 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal Statistical Learning with Self-Concordant Loss
Apr 30, 2022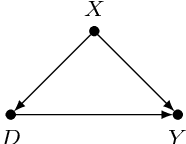

Orthogonal statistical learning and double machine learning have emerged as general frameworks for two-stage statistical prediction in the presence of a nuisance component. We establish non-asymptotic bounds on the excess risk of orthogonal statistical learning methods with a loss function satisfying a self-concordance property. Our bounds improve upon existing bounds by a dimension factor while lifting the assumption of strong convexity. We illustrate the results with examples from multiple treatment effect estimation and generalized partially linear modeling.
Omitted Variable Bias in Machine Learned Causal Models
Dec 29, 2021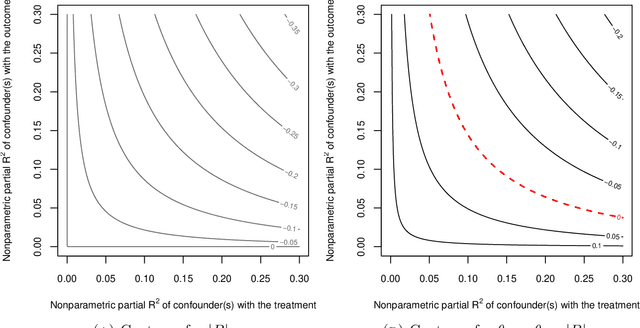
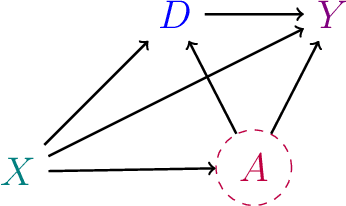
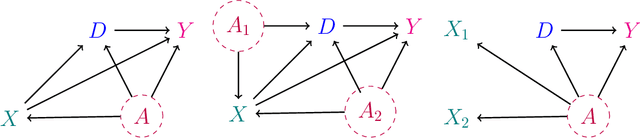
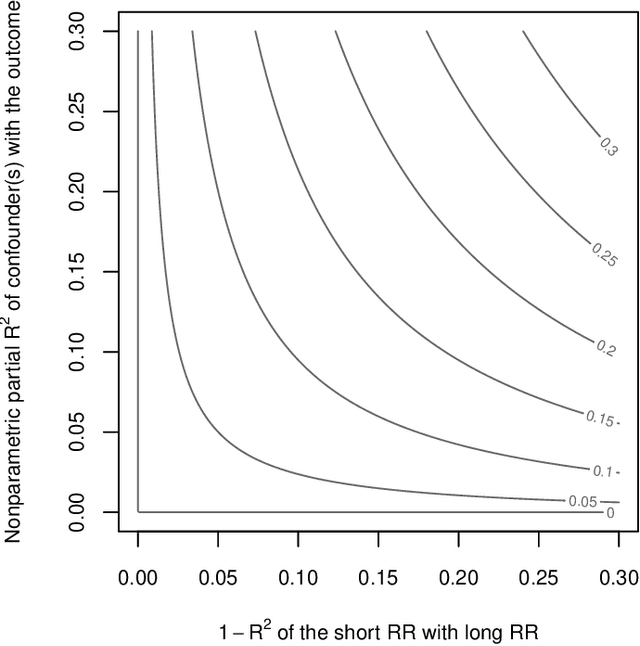
We derive general, yet simple, sharp bounds on the size of the omitted variable bias for a broad class of causal parameters that can be identified as linear functionals of the conditional expectation function of the outcome. Such functionals encompass many of the traditional targets of investigation in causal inference studies, such as, for example, (weighted) average of potential outcomes, average treatment effects (including subgroup effects, such as the effect on the treated), (weighted) average derivatives, and policy effects from shifts in covariate distribution -- all for general, nonparametric causal models. Our construction relies on the Riesz-Frechet representation of the target functional. Specifically, we show how the bound on the bias depends only on the additional variation that the latent variables create both in the outcome and in the Riesz representer for the parameter of interest. Moreover, in many important cases (e.g, average treatment effects in partially linear models, or in nonseparable models with a binary treatment) the bound is shown to depend on two easily interpretable quantities: the nonparametric partial $R^2$ (Pearson's "correlation ratio") of the unobserved variables with the treatment and with the outcome. Therefore, simple plausibility judgments on the maximum explanatory power of omitted variables (in explaining treatment and outcome variation) are sufficient to place overall bounds on the size of the bias. Finally, leveraging debiased machine learning, we provide flexible and efficient statistical inference methods to estimate the components of the bounds that are identifiable from the observed distribution.