 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaia2: Benchmarking LLM Agents on Dynamic and Asynchronous Environments
Feb 12, 2026We introduce Gaia2, a benchmark for evaluating large language model agents in realistic, asynchronous environments. Unlike prior static or synchronous evaluations, Gaia2 introduces scenarios where environments evolve independently of agent actions, requiring agents to operate under temporal constraints, adapt to noisy and dynamic events, resolve ambiguity, and collaborate with other agents. Each scenario is paired with a write-action verifier, enabling fine-grained, action-level evaluation and making Gaia2 directly usable for reinforcement learning from verifiable rewards. Our evaluation of state-of-the-art proprietary and open-source models shows that no model dominates across capabilities: GPT-5 (high) reaches the strongest overall score of 42% pass@1 but fails on time-sensitive tasks, Claude-4 Sonnet trades accuracy and speed for cost, Kimi-K2 leads among open-source models with 21% pass@1. These results highlight fundamental trade-offs between reasoning, efficiency, robustness, and expose challenges in closing the "sim2real" gap. Gaia2 is built on a consumer environment with the open-source Agents Research Environments platform and designed to be easy to extend. By releasing Gaia2 alongside the foundational ARE framework, we aim to provide the community with a flexible infrastructure for developing, benchmarking, and training the next generation of practical agent systems.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
Hyper-VolTran: Fast and Generalizable One-Shot Image to 3D Object Structure via HyperNetworks
Jan 05, 2024



Solving image-to-3D from a single view is an ill-posed problem, and current neural reconstruction methods addressing it through diffusion models still rely on scene-specific optimization, constraining their generalization capability. To overcome the limitations of existing approaches regarding generalization and consistency, we introduce a novel neural rendering technique. Our approach employs the signed distance function as the surface representation and incorporates generalizable priors through geometry-encoding volumes and HyperNetworks. Specifically, our method builds neural encoding volumes from generated multi-view inputs. We adjust the weights of the SDF network conditioned on an input image at test-time to allow model adaptation to novel scenes in a feed-forward manner via HyperNetworks. To mitigate artifacts derived from the synthesized views, we propose the use of a volume transformer module to improve the aggregation of image features instead of processing each viewpoint separately. Through our proposed method, dubbed as Hyper-VolTran, we avoid the bottleneck of scene-specific optimization and maintain consistency across the images generated from multiple viewpoints. Our experiments show the advantages of our proposed approach with consistent results and rapid generation.
Offline Evaluation of Reward-Optimizing Recommender Systems: The Case of Simulation
Sep 18, 2022Both in academic and industry-based research, online evaluation methods are seen as the golden standard for interactive applications like recommendation systems. Naturally, the reason for this is that we can directly measure utility metrics that rely on interventions, being the recommendations that are being shown to users. Nevertheless, online evaluation methods are costly for a number of reasons, and a clear need remains for reliable offline evaluation procedures. In industry, offline metrics are often used as a first-line evaluation to generate promising candidate models to evaluate online. In academic work, limited access to online systems makes offline metrics the de facto approach to validating novel methods. Two classes of offline metrics exist: proxy-based methods, and counterfactual methods. The first class is often poorly correlated with the online metrics we care about, and the latter class only provides theoretical guarantees under assumptions that cannot be fulfilled in real-world environments. Here, we make the case that simulation-based comparisons provide ways forward beyond offline metrics, and argue that they are a preferable means of evaluation.
Scalable representation learning and retrieval for display advertising
Jan 04, 2021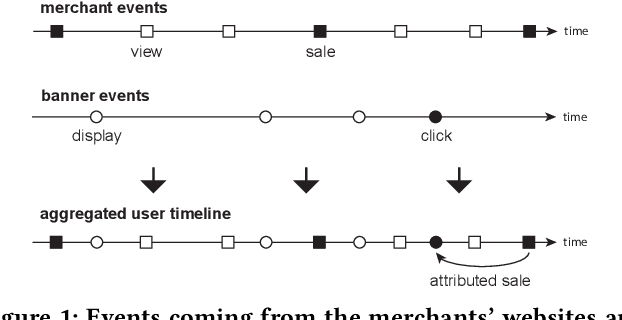

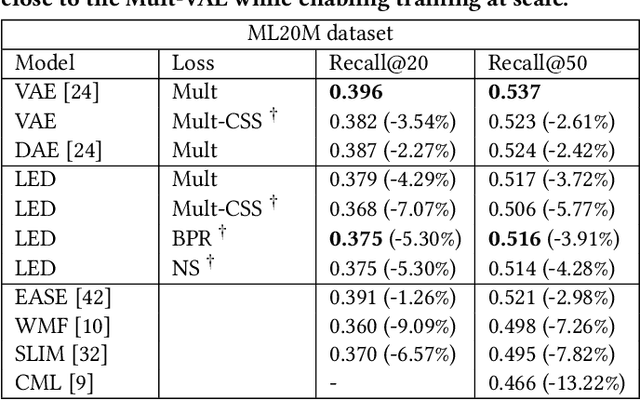
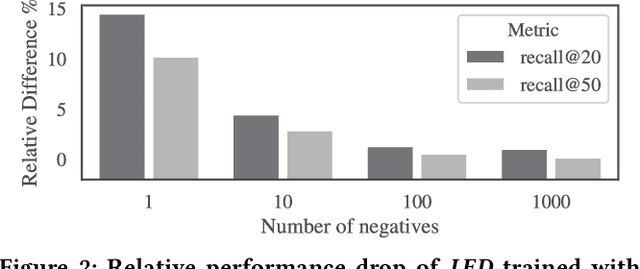
Over the past decades, recommendation has become a critical component of many online services such as media streaming and e-commerce. Recent advances in algorithms, evaluation methods and datasets have led to continuous improvements of the state-of-the-art. However, much work remains to be done to make these methods scale to the size of the internet. Online advertising offers a unique testbed for recommendation at scale. Every day, billions of users interact with millions of products in real-time. Systems addressing this scenario must work reliably at scale. We propose an efficient model (LED, for Lightweight Encoder-Decoder) reaching a new trade-off between complexity, scale and performance. Specifically, we show that combining large-scale matrix factorization with lightweight embedding fine-tuning unlocks state-of-the-art performance at scale. We further provide the detailed description of a system architecture and demonstrate its operation over two months at the scale of the internet. Our design allows serving billions of users across hundreds of millions of items in a few milliseconds using standard hardware.
Trans-gram, Fast Cross-lingual Word-embeddings
Jan 11, 2016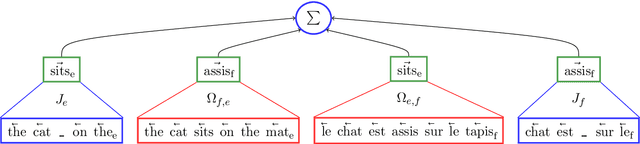
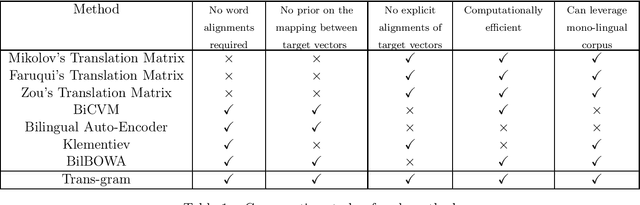

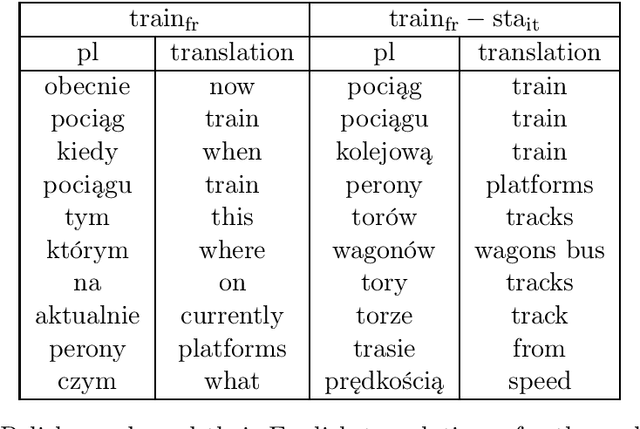
We introduce Trans-gram, a simple and computationally-efficient method to simultaneously learn and align wordembeddings for a variety of languages, using only monolingual data and a smaller set of sentence-aligned data. We use our new method to compute aligned wordembeddings for twenty-one languages using English as a pivot language. We show that some linguistic features are aligned across languages for which we do not have aligned data, even though those properties do not exist in the pivot language. We also achieve state of the art results on standard cross-lingual text classification and word translation tasks.