 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Brain MRI Foundation Models for the Clinic: Findings from the FOMO25 Challenge
Apr 13, 2026Clinical deployment of automated brain MRI analysis faces a fundamental challenge: clinical data is heterogeneous and noisy, and high-quality labels are prohibitively costly to obtain. Self-supervised learning (SSL) can address this by leveraging the vast amounts of unlabeled data produced in clinical workflows to train robust \textit{foundation models} that adapt out-of-domain with minimal supervision. However, the development of foundation models for brain MRI has been limited by small pretraining datasets and in-domain benchmarking focused on high-quality, research-grade data. To address this gap, we organized the FOMO25 challenge as a satellite event at MICCAI 2025. FOMO25 provided participants with a large pretraining dataset, FOMO60K, and evaluated models on data sourced directly from clinical workflows in few-shot and out-of-domain settings. Tasks covered infarct classification, meningioma segmentation, and brain age regression, and considered both models trained on FOMO60K (method track) and any data (open track). Nineteen foundation models from sixteen teams were evaluated using a standardized containerized pipeline. Results show that (a) self-supervised pretraining improves generalization on clinical data under domain shift, with the strongest models trained \textit{out-of-domain} surpassing supervised baselines trained \textit{in-domain}. (b) No single pretraining objective benefits all tasks: MAE favors segmentation, hybrid reconstruction-contrastive objectives favor classification, and (c) strong performance was achieved by small pretrained models, and improvements from scaling model size and training duration did not yield reliable benefits.
Consistent View Alignment Improves Foundation Models for 3D Medical Image Segmentation
Sep 17, 2025Many recent approaches in representation learning implicitly assume that uncorrelated views of a data point are sufficient to learn meaningful representations for various downstream tasks. In this work, we challenge this assumption and demonstrate that meaningful structure in the latent space does not emerge naturally. Instead, it must be explicitly induced. We propose a method that aligns representations from different views of the data to align complementary information without inducing false positives. Our experiments show that our proposed self-supervised learning method, Consistent View Alignment, improves performance for downstream tasks, highlighting the critical role of structured view alignment in learning effective representations. Our method achieved first and second place in the MICCAI 2025 SSL3D challenge when using a Primus vision transformer and ResEnc convolutional neural network, respectively. The code and pretrained model weights are released at https://github.com/Tenbatsu24/LatentCampus.
Data-Agnostic Augmentations for Unknown Variations: Out-of-Distribution Generalisation in MRI Segmentation
May 15, 2025



Medical image segmentation models are often trained on curated datasets, leading to performance degradation when deployed in real-world clinical settings due to mismatches between training and test distributions. While data augmentation techniques are widely used to address these challenges, traditional visually consistent augmentation strategies lack the robustness needed for diverse real-world scenarios. In this work, we systematically evaluate alternative augmentation strategies, focusing on MixUp and Auxiliary Fourier Augmentation. These methods mitigate the effects of multiple variations without explicitly targeting specific sources of distribution shifts. We demonstrate how these techniques significantly improve out-of-distribution generalization and robustness to imaging variations across a wide range of transformations in cardiac cine MRI and prostate MRI segmentation. We quantitatively find that these augmentation methods enhance learned feature representations by promoting separability and compactness. Additionally, we highlight how their integration into nnU-Net training pipelines provides an easy-to-implement, effective solution for enhancing the reliability of medical segmentation models in real-world applications.
Graph convolutional regression of cardiac depolarization from sparse endocardial maps
Sep 28, 2020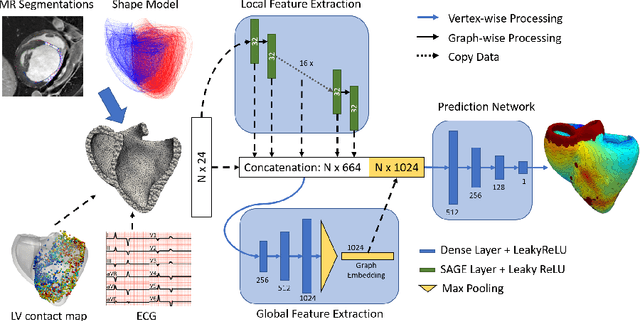
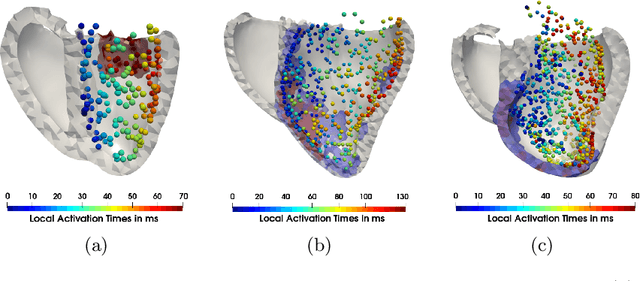
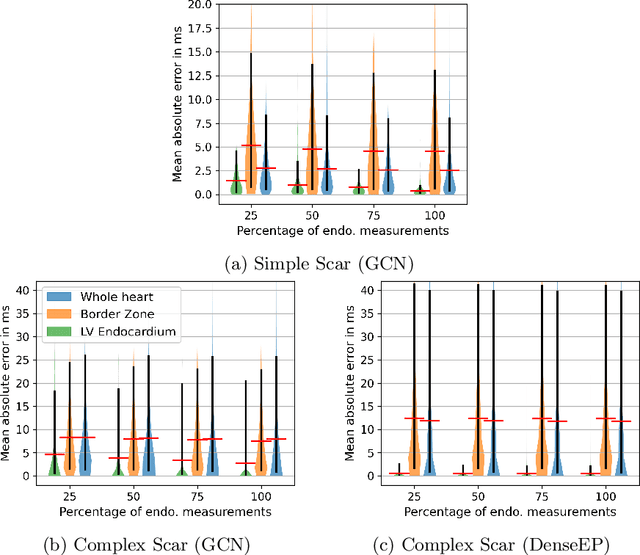
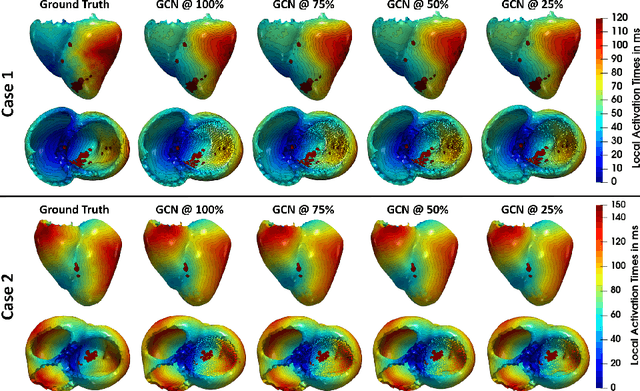
Electroanatomic mapping as routinely acquired in ablation therapy of ventricular tachycardia is the gold standard method to identify the arrhythmogenic substrate. To reduce the acquisition time and still provide maps with high spatial resolution, we propose a novel deep learning method based on graph convolutional neural networks to estimate the depolarization time in the myocardium, given sparse catheter data on the left ventricular endocardium, ECG, and magnetic resonance images. The training set consists of data produced by a computational model of cardiac electrophysiology on a large cohort of synthetically generated geometries of ischemic hearts. The predicted depolarization pattern has good agreement with activation times computed by the cardiac electrophysiology model in a validation set of five swine heart geometries with complex scar and border zone morphologies. The mean absolute error hereby measures 8 ms on the entire myocardium when providing 50\% of the endocardial ground truth in over 500 computed depolarization patterns. Furthermore, when considering a complete animal data set with high density electroanatomic mapping data as reference, the neural network can accurately reproduce the endocardial depolarization pattern, even when a small percentage of measurements are provided as input features (mean absolute error of 7 ms with 50\% of input samples). The results show that the proposed method, trained on synthetically generated data, may generalize to real data.