
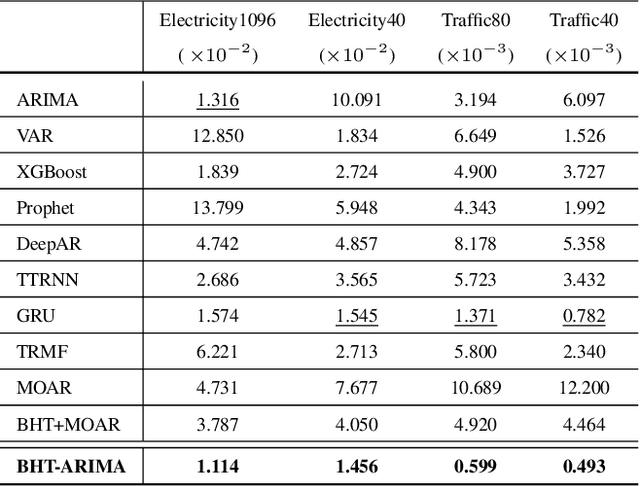
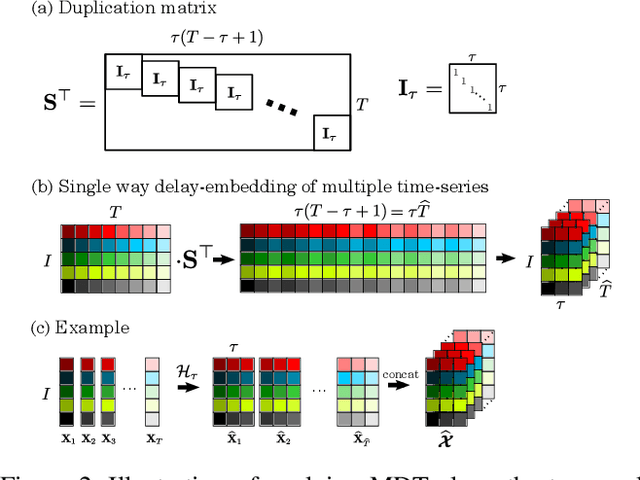
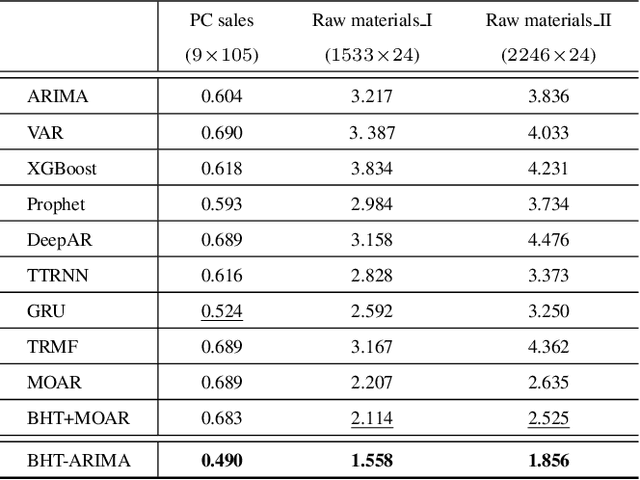
This work proposes a novel approach for multiple time series forecasting. At first, multi-way delay embedding transform (MDT) is employed to represent time series as low-rank block Hankel tensors (BHT). Then, the higher-order tensors are projected to compressed core tensors by applying Tucker decomposition. At the same time, the generalized tensor Autoregressive Integrated Moving Average (ARIMA) is explicitly used on consecutive core tensors to predict future samples. In this manner, the proposed approach tactically incorporates the unique advantages of MDT tensorization (to exploit mutual correlations) and tensor ARIMA coupled with low-rank Tucker decomposition into a unified framework. This framework exploits the low-rank structure of block Hankel tensors in the embedded space and captures the intrinsic correlations among multiple TS, which thus can improve the forecasting results, especially for multiple short time series. Experiments conducted on three public datasets and two industrial datasets verify that the proposed BHT-ARIMA effectively improves forecasting accuracy and reduces computational cost compared with the state-of-the-art methods.
Reduced-Order Modeling of Deep Neural Networks
Nov 25, 2019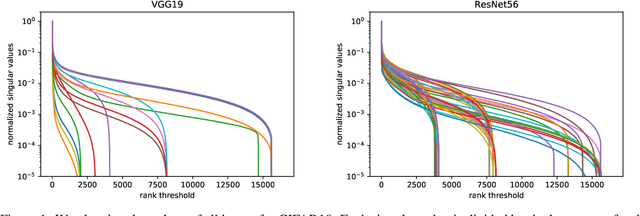

We introduce a new method for speeding up the inference of deep neural networks. It is somewhat inspired by the reduced-order modeling techniques for dynamical systems.The cornerstone of the proposed method is the maximum volume algorithm. We demonstrate efficiency on neural networks pre-trained on different datasets. We show that in many practical cases it is possible to replace convolutional layers with much smaller fully-connected layers with a relatively small drop in accuracy.
Manifold Modeling in Embedded Space: A Perspective for Interpreting "Deep Image Prior"
Aug 08, 2019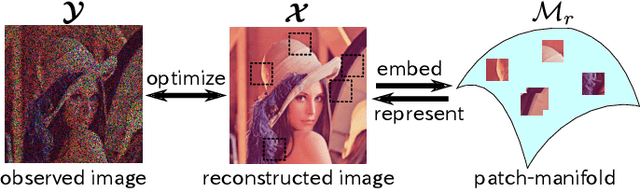
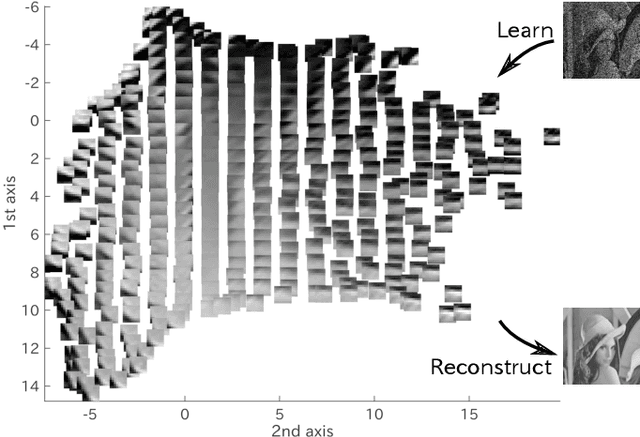
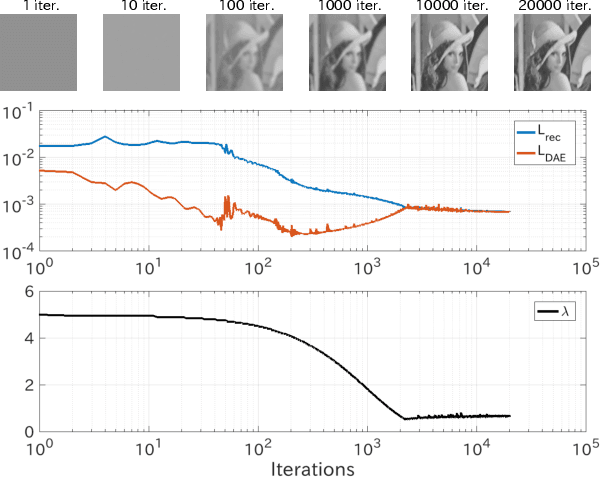

Deep image prior (DIP), which utilizes a deep convolutional network (ConvNet) structure itself as an image prior, has attractive attentions in computer vision community. It empirically showed that the effectiveness of ConvNet structure in various image restoration applications. However, why the DIP works so well is still in black box, and why ConvNet is essential for images is not very clear. In this study, we tackle this question by considering the convolution divided into "embedding" and "transformation", and proposing a simple, but essential, modeling approach of images/tensors related with dynamical system or self-similarity. The proposed approach named as manifold modeling in embedded space (MMES) can be implemented by using a denoising-auto-encoder in combination with multiway delay-embedding transform. In spite of its simplicity, the image/tensor completion and super-resolution results of MMES were very similar even competitive with DIP in our experiments, and these results would help us for reinterpreting/characterizing the DIP from a perspective of "smooth patch-manifold prior".
Multi-Kernel Capsule Network for Schizophrenia Identification
Jul 30, 2019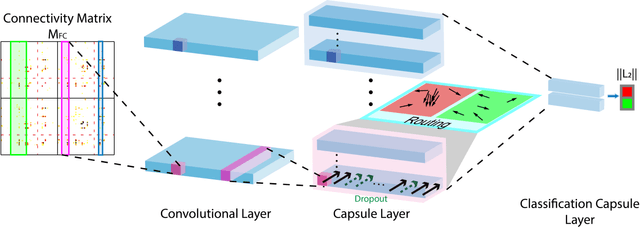
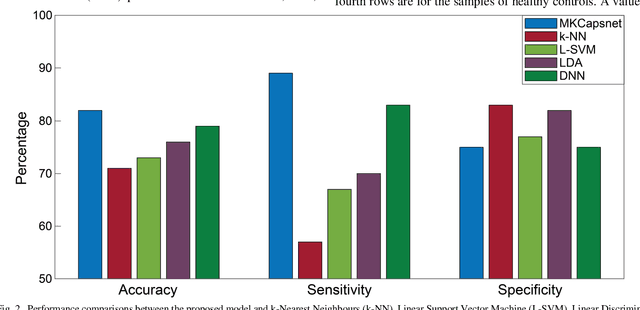
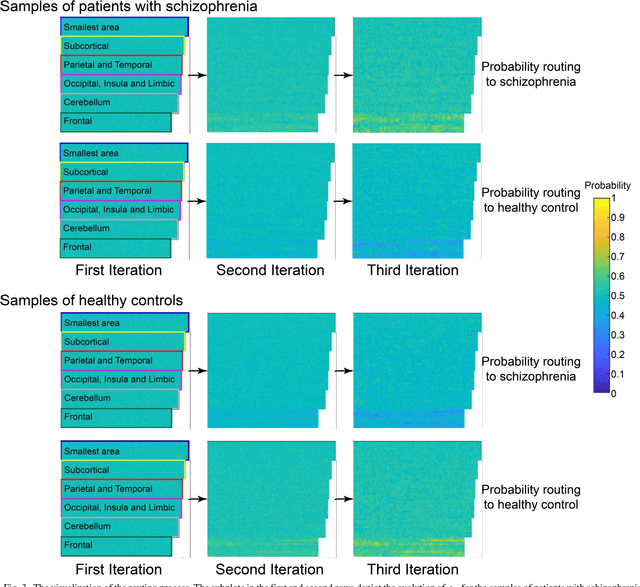
Objective: Schizophrenia seriously affects the quality of life. To date, both simple (linear discriminant analysis) and complex (deep neural network) machine learning methods have been utilized to identify schizophrenia based on functional connectivity features. The existing simple methods need two separate steps (i.e., feature extraction and classification) to achieve the identification, which disables simultaneous tuning for the best feature extraction and classifier training. The complex methods integrate two steps and can be simultaneously tuned to achieve optimal performance, but these methods require a much larger amount of data for model training. Methods: To overcome the aforementioned drawbacks, we proposed a multi-kernel capsule network (MKCapsnet), which was developed by considering the brain anatomical structure. Kernels were set to match with partition sizes of brain anatomical structure in order to capture interregional connectivities at the varying scales. With the inspiration of widely-used dropout strategy in deep learning, we developed vector dropout in the capsule layer to prevent overfitting of the model. Results: The comparison results showed that the proposed method outperformed the state-of-the-art methods. Besides, we compared performances using different parameters and illustrated the routing process to reveal characteristics of the proposed method. Conclusion: MKCapsnet is promising for schizophrenia identification. Significance: Our study not only proposed a multi-kernel capsule network but also provided useful information in the parameter setting, which is informative for further studies using a capsule network for neurophysiological signal classification.
One time is not enough: iterative tensor decomposition for neural network compression
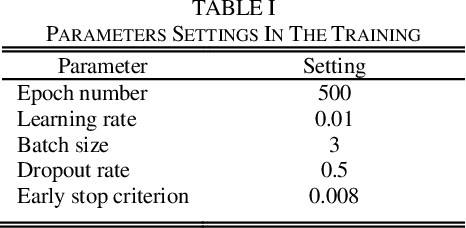
Mar 24, 2019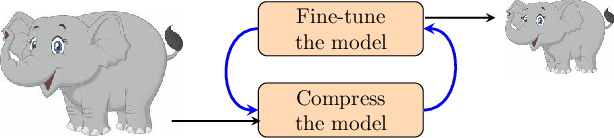
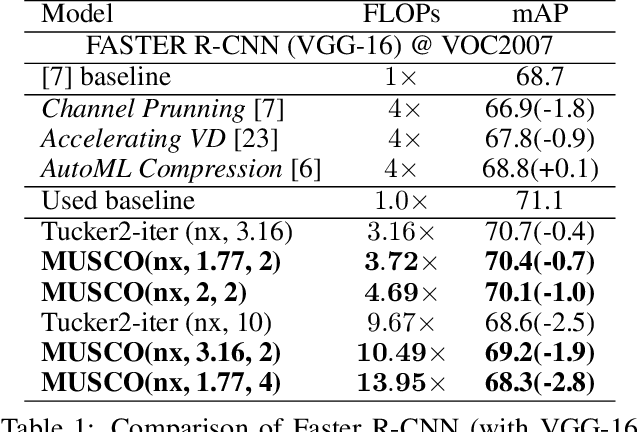
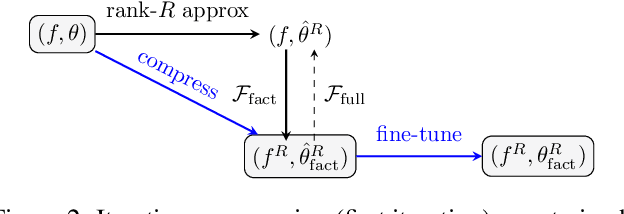

The low-rank tensor approximation is very promising for the compression of deep neural networks. We propose a new simple and efficient iterative approach, which alternates low-rank factorization with a smart rank selection and fine-tuning. We demonstrate the efficiency of our method comparing to non-iterative ones. Our approach improves the compression rate while maintaining the accuracy for a variety of tasks.
Learning the Hierarchical Parts of Objects by Deep Non-Smooth Nonnegative Matrix Factorization
Mar 20, 2018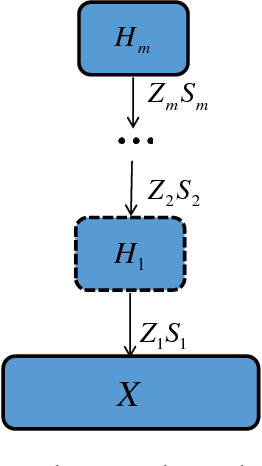
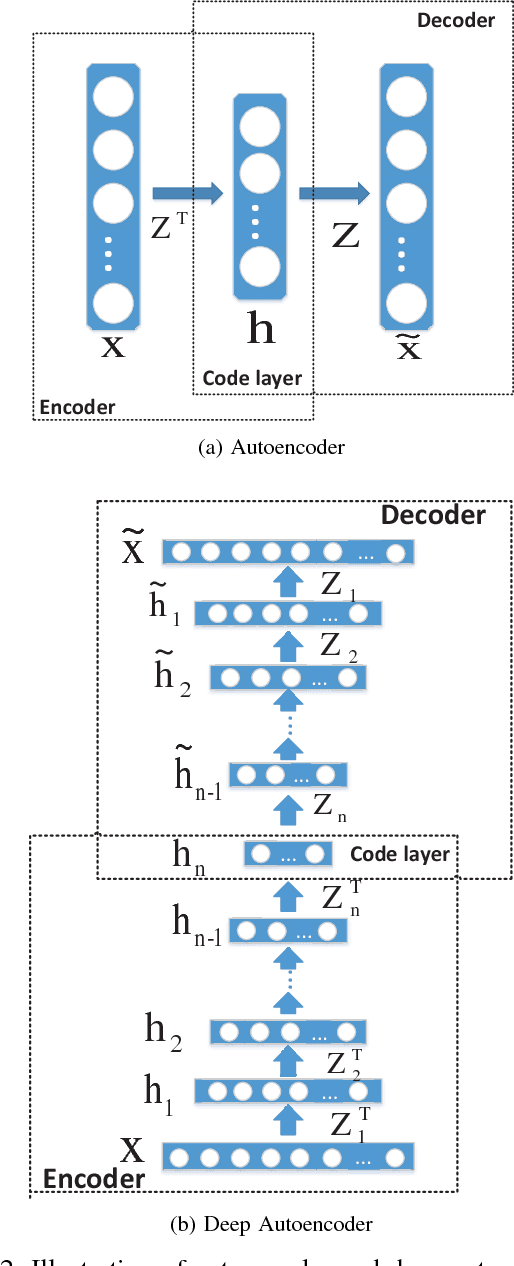


Nonsmooth Nonnegative Matrix Factorization (nsNMF) is capable of producing more localized, less overlapped feature representations than other variants of NMF while keeping satisfactory fit to data. However, nsNMF as well as other existing NMF methods is incompetent to learn hierarchical features of complex data due to its shallow structure. To fill this gap, we propose a deep nsNMF method coined by the fact that it possesses a deeper architecture compared with standard nsNMF. The deep nsNMF not only gives parts-based features due to the nonnegativity constraints, but also creates higher-level, more abstract features by combing lower-level ones. The in-depth description of how deep architecture can help to efficiently discover abstract features in dnsNMF is presented. And we also show that the deep nsNMF has close relationship with the deep autoencoder, suggesting that the proposed model inherits the major advantages from both deep learning and NMF. Extensive experiments demonstrate the standout performance of the proposed method in clustering analysis.
Group Component Analysis for Multiblock Data: Common and Individual Feature Extraction
Mar 12, 2017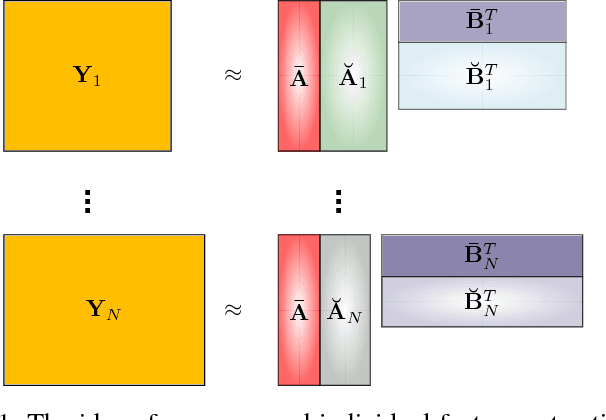
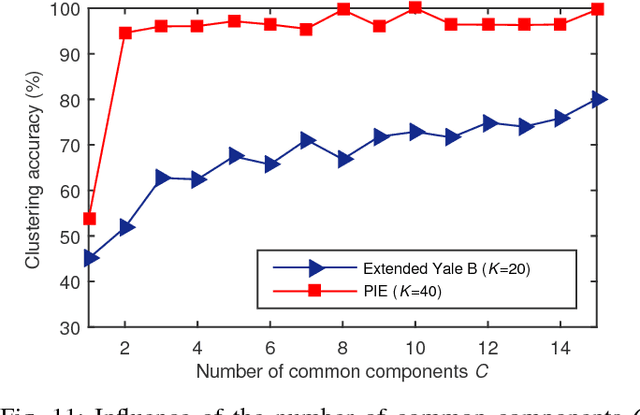
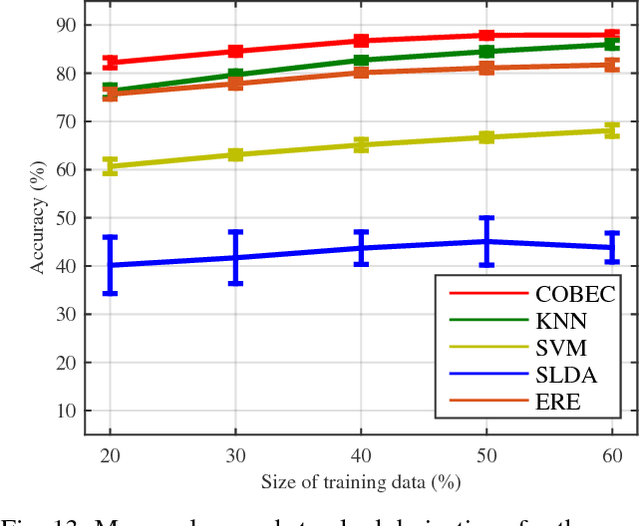
Very often data we encounter in practice is a collection of matrices rather than a single matrix. These multi-block data are naturally linked and hence often share some common features and at the same time they have their own individual features, due to the background in which they are measured and collected. In this study we proposed a new scheme of common and individual feature analysis (CIFA) that processes multi-block data in a linked way aiming at discovering and separating their common and individual features. According to whether the number of common features is given or not, two efficient algorithms were proposed to extract the common basis which is shared by all data. Then feature extraction is performed on the common and the individual spaces separately by incorporating the techniques such as dimensionality reduction and blind source separation. We also discussed how the proposed CIFA can significantly improve the performance of classification and clustering tasks by exploiting common and individual features of samples respectively. Our experimental results show some encouraging features of the proposed methods in comparison to the state-of-the-art methods on synthetic and real data.
* 13 pages,11 figures
Tensor Ring Decomposition
Jun 17, 2016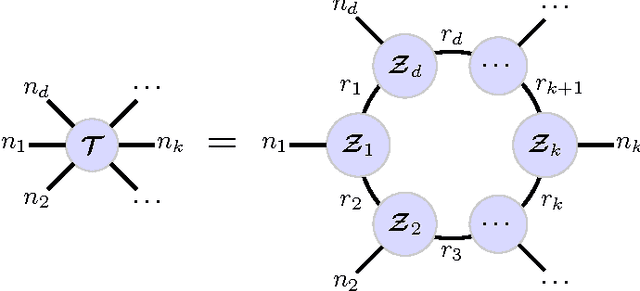


Tensor networks have in recent years emerged as the powerful tools for solving the large-scale optimization problems. One of the most popular tensor network is tensor train (TT) decomposition that acts as the building blocks for the complicated tensor networks. However, the TT decomposition highly depends on permutations of tensor dimensions, due to its strictly sequential multilinear products over latent cores, which leads to difficulties in finding the optimal TT representation. In this paper, we introduce a fundamental tensor decomposition model to represent a large dimensional tensor by a circular multilinear products over a sequence of low dimensional cores, which can be graphically interpreted as a cyclic interconnection of 3rd-order tensors, and thus termed as tensor ring (TR) decomposition. The key advantage of TR model is the circular dimensional permutation invariance which is gained by employing the trace operation and treating the latent cores equivalently. TR model can be viewed as a linear combination of TT decompositions, thus obtaining the powerful and generalized representation abilities. For optimization of latent cores, we present four different algorithms based on the sequential SVDs, ALS scheme, and block-wise ALS techniques. Furthermore, the mathematical properties of TR model are investigated, which shows that the basic multilinear algebra can be performed efficiently by using TR representaions and the classical tensor decompositions can be conveniently transformed into the TR representation. Finally, the experiments on both synthetic signals and real-world datasets were conducted to evaluate the performance of different algorithms.
Total Variation Regularized Tensor RPCA for Background Subtraction from Compressive Measurements
Jun 05, 2016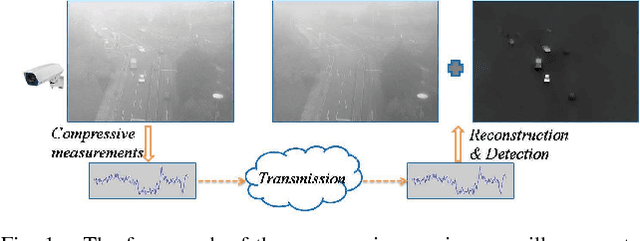


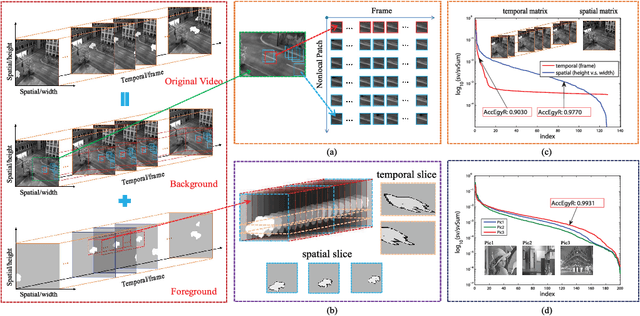
Background subtraction has been a fundamental and widely studied task in video analysis, with a wide range of applications in video surveillance, teleconferencing and 3D modeling. Recently, motivated by compressive imaging, background subtraction from compressive measurements (BSCM) is becoming an active research task in video surveillance. In this paper, we propose a novel tensor-based robust PCA (TenRPCA) approach for BSCM by decomposing video frames into backgrounds with spatial-temporal correlations and foregrounds with spatio-temporal continuity in a tensor framework. In this approach, we use 3D total variation (TV) to enhance the spatio-temporal continuity of foregrounds, and Tucker decomposition to model the spatio-temporal correlations of video background. Based on this idea, we design a basic tensor RPCA model over the video frames, dubbed as the holistic TenRPCA model (H-TenRPCA). To characterize the correlations among the groups of similar 3D patches of video background, we further design a patch-group-based tensor RPCA model (PG-TenRPCA) by joint tensor Tucker decompositions of 3D patch groups for modeling the video background. Efficient algorithms using alternating direction method of multipliers (ADMM) are developed to solve the proposed models. Extensive experiments on simulated and real-world videos demonstrate the superiority of the proposed approaches over the existing state-of-the-art approaches.