 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modality Gait Recognition: Bridging LiDAR and Camera Modalities for Human Identification
Apr 04, 2024



Current gait recognition research mainly focuses on identifying pedestrians captured by the same type of sensor, neglecting the fact that individuals may be captured by different sensors in order to adapt to various environments. A more practical approach should involve cross-modality matching across different sensors. Hence, this paper focuses on investigating the problem of cross-modality gait recognition, with the objective of accurately identifying pedestrians across diverse vision sensors. We present CrossGait inspired by the feature alignment strategy, capable of cross retrieving diverse data modalities. Specifically, we investigate the cross-modality recognition task by initially extracting features within each modality and subsequently aligning these features across modalities. To further enhance the cross-modality performance, we propose a Prototypical Modality-shared Attention Module that learns modality-shared features from two modality-specific features. Additionally, we design a Cross-modality Feature Adapter that transforms the learned modality-specific features into a unified feature space. Extensive experiments conducted on the SUSTech1K dataset demonstrate the effectiveness of CrossGait: (1) it exhibits promising cross-modality ability in retrieving pedestrians across various modalities from different sensors in diverse scenes, and (2) CrossGait not only learns modality-shared features for cross-modality gait recognition but also maintains modality-specific features for single-modality recognition.
Lightweight Structure-Aware Attention for Visual Understanding
Nov 29, 2022



Vision Transformers (ViTs) have become a dominant paradigm for visual representation learning with self-attention operators. Although these operators provide flexibility to the model with their adjustable attention kernels, they suffer from inherent limitations: (1) the attention kernel is not discriminative enough, resulting in high redundancy of the ViT layers, and (2) the complexity in computation and memory is quadratic in the sequence length. In this paper, we propose a novel attention operator, called lightweight structure-aware attention (LiSA), which has a better representation power with log-linear complexity. Our operator learns structural patterns by using a set of relative position embeddings (RPEs). To achieve log-linear complexity, the RPEs are approximated with fast Fourier transforms. Our experiments and ablation studies demonstrate that ViTs based on the proposed operator outperform self-attention and other existing operators, achieving state-of-the-art results on ImageNet, and competitive results on other visual understanding benchmarks such as COCO and Something-Something-V2. The source code of our approach will be released online.
LAEO-Net++: revisiting people Looking At Each Other in videos
Jan 06, 2021
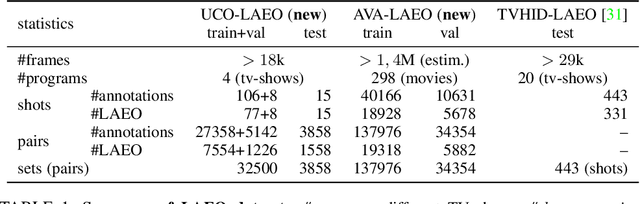
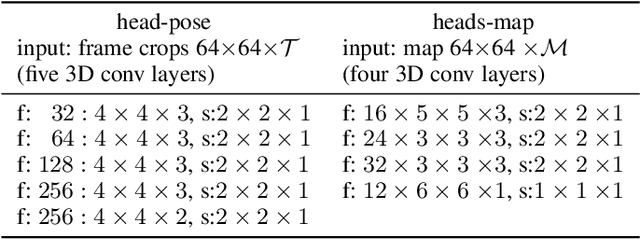
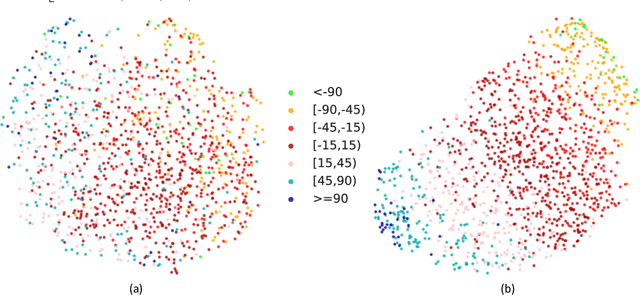
Capturing the 'mutual gaze' of people is essential for understanding and interpreting the social interactions between them. To this end, this paper addresses the problem of detecting people Looking At Each Other (LAEO) in video sequences. For this purpose, we propose LAEO-Net++, a new deep CNN for determining LAEO in videos. In contrast to previous works, LAEO-Net++ takes spatio-temporal tracks as input and reasons about the whole track. It consists of three branches, one for each character's tracked head and one for their relative position. Moreover, we introduce two new LAEO datasets: UCO-LAEO and AVA-LAEO. A thorough experimental evaluation demonstrates the ability of LAEO-Net++ to successfully determine if two people are LAEO and the temporal window where it happens. Our model achieves state-of-the-art results on the existing TVHID-LAEO video dataset, significantly outperforming previous approaches. Finally, we apply LAEO-Net++ to a social network, where we automatically infer the social relationship between pairs of people based on the frequency and duration that they LAEO, and show that LAEO can be a useful tool for guided search of human interactions in videos. The code is available at https://github.com/AVAuco/laeonetplus.
* 16 pages, 16 Figures. arXiv admin note: substantial text overlap with arXiv:1906.05261
iLGaCo: Incremental Learning of Gait Covariate Factors
Aug 31, 2020
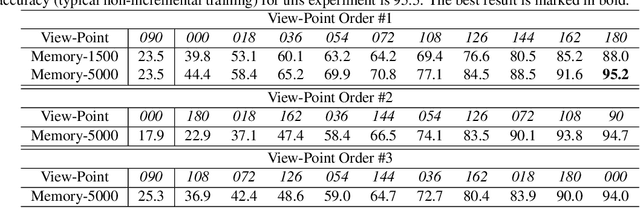
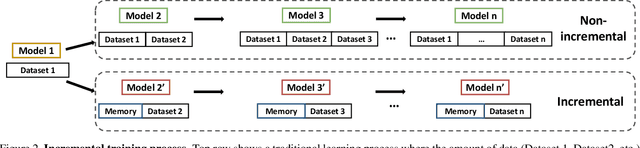
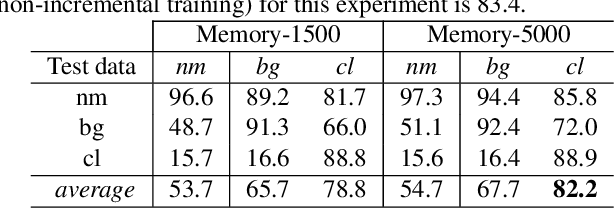
Gait is a popular biometric pattern used for identifying people based on their way of walking. Traditionally, gait recognition approaches based on deep learning are trained using the whole training dataset. In fact, if new data (classes, view-points, walking conditions, etc.) need to be included, it is necessary to re-train again the model with old and new data samples. In this paper, we propose iLGaCo, the first incremental learning approach of covariate factors for gait recognition, where the deep model can be updated with new information without re-training it from scratch by using the whole dataset. Instead, our approach performs a shorter training process with the new data and a small subset of previous samples. This way, our model learns new information while retaining previous knowledge. We evaluate iLGaCo on CASIA-B dataset in two incremental ways: adding new view-points and adding new walking conditions. In both cases, our results are close to the classical `training-from-scratch' approach, obtaining a marginal drop in accuracy ranging from 0.2% to 1.2%, what shows the efficacy of our approach. In addition, the comparison of iLGaCo with other incremental learning methods, such as LwF and iCarl, shows a significant improvement in accuracy, between 6% and 15% depending on the experiment.
LAEO-Net: revisiting people Looking At Each Other in videos
Jun 12, 2019

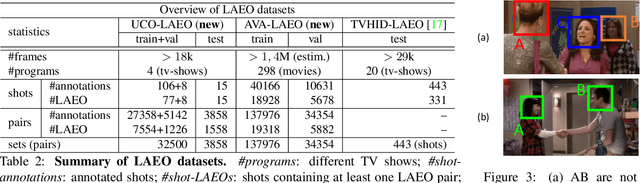
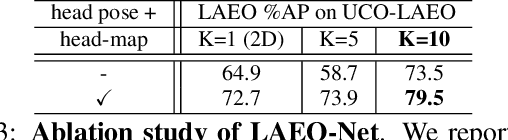
Capturing the `mutual gaze' of people is essential for understanding and interpreting the social interactions between them. To this end, this paper addresses the problem of detecting people Looking At Each Other (LAEO) in video sequences. For this purpose, we propose LAEO-Net, a new deep CNN for determining LAEO in videos. In contrast to previous works, LAEO-Net takes spatio-temporal tracks as input and reasons about the whole track. It consists of three branches, one for each character's tracked head and one for their relative position. Moreover, we introduce two new LAEO datasets: UCO-LAEO and AVA-LAEO. A thorough experimental evaluation demonstrates the ability of LAEONet to successfully determine if two people are LAEO and the temporal window where it happens. Our model achieves state-of-the-art results on the existing TVHID-LAEO video dataset, significantly outperforming previous approaches. Finally, we apply LAEO-Net to social network analysis, where we automatically infer the social relationship between pairs of people based on the frequency and duration that they LAEO.
3D human pose estimation from depth maps using a deep combination of poses
Jul 14, 2018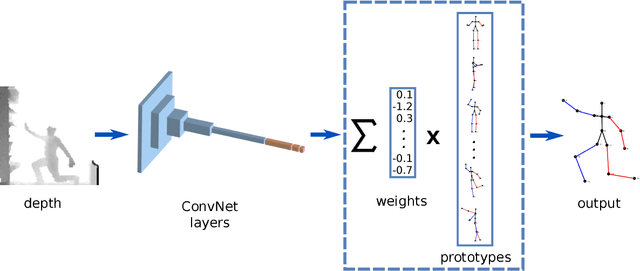


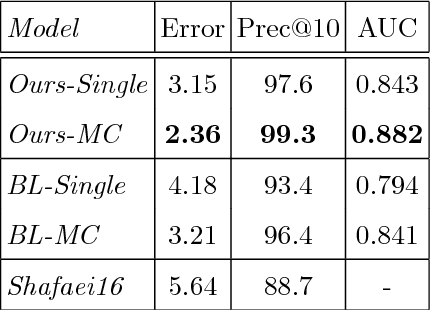
Many real-world applications require the estimation of human body joints for higher-level tasks as, for example, human behaviour understanding. In recent years, depth sensors have become a popular approach to obtain three-dimensional information. The depth maps generated by these sensors provide information that can be employed to disambiguate the poses observed in two-dimensional images. This work addresses the problem of 3D human pose estimation from depth maps employing a Deep Learning approach. We propose a model, named Deep Depth Pose (DDP), which receives a depth map containing a person and a set of predefined 3D prototype poses and returns the 3D position of the body joints of the person. In particular, DDP is defined as a ConvNet that computes the specific weights needed to linearly combine the prototypes for the given input. We have thoroughly evaluated DDP on the challenging 'ITOP' and 'UBC3V' datasets, which respectively depict realistic and synthetic samples, defining a new state-of-the-art on them.