 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing wake words: Audio-visual Keyword Spotting
Sep 02, 2020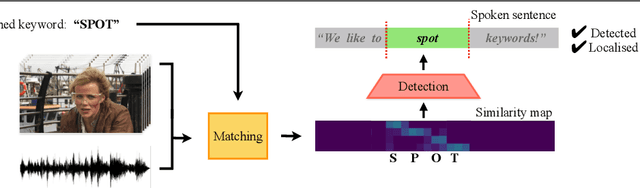
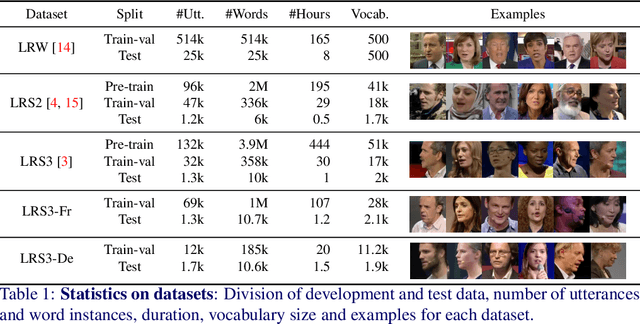
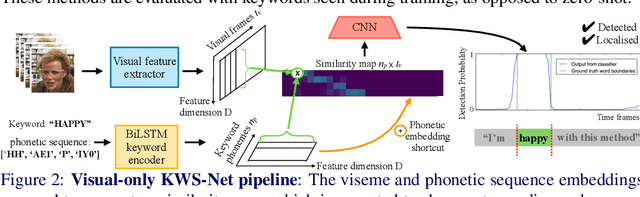
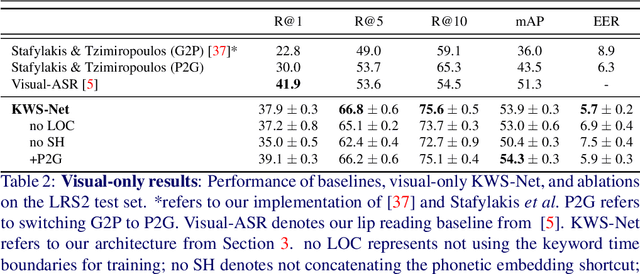
The goal of this work is to automatically determine whether and when a word of interest is spoken by a talking face, with or without the audio. We propose a zero-shot method suitable for in the wild videos. Our key contributions are: (1) a novel convolutional architecture, KWS-Net, that uses a similarity map intermediate representation to separate the task into (i) sequence matching, and (ii) pattern detection, to decide whether the word is there and when; (2) we demonstrate that if audio is available, visual keyword spotting improves the performance both for a clean and noisy audio signal. Finally, (3) we show that our method generalises to other languages, specifically French and German, and achieves a comparable performance to English with less language specific data, by fine-tuning the network pre-trained on English. The method exceeds the performance of the previous state-of-the-art visual keyword spotting architecture when trained and tested on the same benchmark, and also that of a state-of-the-art lip reading method.
Inducing Predictive Uncertainty Estimation for Face Recognition
Sep 01, 2020
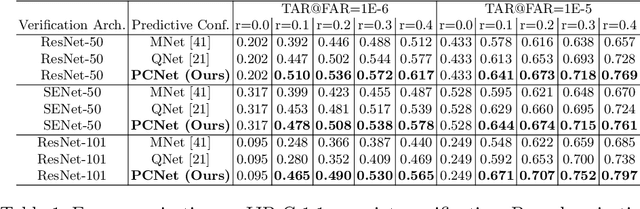

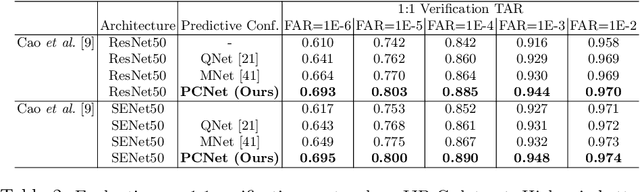
Knowing when an output can be trusted is critical for reliably using face recognition systems. While there has been enormous effort in recent research on improving face verification performance, understanding when a model's predictions should or should not be trusted has received far less attention. Our goal is to assign a confidence score for a face image that reflects its quality in terms of recognizable information. To this end, we propose a method for generating image quality training data automatically from 'mated-pairs' of face images, and use the generated data to train a lightweight Predictive Confidence Network, termed as PCNet, for estimating the confidence score of a face image. We systematically evaluate the usefulness of PCNet with its error versus reject performance, and demonstrate that it can be universally paired with and improve the robustness of any verification model. We describe three use cases on the public IJB-C face verification benchmark: (i) to improve 1:1 image-based verification error rates by rejecting low-quality face images; (ii) to improve quality score based fusion performance on the 1:1 set-based verification benchmark; and (iii) its use as a quality measure for selecting high quality (unblurred, good lighting, more frontal) faces from a collection, e.g. for automatic enrolment or display.
Self-Supervised Learning of Audio-Visual Objects from Video
Aug 10, 2020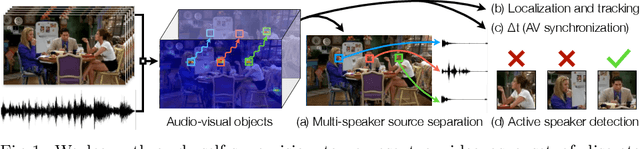
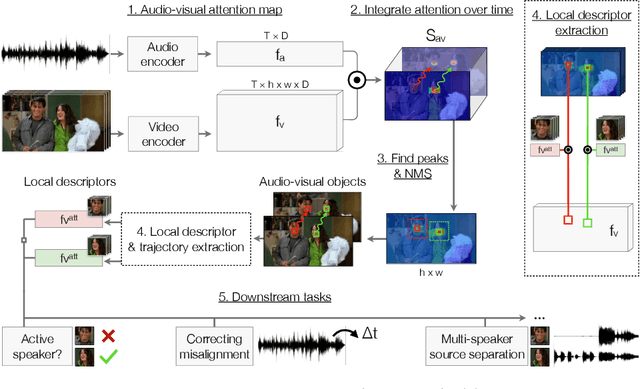
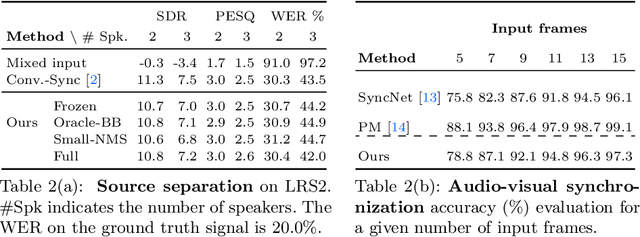
Our objective is to transform a video into a set of discrete audio-visual objects using self-supervised learning. To this end, we introduce a model that uses attention to localize and group sound sources, and optical flow to aggregate information over time. We demonstrate the effectiveness of the audio-visual object embeddings that our model learns by using them for four downstream speech-oriented tasks: (a) multi-speaker sound source separation, (b) localizing and tracking speakers, (c) correcting misaligned audio-visual data, and (d) active speaker detection. Using our representation, these tasks can be solved entirely by training on unlabeled video, without the aid of object detectors. We also demonstrate the generality of our method by applying it to non-human speakers, including cartoons and puppets.Our model significantly outperforms other self-supervised approaches, and obtains performance competitive with methods that use supervised face detection.
Memory-augmented Dense Predictive Coding for Video Representation Learning
Aug 03, 2020
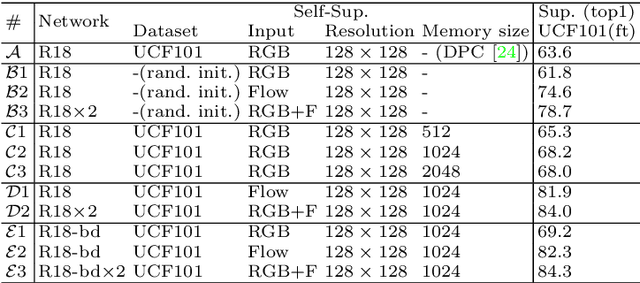
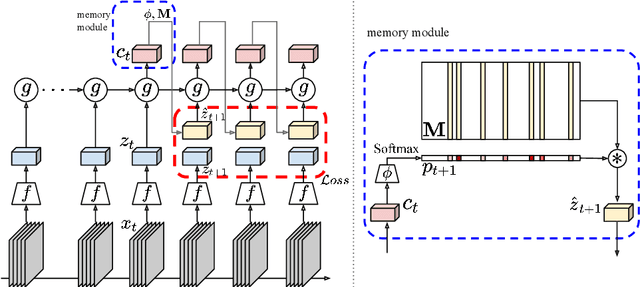
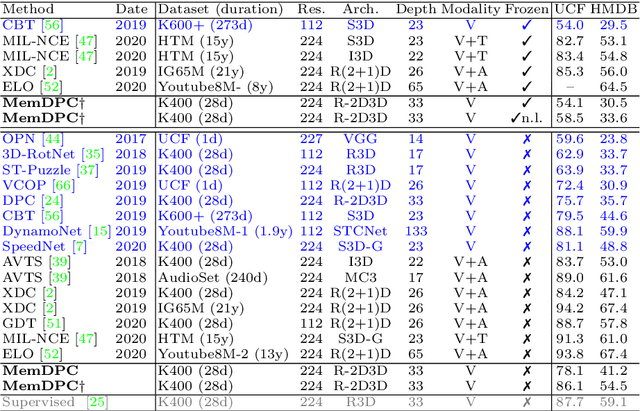
The objective of this paper is self-supervised learning from video, in particular for representations for action recognition. We make the following contributions: (i) We propose a new architecture and learning framework Memory-augmented Dense Predictive Coding (MemDPC) for the task. It is trained with a predictive attention mechanism over the set of compressed memories, such that any future states can always be constructed by a convex combination of the condense representations, allowing to make multiple hypotheses efficiently. (ii) We investigate visual-only self-supervised video representation learning from RGB frames, or from unsupervised optical flow, or both. (iii) We thoroughly evaluate the quality of learnt representation on four different downstream tasks: action recognition, video retrieval, learning with scarce annotations, and unintentional action classification. In all cases, we demonstrate state-of-the-art or comparable performance over other approaches with orders of magnitude fewer training data.
RareAct: A video dataset of unusual interactions
Aug 03, 2020


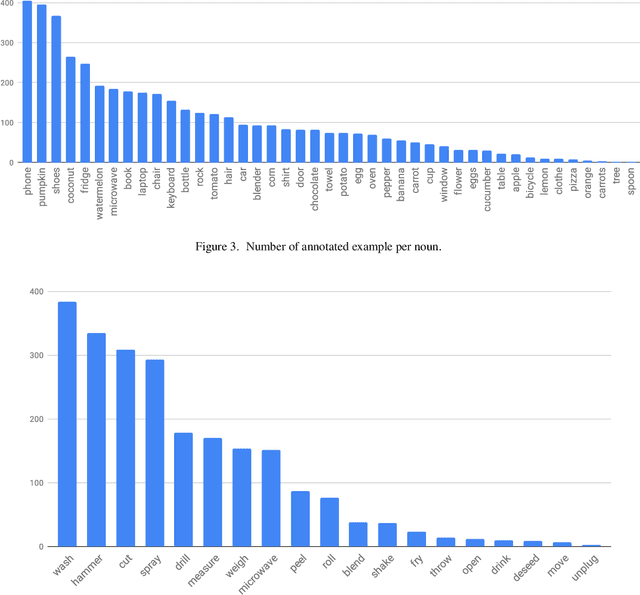
This paper introduces a manually annotated video dataset of unusual actions, namely RareAct, including actions such as "blend phone", "cut keyboard" and "microwave shoes". RareAct aims at evaluating the zero-shot and few-shot compositionality of action recognition models for unlikely compositions of common action verbs and object nouns. It contains 122 different actions which were obtained by combining verbs and nouns rarely co-occurring together in the large-scale textual corpus from HowTo100M, but that frequently appear separately. We provide benchmarks using a state-of-the-art HowTo100M pretrained video and text model and show that zero-shot and few-shot compositionality of actions remains a challenging and unsolved task.
The End-of-End-to-End: A Video Understanding Pentathlon Challenge
Aug 03, 2020
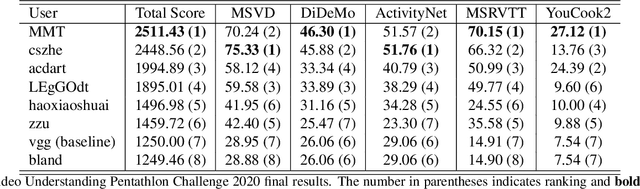
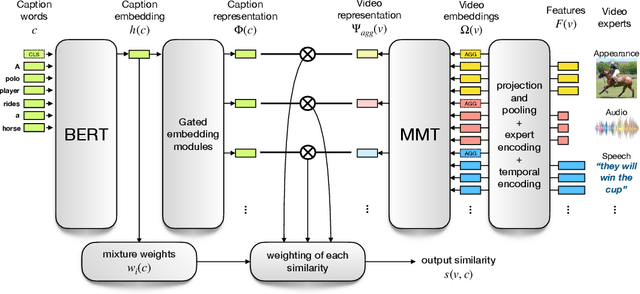
We present a new video understanding pentathlon challenge, an open competition held in conjunction with the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020. The objective of the challenge was to explore and evaluate new methods for text-to-video retrieval-the task of searching for content within a corpus of videos using natural language queries. This report summarizes the results of the first edition of the challenge together with the findings of the participants.
Smooth-AP: Smoothing the Path Towards Large-Scale Image Retrieval
Jul 23, 2020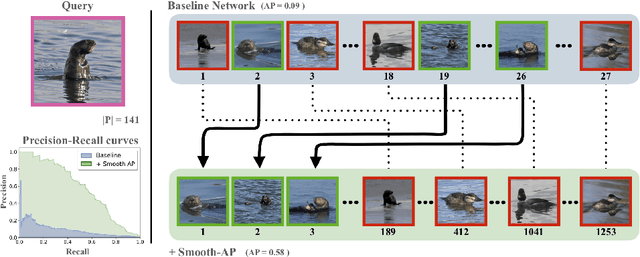
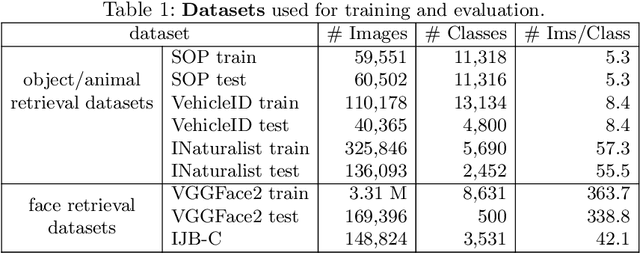

Optimising a ranking-based metric, such as Average Precision (AP), is notoriously challenging due to the fact that it is non-differentiable, and hence cannot be optimised directly using gradient-descent methods. To this end, we introduce an objective that optimises instead a smoothed approximation of AP, coined Smooth-AP. Smooth-AP is a plug-and-play objective function that allows for end-to-end training of deep networks with a simple and elegant implementation. We also present an analysis for why directly optimising the ranking based metric of AP offers benefits over other deep metric learning losses. We apply Smooth-AP to standard retrieval benchmarks: Stanford Online products and VehicleID, and also evaluate on larger-scale datasets: INaturalist for fine-grained category retrieval, and VGGFace2 and IJB-C for face retrieval. In all cases, we improve the performance over the state-of-the-art, especially for larger-scale datasets, thus demonstrating the effectiveness and scalability of Smooth-AP to real-world scenarios.
BSL-1K: Scaling up co-articulated sign language recognition using mouthing cues
Jul 23, 2020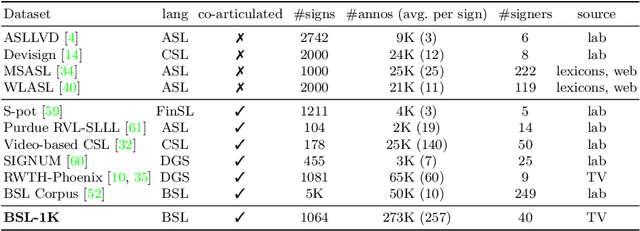

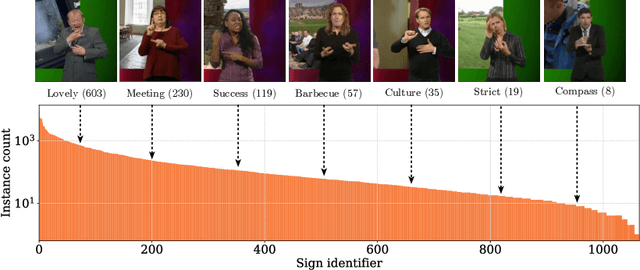

Recent progress in fine-grained gesture and action classification, and machine translation, point to the possibility of automated sign language recognition becoming a reality. A key stumbling block in making progress towards this goal is a lack of appropriate training data, stemming from the high complexity of sign annotation and a limited supply of qualified annotators. In this work, we introduce a new scalable approach to data collection for sign recognition in continuous videos. We make use of weakly-aligned subtitles for broadcast footage together with a keyword spotting method to automatically localise sign-instances for a vocabulary of 1,000 signs in 1,000 hours of video. We make the following contributions: (1) We show how to use mouthing cues from signers to obtain high-quality annotations from video data - the result is the BSL-1K dataset, a collection of British Sign Language (BSL) signs of unprecedented scale; (2) We show that we can use BSL-1K to train strong sign recognition models for co-articulated signs in BSL and that these models additionally form excellent pretraining for other sign languages and benchmarks - we exceed the state of the art on both the MSASL and WLASL benchmarks. Finally, (3) we propose new large-scale evaluation sets for the tasks of sign recognition and sign spotting and provide baselines which we hope will serve to stimulate research in this area.
CrossTransformers: spatially-aware few-shot transfer
Jul 23, 2020
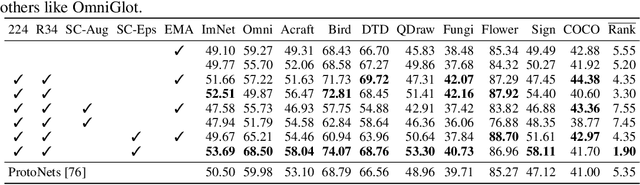
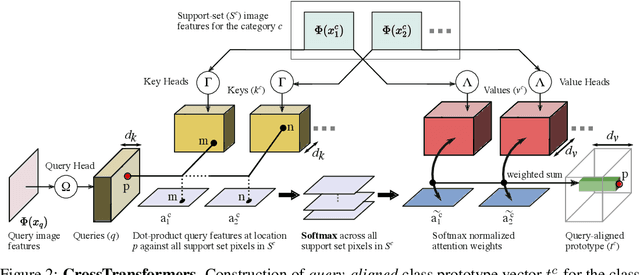
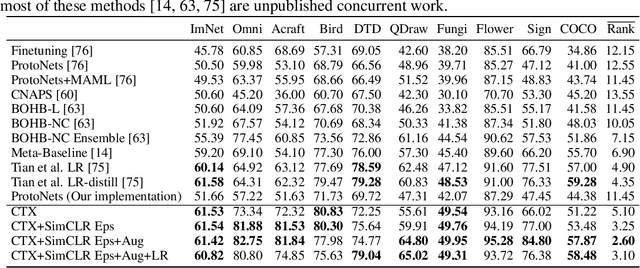
Given new tasks with very little data--such as new classes in a classification problem or a domain shift in the input--performance of modern vision systems degrades remarkably quickly. In this work, we illustrate how the neural network representations which underpin modern vision systems are subject to supervision collapse, whereby they lose any information that is not necessary for performing the training task, including information that may be necessary for transfer to new tasks or domains. We then propose two methods to mitigate this problem. First, we employ self-supervised learning to encourage general-purpose features that transfer better. Second, we propose a novel Transformer based neural network architecture called CrossTransformers, which can take a small number of labeled images and an unlabeled query, find coarse spatial correspondence between the query and the labeled images, and then infer class membership by computing distances between spatially-corresponding features. The result is a classifier that is more robust to task and domain shift, which we demonstrate via state-of-the-art performance on Meta-Dataset, a recent dataset for evaluating transfer from ImageNet to many other vision datasets.
D2D: Learning to find good correspondences for image matching and manipulation
Jul 16, 2020
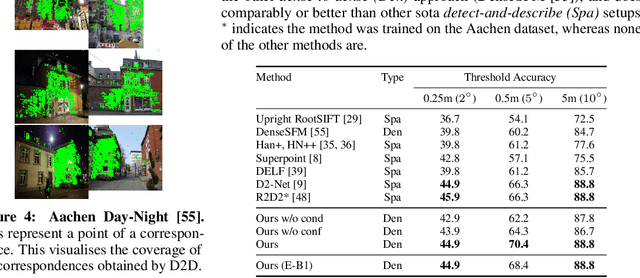
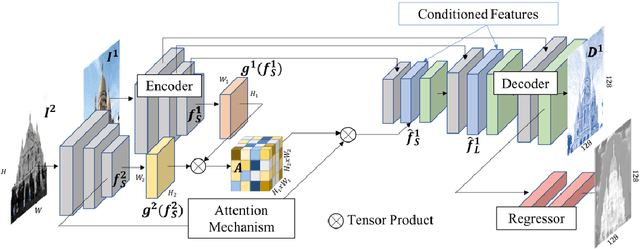
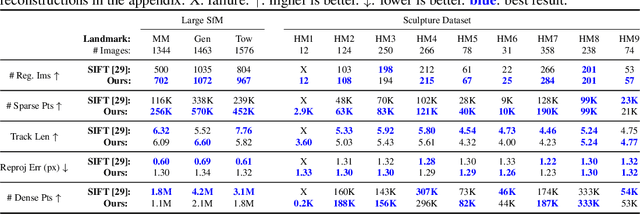
We propose a new approach to determining correspondences between image pairs under large changes in illumination, viewpoint, context, and material. While most approaches seek to extract a set of reliably detectable regions in each image which are then compared (sparse-to-sparse) using increasingly complicated or specialized pipelines, we propose a simple approach for matching all points between the images (dense-to-dense) and subsequently selecting the best matches. The two key parts of our approach are: (i) to condition the learned features on both images, and (ii) to learn a distinctiveness score which is used to choose the best matches at test time. We demonstrate that our model can be used to achieve state of the art or competitive results on a wide range of tasks: local matching, camera localization, 3D reconstruction, and image stylization.