 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Human Pose Estimation in Ancient Vase Paintings via Perceptually-grounded Style Transfer Learning
Dec 10, 2020
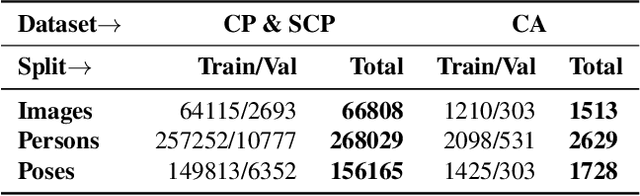

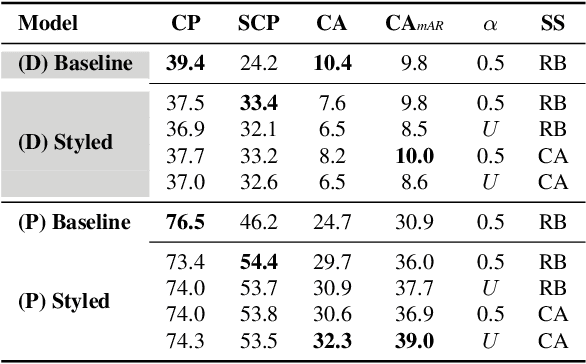
Human pose estimation (HPE) is a central part of understanding the visual narration and body movements of characters depicted in artwork collections, such as Greek vase paintings. Unfortunately, existing HPE methods do not generalise well across domains resulting in poorly recognized poses. Therefore, we propose a two step approach: (1) adapting a dataset of natural images of known person and pose annotations to the style of Greek vase paintings by means of image style-transfer. We introduce a perceptually-grounded style transfer training to enforce perceptual consistency. Then, we fine-tune the base model with this newly created dataset. We show that using style-transfer learning significantly improves the SOTA performance on unlabelled data by more than 6% mean average precision (mAP) as well as mean average recall (mAR). (2) To improve the already strong results further, we created a small dataset (ClassArch) consisting of ancient Greek vase paintings from the 6-5th century BCE with person and pose annotations. We show that fine-tuning on this data with a style-transferred model improves the performance further. In a thorough ablation study, we give a targeted analysis of the influence of style intensities, revealing that the model learns generic domain styles. Additionally, we provide a pose-based image retrieval to demonstrate the effectiveness of our method.
Robustness Investigation on Deep Learning CT Reconstruction for Real-Time Dose Optimization
Dec 07, 2020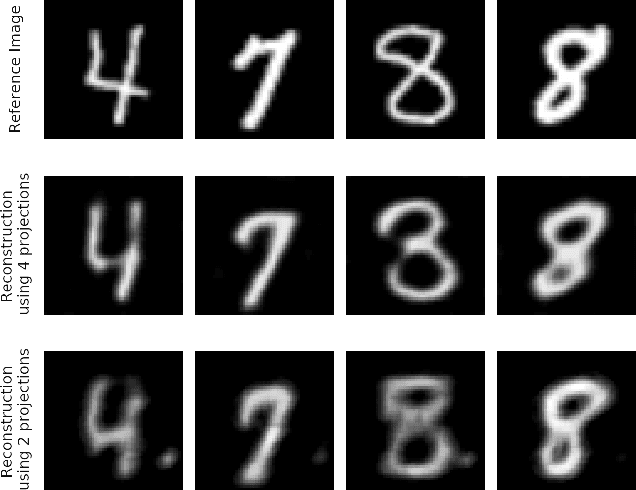

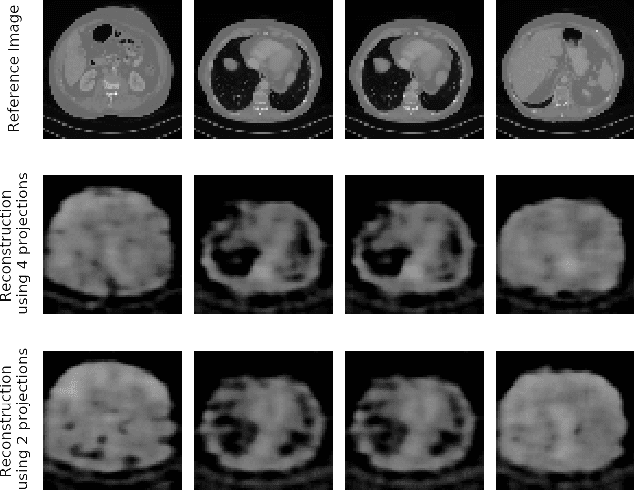
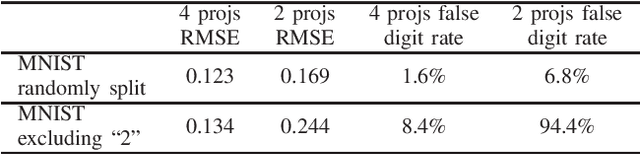
In computed tomography (CT), automatic exposure control (AEC) is frequently used to reduce radiation dose exposure to patients. For organ-specific AEC, a preliminary CT reconstruction is necessary to estimate organ shapes for dose optimization, where only a few projections are allowed for real-time reconstruction. In this work, we investigate the performance of automated transform by manifold approximation (AUTOMAP) in such applications. For proof of concept, we investigate its performance on the MNIST dataset first, where the dataset containing all the 10 digits are randomly split into a training set and a test set. We train the AUTOMAP model for image reconstruction from 2 projections or 4 projections directly. The test results demonstrate that AUTOMAP is able to reconstruct most digits well with a false rate of 1.6% and 6.8% respectively. In our subsequent experiment, the MNIST dataset is split in a way that the training set contains 9 digits only while the test set contains the excluded digit only, for instance "2". In the test results, the digit "2"s are falsely predicted as "3" or "5" when using 2 projections for reconstruction, reaching a false rate of 94.4%. For the application in medical images, AUTOMAP is also trained on patients' CT images. The test images reach an average root-mean-square error of 290 HU. Although the coarse body outlines are well reconstructed, some organs are misshaped.
Synthetic Image Rendering Solves Annotation Problem in Deep Learning Nanoparticle Segmentation
Nov 20, 2020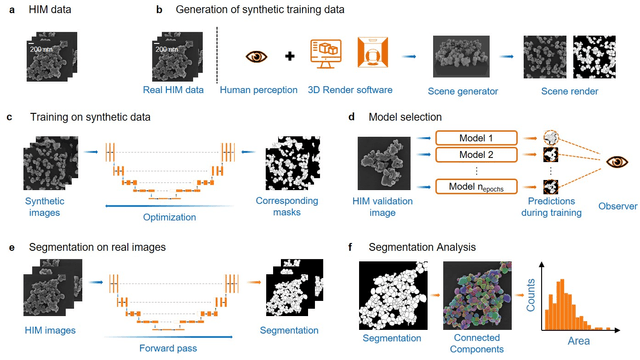
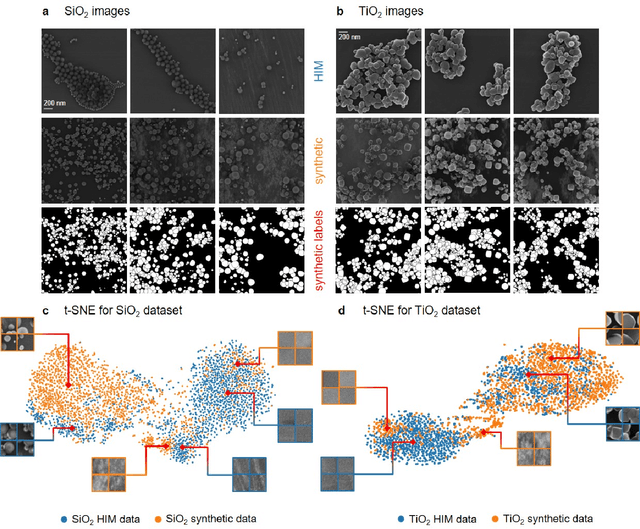
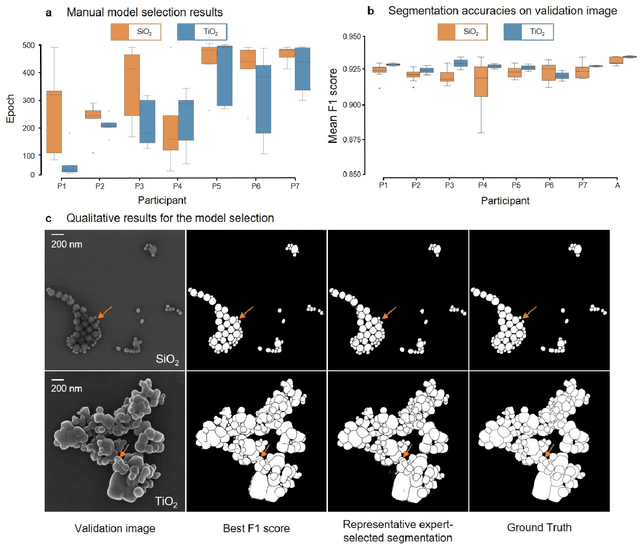
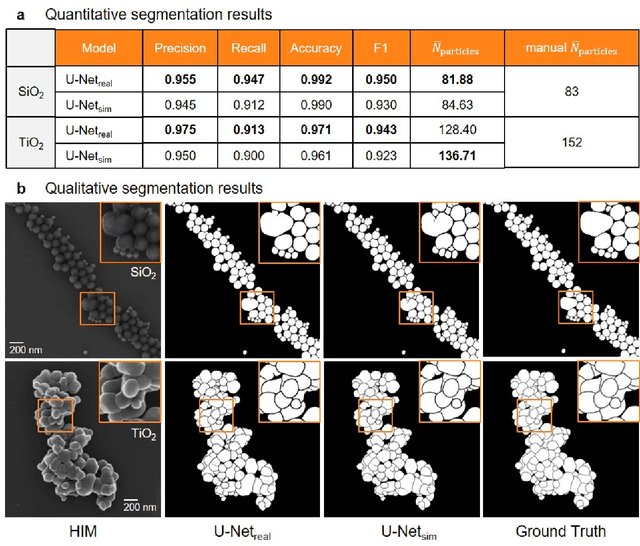
Nanoparticles occur in various environments as a consequence of man-made processes, which raises concerns about their impact on the environment and human health. To allow for proper risk assessment, a precise and statistically relevant analysis of particle characteristics (such as e.g. size, shape and composition) is required that would greatly benefit from automated image analysis procedures. While deep learning shows impressive results in object detection tasks, its applicability is limited by the amount of representative, experimentally collected and manually annotated training data. Here, we present an elegant, flexible and versatile method to bypass this costly and tedious data acquisition process. We show that using a rendering software allows to generate realistic, synthetic training data to train a state-of-the art deep neural network. Using this approach, we derive a segmentation accuracy that is comparable to man-made annotations for toxicologically relevant metal-oxide nanoparticle ensembles which we chose as examples. Our study paves the way towards the use of deep learning for automated, high-throughput particle detection in a variety of imaging techniques such as microscopies and spectroscopies, for a wide variety of studies and applications, including the detection of plastic micro- and nanoparticles.
Joint Super-Resolution and Rectification for Solar Cell Inspection
Nov 10, 2020
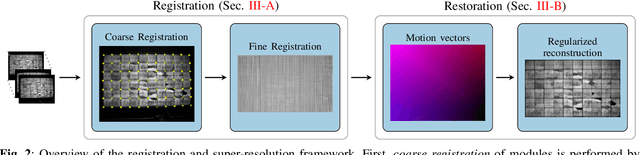
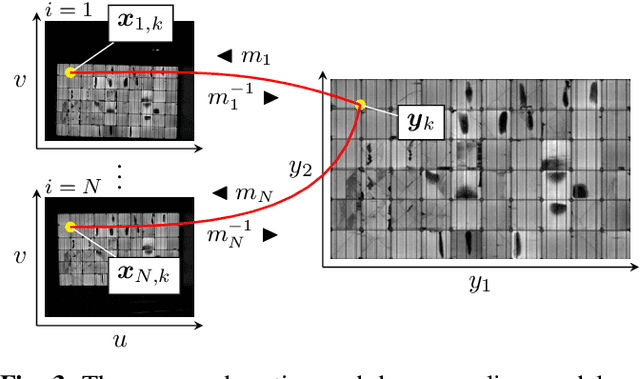

Visual inspection of solar modules is an important monitoring facility in photovoltaic power plants. Since a single measurement of fast CMOS sensors is limited in spatial resolution and often not sufficient to reliably detect small defects, we apply multi-frame super-resolution (MFSR) to a sequence of low resolution measurements. In addition, the rectification and removal of lens distortion simplifies subsequent analysis. Therefore, we propose to fuse this pre-processing with standard MFSR algorithms. This is advantageous, because we omit a separate processing step, the motion estimation becomes more stable and the spacing of high-resolution (HR) pixels on the rectified module image becomes uniform w.r.t. the module plane, regardless of perspective distortion. We present a comprehensive user study showing that MFSR is beneficial for defect recognition by human experts and that the proposed method performs better than the state of the art. Furthermore, we apply automated crack segmentation and show that the proposed method performs 3x better than bicubic upsampling and 2x better than the state of the art for automated inspection.
Maximum a posteriori signal recovery for optical coherence tomography angiography image generation and denoising
Oct 29, 2020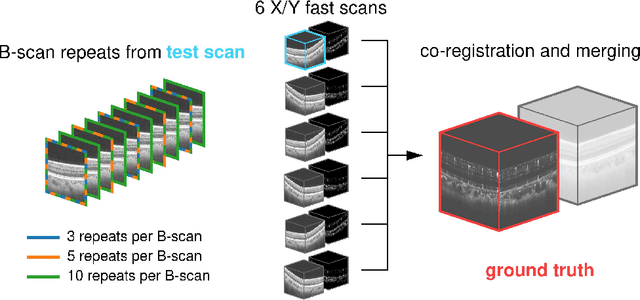
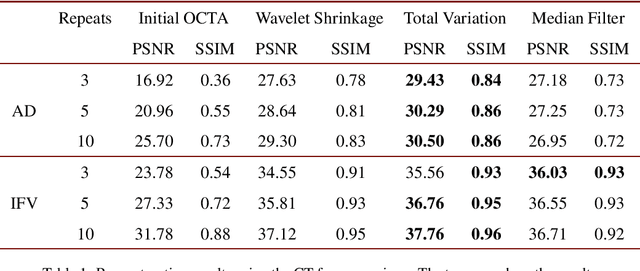
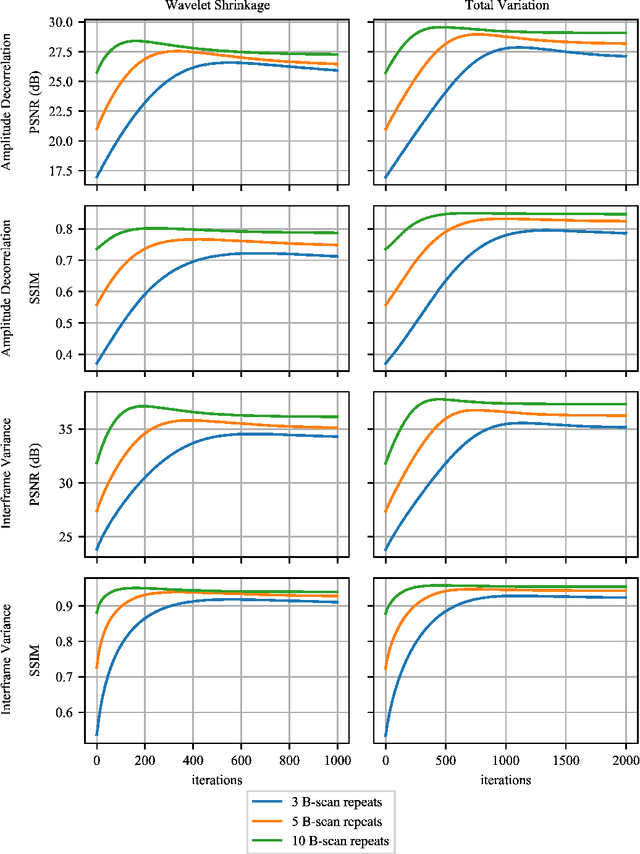

Optical coherence tomography angiography (OCTA) is a novel and clinically promising imaging modality to image retinal and sub-retinal vasculature. Based on repeated optical coherence tomography (OCT) scans, intensity changes are observed over time and used to compute OCTA image data. OCTA data are prone to noise and artifacts caused by variations in flow speed and patient movement. We propose a novel iterative maximum a posteriori signal recovery algorithm in order to generate OCTA volumes with reduced noise and increased image quality. This algorithm is based on previous work on probabilistic OCTA signal models and maximum likelihood estimates. Reconstruction results using total variation minimization and wavelet shrinkage for regularization were compared against an OCTA ground truth volume, merged from six co-registered single OCTA volumes. The results show a significant improvement in peak signal-to-noise ratio and structural similarity. The presented algorithm brings together OCTA image generation and Bayesian statistics and can be developed into new OCTA image generation and denoising algorithms.
Reconstruction of Voxels with Position- and Angle-Dependent Weightings
Oct 27, 2020

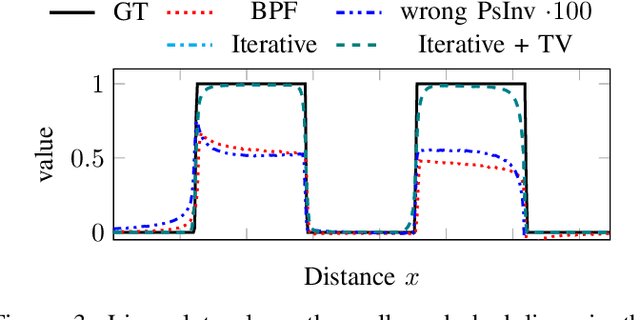
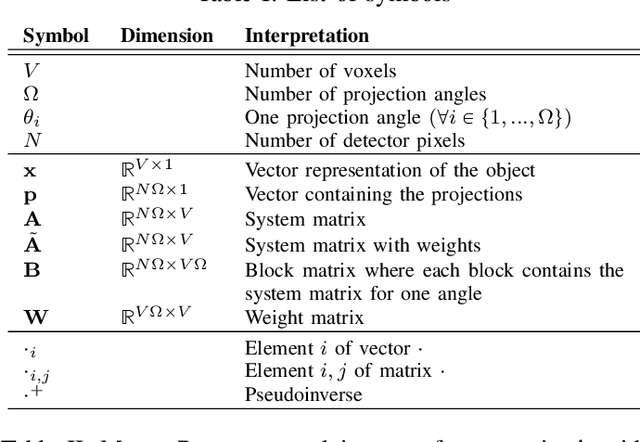
The reconstruction problem of voxels with individual weightings can be modeled a position- and angle- dependent function in the forward-projection. This changes the system matrix and prohibits to use standard filtered backprojection. In this work we first formulate this reconstruction problem in terms of a system matrix and weighting part. We compute the pseudoinverse and show that the solution is rank-deficient and hence very ill posed. This is a fundamental limitation for reconstruction. We then derive an iterative solution and experimentally show its uperiority to any closed-form solution.
ICFHR 2020 Competition on Image Retrieval for Historical Handwritten Fragments
Oct 20, 2020


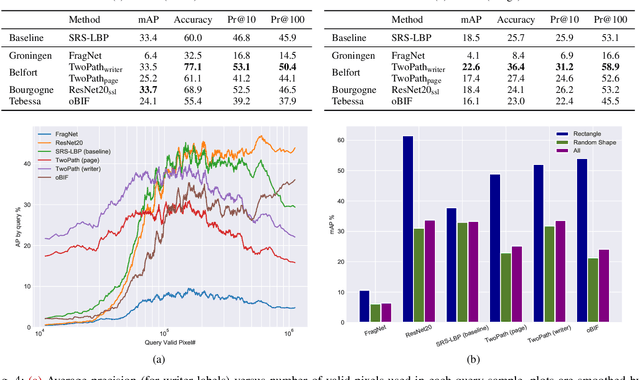
This competition succeeds upon a line of competitions for writer and style analysis of historical document images. In particular, we investigate the performance of large-scale retrieval of historical document fragments in terms of style and writer identification. The analysis of historic fragments is a difficult challenge commonly solved by trained humanists. In comparison to previous competitions, we make the results more meaningful by addressing the issue of sample granularity and moving from writer to page fragment retrieval. The two approaches, style and author identification, provide information on what kind of information each method makes better use of and indirectly contribute to the interpretability of the participating method. Therefore, we created a large dataset consisting of more than 120 000 fragments. Although the most teams submitted methods based on convolutional neural networks, the winning entry achieves an mAP below 40%.
Automatic CAD-RADS Scoring Using Deep Learning
Oct 05, 2020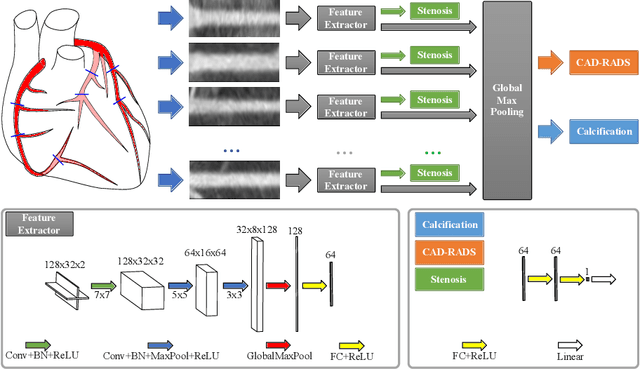
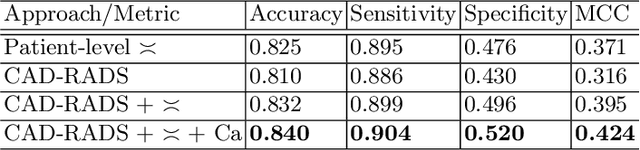
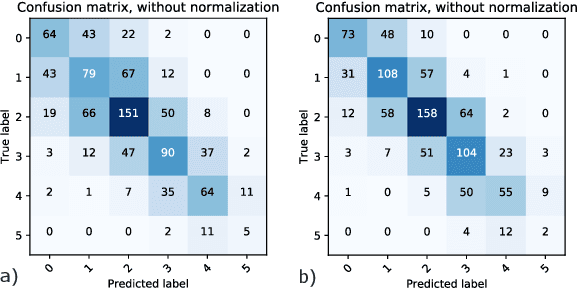
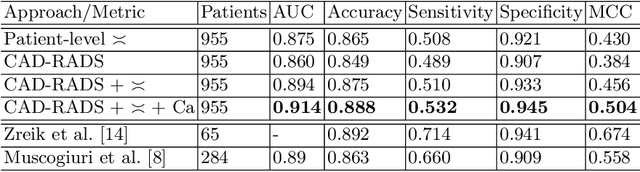
Coronary CT angiography (CCTA) has established its role as a non-invasive modality for the diagnosis of coronary artery disease (CAD). The CAD-Reporting and Data System (CAD-RADS) has been developed to standardize communication and aid in decision making based on CCTA findings. The CAD-RADS score is determined by manual assessment of all coronary vessels and the grading of lesions within the coronary artery tree. We propose a bottom-up approach for fully-automated prediction of this score using deep-learning operating on a segment-wise representation of the coronary arteries. The method relies solely on a prior fully-automated centerline extraction and segment labeling and predicts the segment-wise stenosis degree and the overall calcification grade as auxiliary tasks in a multi-task learning setup. We evaluate our approach on a data collection consisting of 2,867 patients. On the task of identifying patients with a CAD-RADS score indicating the need for further invasive investigation our approach reaches an area under curve (AUC) of 0.923 and an AUC of 0.914 for determining whether the patient suffers from CAD. This level of performance enables our approach to be used in a fully-automated screening setup or to assist diagnostic CCTA reading, especially due to its neural architecture design -- which allows comprehensive predictions.
Deep Learning-based Pipeline for Module Power Prediction from EL Measurements
Sep 30, 2020


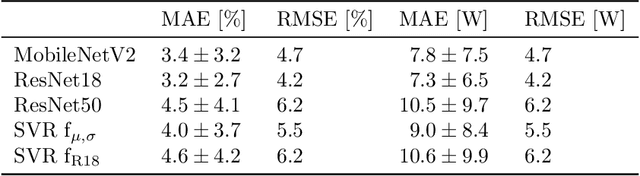
Automated inspection plays an important role in monitoring large-scale photovoltaic power plants. Commonly, electroluminescense measurements are used to identify various types of defects on solar modules but have not been used to determine the power of a module. However, knowledge of the power at maximum power point is important as well, since drops in the power of a single module can affect the performance of an entire string. By now, this is commonly determined by measurements that require to discontact or even dismount the module, rendering a regular inspection of individual modules infeasible. In this work, we bridge the gap between electroluminescense measurements and the power determination of a module. We compile a large dataset of 719 electroluminescense measurementsof modules at various stages of degradation, especially cell cracks and fractures, and the corresponding power at maximum power point. Here,we focus on inactive regions and cracks as the predominant type of defect. We set up a baseline regression model to predict the power from electroluminescense measurements with a mean absolute error of 9.0+/-3.7W (4.0+/-8.4%). Then, we show that deep-learning can be used to train a model that performs significantly better (7.3+/-2.7W or 3.2+/-6.5%). With this work, we aim to open a new research topic. Therefore, we publicly release the dataset, the code and trained models to empower other researchers to compare against our results. Finally, we present a thorough evaluation of certain boundary conditions like the dataset size and an automated preprocessing pipeline for on-site measurements showing multiple modules at once.
Graph convolutional regression of cardiac depolarization from sparse endocardial maps
Sep 28, 2020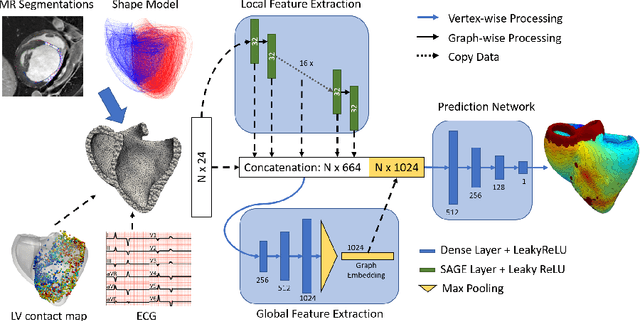
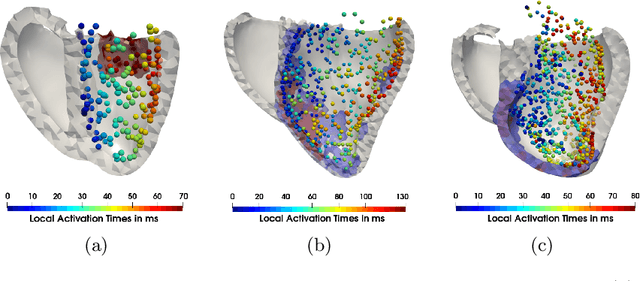
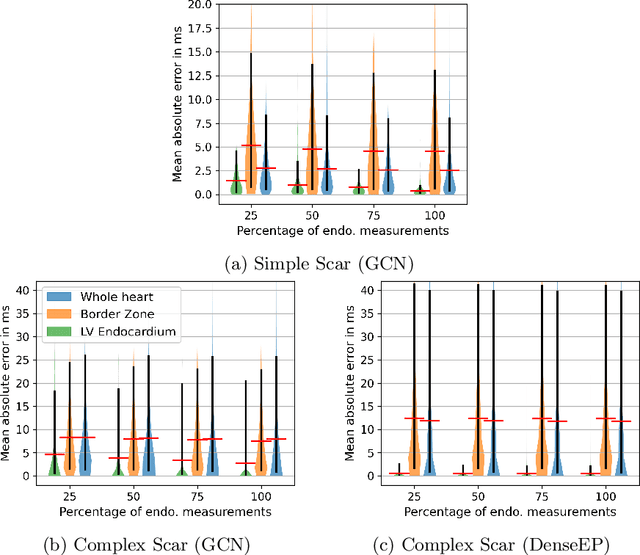
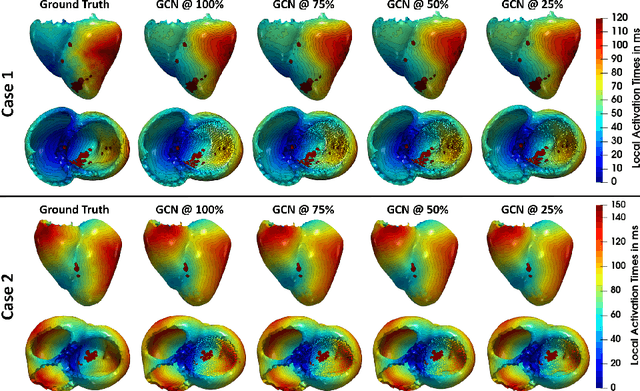
Electroanatomic mapping as routinely acquired in ablation therapy of ventricular tachycardia is the gold standard method to identify the arrhythmogenic substrate. To reduce the acquisition time and still provide maps with high spatial resolution, we propose a novel deep learning method based on graph convolutional neural networks to estimate the depolarization time in the myocardium, given sparse catheter data on the left ventricular endocardium, ECG, and magnetic resonance images. The training set consists of data produced by a computational model of cardiac electrophysiology on a large cohort of synthetically generated geometries of ischemic hearts. The predicted depolarization pattern has good agreement with activation times computed by the cardiac electrophysiology model in a validation set of five swine heart geometries with complex scar and border zone morphologies. The mean absolute error hereby measures 8 ms on the entire myocardium when providing 50\% of the endocardial ground truth in over 500 computed depolarization patterns. Furthermore, when considering a complete animal data set with high density electroanatomic mapping data as reference, the neural network can accurately reproduce the endocardial depolarization pattern, even when a small percentage of measurements are provided as input features (mean absolute error of 7 ms with 50\% of input samples). The results show that the proposed method, trained on synthetically generated data, may generalize to real data.