 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Gaze to Guidance: Interpreting and Adapting to Users' Cognitive Needs with Multimodal Gaze-Aware AI Assistants
Apr 09, 2026Current LLM assistants are powerful at answering questions, but they have limited access to the behavioral context that reveals when and where a user is struggling. We present a gaze-grounded multimodal LLM assistant that uses egocentric video with gaze overlays to identify likely points of difficulty and target follow-up retrospective assistance. We instantiate this vision in a controlled study (n=36) comparing the gaze-aware AI assistant to a text-only LLM assistant. Compared to a conventional LLM assistant, the gaze-aware assistant was rated as significantly more accurate and personalized in its assessments of users' reading behavior and significantly improved people's ability to recall information. Users spoke significantly fewer words with the gaze-aware assistant, indicating more efficient interactions. Qualitative results underscored both perceived benefits in comprehension and challenges when interpretations of gaze behaviors were inaccurate. Our findings suggest that gaze-aware LLM assistants can reason about cognitive needs to improve cognitive outcomes of users.
Reliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
Uncertainty Calibration in Bayesian Neural Networks via Distance-Aware Priors
Jul 17, 2022
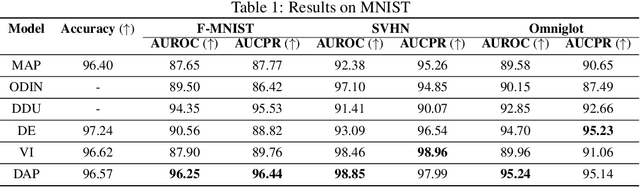
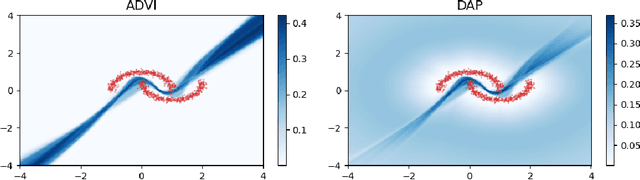
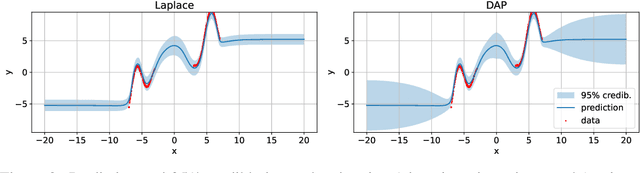
As we move away from the data, the predictive uncertainty should increase, since a great variety of explanations are consistent with the little available information. We introduce Distance-Aware Prior (DAP) calibration, a method to correct overconfidence of Bayesian deep learning models outside of the training domain. We define DAPs as prior distributions over the model parameters that depend on the inputs through a measure of their distance from the training set. DAP calibration is agnostic to the posterior inference method, and it can be performed as a post-processing step. We demonstrate its effectiveness against several baselines in a variety of classification and regression problems, including benchmarks designed to test the quality of predictive distributions away from the data.
Scalable Gaussian Processes for Characterizing Multidimensional Change Surfaces
Nov 13, 2015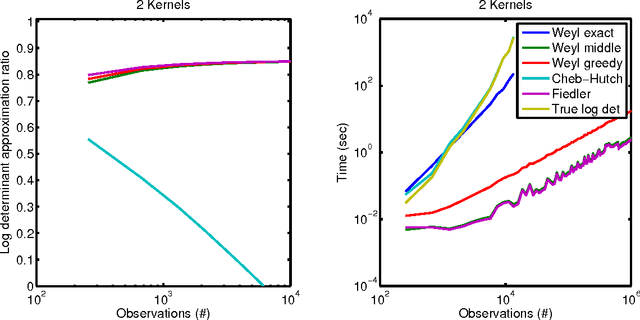
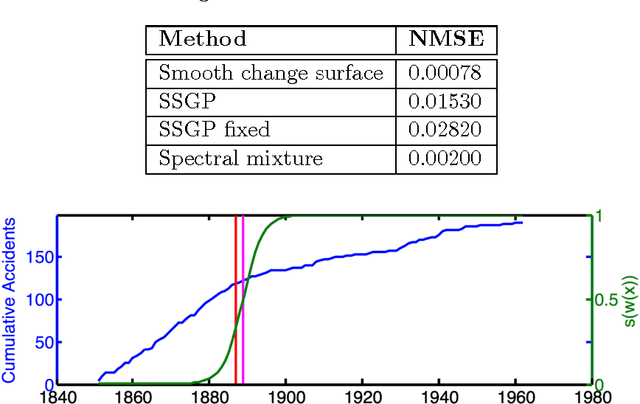
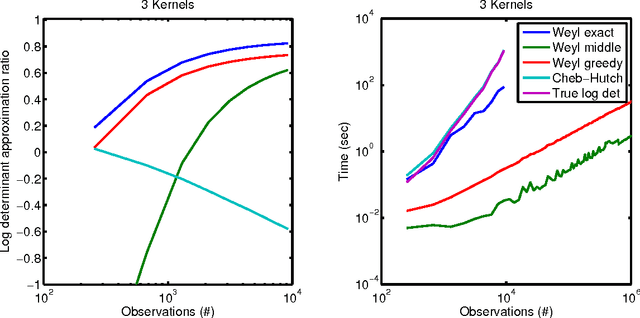
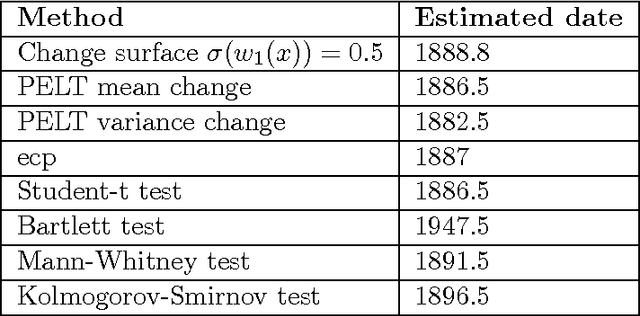
We present a scalable Gaussian process model for identifying and characterizing smooth multidimensional changepoints, and automatically learning changes in expressive covariance structure. We use Random Kitchen Sink features to flexibly define a change surface in combination with expressive spectral mixture kernels to capture the complex statistical structure. Finally, through the use of novel methods for additive non-separable kernels, we can scale the model to large datasets. We demonstrate the model on numerical and real world data, including a large spatio-temporal disease dataset where we identify previously unknown heterogeneous changes in space and time.