 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022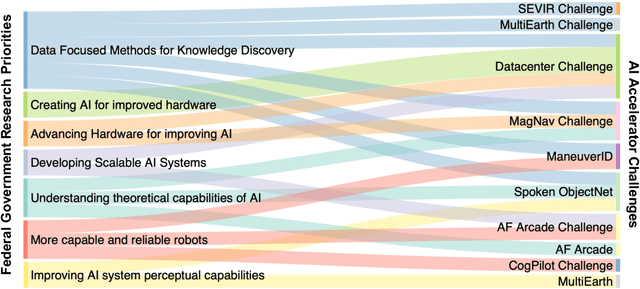

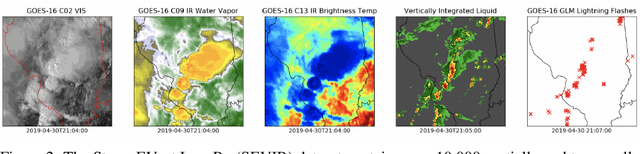
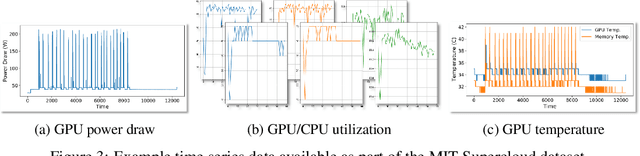
Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
On the use of Cortical Magnification and Saccades as Biological Proxies for Data Augmentation
Dec 14, 2021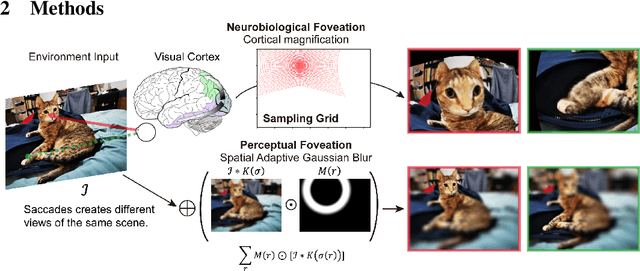
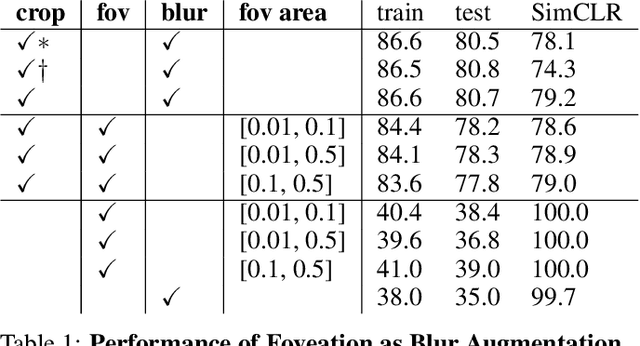
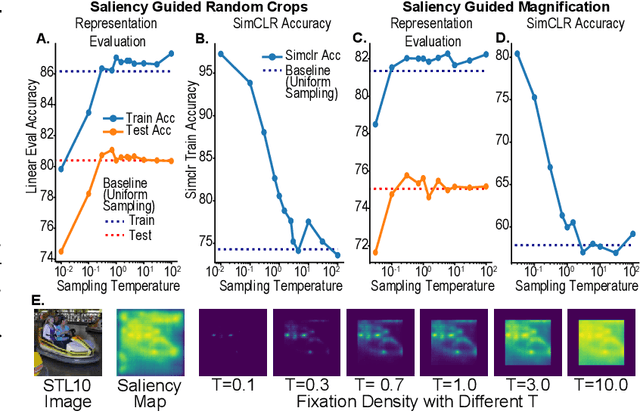
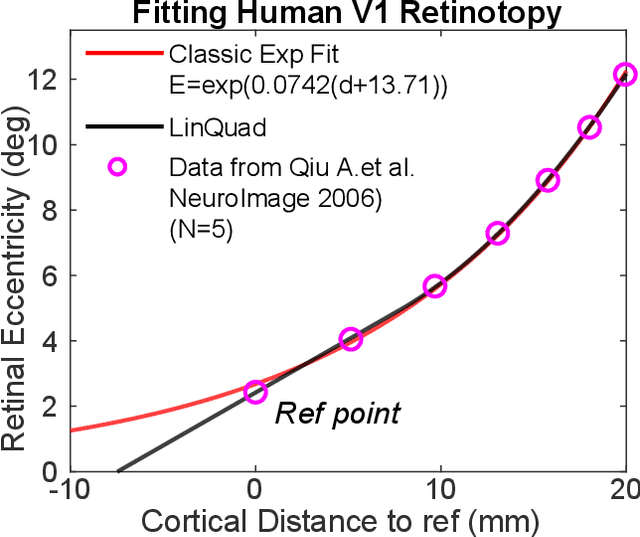
Self-supervised learning is a powerful way to learn useful representations from natural data. It has also been suggested as one possible means of building visual representation in humans, but the specific objective and algorithm are unknown. Currently, most self-supervised methods encourage the system to learn an invariant representation of different transformations of the same image in contrast to those of other images. However, such transformations are generally non-biologically plausible, and often consist of contrived perceptual schemes such as random cropping and color jittering. In this paper, we attempt to reverse-engineer these augmentations to be more biologically or perceptually plausible while still conferring the same benefits for encouraging robust representation. Critically, we find that random cropping can be substituted by cortical magnification, and saccade-like sampling of the image could also assist the representation learning. The feasibility of these transformations suggests a potential way that biological visual systems could implement self-supervision. Further, they break the widely accepted spatially-uniform processing assumption used in many computer vision algorithms, suggesting a role for spatially-adaptive computation in humans and machines alike. Our code and demo can be found here.
Incorporating Rich Social Interactions Into MDPs
Oct 22, 2021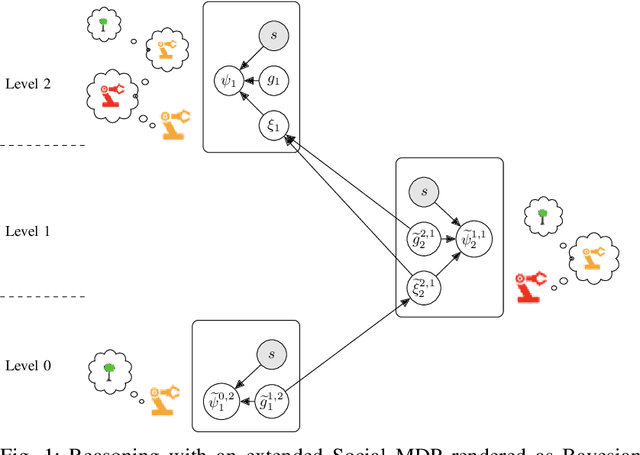
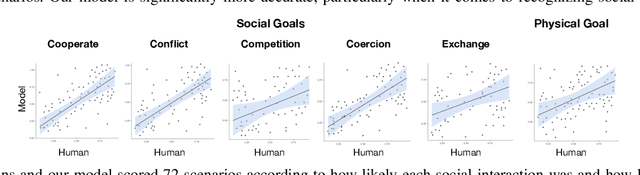
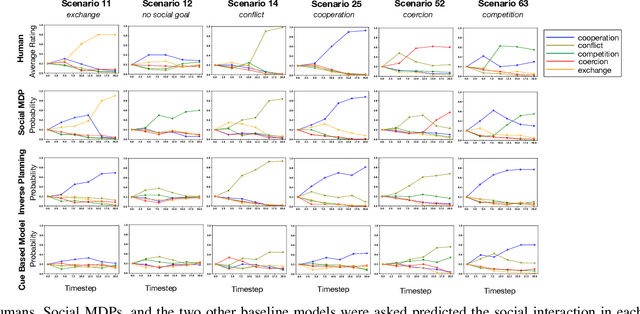

Much of what we do as humans is engage socially with other agents, a skill that robots must also eventually possess. We demonstrate that a rich theory of social interactions originating from microsociology and economics can be formalized by extending a nested MDP where agents reason about arbitrary functions of each other's hidden rewards. This extended Social MDP allows us to encode the five basic interactions that underlie microsociology: cooperation, conflict, coercion, competition, and exchange. The result is a robotic agent capable of executing social interactions zero-shot in new environments; like humans it can engage socially in novel ways even without a single example of that social interaction. Moreover, the judgments of these Social MDPs align closely with those of humans when considering which social interaction is taking place in an environment. This method both sheds light on the nature of social interactions, by providing concrete mathematical definitions, and brings rich social interactions into a mathematical framework that has proven to be natural for robotics, MDPs.
Trajectory Prediction with Linguistic Representations
Oct 19, 2021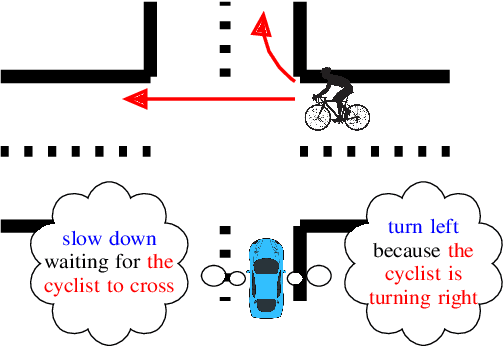
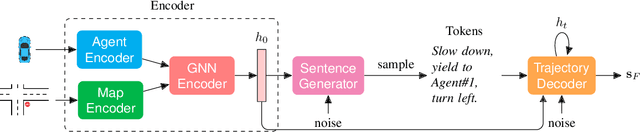
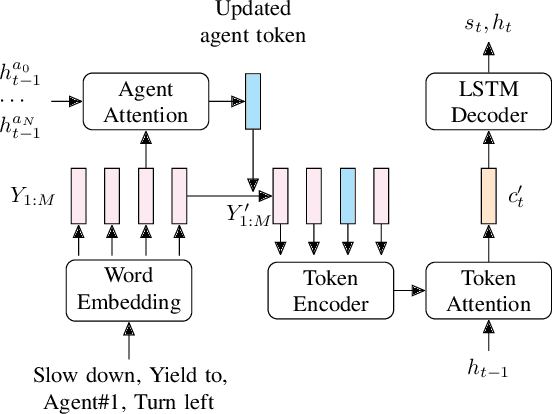

Language allows humans to build mental models that interpret what is happening around them resulting in more accurate long-term predictions. We present a novel trajectory prediction model that uses linguistic intermediate representations to forecast trajectories, and is trained using trajectory samples with partially annotated captions. The model learns the meaning of each of the words without direct per-word supervision. At inference time, it generates a linguistic description of trajectories which captures maneuvers and interactions over an extended time interval. This generated description is used to refine predictions of the trajectories of multiple agents. We train and validate our model on the Argoverse dataset, and demonstrate improved accuracy results in trajectory prediction. In addition, our model is more interpretable: it presents part of its reasoning in plain language as captions, which can aid model development and can aid in building confidence in the model before deploying it.
Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset
Oct 14, 2021
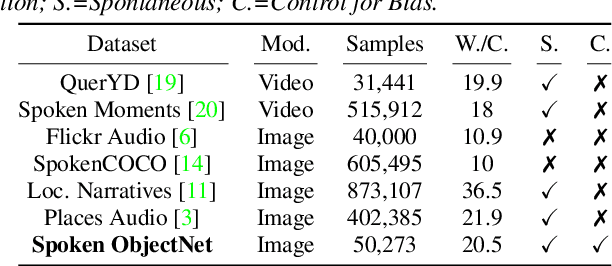


Visually-grounded spoken language datasets can enable models to learn cross-modal correspondences with very weak supervision. However, modern audio-visual datasets contain biases that undermine the real-world performance of models trained on that data. We introduce Spoken ObjectNet, which is designed to remove some of these biases and provide a way to better evaluate how effectively models will perform in real-world scenarios. This dataset expands upon ObjectNet, which is a bias-controlled image dataset that features similar image classes to those present in ImageNet. We detail our data collection pipeline, which features several methods to improve caption quality, including automated language model checks. Lastly, we show baseline results on image retrieval and audio retrieval tasks. These results show that models trained on other datasets and then evaluated on Spoken ObjectNet tend to perform poorly due to biases in other datasets that the models have learned. We also show evidence that the performance decrease is due to the dataset controls, and not the transfer setting.
PHASE: PHysically-grounded Abstract Social Events for Machine Social Perception
Mar 19, 2021
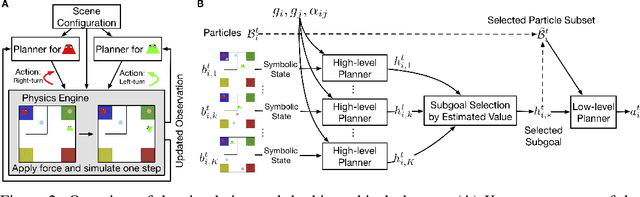

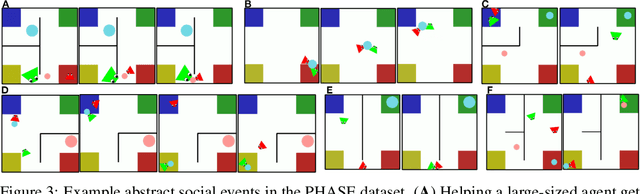
The ability to perceive and reason about social interactions in the context of physical environments is core to human social intelligence and human-machine cooperation. However, no prior dataset or benchmark has systematically evaluated physically grounded perception of complex social interactions that go beyond short actions, such as high-fiving, or simple group activities, such as gathering. In this work, we create a dataset of physically-grounded abstract social events, PHASE, that resemble a wide range of real-life social interactions by including social concepts such as helping another agent. PHASE consists of 2D animations of pairs of agents moving in a continuous space generated procedurally using a physics engine and a hierarchical planner. Agents have a limited field of view, and can interact with multiple objects, in an environment that has multiple landmarks and obstacles. Using PHASE, we design a social recognition task and a social prediction task. PHASE is validated with human experiments demonstrating that humans perceive rich interactions in the social events, and that the simulated agents behave similarly to humans. As a baseline model, we introduce a Bayesian inverse planning approach, SIMPLE (SIMulation, Planning and Local Estimation), which outperforms state-of-the-art feed-forward neural networks. We hope that PHASE can serve as a difficult new challenge for developing new models that can recognize complex social interactions.
Learning a natural-language to LTL executable semantic parser for grounded robotics
Aug 11, 2020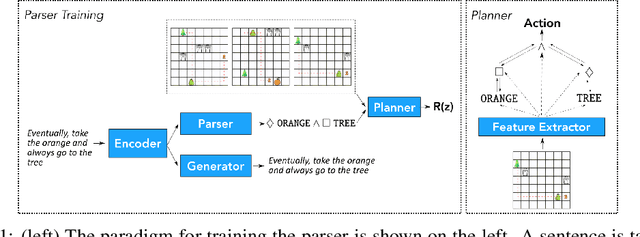
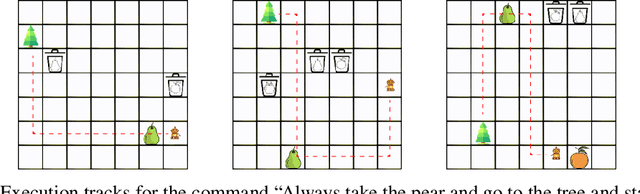
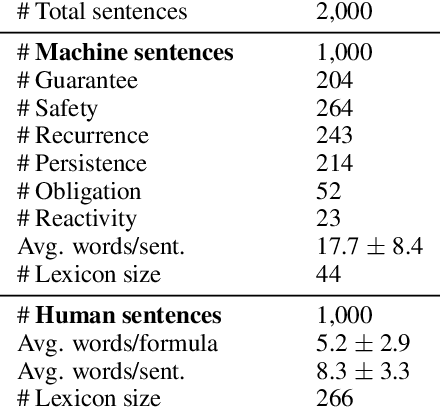
Children acquire their native language with apparent ease by observing how language is used in context and attempting to use it themselves. They do so without laborious annotations, negative examples, or even direct corrections. We take a step toward robots that can do the same by training a grounded semantic parser, which discovers latent linguistic representations that can be used for the execution of natural-language commands. In particular, we focus on the difficult domain of commands with a temporal aspect, whose semantics we capture with Linear Temporal Logic, LTL. Our parser is trained with pairs of sentences and executions as well as an executor. At training time, the parser hypothesizes a meaning representation for the input as a formula in LTL. Three competing pressures allow the parser to discover meaning from language. First, any hypothesized meaning for a sentence must be permissive enough to reflect all the annotated execution trajectories. Second, the executor -- a pretrained end-to-end LTL planner -- must find that the observed trajectories are likely executions of the meaning. Finally, a generator, which reconstructs the original input, encourages the model to find representations that conserve knowledge about the command. Together these ensure that the meaning is neither too general nor too specific. Our model generalizes well, being able to parse and execute both machine-generated and human-generated commands, with near-equal accuracy, despite the fact that the human-generated sentences are much more varied and complex with an open lexicon. The approach presented here is not specific to LTL; it can be applied to any domain where sentence meanings can be hypothesized and an executor can verify these meanings, thus opening the door to many applications for robotic agents.
Compositional Networks Enable Systematic Generalization for Grounded Language Understanding
Aug 06, 2020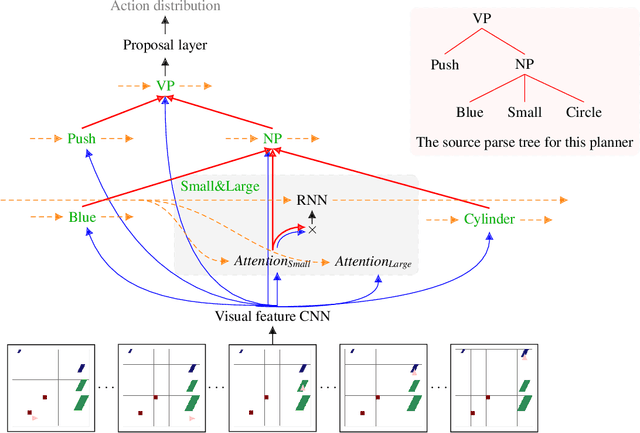
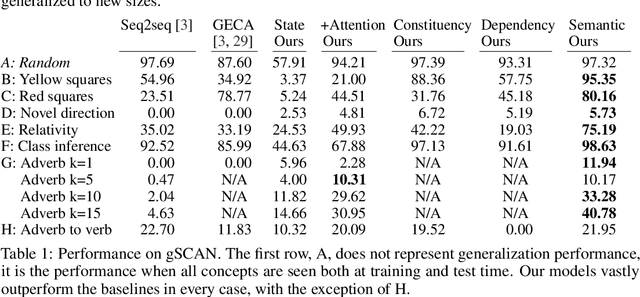
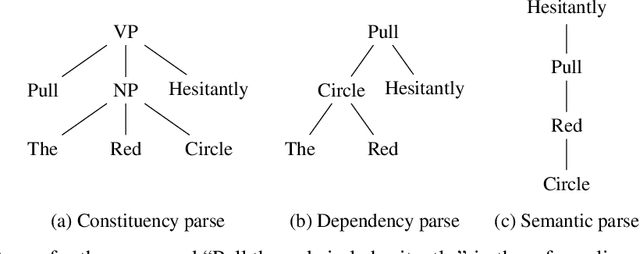
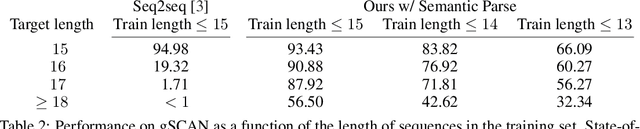
Humans are remarkably flexible when understanding new sentences that include combinations of concepts they have never encountered before. Recent work has shown that while deep networks can mimic some human language abilities when presented with novel sentences, systematic variation uncovers the limitations in the language-understanding abilities of neural networks. We demonstrate that these limitations can be overcome by addressing the generalization challenges in a recently-released dataset, gSCAN, which explicitly measures how well a robotic agent is able to interpret novel ideas grounded in vision, e.g., novel pairings of adjectives and nouns. The key principle we employ is compositionality: that the compositional structure of networks should reflect the compositional structure of the problem domain they address, while allowing all other parameters and properties to be learned end-to-end with weak supervision. We build a general-purpose mechanism that enables robots to generalize their language understanding to compositional domains. Crucially, our base network has the same state-of-the-art performance as prior work, 97% execution accuracy, while at the same time generalizing its knowledge when prior work does not; for example, achieving 95% accuracy on novel adjective-noun compositions where previous work has 55% average accuracy. Robust language understanding without dramatic failures and without corner causes is critical to building safe and fair robots; we demonstrate the significant role that compositionality can play in achieving that goal.
Encoding formulas as deep networks: Reinforcement learning for zero-shot execution of LTL formulas
Jun 01, 2020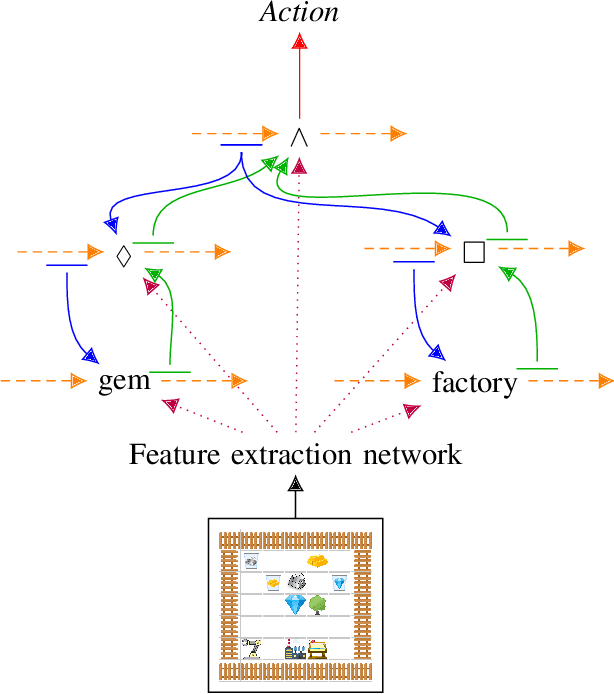
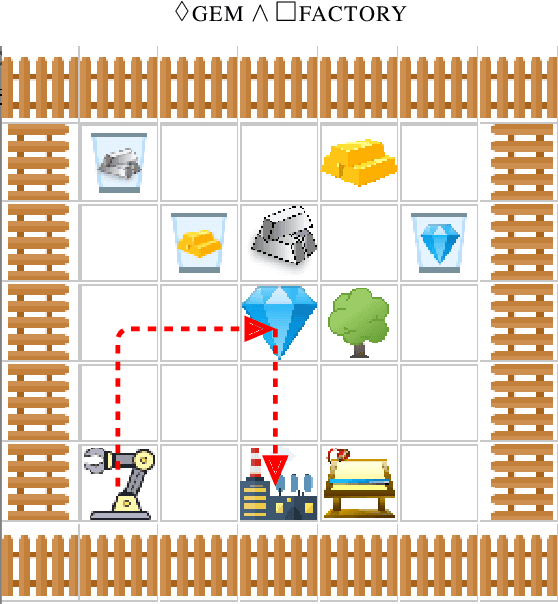


We demonstrate a reinforcement learning agent which uses a compositional recurrent neural network that takes as input an LTL formula and determines satisfying actions. The input LTL formulas have never been seen before, yet the network performs zero-shot generalization to satisfy them. This is a novel form of multi-task learning for RL agents where agents learn from one diverse set of tasks and generalize to a new set of diverse tasks. The formulation of the network enables this capacity to generalize. We demonstrate this ability in two domains. In a symbolic domain, the agent finds a sequence of letters in that are accepted. In a Minecraft-like environment, the agent finds a sequence of actions that conform to the formula. While prior work could learn to execute one formula reliably given examples of that formula, we demonstrate how to encode all formulas reliably. This could form the basis of new multi-task agents that discover sub-tasks and execute them without any additional training, as well as the agents which follow more complex linguistic commands. The structures required for this generalization are specific to LTL formulas, which opens up an interesting theoretical question: what structures are required in neural networks for zero-shot generalization to different logics?
Measuring Social Biases in Grounded Vision and Language Embeddings
Feb 20, 2020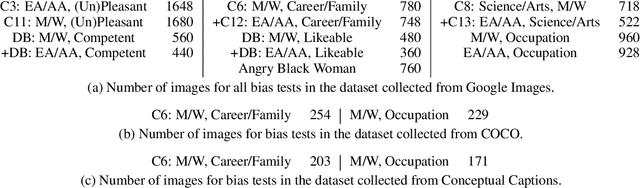


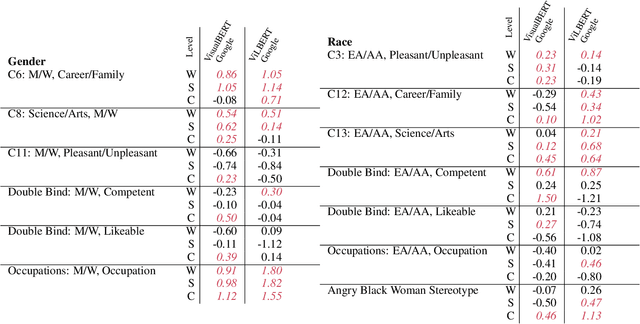
We generalize the notion of social biases from language embeddings to grounded vision and language embeddings. Biases are present in grounded embeddings, and indeed seem to be equally or more significant than for ungrounded embeddings. This is despite the fact that vision and language can suffer from different biases, which one might hope could attenuate the biases in both. Multiple ways exist to generalize metrics measuring bias in word embeddings to this new setting. We introduce the space of generalizations (Grounded-WEAT and Grounded-SEAT) and demonstrate that three generalizations answer different yet important questions about how biases, language, and vision interact. These metrics are used on a new dataset, the first for grounded bias, created by augmenting extending standard linguistic bias benchmarks with 10,228 images from COCO, Conceptual Captions, and Google Images. Dataset construction is challenging because vision datasets are themselves very biased. The presence of these biases in systems will begin to have real-world consequences as they are deployed, making carefully measuring bias and then mitigating it critical to building a fair society.