 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA View From Somewhere: Human-Centric Face Representations
Mar 30, 2023



Few datasets contain self-identified sensitive attributes, inferring attributes risks introducing additional biases, and collecting attributes can carry legal risks. Besides, categorical labels can fail to reflect the continuous nature of human phenotypic diversity, making it difficult to compare the similarity between same-labeled faces. To address these issues, we present A View From Somewhere (AVFS) -- a dataset of 638,180 human judgments of face similarity. We demonstrate the utility of AVFS for learning a continuous, low-dimensional embedding space aligned with human perception. Our embedding space, induced under a novel conditional framework, not only enables the accurate prediction of face similarity, but also provides a human-interpretable decomposition of the dimensions used in the human-decision making process, and the importance distinct annotators place on each dimension. We additionally show the practicality of the dimensions for collecting continuous attributes, performing classification, and comparing dataset attribute disparities.
Ethical Considerations for Collecting Human-Centric Image Datasets
Feb 07, 2023
Human-centric image datasets are critical to the development of computer vision technologies. However, recent investigations have foregrounded significant ethical issues related to privacy and bias, which have resulted in the complete retraction, or modification, of several prominent datasets. Recent works have tried to reverse this trend, for example, by proposing analytical frameworks for ethically evaluating datasets, the standardization of dataset documentation and curation practices, privacy preservation methodologies, as well as tools for surfacing and mitigating representational biases. Little attention, however, has been paid to the realities of operationalizing ethical data collection. To fill this gap, we present a set of key ethical considerations and practical recommendations for collecting more ethically-minded human-centric image data. Our research directly addresses issues of privacy and bias by contributing to the research community best practices for ethical data collection, covering purpose, privacy and consent, as well as diversity. We motivate each consideration by drawing on lessons from current practices, dataset withdrawals and audits, and analytical ethical frameworks. Our research is intended to augment recent scholarship, representing an important step toward more responsible data curation practices.
From Single-Visit to Multi-Visit Image-Based Models: Single-Visit Models are Enough to Predict Obstructive Hydronephrosis
Dec 27, 2022Previous work has shown the potential of deep learning to predict renal obstruction using kidney ultrasound images. However, these image-based classifiers have been trained with the goal of single-visit inference in mind. We compare methods from video action recognition (i.e. convolutional pooling, LSTM, TSM) to adapt single-visit convolutional models to handle multiple visit inference. We demonstrate that incorporating images from a patient's past hospital visits provides only a small benefit for the prediction of obstructive hydronephrosis. Therefore, inclusion of prior ultrasounds is beneficial, but prediction based on the latest ultrasound is sufficient for patient risk stratification.
Towards the Use of Saliency Maps for Explaining Low-Quality Electrocardiograms to End Users
Jul 06, 2022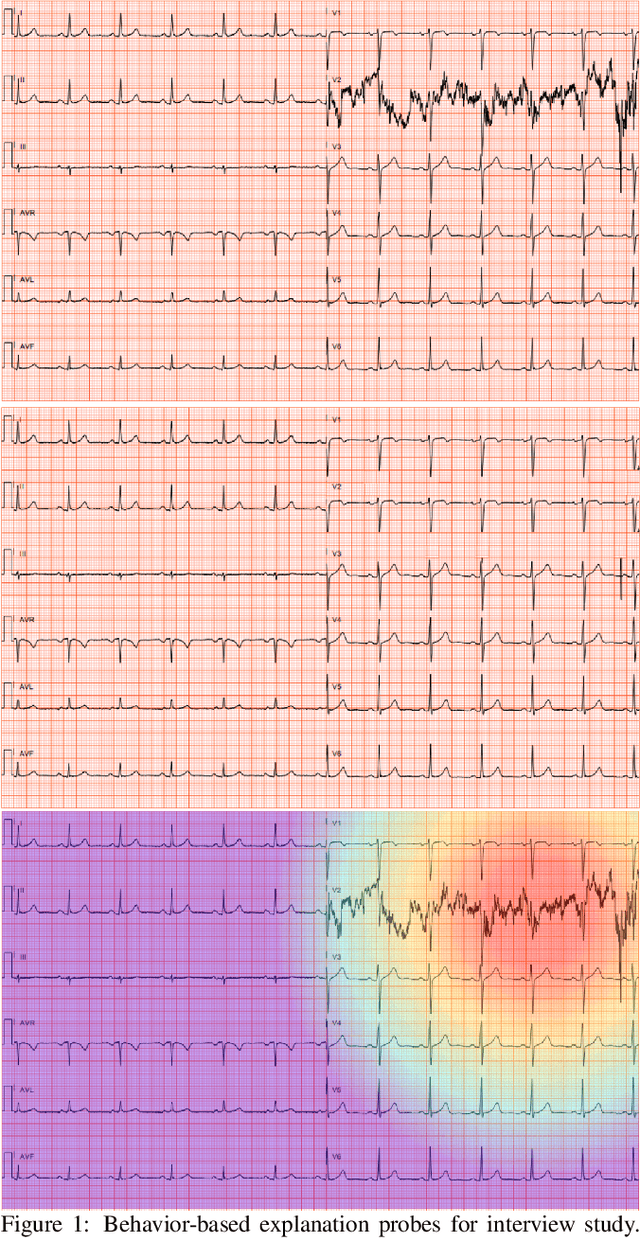

When using medical images for diagnosis, either by clinicians or artificial intelligence (AI) systems, it is important that the images are of high quality. When an image is of low quality, the medical exam that produced the image often needs to be redone. In telemedicine, a common problem is that the quality issue is only flagged once the patient has left the clinic, meaning they must return in order to have the exam redone. This can be especially difficult for people living in remote regions, who make up a substantial portion of the patients at Portal Telemedicina, a digital healthcare organization based in Brazil. In this paper, we report on ongoing work regarding (i) the development of an AI system for flagging and explaining low-quality medical images in real-time, (ii) an interview study to understand the explanation needs of stakeholders using the AI system at OurCompany, and, (iii) a longitudinal user study design to examine the effect of including explanations on the workflow of the technicians in our clinics. To the best of our knowledge, this would be the first longitudinal study on evaluating the effects of XAI methods on end-users -- stakeholders that use AI systems but do not have AI-specific expertise. We welcome feedback and suggestions on our experimental setup.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Regulating Facial Processing Technologies: Tensions Between Legal and Technical Considerations in the Application of Illinois BIPA
May 15, 2022Harms resulting from the development and deployment of facial processing technologies (FPT) have been met with increasing controversy. Several states and cities in the U.S. have banned the use of facial recognition by law enforcement and governments, but FPT are still being developed and used in a wide variety of contexts where they primarily are regulated by state biometric information privacy laws. Among these laws, the 2008 Illinois Biometric Information Privacy Act (BIPA) has generated a significant amount of litigation. Yet, with most BIPA lawsuits reaching settlements before there have been meaningful clarifications of relevant technical intricacies and legal definitions, there remains a great degree of uncertainty as to how exactly this law applies to FPT. What we have found through applications of BIPA in FPT litigation so far, however, points to potential disconnects between technical and legal communities. This paper analyzes what we know based on BIPA court proceedings and highlights these points of tension: areas where the technical operationalization of BIPA may create unintended and undesirable incentives for FPT development, as well as areas where BIPA litigation can bring to light the limitations of solely technical methods in achieving legal privacy values. These factors are relevant for (i) reasoning about biometric information privacy laws as a governing mechanism for FPT, (ii) assessing the potential harms of FPT, and (iii) providing incentives for the mitigation of these harms. By illuminating these considerations, we hope to empower courts and lawmakers to take a more nuanced approach to regulating FPT and developers to better understand privacy values in the current U.S. legal landscape.
Promises and Challenges of Causality for Ethical Machine Learning
Jan 26, 2022In recent years, there has been increasing interest in causal reasoning for designing fair decision-making systems due to its compatibility with legal frameworks, interpretability for human stakeholders, and robustness to spurious correlations inherent in observational data, among other factors. The recent attention to causal fairness, however, has been accompanied with great skepticism due to practical and epistemological challenges with applying current causal fairness approaches in the literature. Motivated by the long-standing empirical work on causality in econometrics, social sciences, and biomedical sciences, in this paper we lay out the conditions for appropriate application of causal fairness under the "potential outcomes framework." We highlight key aspects of causal inference that are often ignored in the causal fairness literature. In particular, we discuss the importance of specifying the nature and timing of interventions on social categories such as race or gender. Precisely, instead of postulating an intervention on immutable attributes, we propose a shift in focus to their perceptions and discuss the implications for fairness evaluation. We argue that such conceptualization of the intervention is key in evaluating the validity of causal assumptions and conducting sound causal analysis including avoiding post-treatment bias. Subsequently, we illustrate how causality can address the limitations of existing fairness metrics, including those that depend upon statistical correlations. Specifically, we introduce causal variants of common statistical notions of fairness, and we make a novel observation that under the causal framework there is no fundamental disagreement between different notions of fairness. Finally, we conduct extensive experiments where we demonstrate our approach for evaluating and mitigating unfairness, specially when post-treatment variables are present.
Affirmative Algorithms: The Legal Grounds for Fairness as Awareness
Dec 18, 2020
While there has been a flurry of research in algorithmic fairness, what is less recognized is that modern antidiscrimination law may prohibit the adoption of such techniques. We make three contributions. First, we discuss how such approaches will likely be deemed "algorithmic affirmative action," posing serious legal risks of violating equal protection, particularly under the higher education jurisprudence. Such cases have increasingly turned toward anticlassification, demanding "individualized consideration" and barring formal, quantitative weights for race regardless of purpose. This case law is hence fundamentally incompatible with fairness in machine learning. Second, we argue that the government-contracting cases offer an alternative grounding for algorithmic fairness, as these cases permit explicit and quantitative race-based remedies based on historical discrimination by the actor. Third, while limited, this doctrinal approach also guides the future of algorithmic fairness, mandating that adjustments be calibrated to the entity's responsibility for historical discrimination causing present-day disparities. The contractor cases provide a legally viable path for algorithmic fairness under current constitutional doctrine but call for more research at the intersection of algorithmic fairness and causal inference to ensure that bias mitigation is tailored to specific causes and mechanisms of bias.
* 12 pages, 3 figures
Uncertainty as a Form of Transparency: Measuring, Communicating, and Using Uncertainty
Nov 15, 2020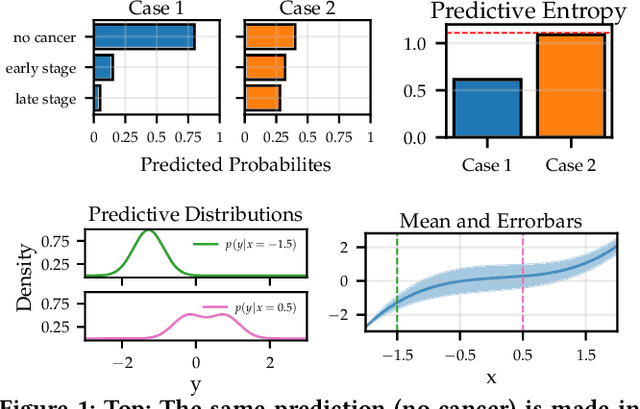

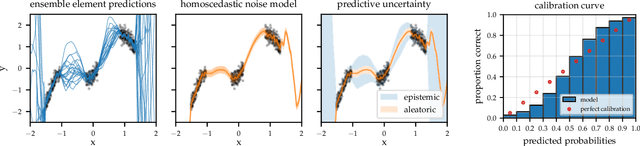
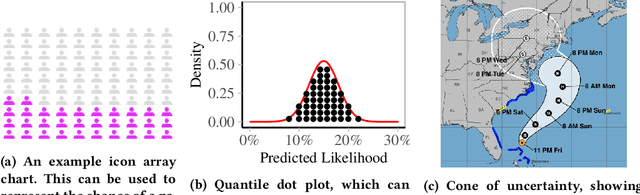
Transparency of algorithmic systems entails exposing system properties to various stakeholders for purposes that include understanding, improving, and/or contesting predictions. The machine learning (ML) community has mostly considered explainability as a proxy for transparency. With this work, we seek to encourage researchers to study uncertainty as a form of transparency and practitioners to communicate uncertainty estimates to stakeholders. First, we discuss methods for assessing uncertainty. Then, we describe the utility of uncertainty for mitigating model unfairness, augmenting decision-making, and building trustworthy systems. We also review methods for displaying uncertainty to stakeholders and discuss how to collect information required for incorporating uncertainty into existing ML pipelines. Our contribution is an interdisciplinary review to inform how to measure, communicate, and use uncertainty as a form of transparency.
"What We Can't Measure, We Can't Understand": Challenges to Demographic Data Procurement in the Pursuit of Fairness
Oct 30, 2020

As calls for fair and unbiased algorithmic systems increase, so too does the number of individuals working on algorithmic fairness in industry. However, these practitioners often do not have access to the demographic data they feel they need to detect bias in practice. Even with the growing variety of toolkits and strategies for working towards algorithmic fairness, they almost invariably require access to demographic attributes or proxies. We investigated this dilemma through semi-structured interviews with 38 practitioners and professionals either working in or adjacent to algorithmic fairness. Participants painted a complex picture of what demographic data availability and use look like on the ground, ranging from not having access to personal data of any kind to being legally required to collect and use demographic data for discrimination assessments. In many domains, demographic data collection raises a host of difficult questions, including how to balance privacy and fairness, how to define relevant social categories, how to ensure meaningful consent, and whether it is appropriate for private companies to infer someone's demographics. Our research suggests challenges that must be considered by businesses, regulators, researchers, and community groups in order to enable practitioners to address algorithmic bias in practice. Critically, we do not propose that the overall goal of future work should be to simply lower the barriers to collecting demographic data. Rather, our study surfaces a swath of normative questions about how, when, and even whether this data should be collected.