 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Information Extraction: A Review of Baseline Techniques, Approaches, and Applications
Oct 18, 2023



With the abundant amount of available online and offline text data, there arises a crucial need to extract the relation between phrases and summarize the main content of each document in a few words. For this purpose, there have been many studies recently in Open Information Extraction (OIE). OIE improves upon relation extraction techniques by analyzing relations across different domains and avoids requiring hand-labeling pre-specified relations in sentences. This paper surveys recent approaches of OIE and its applications on Knowledge Graph (KG), text summarization, and Question Answering (QA). Moreover, the paper describes OIE basis methods in relation extraction. It briefly discusses the main approaches and the pros and cons of each method. Finally, it gives an overview about challenges, open issues, and future work opportunities for OIE, relation extraction, and OIE applications.
FuNToM: Functional Modeling of RF Circuits Using a Neural Network Assisted Two-Port Analysis Method
Aug 03, 2023



Automatic synthesis of analog and Radio Frequency (RF) circuits is a trending approach that requires an efficient circuit modeling method. This is due to the expensive cost of running a large number of simulations at each synthesis cycle. Artificial intelligence methods are promising approaches for circuit modeling due to their speed and relative accuracy. However, existing approaches require a large amount of training data, which is still collected using simulation runs. In addition, such approaches collect a whole separate dataset for each circuit topology even if a single element is added or removed. These matters are only exacerbated by the need for post-layout modeling simulations, which take even longer. To alleviate these drawbacks, in this paper, we present FuNToM, a functional modeling method for RF circuits. FuNToM leverages the two-port analysis method for modeling multiple topologies using a single main dataset and multiple small datasets. It also leverages neural networks which have shown promising results in predicting the behavior of circuits. Our results show that for multiple RF circuits, in comparison to the state-of-the-art works, while maintaining the same accuracy, the required training data is reduced by 2.8x - 10.9x. In addition, FuNToM needs 176.8x - 188.6x less time for collecting the training set in post-layout modeling.
MTrainS: Improving DLRM training efficiency using heterogeneous memories
Apr 19, 2023



Recommendation models are very large, requiring terabytes (TB) of memory during training. In pursuit of better quality, the model size and complexity grow over time, which requires additional training data to avoid overfitting. This model growth demands a large number of resources in data centers. Hence, training efficiency is becoming considerably more important to keep the data center power demand manageable. In Deep Learning Recommendation Models (DLRM), sparse features capturing categorical inputs through embedding tables are the major contributors to model size and require high memory bandwidth. In this paper, we study the bandwidth requirement and locality of embedding tables in real-world deployed models. We observe that the bandwidth requirement is not uniform across different tables and that embedding tables show high temporal locality. We then design MTrainS, which leverages heterogeneous memory, including byte and block addressable Storage Class Memory for DLRM hierarchically. MTrainS allows for higher memory capacity per node and increases training efficiency by lowering the need to scale out to multiple hosts in memory capacity bound use cases. By optimizing the platform memory hierarchy, we reduce the number of nodes for training by 4-8X, saving power and cost of training while meeting our target training performance.
Tablext: A Combined Neural Network And Heuristic Based Table Extractor
Apr 22, 2021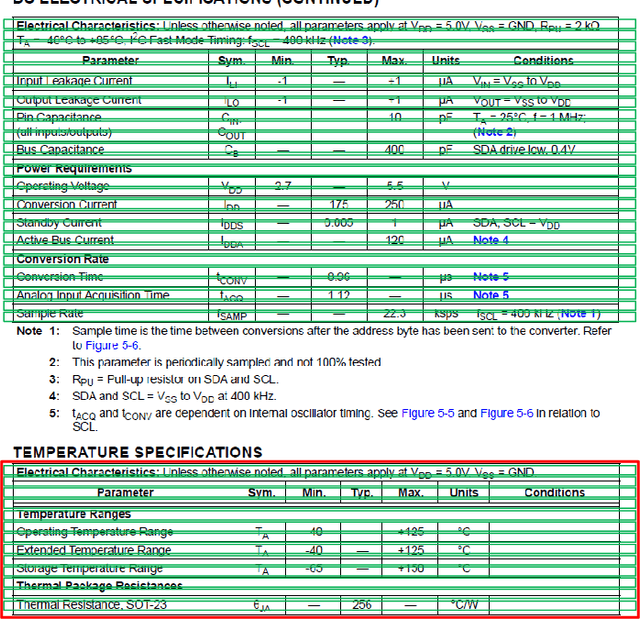
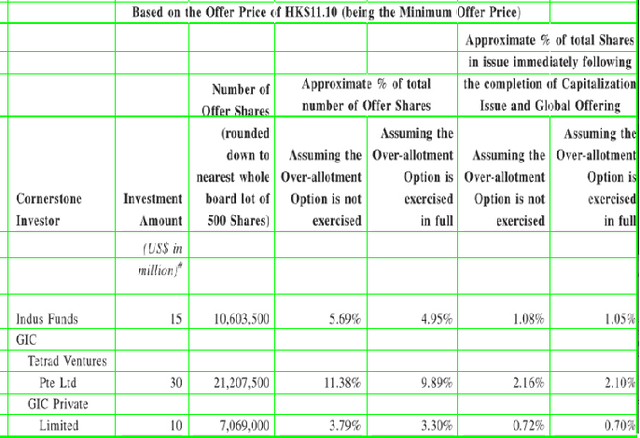
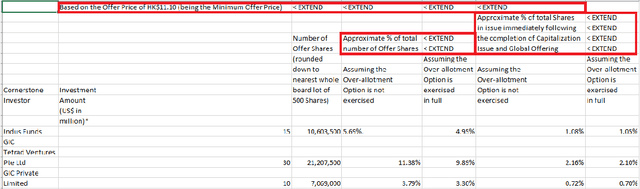
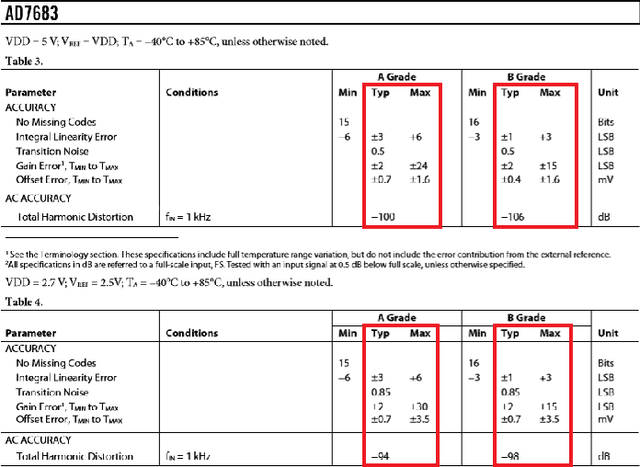
A significant portion of the data available today is found within tables. Therefore, it is necessary to use automated table extraction to obtain thorough results when data-mining. Today's popular state-of-the-art methods for table extraction struggle to adequately extract tables with machine-readable text and structural data. To make matters worse, many tables do not have machine-readable data, such as tables saved as images, making most extraction methods completely ineffective. In order to address these issues, a novel, general format table extractor tool, Tablext, is proposed. This tool uses a combination of computer vision techniques and machine learning methods to efficiently and effectively identify and extract data from tables. Tablext begins by using a custom Convolutional Neural Network (CNN) to identify and separate all potential tables. The identification process is optimized by combining the custom CNN with the YOLO object detection network. Then, the high-level structure of each table is identified with computer vision methods. This high-level, structural meta-data is used by another CNN to identify exact cell locations. As a final step, Optical Characters Recognition (OCR) is performed on every individual cell to extract their content without needing machine-readable text. This multi-stage algorithm allows for the neural networks to focus on completing complex tasks, while letting image processing methods efficiently complete the simpler ones. This leads to the proposed approach to be general-purpose enough to handle a large batch of tables regardless of their internal encodings or their layout complexity. Additionally, it becomes accurate enough to outperform competing state-of-the-art table extractors on the ICDAR 2013 table dataset.