 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Object Keypoints for Perception and Control
Jun 19, 2019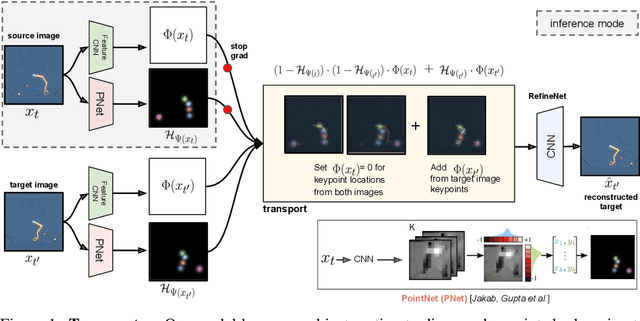


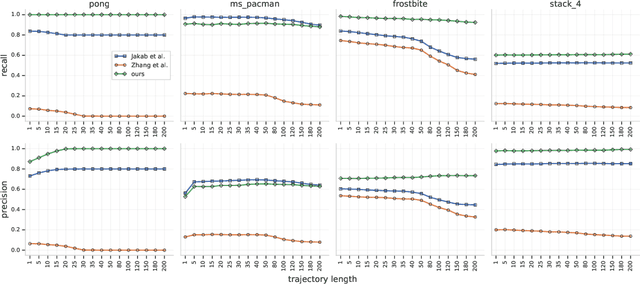
The study of object representations in computer vision has primarily focused on developing representations that are useful for image classification, object detection, or semantic segmentation as downstream tasks. In this work we aim to learn object representations that are useful for control and reinforcement learning (RL). To this end, we introduce Transporter, a neural network architecture for discovering concise geometric object representations in terms of keypoints or image-space coordinates. Our method learns from raw video frames in a fully unsupervised manner, by transporting learnt image features between video frames using a keypoint bottleneck. The discovered keypoints track objects and object parts across long time-horizons more accurately than recent similar methods. Furthermore, consistent long-term tracking enables two notable results in control domains -- (1) using the keypoint co-ordinates and corresponding image features as inputs enables highly sample-efficient reinforcement learning; (2) learning to explore by controlling keypoint locations drastically reduces the search space, enabling deep exploration (leading to states unreachable through random action exploration) without any extrinsic rewards.
Training Neural Networks for and by Interpolation
Jun 13, 2019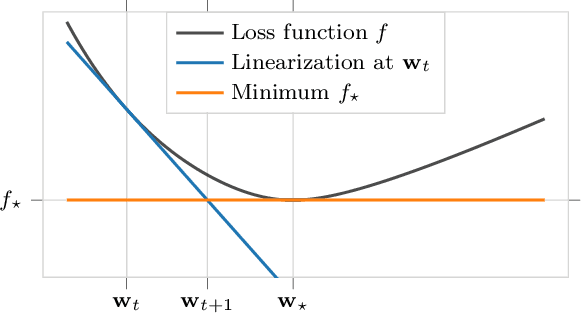
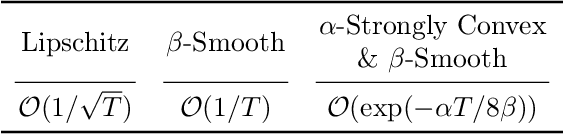
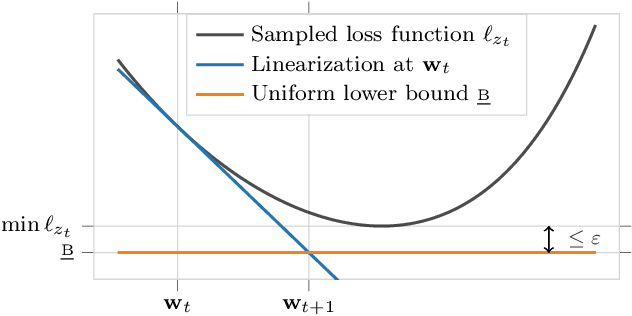

The majority of modern deep learning models are able to interpolate the data: the empirical loss can be driven near zero on all samples simultaneously. In this work, we explicitly exploit this interpolation property for the design of a new optimization algorithm for deep learning. Specifically, we use it to compute an adaptive learning-rate given a stochastic gradient direction. This results in the Adaptive Learning-rates for Interpolation with Gradients (ALI-G) algorithm. ALI-G retains the advantages of SGD, which are low computational cost and provable convergence in the convex setting. But unlike SGD, the learning-rate of ALI-G can be computed inexpensively in closed-form and does not require a manual schedule. We provide a detailed analysis of ALI-G in the stochastic convex setting with explicit convergence rates. In order to obtain good empirical performance in deep learning, we extend the algorithm to use a maximal learning-rate, which gives a single hyper-parameter to tune. We show that employing such a maximal learning-rate has an intuitive proximal interpretation and preserves all convergence guarantees. We provide experiments on a variety of architectures and tasks: (i) learning a differentiable neural computer; (ii) training a wide residual network on the SVHN data set; (iii) training a Bi-LSTM on the SNLI data set; and (iv) training wide residual networks and densely connected networks on the CIFAR data sets. We empirically show that ALI-G outperforms adaptive gradient methods such as Adam, and provides comparable performance with SGD, although SGD benefits from manual learning rate schedules. We release PyTorch and Tensorflow implementations of ALI-G as standalone optimizers that can be used as a drop-in replacement in existing code (code available at https://github.com/oval-group/ali-g ).
LAEO-Net: revisiting people Looking At Each Other in videos
Jun 12, 2019

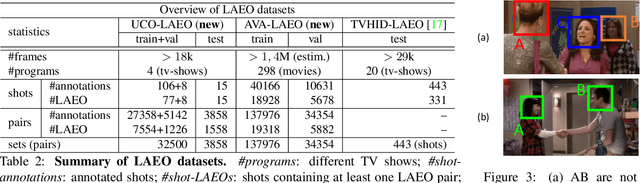
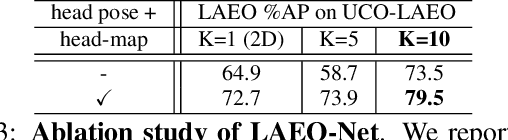
Capturing the `mutual gaze' of people is essential for understanding and interpreting the social interactions between them. To this end, this paper addresses the problem of detecting people Looking At Each Other (LAEO) in video sequences. For this purpose, we propose LAEO-Net, a new deep CNN for determining LAEO in videos. In contrast to previous works, LAEO-Net takes spatio-temporal tracks as input and reasons about the whole track. It consists of three branches, one for each character's tracked head and one for their relative position. Moreover, we introduce two new LAEO datasets: UCO-LAEO and AVA-LAEO. A thorough experimental evaluation demonstrates the ability of LAEONet to successfully determine if two people are LAEO and the temporal window where it happens. Our model achieves state-of-the-art results on the existing TVHID-LAEO video dataset, significantly outperforming previous approaches. Finally, we apply LAEO-Net to social network analysis, where we automatically infer the social relationship between pairs of people based on the frequency and duration that they LAEO.
The VIA Annotation Software for Images, Audio and Video
May 31, 2019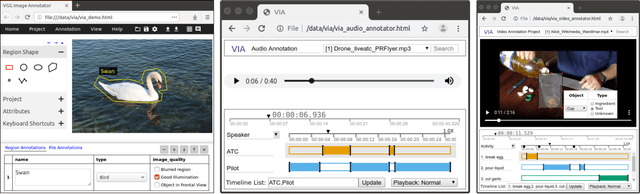
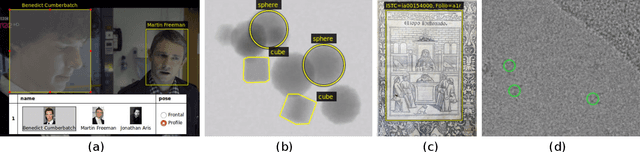
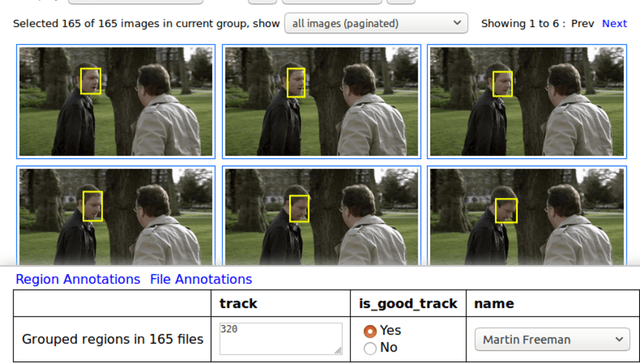
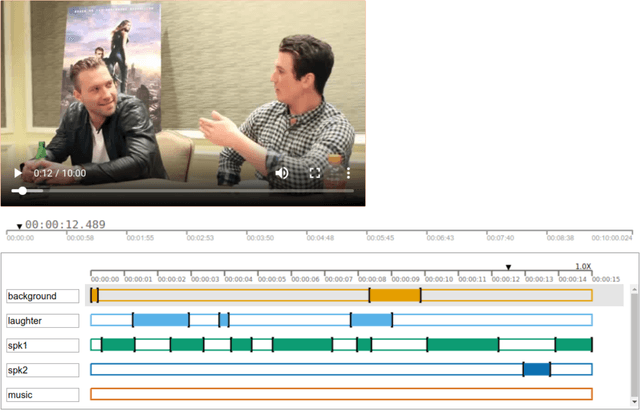
In this paper, we introduce a simple and standalone manual annotation tool for images, audio and video: the VGG Image Annotator (VIA). This is a light weight, standalone and offline software package that does not require any installation or setup and runs solely in a web browser. Due to its lightness and flexibility, the VIA software has quickly become an essential and invaluable research support tool in many academic disciplines. Furthermore, it has also been very popular in several industrial sectors which have invested in adapting this open source software to their requirements. Since its public release in 2017, the VIA software has been used more than 600,000 times and has nurtured a large and thriving open source community.
A Hierarchical Probabilistic U-Net for Modeling Multi-Scale Ambiguities
May 30, 2019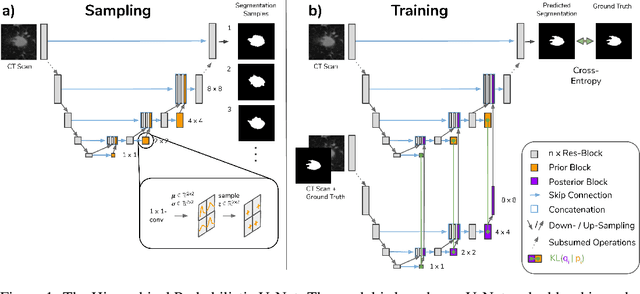
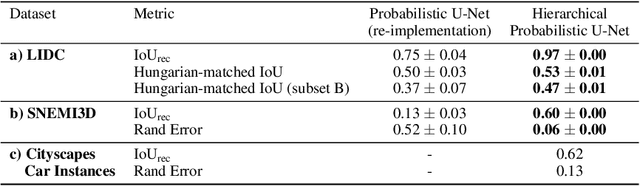
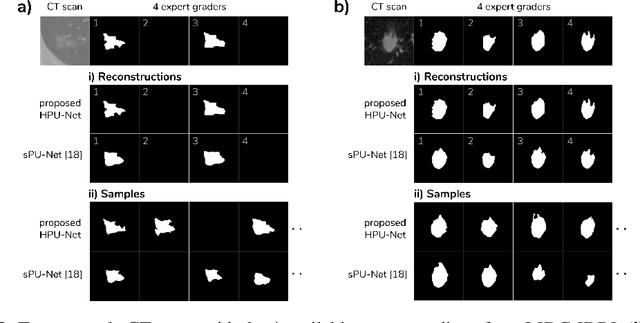

Medical imaging only indirectly measures the molecular identity of the tissue within each voxel, which often produces only ambiguous image evidence for target measures of interest, like semantic segmentation. This diversity and the variations of plausible interpretations are often specific to given image regions and may thus manifest on various scales, spanning all the way from the pixel to the image level. In order to learn a flexible distribution that can account for multiple scales of variations, we propose the Hierarchical Probabilistic U-Net, a segmentation network with a conditional variational auto-encoder (cVAE) that uses a hierarchical latent space decomposition. We show that this model formulation enables sampling and reconstruction of segmenations with high fidelity, i.e. with finely resolved detail, while providing the flexibility to learn complex structured distributions across scales. We demonstrate these abilities on the task of segmenting ambiguous medical scans as well as on instance segmentation of neurobiological and natural images. Our model automatically separates independent factors across scales, an inductive bias that we deem beneficial in structured output prediction tasks beyond segmentation.
Object Discovery with a Copy-Pasting GAN
May 27, 2019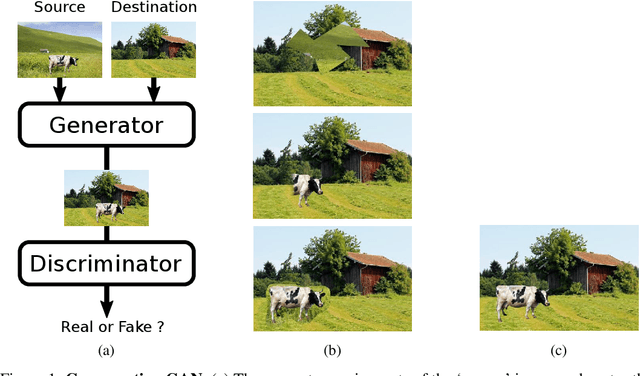
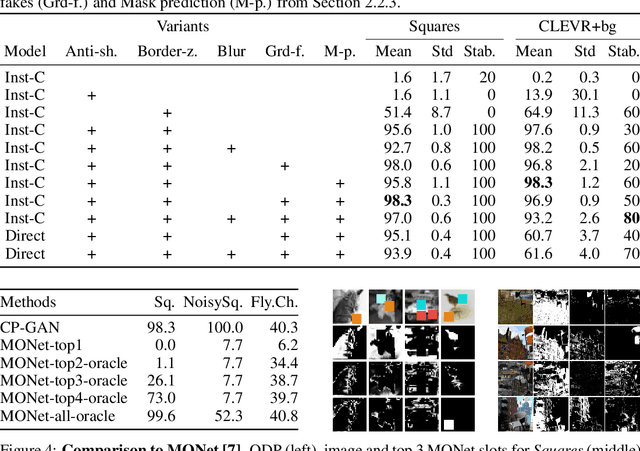
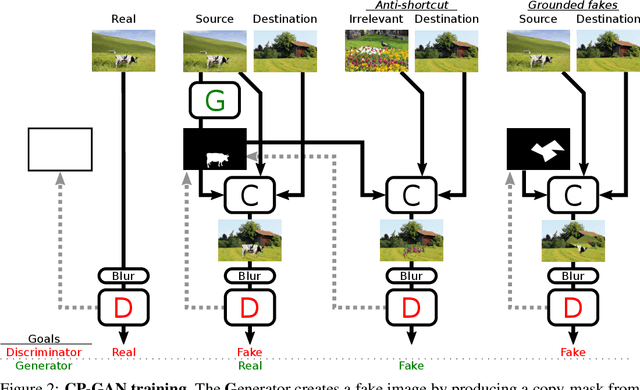

We tackle the problem of object discovery, where objects are segmented for a given input image, and the system is trained without using any direct supervision whatsoever. A novel copy-pasting GAN framework is proposed, where the generator learns to discover an object in one image by compositing it into another image such that the discriminator cannot tell that the resulting image is fake. After carefully addressing subtle issues, such as preventing the generator from `cheating', this game results in the generator learning to select objects, as copy-pasting objects is most likely to fool the discriminator. The system is shown to work well on four very different datasets, including large object appearance variations in challenging cluttered backgrounds.
Semi-Supervised Learning with Scarce Annotations
May 21, 2019

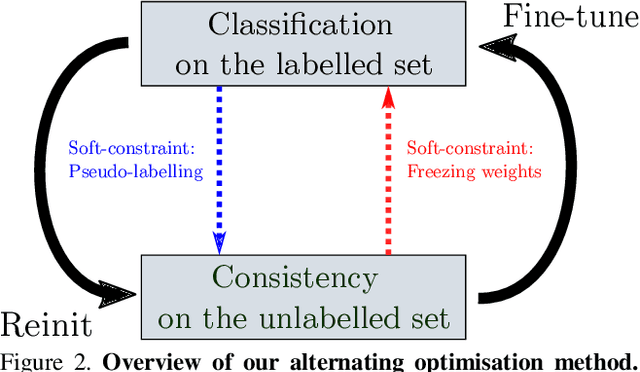

While semi-supervised learning (SSL) algorithms provide an efficient way to make use of both labelled and unlabelled data, they generally struggle when the number of annotated samples is very small. In this work, we consider the problem of SSL multi-class classification with very few labelled instances. We introduce two key ideas. The first is a simple but effective one: we leverage the power of transfer learning among different tasks and self-supervision to initialize a good representation of the data without making use of any label. The second idea is a new algorithm for SSL that can exploit well such a pre-trained representation. The algorithm works by alternating two phases, one fitting the labelled points and one fitting the unlabelled ones, with carefully-controlled information flow between them. The benefits are greatly reducing overfitting of the labelled data and avoiding issue with balancing labelled and unlabelled losses during training. We show empirically that this method can successfully train competitive models with as few as 10 labelled data points per class. More in general, we show that the idea of bootstrapping features using self-supervised learning always improves SSL on standard benchmarks. We show that our algorithm works increasingly well compared to other methods when refining from other tasks or datasets.
Exploiting temporal context for 3D human pose estimation in the wild
May 10, 2019
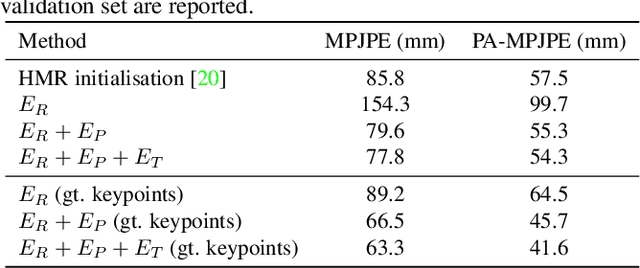
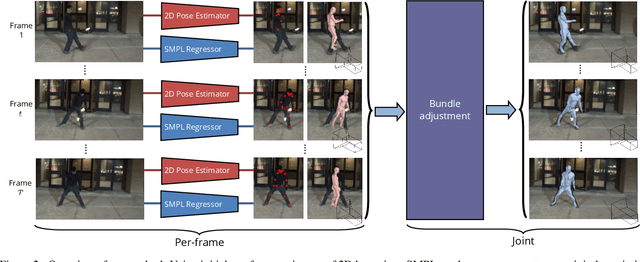
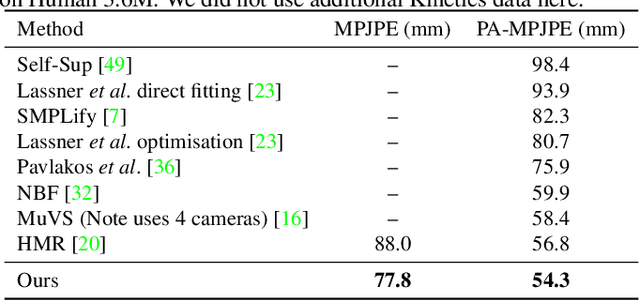
We present a bundle-adjustment-based algorithm for recovering accurate 3D human pose and meshes from monocular videos. Unlike previous algorithms which operate on single frames, we show that reconstructing a person over an entire sequence gives extra constraints that can resolve ambiguities. This is because videos often give multiple views of a person, yet the overall body shape does not change and 3D positions vary slowly. Our method improves not only on standard mocap-based datasets like Human 3.6M -- where we show quantitative improvements -- but also on challenging in-the-wild datasets such as Kinetics. Building upon our algorithm, we present a new dataset of more than 3 million frames of YouTube videos from Kinetics with automatically generated 3D poses and meshes. We show that retraining a single-frame 3D pose estimator on this data improves accuracy on both real-world and mocap data by evaluating on the 3DPW and HumanEVA datasets.
A Geometric Approach to Obtain a Bird's Eye View from an Image
May 06, 2019



The objective of this paper is to rectify any monocular image by computing a homography matrix that transforms it to a bird's eye (overhead) view. We make the following contributions: (i) we show that the homography matrix can be parameterised with only four parameters that specify the horizon line and the vertical vanishing point, or only two if the field of view or focal length is known; (ii) We introduce a novel representation for the geometry of a line or point (which can be at infinity) that is suitable for regression with a convolutional neural network (CNN); (iii) We introduce a large synthetic image dataset with ground truth for the orthogonal vanishing points, that can be used for training a CNN to predict these geometric entities; and finally (iv) We achieve state-of-the-art results on horizon detection, with 74.52% AUC on the Horizon Lines in the Wild dataset. Our method is fast and robust, and can be used to remove perspective distortion from videos in real time.
Temporal Cycle-Consistency Learning
Apr 16, 2019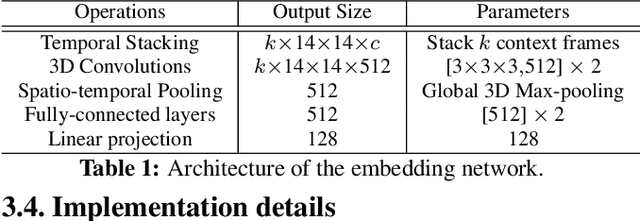
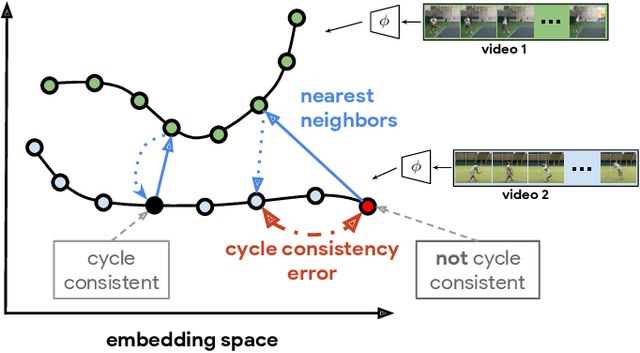

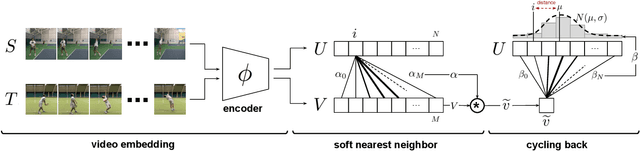
We introduce a self-supervised representation learning method based on the task of temporal alignment between videos. The method trains a network using temporal cycle consistency (TCC), a differentiable cycle-consistency loss that can be used to find correspondences across time in multiple videos. The resulting per-frame embeddings can be used to align videos by simply matching frames using the nearest-neighbors in the learned embedding space. To evaluate the power of the embeddings, we densely label the Pouring and Penn Action video datasets for action phases. We show that (i) the learned embeddings enable few-shot classification of these action phases, significantly reducing the supervised training requirements; and (ii) TCC is complementary to other methods of self-supervised learning in videos, such as Shuffle and Learn and Time-Contrastive Networks. The embeddings are also used for a number of applications based on alignment (dense temporal correspondence) between video pairs, including transfer of metadata of synchronized modalities between videos (sounds, temporal semantic labels), synchronized playback of multiple videos, and anomaly detection. Project webpage: https://sites.google.com/view/temporal-cycle-consistency .