 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Agnostic Characterization of Fairness Trade-offs
Apr 08, 2020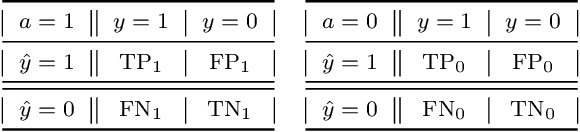
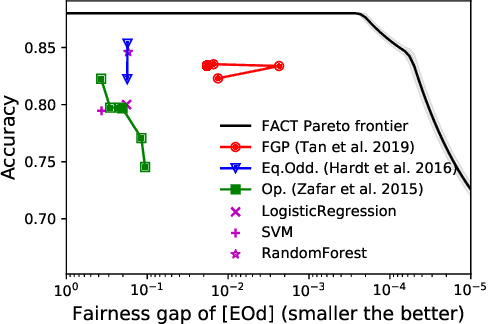

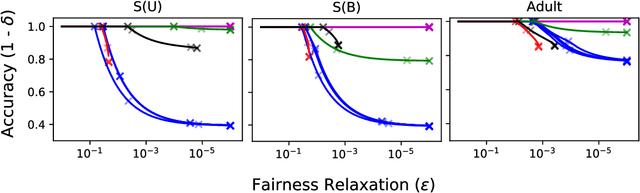
There exist several inherent trade-offs in designing a fair model, such as those between the model's predictive performance and fairness, or even among different notions of fairness. In practice, exploring these trade-offs requires significant human and computational resources. We propose a diagnostic that enables practitioners to explore these trade-offs without training a single model. Our work hinges on the observation that many widely-used fairness definitions can be expressed via the fairness-confusion tensor, an object obtained by splitting the traditional confusion matrix according to protected data attributes. Optimizing accuracy and fairness objectives directly over the elements in this tensor yields a data-dependent yet model-agnostic way of understanding several types of trade-offs. We further leverage this tensor-based perspective to generalize existing theoretical impossibility results to a wider range of fairness definitions. Finally, we demonstrate the usefulness of the proposed diagnostic on synthetic and real datasets.
Explaining Groups of Points in Low-Dimensional Representations
Mar 18, 2020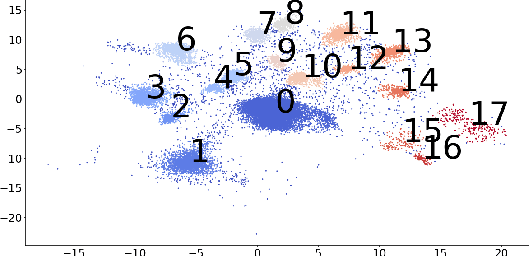
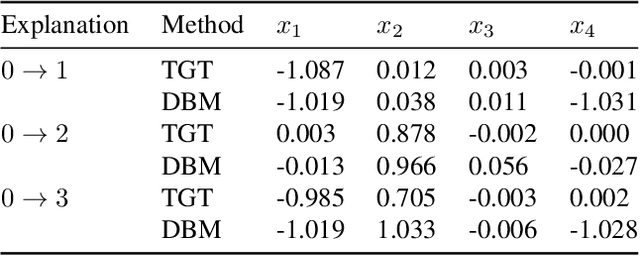
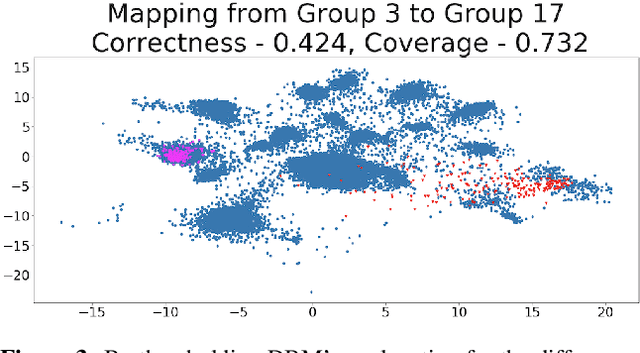
A common workflow in data exploration is to learn a low-dimensional representation of the data, identify groups of points in that representation, and examine the differences between the groups to determine what they represent. We treat this as an interpretable machine learning problem by leveraging the model that learned the low-dimensional representation to help identify the key differences between the groups. To solve this problem, we introduce a new type of explanation, a Global Counterfactual Explanation (GCE), and our algorithm, Transitive Global Translations (TGT), for computing GCEs. TGT identifies the differences between each pair of groups using compressed sensing but constrains those pairwise differences to be consistent among all of the groups. Empirically, we demonstrate that TGT is able to identify explanations that accurately explain the model while being relatively sparse, and that these explanations match real patterns in the data.
FedDANE: A Federated Newton-Type Method
Jan 07, 2020
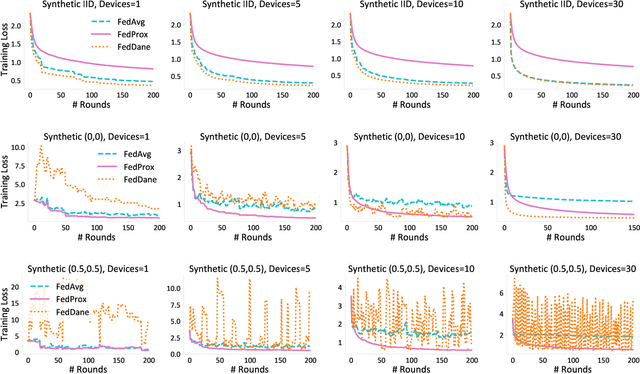
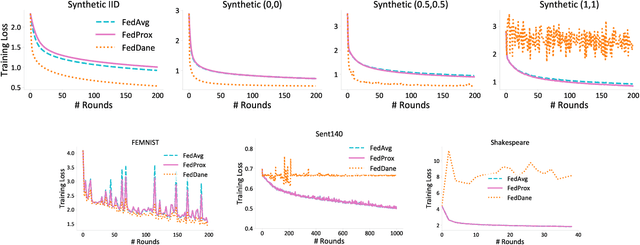
Federated learning aims to jointly learn statistical models over massively distributed remote devices. In this work, we propose FedDANE, an optimization method that we adapt from DANE, a method for classical distributed optimization, to handle the practical constraints of federated learning. We provide convergence guarantees for this method when learning over both convex and non-convex functions. Despite encouraging theoretical results, we find that the method has underwhelming performance empirically. In particular, through empirical simulations on both synthetic and real-world datasets, FedDANE consistently underperforms baselines of FedAvg and FedProx in realistic federated settings. We identify low device participation and statistical device heterogeneity as two underlying causes of this underwhelming performance, and conclude by suggesting several directions of future work.
Differentially Private Meta-Learning
Sep 12, 2019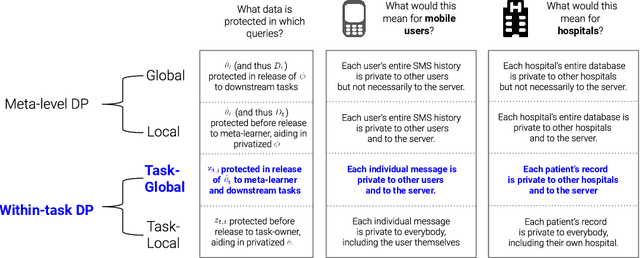
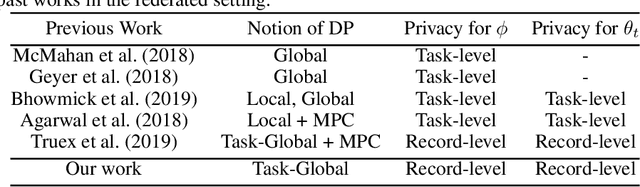
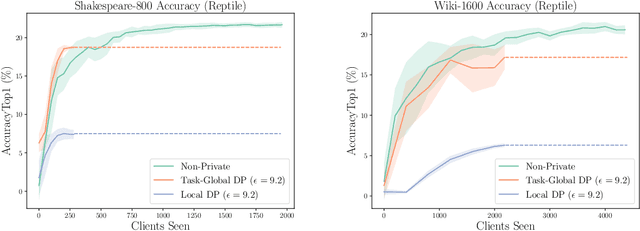
Parameter-transfer is a well-known and versatile approach for meta-learning, with applications including few-shot learning, federated learning, and reinforcement learning. However, parameter-transfer algorithms often require sharing models that have been trained on the samples from specific tasks, thus leaving the task-owners susceptible to breaches of privacy. We conduct the first formal study of privacy in this setting and formalize the notion of task-global differential privacy as a practical relaxation of more commonly studied threat models. We then propose a new differentially private algorithm for gradient-based parameter transfer that not only satisfies this privacy requirement but also retains provable transfer learning guarantees in convex settings. Empirically, we apply our analysis to the problem of federated learning with personalization and show that allowing the relaxation to task-global privacy from the more commonly studied notion of local privacy leads to dramatically increased performance in recurrent neural language modeling.
Federated Learning: Challenges, Methods, and Future Directions
Aug 21, 2019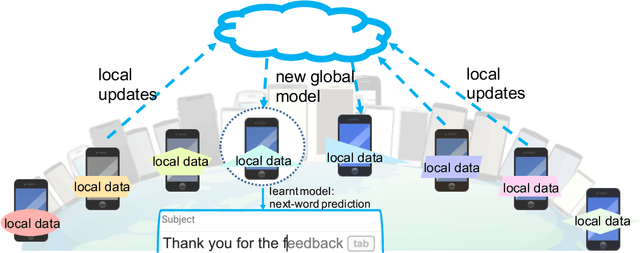

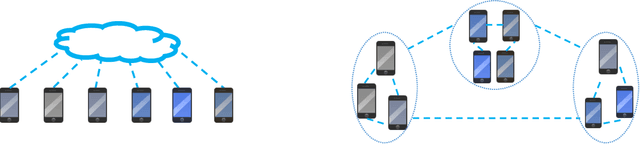
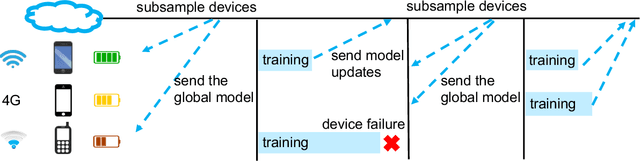
Federated learning involves training statistical models over remote devices or siloed data centers, such as mobile phones or hospitals, while keeping data localized. Training in heterogeneous and potentially massive networks introduces novel challenges that require a fundamental departure from standard approaches for large-scale machine learning, distributed optimization, and privacy-preserving data analysis. In this article, we discuss the unique characteristics and challenges of federated learning, provide a broad overview of current approaches, and outline several directions of future work that are relevant to a wide range of research communities.
Learning Fair Representations for Kernel Models
Jun 27, 2019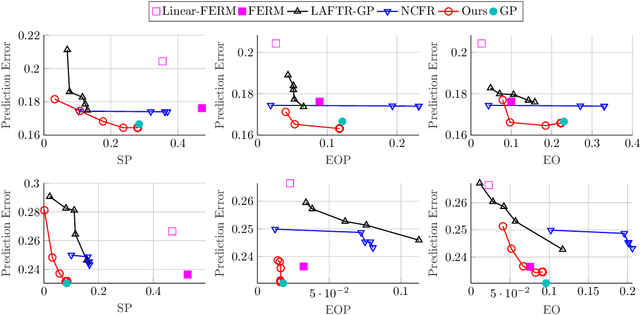
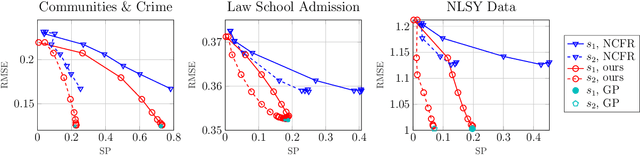
Fair representations are a powerful tool for establishing criteria like statistical parity, proxy non-discrimination, and equality of opportunity in learned models. Existing techniques for learning these representations are typically model-agnostic, as they preprocess the original data such that the output satisfies some fairness criterion, and can be used with arbitrary learning methods. In contrast, we demonstrate the promise of learning a model-aware fair representation, focusing on kernel-based models. We leverage the classical Sufficient Dimension Reduction (SDR) framework to construct representations as subspaces of the reproducing kernel Hilbert space (RKHS), whose member functions are guaranteed to satisfy fairness. Our method supports several fairness criteria, continuous and discrete data, and multiple protected attributes. We further show how to calibrate the accuracy tradeoff by characterizing it in terms of the principal angles between subspaces of the RKHS. Finally, we apply our approach to obtain the first Fair Gaussian Process (FGP) prior for fair Bayesian learning, and show that it is competitive with, and in some cases outperforms, state-of-the-art methods on real data.
Adaptive Gradient-Based Meta-Learning Methods
Jun 17, 2019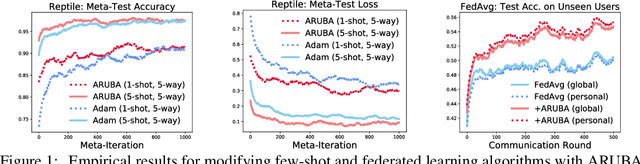
We build a theoretical framework for understanding practical meta-learning methods that enables the integration of sophisticated formalizations of task-similarity with the extensive literature on online convex optimization and sequential prediction algorithms. Our approach enables the task-similarity to be learned adaptively, provides sharper transfer-risk bounds in the setting of statistical learning-to-learn, and leads to straightforward derivations of average-case regret bounds for efficient algorithms in settings where the task-environment changes dynamically or the tasks share a certain geometric structure. We use our theory to modify several popular meta-learning algorithms and improve their training and meta-test-time performance on standard problems in few-shot and federated deep learning.
Regularizing Black-box Models for Improved Interpretability (HILL 2019 Version)
May 31, 2019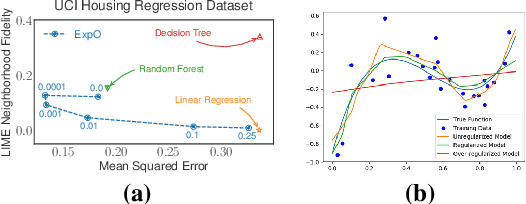
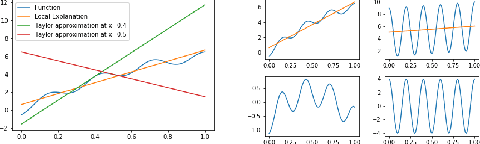
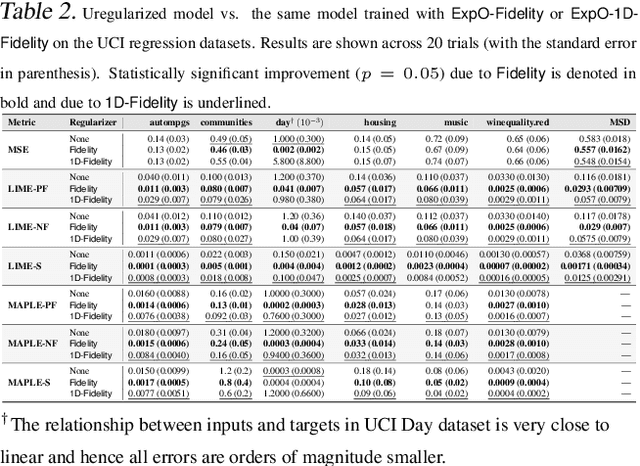
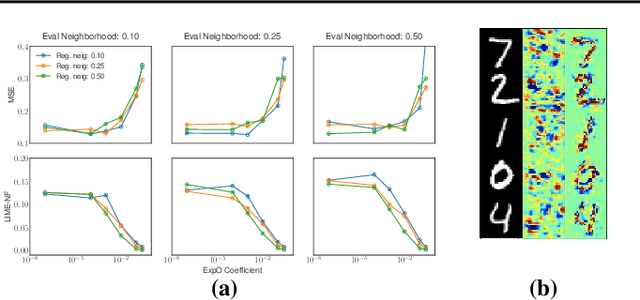
Most of the work on interpretable machine learning has focused on designing either inherently interpretable models, which typically trade-off accuracy for interpretability, or post-hoc explanation systems, which lack guarantees about their explanation quality. We propose an alternative to these approaches by directly regularizing a black-box model for interpretability at training time. Our approach explicitly connects three key aspects of interpretable machine learning: (i) the model's innate explainability, (ii) the explanation system used at test time, and (iii) the metrics that measure explanation quality. Our regularization results in substantial improvement in terms of the explanation fidelity and stability metrics across a range of datasets and black-box explanation systems while slightly improving accuracy. Further, if the resulting model is still not sufficiently interpretable, the weight of the regularization term can be adjusted to achieve the desired trade-off between accuracy and interpretability. Finally, we justify theoretically that the benefits of explanation-based regularization generalize to unseen points.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Exploiting Reuse in Pipeline-Aware Hyperparameter Tuning
Mar 12, 2019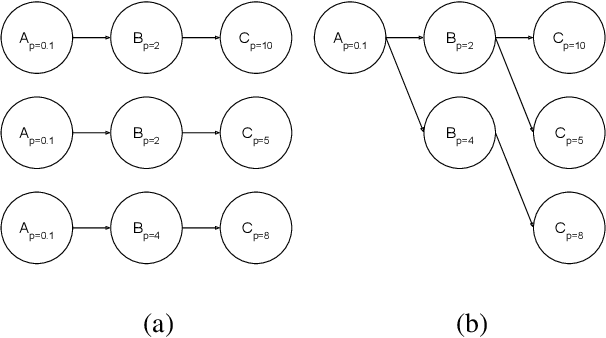
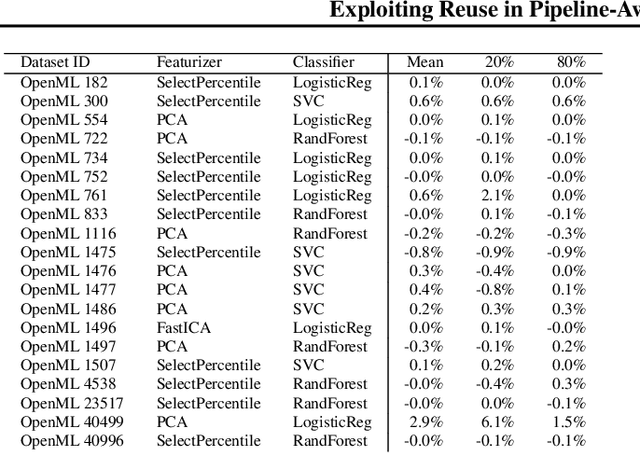
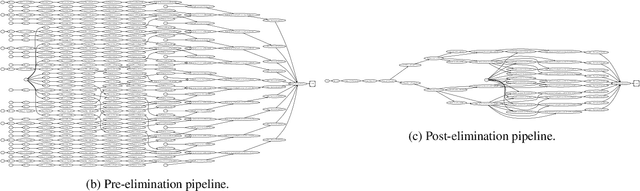
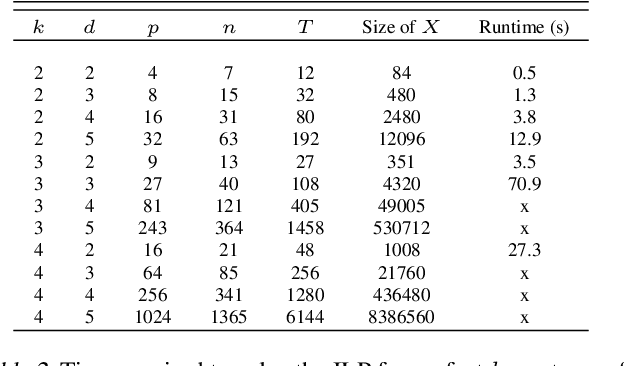
Hyperparameter tuning of multi-stage pipelines introduces a significant computational burden. Motivated by the observation that work can be reused across pipelines if the intermediate computations are the same, we propose a pipeline-aware approach to hyperparameter tuning. Our approach optimizes both the design and execution of pipelines to maximize reuse. We design pipelines amenable for reuse by (i) introducing a novel hybrid hyperparameter tuning method called gridded random search, and (ii) reducing the average training time in pipelines by adapting early-stopping hyperparameter tuning approaches. We then realize the potential for reuse during execution by introducing a novel caching problem for ML workloads which we pose as a mixed integer linear program (ILP), and subsequently evaluating various caching heuristics relative to the optimal solution of the ILP. We conduct experiments on simulated and real-world machine learning pipelines to show that a pipeline-aware approach to hyperparameter tuning can offer over an order-of-magnitude speedup over independently evaluating pipeline configurations.