 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Inference Using LLM-Guided Discovery
Oct 23, 2023



At the core of causal inference lies the challenge of determining reliable causal graphs solely based on observational data. Since the well-known backdoor criterion depends on the graph, any errors in the graph can propagate downstream to effect inference. In this work, we initially show that complete graph information is not necessary for causal effect inference; the topological order over graph variables (causal order) alone suffices. Further, given a node pair, causal order is easier to elicit from domain experts compared to graph edges since determining the existence of an edge can depend extensively on other variables. Interestingly, we find that the same principle holds for Large Language Models (LLMs) such as GPT-3.5-turbo and GPT-4, motivating an automated method to obtain causal order (and hence causal effect) with LLMs acting as virtual domain experts. To this end, we employ different prompting strategies and contextual cues to propose a robust technique of obtaining causal order from LLMs. Acknowledging LLMs' limitations, we also study possible techniques to integrate LLMs with established causal discovery algorithms, including constraint-based and score-based methods, to enhance their performance. Extensive experiments demonstrate that our approach significantly improves causal ordering accuracy as compared to discovery algorithms, highlighting the potential of LLMs to enhance causal inference across diverse fields.
Faithful Explanations of Black-box NLP Models Using LLM-generated Counterfactuals
Oct 01, 2023



Causal explanations of the predictions of NLP systems are essential to ensure safety and establish trust. Yet, existing methods often fall short of explaining model predictions effectively or efficiently and are often model-specific. In this paper, we address model-agnostic explanations, proposing two approaches for counterfactual (CF) approximation. The first approach is CF generation, where a large language model (LLM) is prompted to change a specific text concept while keeping confounding concepts unchanged. While this approach is demonstrated to be very effective, applying LLM at inference-time is costly. We hence present a second approach based on matching, and propose a method that is guided by an LLM at training-time and learns a dedicated embedding space. This space is faithful to a given causal graph and effectively serves to identify matches that approximate CFs. After showing theoretically that approximating CFs is required in order to construct faithful explanations, we benchmark our approaches and explain several models, including LLMs with billions of parameters. Our empirical results demonstrate the excellent performance of CF generation models as model-agnostic explainers. Moreover, our matching approach, which requires far less test-time resources, also provides effective explanations, surpassing many baselines. We also find that Top-K techniques universally improve every tested method. Finally, we showcase the potential of LLMs in constructing new benchmarks for model explanation and subsequently validate our conclusions. Our work illuminates new pathways for efficient and accurate approaches to interpreting NLP systems.
Large Language Models as Annotators: Enhancing Generalization of NLP Models at Minimal Cost
Jun 27, 2023State-of-the-art supervised NLP models achieve high accuracy but are also susceptible to failures on inputs from low-data regimes, such as domains that are not represented in training data. As an approximation to collecting ground-truth labels for the specific domain, we study the use of large language models (LLMs) for annotating inputs and improving the generalization of NLP models. Specifically, given a budget for LLM annotations, we present an algorithm for sampling the most informative inputs to annotate and retrain the NLP model. We find that popular active learning strategies such as uncertainty-based sampling do not work well. Instead, we propose a sampling strategy based on the difference in prediction scores between the base model and the finetuned NLP model, utilizing the fact that most NLP models are finetuned from a base model. Experiments with classification (semantic similarity) and ranking (semantic search) tasks show that our sampling strategy leads to significant gains in accuracy for both the training and target domains.
Causal Effect Regularization: Automated Detection and Removal of Spurious Attributes
Jun 19, 2023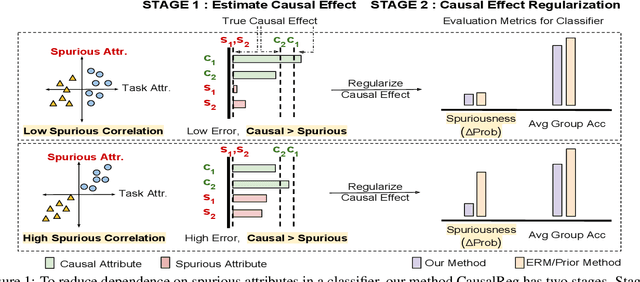

In many classification datasets, the task labels are spuriously correlated with some input attributes. Classifiers trained on such datasets often rely on these attributes for prediction, especially when the spurious correlation is high, and thus fail to generalize whenever there is a shift in the attributes' correlation at deployment. If we assume that the spurious attributes are known a priori, several methods have been proposed to learn a classifier that is invariant to the specified attributes. However, in real-world data, information about spurious attributes is typically unavailable. Therefore, we propose a method to automatically identify spurious attributes by estimating their causal effect on the label and then use a regularization objective to mitigate the classifier's reliance on them. Compared to a recent method for identifying spurious attributes, we find that our method is more accurate in removing the attribute from the learned model, especially when spurious correlation is high. Specifically, across synthetic, semi-synthetic, and real-world datasets, our method shows significant improvement in a metric used to quantify the dependence of a classifier on spurious attributes ($\Delta$Prob), while obtaining better or similar accuracy. In addition, our method mitigates the reliance on spurious attributes even under noisy estimation of causal effects. To explain the empirical robustness of our method, we create a simple linear classification task with two sets of attributes: causal and spurious. We prove that our method only requires that the ranking of estimated causal effects is correct across attributes to select the correct classifier.
Rethinking Counterfactual Data Augmentation Under Confounding
May 29, 2023



Counterfactual data augmentation has recently emerged as a method to mitigate confounding biases in the training data for a machine learning model. These biases, such as spurious correlations, arise due to various observed and unobserved confounding variables in the data generation process. In this paper, we formally analyze how confounding biases impact downstream classifiers and present a causal viewpoint to the solutions based on counterfactual data augmentation. We explore how removing confounding biases serves as a means to learn invariant features, ultimately aiding in generalization beyond the observed data distribution. Additionally, we present a straightforward yet powerful algorithm for generating counterfactual images, which effectively mitigates the influence of confounding effects on downstream classifiers. Through experiments on MNIST variants and the CelebA datasets, we demonstrate the effectiveness and practicality of our approach.
Controlling Learned Effects to Reduce Spurious Correlations in Text Classifiers
May 26, 2023To address the problem of NLP classifiers learning spurious correlations between training features and target labels, a common approach is to make the model's predictions invariant to these features. However, this can be counter-productive when the features have a non-zero causal effect on the target label and thus are important for prediction. Therefore, using methods from the causal inference literature, we propose an algorithm to regularize the learnt effect of the features on the model's prediction to the estimated effect of feature on label. This results in an automated augmentation method that leverages the estimated effect of a feature to appropriately change the labels for new augmented inputs. On toxicity and IMDB review datasets, the proposed algorithm minimises spurious correlations and improves the minority group (i.e., samples breaking spurious correlations) accuracy, while also improving the total accuracy compared to standard training.
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
May 08, 2023The causal capabilities of large language models (LLMs) is a matter of significant debate, with critical implications for the use of LLMs in societally impactful domains such as medicine, science, law, and policy. We further our understanding of LLMs and their causal implications, considering the distinctions between different types of causal reasoning tasks, as well as the entangled threats of construct and measurement validity. LLM-based methods establish new state-of-the-art accuracies on multiple causal benchmarks. Algorithms based on GPT-3.5 and 4 outperform existing algorithms on a pairwise causal discovery task (97%, 13 points gain), counterfactual reasoning task (92%, 20 points gain), and actual causality (86% accuracy in determining necessary and sufficient causes in vignettes). At the same time, LLMs exhibit unpredictable failure modes and we provide some techniques to interpret their robustness. Crucially, LLMs perform these causal tasks while relying on sources of knowledge and methods distinct from and complementary to non-LLM based approaches. Specifically, LLMs bring capabilities so far understood to be restricted to humans, such as using collected knowledge to generate causal graphs or identifying background causal context from natural language. We envision LLMs to be used alongside existing causal methods, as a proxy for human domain knowledge and to reduce human effort in setting up a causal analysis, one of the biggest impediments to the widespread adoption of causal methods. We also see existing causal methods as promising tools for LLMs to formalize, validate, and communicate their reasoning especially in high-stakes scenarios. In capturing common sense and domain knowledge about causal mechanisms and supporting translation between natural language and formal methods, LLMs open new frontiers for advancing the research, practice, and adoption of causality.
The Counterfactual-Shapley Value: Attributing Change in System Metrics
Aug 17, 2022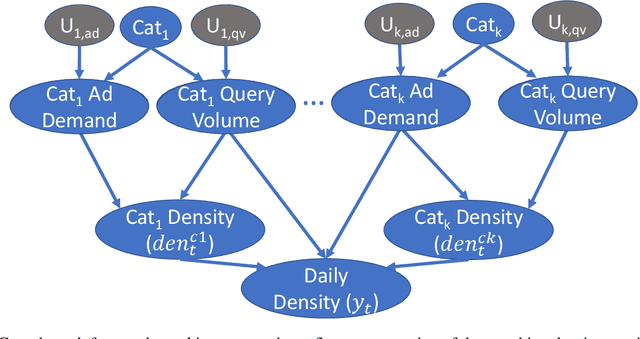
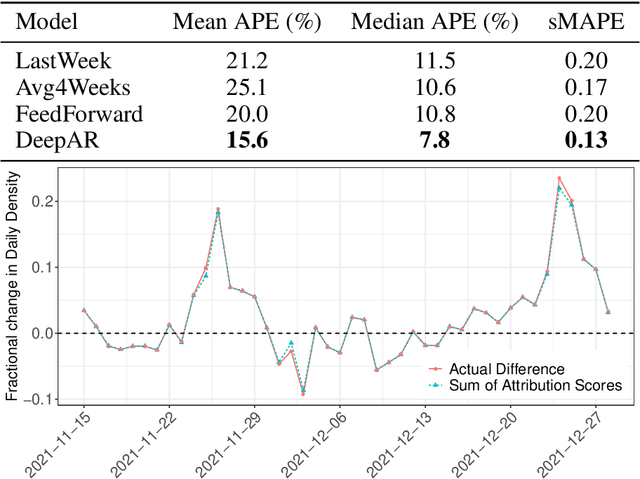
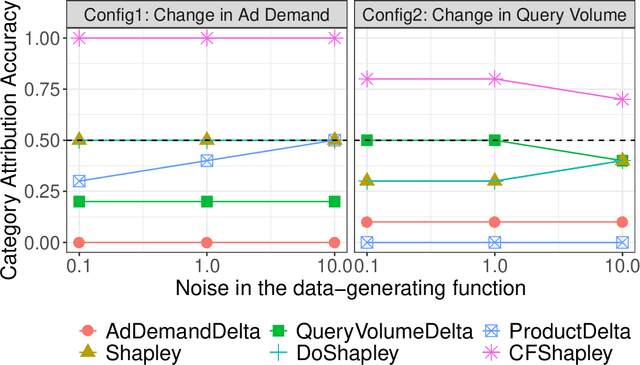
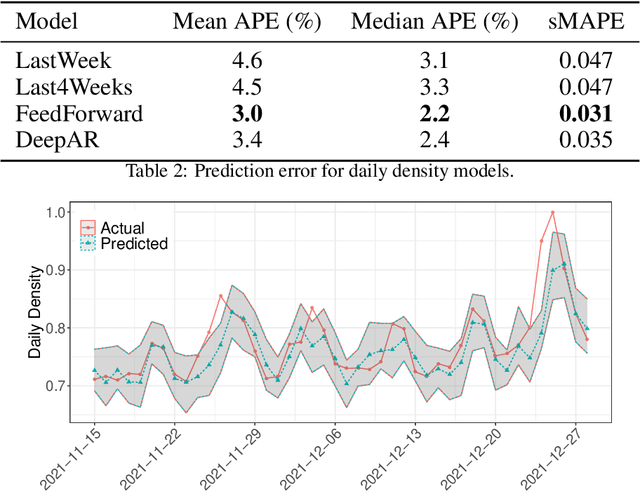
Given an unexpected change in the output metric of a large-scale system, it is important to answer why the change occurred: which inputs caused the change in metric? A key component of such an attribution question is estimating the counterfactual: the (hypothetical) change in the system metric due to a specified change in a single input. However, due to inherent stochasticity and complex interactions between parts of the system, it is difficult to model an output metric directly. We utilize the computational structure of a system to break up the modelling task into sub-parts, such that each sub-part corresponds to a more stable mechanism that can be modelled accurately over time. Using the system's structure also helps to view the metric as a computation over a structural causal model (SCM), thus providing a principled way to estimate counterfactuals. Specifically, we propose a method to estimate counterfactuals using time-series predictive models and construct an attribution score, CF-Shapley, that is consistent with desirable axioms for attributing an observed change in the output metric. Unlike past work on causal shapley values, our proposed method can attribute a single observed change in output (rather than a population-level effect) and thus provides more accurate attribution scores when evaluated on simulated datasets. As a real-world application, we analyze a query-ad matching system with the goal of attributing observed change in a metric for ad matching density. Attribution scores explain how query volume and ad demand from different query categories affect the ad matching density, leading to actionable insights and uncovering the role of external events (e.g., "Cheetah Day") in driving the matching density.
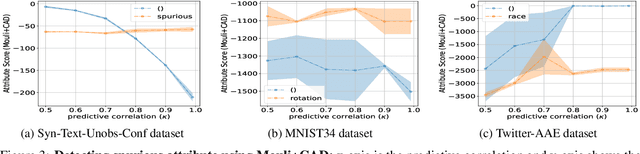
Probing Classifiers are Unreliable for Concept Removal and Detection
Jul 08, 2022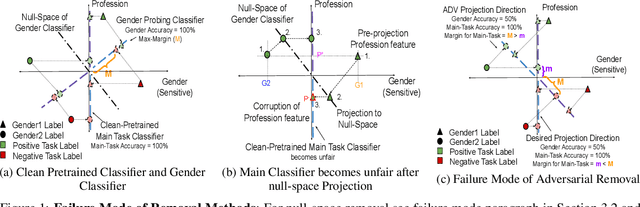
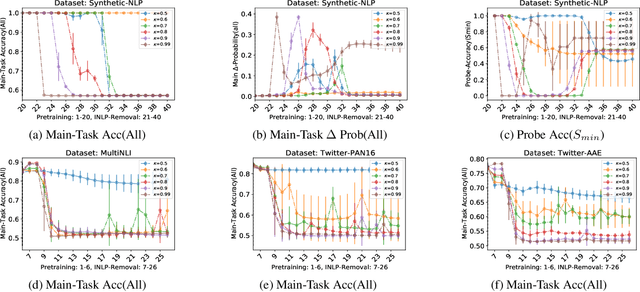
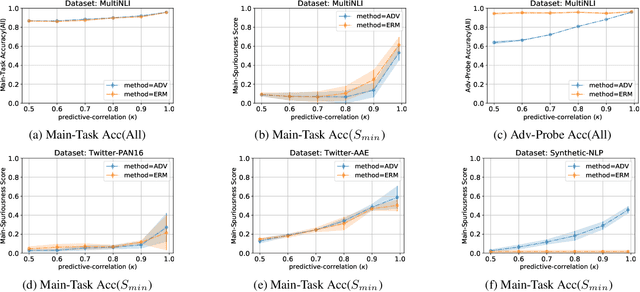
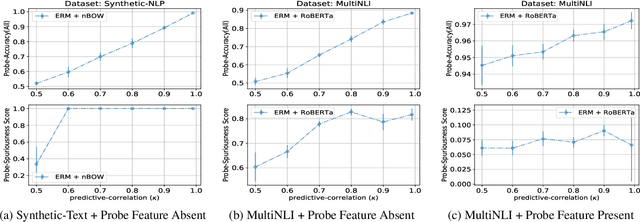
Neural network models trained on text data have been found to encode undesired linguistic or sensitive attributes in their representation. Removing such attributes is non-trivial because of a complex relationship between the attribute, text input, and the learnt representation. Recent work has proposed post-hoc and adversarial methods to remove such unwanted attributes from a model's representation. Through an extensive theoretical and empirical analysis, we show that these methods can be counter-productive: they are unable to remove the attributes entirely, and in the worst case may end up destroying all task-relevant features. The reason is the methods' reliance on a probing classifier as a proxy for the attribute. Even under the most favorable conditions when an attribute's features in representation space can alone provide 100% accuracy for learning the probing classifier, we prove that post-hoc or adversarial methods will fail to remove the attribute correctly. These theoretical implications are confirmed by empirical experiments on models trained on synthetic, Multi-NLI, and Twitter datasets. For sensitive applications of attribute removal such as fairness, we recommend caution against using these methods and propose a spuriousness metric to gauge the quality of the final classifier.
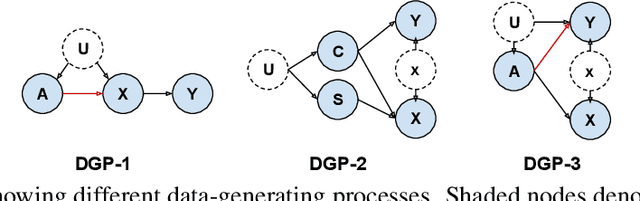
Modeling the Data-Generating Process is Necessary for Out-of-Distribution Generalization
Jun 15, 2022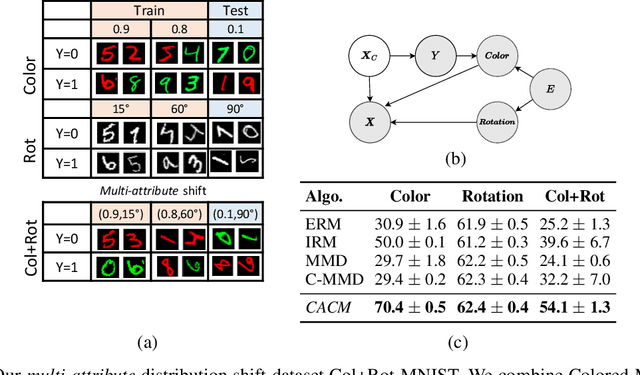

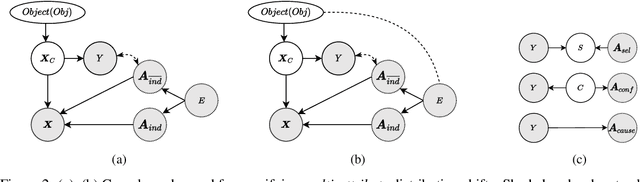
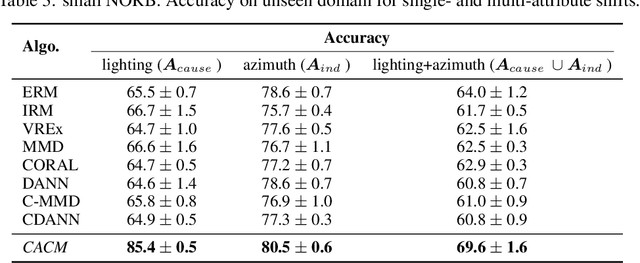
Real-world data collected from multiple domains can have multiple, distinct distribution shifts over multiple attributes. However, state-of-the art advances in domain generalization (DG) algorithms focus only on specific shifts over a single attribute. We introduce datasets with multi-attribute distribution shifts and find that existing DG algorithms fail to generalize. To explain this, we use causal graphs to characterize the different types of shifts based on the relationship between spurious attributes and the classification label. Each multi-attribute causal graph entails different constraints over observed variables, and therefore any algorithm based on a single, fixed independence constraint cannot work well across all shifts. We present Causally Adaptive Constraint Minimization (CACM), a new algorithm for identifying the correct independence constraints for regularization. Results on fully synthetic, MNIST and small NORB datasets, covering binary and multi-valued attributes and labels, confirm our theoretical claim: correct independence constraints lead to the highest accuracy on unseen domains whereas incorrect constraints fail to do so. Our results demonstrate the importance of modeling the causal relationships inherent in the data-generating process: in many cases, it is impossible to know the correct regularization constraints without this information.