 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Weather Temperature Prediction
Jan 25, 2018

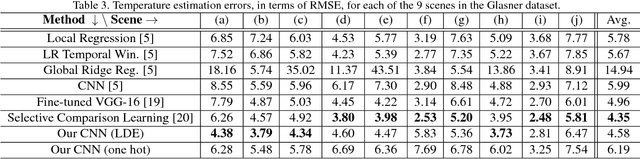
In this paper, we attempt to employ convolutional recurrent neural networks for weather temperature estimation using only image data. We study ambient temperature estimation based on deep neural networks in two scenarios a) estimating temperature of a single outdoor image, and b) predicting temperature of the last image in an image sequence. In the first scenario, visual features are extracted by a convolutional neural network trained on a large-scale image dataset. We demonstrate that promising performance can be obtained, and analyze how volume of training data influences performance. In the second scenario, we consider the temporal evolution of visual appearance, and construct a recurrent neural network to predict the temperature of the last image in a given image sequence. We obtain better prediction accuracy compared to the state-of-the-art models. Further, we investigate how performance varies when information is extracted from different scene regions, and when images are captured in different daytime hours. Our approach further reinforces the idea of using only visual information for cost efficient weather prediction in the future.
Segmenting Sky Pixels in Images
Jan 08, 2018
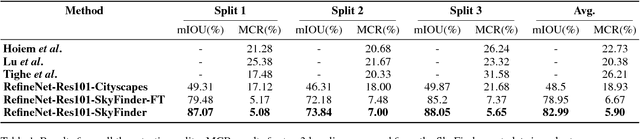


Outdoor scene parsing models are often trained on ideal datasets and produce quality results. However, this leads to a discrepancy when applied to the real world. The quality of scene parsing, particularly sky classification, decreases in night time images, images involving varying weather conditions, and scene changes due to seasonal weather. This project focuses on approaching these challenges by using a state-of-the-art model in conjunction with a non-ideal dataset: SkyFinder and a subset from SUN database with Sky object. We focus specifically on sky segmentation, the task of determining sky and not-sky pixels, and improving upon an existing state-of-the-art model: RefineNet. As a result of our efforts, we have seen an improvement of 10-15% in the average MCR compared to the prior methods on SkyFinder dataset. We have also improved from an off-the shelf-model in terms of average mIOU by nearly 35%. Further, we analyze our trained models on images w.r.t two aspects: times of day and weather, and find that, in spite of facing same challenges as prior methods, our trained models significantly outperform them.
Human-like Clustering with Deep Convolutional Neural Networks
Dec 11, 2017
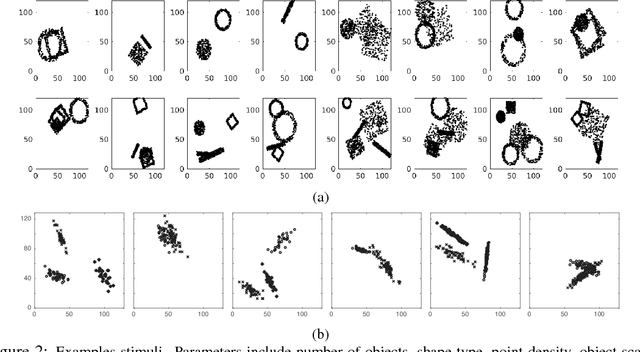
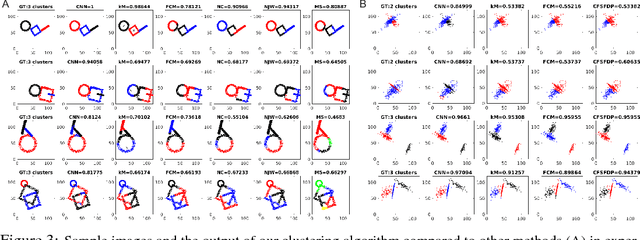
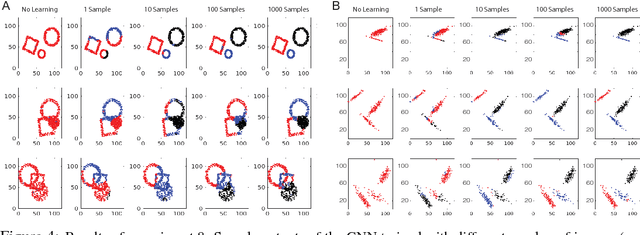
Classification and clustering have been studied separately in machine learning and computer vision. Inspired by the recent success of deep learning models in solving various vision problems (e.g., object recognition, semantic segmentation) and the fact that humans serve as the gold standard in assessing clustering algorithms, here, we advocate for a unified treatment of the two problems and suggest that hierarchical frameworks that progressively build complex patterns on top of the simpler ones (e.g., convolutional neural networks) offer a promising solution. We do not dwell much on the learning mechanisms in these frameworks as they are still a matter of debate, with respect to biological constraints. Instead, we emphasize on the compositionality of the real world structures and objects. In particular, we show that CNNs, trained end to end using back propagation with noisy labels, are able to cluster data points belonging to several overlapping shapes, and do so much better than the state of the art algorithms. The main takeaway lesson from our study is that mechanisms of human vision, particularly the hierarchal organization of the visual ventral stream should be taken into account in clustering algorithms (e.g., for learning representations in an unsupervised manner or with minimum supervision) to reach human level clustering performance. This, by no means, suggests that other methods do not hold merits. For example, methods relying on pairwise affinities (e.g., spectral clustering) have been very successful in many scenarios but still fail in some cases (e.g., overlapping clusters).
An Unsupervised Game-Theoretic Approach to Saliency Detection
Aug 08, 2017
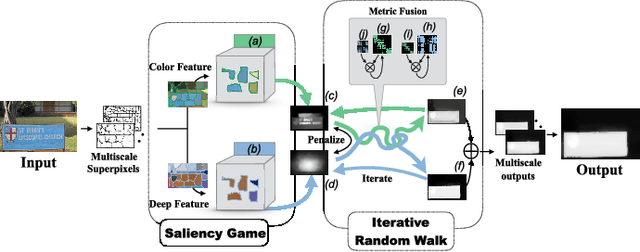


We propose a novel unsupervised game-theoretic salient object detection algorithm that does not require labeled training data. First, saliency detection problem is formulated as a non-cooperative game, hereinafter referred to as Saliency Game, in which image regions are players who choose to be "background" or "foreground" as their pure strategies. A payoff function is constructed by exploiting multiple cues and combining complementary features. Saliency maps are generated according to each region's strategy in the Nash equilibrium of the proposed Saliency Game. Second, we explore the complementary relationship between color and deep features and propose an Iterative Random Walk algorithm to combine saliency maps produced by the Saliency Game using different features. Iterative random walk allows sharing information across feature spaces, and detecting objects that are otherwise very hard to detect. Extensive experiments over 6 challenging datasets demonstrate the superiority of our proposed unsupervised algorithm compared to several state of the art supervised algorithms.
Paying Attention to Descriptions Generated by Image Captioning Models
Aug 04, 2017
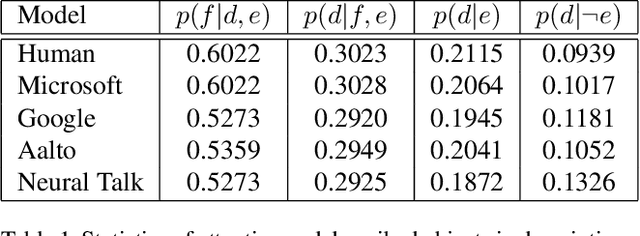
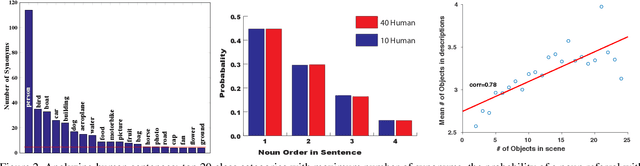
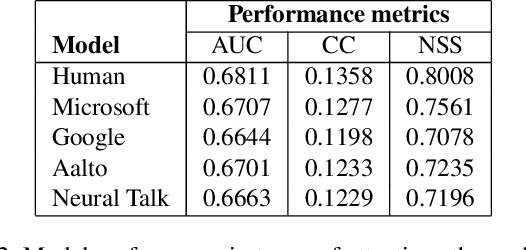
To bridge the gap between humans and machines in image understanding and describing, we need further insight into how people describe a perceived scene. In this paper, we study the agreement between bottom-up saliency-based visual attention and object referrals in scene description constructs. We investigate the properties of human-written descriptions and machine-generated ones. We then propose a saliency-boosted image captioning model in order to investigate benefits from low-level cues in language models. We learn that (1) humans mention more salient objects earlier than less salient ones in their descriptions, (2) the better a captioning model performs, the better attention agreement it has with human descriptions, (3) the proposed saliency-boosted model, compared to its baseline form, does not improve significantly on the MS COCO database, indicating explicit bottom-up boosting does not help when the task is well learnt and tuned on a data, (4) a better generalization is, however, observed for the saliency-boosted model on unseen data.
Structure-measure: A New Way to Evaluate Foreground Maps
Aug 02, 2017

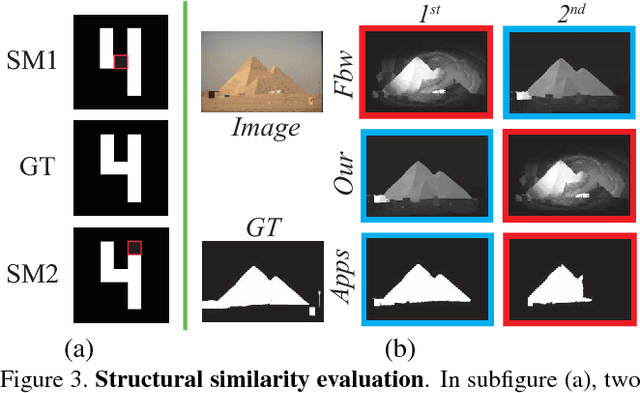
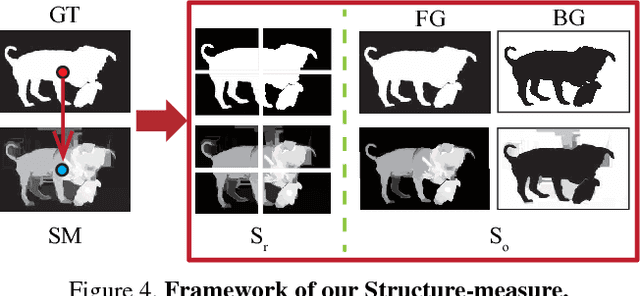
Foreground map evaluation is crucial for gauging the progress of object segmentation algorithms, in particular in the filed of salient object detection where the purpose is to accurately detect and segment the most salient object in a scene. Several widely-used measures such as Area Under the Curve (AUC), Average Precision (AP) and the recently proposed Fbw have been utilized to evaluate the similarity between a non-binary saliency map (SM) and a ground-truth (GT) map. These measures are based on pixel-wise errors and often ignore the structural similarities. Behavioral vision studies, however, have shown that the human visual system is highly sensitive to structures in scenes. Here, we propose a novel, efficient, and easy to calculate measure known an structural similarity measure (Structure-measure) to evaluate non-binary foreground maps. Our new measure simultaneously evaluates region-aware and object-aware structural similarity between a SM and a GT map. We demonstrate superiority of our measure over existing ones using 5 meta-measures on 5 benchmark datasets.
A Review of Co-saliency Detection Technique: Fundamentals, Applications, and Challenges
Jul 09, 2017



Co-saliency detection is a newly emerging and rapidly growing research area in computer vision community. As a novel branch of visual saliency, co-saliency detection refers to the discovery of common and salient foregrounds from two or more relevant images, and can be widely used in many computer vision tasks. The existing co-saliency detection algorithms mainly consist of three components: extracting effective features to represent the image regions, exploring the informative cues or factors to characterize co-saliency, and designing effective computational frameworks to formulate co-saliency. Although numerous methods have been developed, the literature is still lacking a deep review and evaluation of co-saliency detection techniques. In this paper, we aim at providing a comprehensive review of the fundamentals, challenges, and applications of co-saliency detection. Specifically, we provide an overview of some related computer vision works, review the history of co-saliency detection, summarize and categorize the major algorithms in this research area, discuss some open issues in this area, present the potential applications of co-saliency detection, and finally point out some unsolved challenges and promising future works. We expect this review to be beneficial to both fresh and senior researchers in this field, and give insights to researchers in other related areas regarding the utility of co-saliency detection algorithms.
Negative Results in Computer Vision: A Perspective
Jun 06, 2017A negative result is when the outcome of an experiment or a model is not what is expected or when a hypothesis does not hold. Despite being often overlooked in the scientific community, negative results are results and they carry value. While this topic has been extensively discussed in other fields such as social sciences and biosciences, less attention has been paid to it in the computer vision community. The unique characteristics of computer vision, particularly its experimental aspect, call for a special treatment of this matter. In this paper, I will address what makes negative results important, how they should be disseminated and incentivized, and what lessons can be learned from cognitive vision research in this regard. Further, I will discuss issues such as computer vision and human vision interaction, experimental design and statistical hypothesis testing, explanatory versus predictive modeling, performance evaluation, model comparison, as well as computer vision research culture.
Saliency Revisited: Analysis of Mouse Movements versus Fixations
May 30, 2017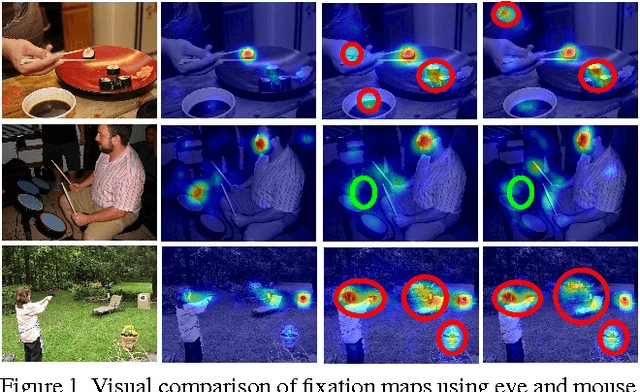
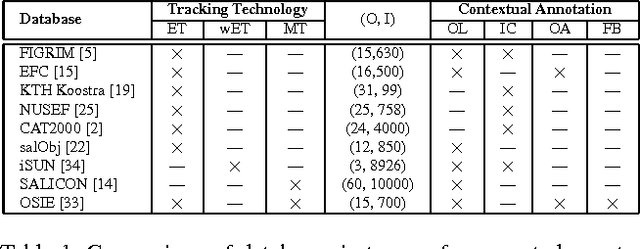
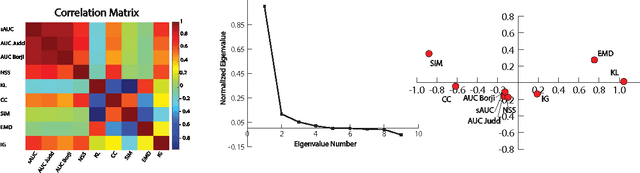

This paper revisits visual saliency prediction by evaluating the recent advancements in this field such as crowd-sourced mouse tracking-based databases and contextual annotations. We pursue a critical and quantitative approach towards some of the new challenges including the quality of mouse tracking versus eye tracking for model training and evaluation. We extend quantitative evaluation of models in order to incorporate contextual information by proposing an evaluation methodology that allows accounting for contextual factors such as text, faces, and object attributes. The proposed contextual evaluation scheme facilitates detailed analysis of models and helps identify their pros and cons. Through several experiments, we find that (1) mouse tracking data has lower inter-participant visual congruency and higher dispersion, compared to the eye tracking data, (2) mouse tracking data does not totally agree with eye tracking in general and in terms of different contextual regions in specific, and (3) mouse tracking data leads to acceptable results in training current existing models, and (4) mouse tracking data is less reliable for model selection and evaluation. The contextual evaluation also reveals that, among the studied models, there is no single model that performs best on all the tested annotations.
Learning to predict where to look in interactive environments using deep recurrent q-learning
Feb 18, 2017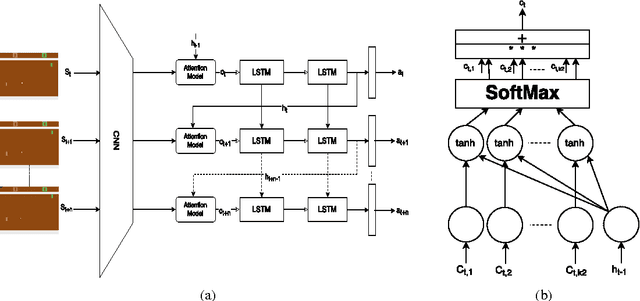
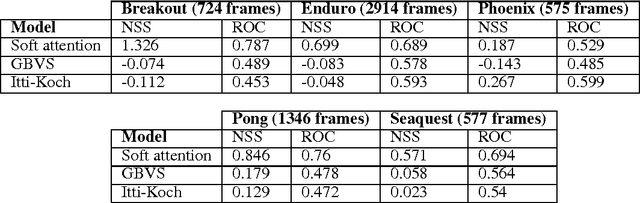


Bottom-Up (BU) saliency models do not perform well in complex interactive environments where humans are actively engaged in tasks (e.g., sandwich making and playing the video games). In this paper, we leverage Reinforcement Learning (RL) to highlight task-relevant locations of input frames. We propose a soft attention mechanism combined with the Deep Q-Network (DQN) model to teach an RL agent how to play a game and where to look by focusing on the most pertinent parts of its visual input. Our evaluations on several Atari 2600 games show that the soft attention based model could predict fixation locations significantly better than bottom-up models such as Itti-Kochs saliency and Graph-Based Visual Saliency (GBVS) models.