 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Model Inversion Attacks
Jan 26, 2022
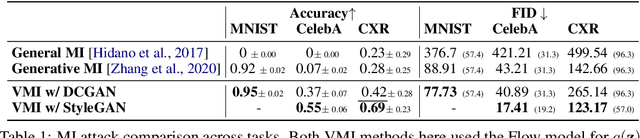

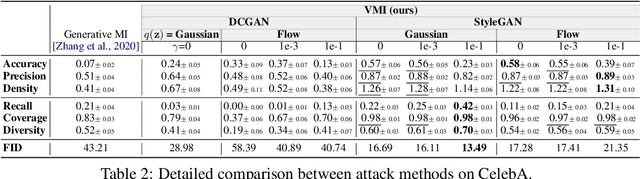
Given the ubiquity of deep neural networks, it is important that these models do not reveal information about sensitive data that they have been trained on. In model inversion attacks, a malicious user attempts to recover the private dataset used to train a supervised neural network. A successful model inversion attack should generate realistic and diverse samples that accurately describe each of the classes in the private dataset. In this work, we provide a probabilistic interpretation of model inversion attacks, and formulate a variational objective that accounts for both diversity and accuracy. In order to optimize this variational objective, we choose a variational family defined in the code space of a deep generative model, trained on a public auxiliary dataset that shares some structural similarity with the target dataset. Empirically, our method substantially improves performance in terms of target attack accuracy, sample realism, and diversity on datasets of faces and chest X-ray images.
Compressing Multisets with Large Alphabets
Jul 15, 2021
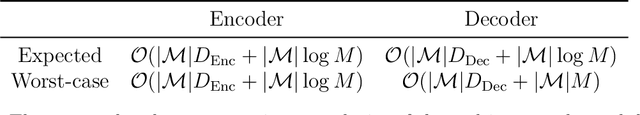
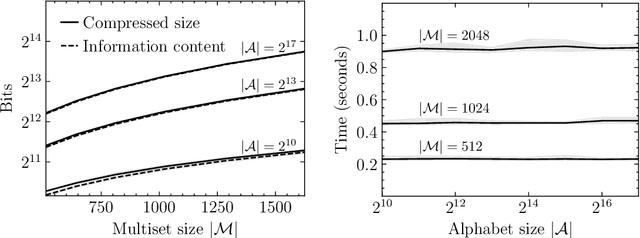
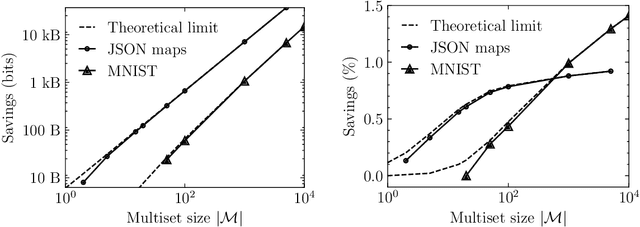
Current methods that optimally compress multisets are not suitable for high-dimensional symbols, as their compute time scales linearly with alphabet size. Compressing a multiset as an ordered sequence with off-the-shelf codecs is computationally more efficient, but has a sub-optimal compression rate, as bits are wasted encoding the order between symbols. We present a method that can recover those bits, assuming symbols are i.i.d., at the cost of an additional $\mathcal{O}(|\mathcal{M}|\log M)$ in average time complexity, where $|\mathcal{M}|$ and $M$ are the total and unique number of symbols in the multiset. Our method is compatible with any prefix-free code. Experiments show that, when paired with efficient coders, our method can efficiently compress high-dimensional sources such as multisets of images and collections of JSON files.
Improving Lossless Compression Rates via Monte Carlo Bits-Back Coding
Feb 22, 2021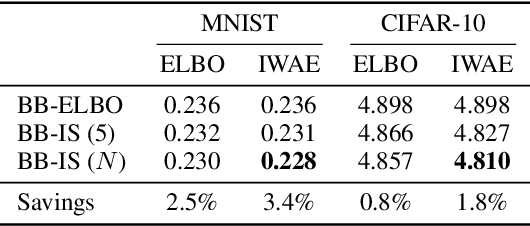
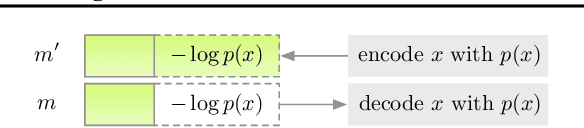
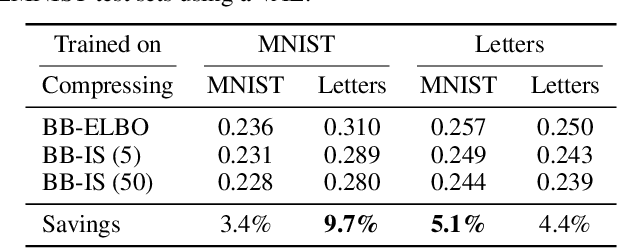
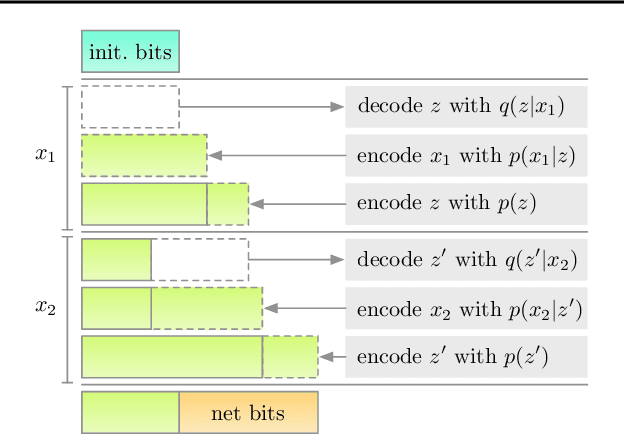
Latent variable models have been successfully applied in lossless compression with the bits-back coding algorithm. However, bits-back suffers from an increase in the bitrate equal to the KL divergence between the approximate posterior and the true posterior. In this paper, we show how to remove this gap asymptotically by deriving bits-back coding algorithms from tighter variational bounds. The key idea is to exploit extended space representations of Monte Carlo estimators of the marginal likelihood. Naively applied, our schemes would require more initial bits than the standard bits-back coder, but we show how to drastically reduce this additional cost with couplings in the latent space. When parallel architectures can be exploited, our coders can achieve better rates than bits-back with little additional cost. We demonstrate improved lossless compression rates in a variety of settings, including entropy coding for lossy compression.
Likelihood Ratio Exponential Families
Jan 15, 2021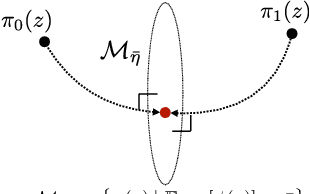
The exponential family is well known in machine learning and statistical physics as the maximum entropy distribution subject to a set of observed constraints, while the geometric mixture path is common in MCMC methods such as annealed importance sampling. Linking these two ideas, recent work has interpreted the geometric mixture path as an exponential family of distributions to analyze the thermodynamic variational objective (TVO). We extend these likelihood ratio exponential families to include solutions to rate-distortion (RD) optimization, the information bottleneck (IB) method, and recent rate-distortion-classification approaches which combine RD and IB. This provides a common mathematical framework for understanding these methods via the conjugate duality of exponential families and hypothesis testing. Further, we collect existing results to provide a variational representation of intermediate RD or TVO distributions as a minimizing an expectation of KL divergences. This solution also corresponds to a size-power tradeoff using the likelihood ratio test and the Neyman Pearson lemma. In thermodynamic integration bounds such as the TVO, we identify the intermediate distribution whose expected sufficient statistics match the log partition function.
Evaluating Lossy Compression Rates of Deep Generative Models
Aug 15, 2020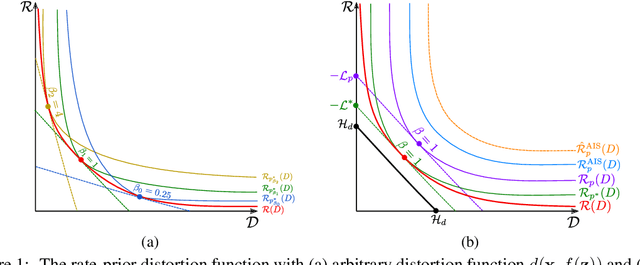
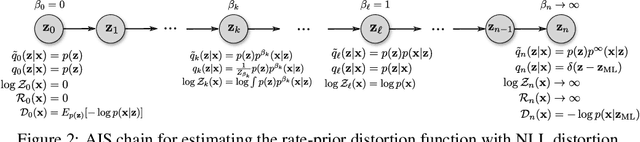
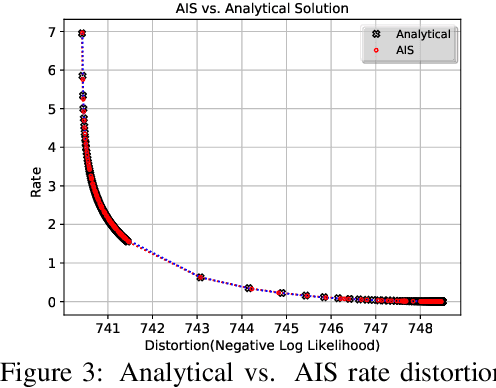
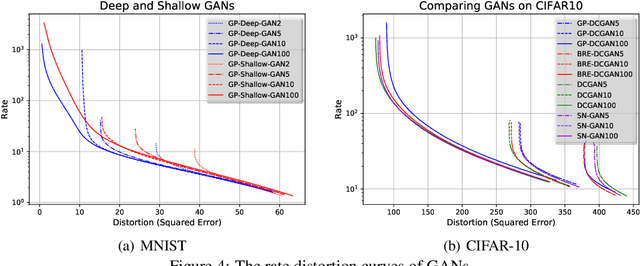
The field of deep generative modeling has succeeded in producing astonishingly realistic-seeming images and audio, but quantitative evaluation remains a challenge. Log-likelihood is an appealing metric due to its grounding in statistics and information theory, but it can be challenging to estimate for implicit generative models, and scalar-valued metrics give an incomplete picture of a model's quality. In this work, we propose to use rate distortion (RD) curves to evaluate and compare deep generative models. While estimating RD curves is seemingly even more computationally demanding than log-likelihood estimation, we show that we can approximate the entire RD curve using nearly the same computations as were previously used to achieve a single log-likelihood estimate. We evaluate lossy compression rates of VAEs, GANs, and adversarial autoencoders (AAEs) on the MNIST and CIFAR10 datasets. Measuring the entire RD curve gives a more complete picture than scalar-valued metrics, and we arrive at a number of insights not obtainable from log-likelihoods alone.
Implicit Autoencoders
May 24, 2018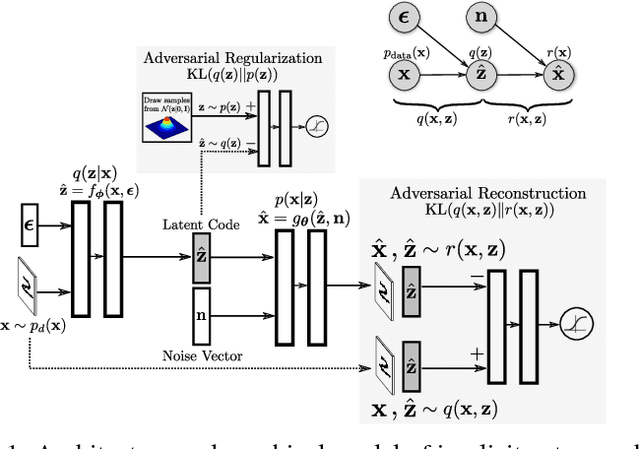



In this paper, we describe the "implicit autoencoder" (IAE), a generative autoencoder in which both the generative path and the recognition path are parametrized by implicit distributions. We use two generative adversarial networks to define the reconstruction and the regularization cost functions of the implicit autoencoder, and derive the learning rules based on maximum-likelihood learning. Using implicit distributions allows us to learn more expressive posterior and conditional likelihood distributions for the autoencoder. Learning an expressive conditional likelihood distribution enables the latent code to only capture the abstract and high-level information of the data, while the remaining information is captured by the implicit conditional likelihood distribution. For example, we show that implicit autoencoders can disentangle the global and local information, and perform deterministic or stochastic reconstructions of the images. We further show that implicit autoencoders can disentangle discrete underlying factors of variation from the continuous factors in an unsupervised fashion, and perform clustering and semi-supervised learning.
StarCraft II: A New Challenge for Reinforcement Learning
Aug 16, 2017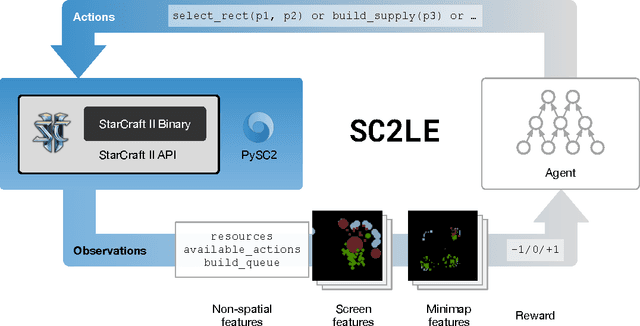
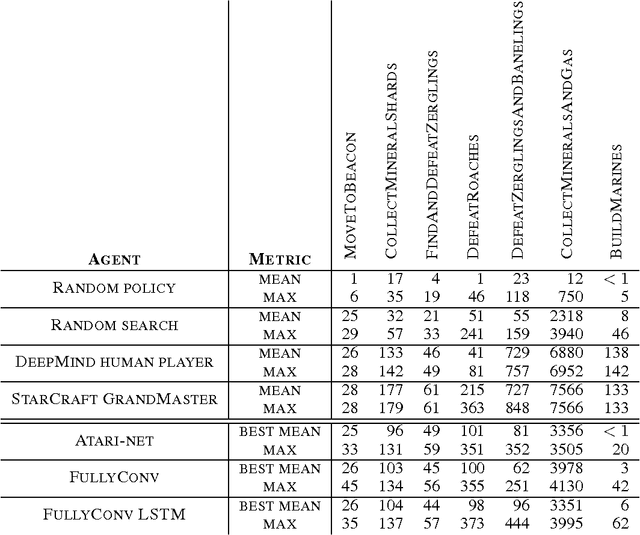

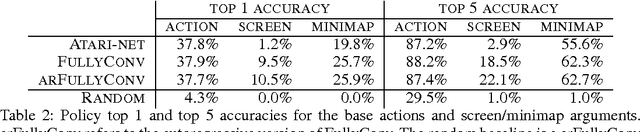
This paper introduces SC2LE (StarCraft II Learning Environment), a reinforcement learning environment based on the StarCraft II game. This domain poses a new grand challenge for reinforcement learning, representing a more difficult class of problems than considered in most prior work. It is a multi-agent problem with multiple players interacting; there is imperfect information due to a partially observed map; it has a large action space involving the selection and control of hundreds of units; it has a large state space that must be observed solely from raw input feature planes; and it has delayed credit assignment requiring long-term strategies over thousands of steps. We describe the observation, action, and reward specification for the StarCraft II domain and provide an open source Python-based interface for communicating with the game engine. In addition to the main game maps, we provide a suite of mini-games focusing on different elements of StarCraft II gameplay. For the main game maps, we also provide an accompanying dataset of game replay data from human expert players. We give initial baseline results for neural networks trained from this data to predict game outcomes and player actions. Finally, we present initial baseline results for canonical deep reinforcement learning agents applied to the StarCraft II domain. On the mini-games, these agents learn to achieve a level of play that is comparable to a novice player. However, when trained on the main game, these agents are unable to make significant progress. Thus, SC2LE offers a new and challenging environment for exploring deep reinforcement learning algorithms and architectures.
PixelGAN Autoencoders
Jun 02, 2017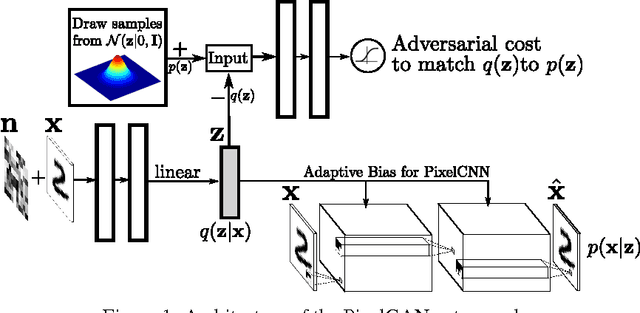
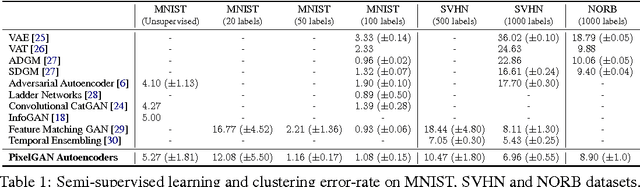

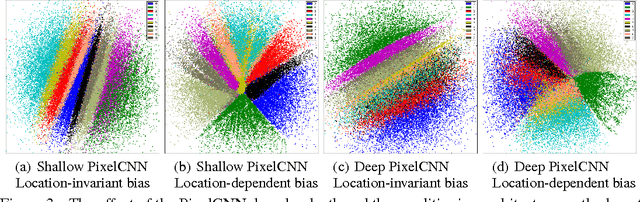
In this paper, we describe the "PixelGAN autoencoder", a generative autoencoder in which the generative path is a convolutional autoregressive neural network on pixels (PixelCNN) that is conditioned on a latent code, and the recognition path uses a generative adversarial network (GAN) to impose a prior distribution on the latent code. We show that different priors result in different decompositions of information between the latent code and the autoregressive decoder. For example, by imposing a Gaussian distribution as the prior, we can achieve a global vs. local decomposition, or by imposing a categorical distribution as the prior, we can disentangle the style and content information of images in an unsupervised fashion. We further show how the PixelGAN autoencoder with a categorical prior can be directly used in semi-supervised settings and achieve competitive semi-supervised classification results on the MNIST, SVHN and NORB datasets.
Adversarial Autoencoders
May 25, 2016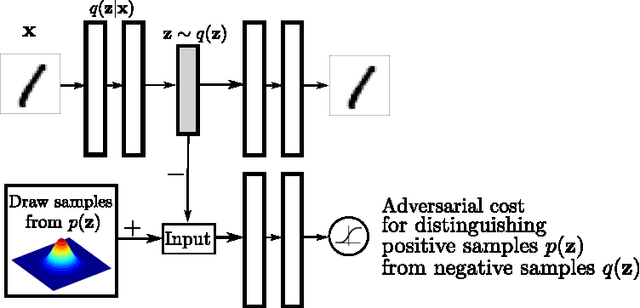
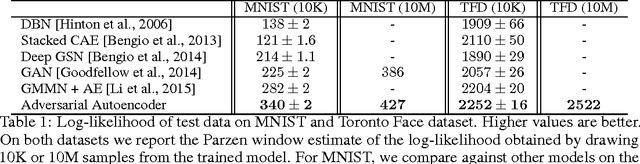
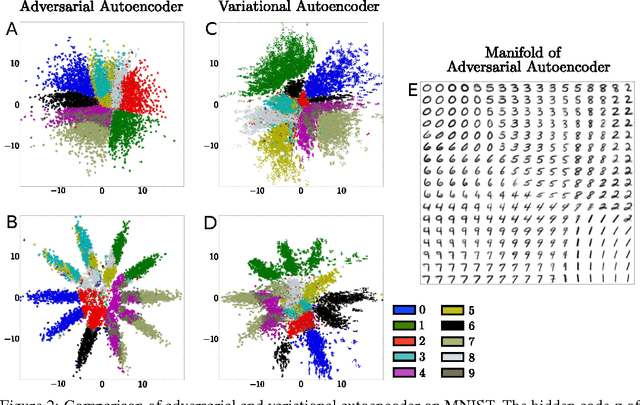
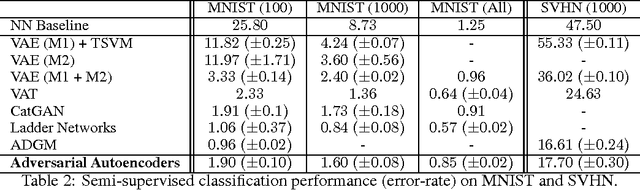
In this paper, we propose the "adversarial autoencoder" (AAE), which is a probabilistic autoencoder that uses the recently proposed generative adversarial networks (GAN) to perform variational inference by matching the aggregated posterior of the hidden code vector of the autoencoder with an arbitrary prior distribution. Matching the aggregated posterior to the prior ensures that generating from any part of prior space results in meaningful samples. As a result, the decoder of the adversarial autoencoder learns a deep generative model that maps the imposed prior to the data distribution. We show how the adversarial autoencoder can be used in applications such as semi-supervised classification, disentangling style and content of images, unsupervised clustering, dimensionality reduction and data visualization. We performed experiments on MNIST, Street View House Numbers and Toronto Face datasets and show that adversarial autoencoders achieve competitive results in generative modeling and semi-supervised classification tasks.
Winner-Take-All Autoencoders
Jun 07, 2015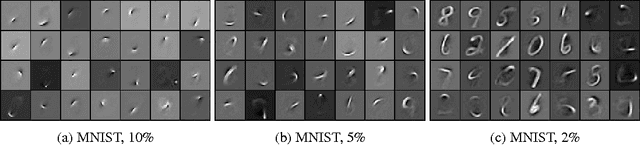


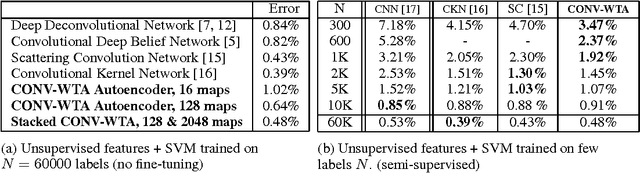
In this paper, we propose a winner-take-all method for learning hierarchical sparse representations in an unsupervised fashion. We first introduce fully-connected winner-take-all autoencoders which use mini-batch statistics to directly enforce a lifetime sparsity in the activations of the hidden units. We then propose the convolutional winner-take-all autoencoder which combines the benefits of convolutional architectures and autoencoders for learning shift-invariant sparse representations. We describe a way to train convolutional autoencoders layer by layer, where in addition to lifetime sparsity, a spatial sparsity within each feature map is achieved using winner-take-all activation functions. We will show that winner-take-all autoencoders can be used to to learn deep sparse representations from the MNIST, CIFAR-10, ImageNet, Street View House Numbers and Toronto Face datasets, and achieve competitive classification performance.