 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Saliency Evaluation Metric Using Crowdsourced Perceptual Judgments
Jun 27, 2018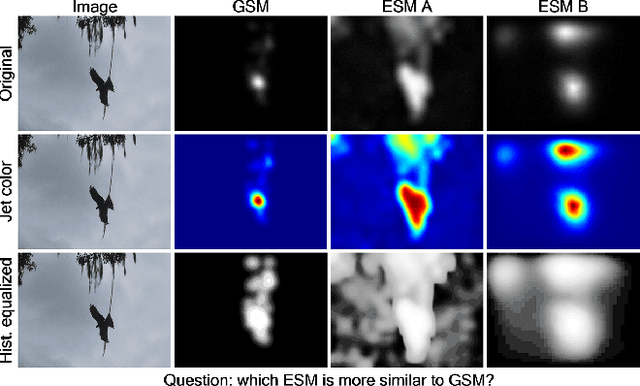

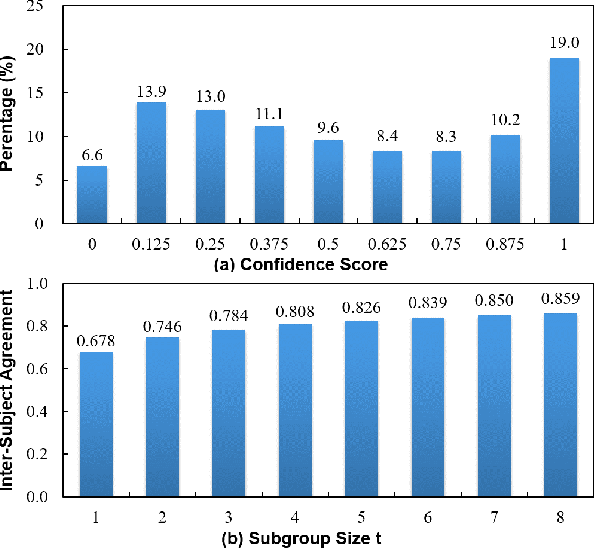

In the area of human fixation prediction, dozens of computational saliency models are proposed to reveal certain saliency characteristics under different assumptions and definitions. As a result, saliency model benchmarking often requires several evaluation metrics to simultaneously assess saliency models from multiple perspectives. However, most computational metrics are not designed to directly measure the perceptual similarity of saliency maps so that the evaluation results may be sometimes inconsistent with the subjective impression. To address this problem, this paper first conducts extensive subjective tests to find out how the visual similarities between saliency maps are perceived by humans. Based on the crowdsourced data collected in these tests, we conclude several key factors in assessing saliency maps and quantize the performance of existing metrics. Inspired by these factors, we propose to learn a saliency evaluation metric based on a two-stream convolutional neural network using crowdsourced perceptual judgements. Specifically, the relative saliency score of each pair from the crowdsourced data is utilized to regularize the network during the training process. By capturing the key factors shared by various subjects in comparing saliency maps, the learned metric better aligns with human perception of saliency maps, making it a good complement to the existing metrics. Experimental results validate that the learned metric can be generalized to the comparisons of saliency maps from new images, new datasets, new models and synthetic data. Due to the effectiveness of the learned metric, it also can be used to facilitate the development of new models for fixation prediction.
Statistics of Deep Generated Images
Jun 16, 2018


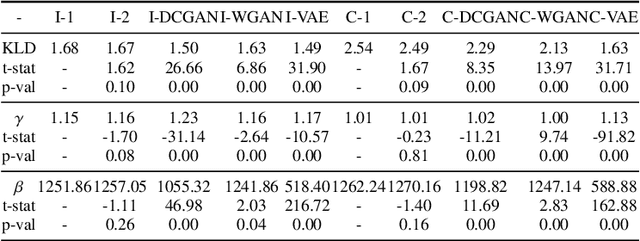
Here, we explore the low-level statistics of images generated by state-of-the-art deep generative models. First, Variational auto-encoder (VAE~\cite{kingma2013auto}), Wasserstein generative adversarial network (WGAN~\cite{arjovsky2017wasserstein}) and deep convolutional generative adversarial network (DCGAN~\cite{radford2015unsupervised}) are trained on the ImageNet dataset and a large set of cartoon frames from animations. Then, for images generated by these models as well as natural scenes and cartoons, statistics including mean power spectrum, the number of connected components in a given image area, distribution of random filter responses, and contrast distribution are computed. Our analyses on training images support current findings on scale invariance, non-Gaussianity, and Weibull contrast distribution of natural scenes. We find that although similar results hold over cartoon images, there is still a significant difference between statistics of natural scenes and images generated by VAE, DCGAN and WGAN models. In particular, generated images do not have scale invariant mean power spectrum magnitude, which indicates existence of extra structures in these images caused by deconvolution operations. We also find that replacing deconvolution layers in the deep generative models by sub-pixel convolution helps them generate images with a mean power spectrum closer to the mean power spectrum of natural images. Inspecting how well the statistics of deep generated images match the known statistical properties of natural images, such as scale invariance, non-Gaussianity, and Weibull contrast distribution, can a) reveal the degree to which deep learning models capture the essence of the natural scenes, b) provide a new dimension to evaluate models, and c) allow possible improvement of image generative models (e.g., via defining new loss functions).
Revisiting Video Saliency: A Large-scale Benchmark and a New Model
May 26, 2018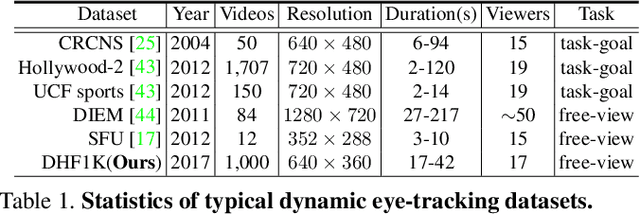

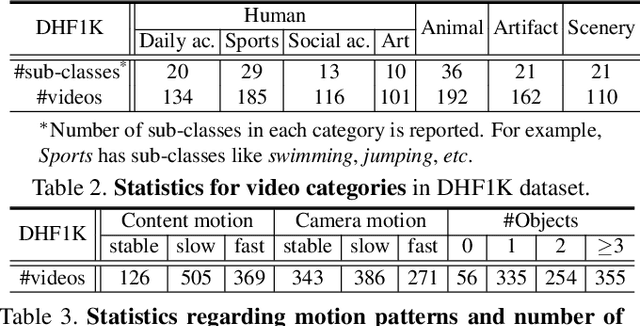

In this work, we contribute to video saliency research in two ways. First, we introduce a new benchmark for predicting human eye movements during dynamic scene free-viewing, which is long-time urged in this field. Our dataset, named DHF1K (Dynamic Human Fixation), consists of 1K high-quality, elaborately selected video sequences spanning a large range of scenes, motions, object types and background complexity. Existing video saliency datasets lack variety and generality of common dynamic scenes and fall short in covering challenging situations in unconstrained environments. In contrast, DHF1K makes a significant leap in terms of scalability, diversity and difficulty, and is expected to boost video saliency modeling. Second, we propose a novel video saliency model that augments the CNN-LSTM network architecture with an attention mechanism to enable fast, end-to-end saliency learning. The attention mechanism explicitly encodes static saliency information, thus allowing LSTM to focus on learning more flexible temporal saliency representation across successive frames. Such a design fully leverages existing large-scale static fixation datasets, avoids overfitting, and significantly improves training efficiency and testing performance. We thoroughly examine the performance of our model, with respect to state-of-the-art saliency models, on three large-scale datasets (i.e., DHF1K, Hollywood2, UCF sports). Experimental results over more than 1.2K testing videos containing 400K frames demonstrate that our model outperforms other competitors.
What are the Receptive, Effective Receptive, and Projective Fields of Neurons in Convolutional Neural Networks?
Apr 07, 2018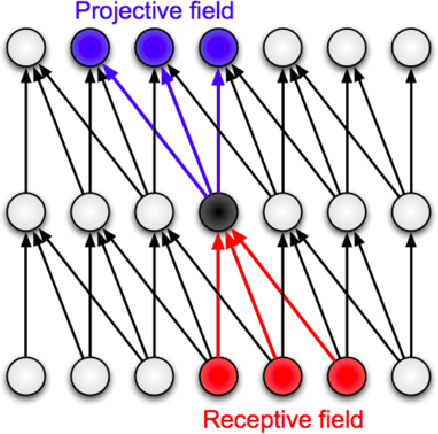
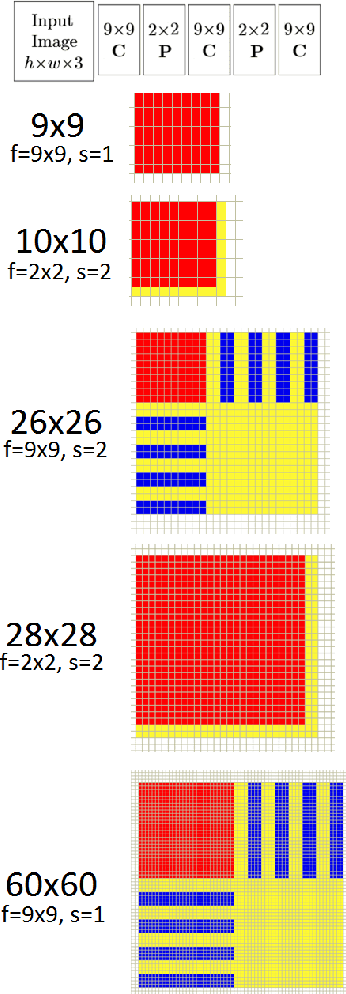
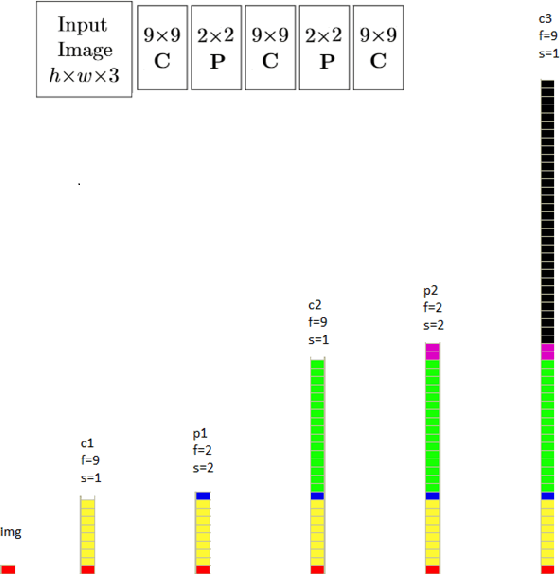
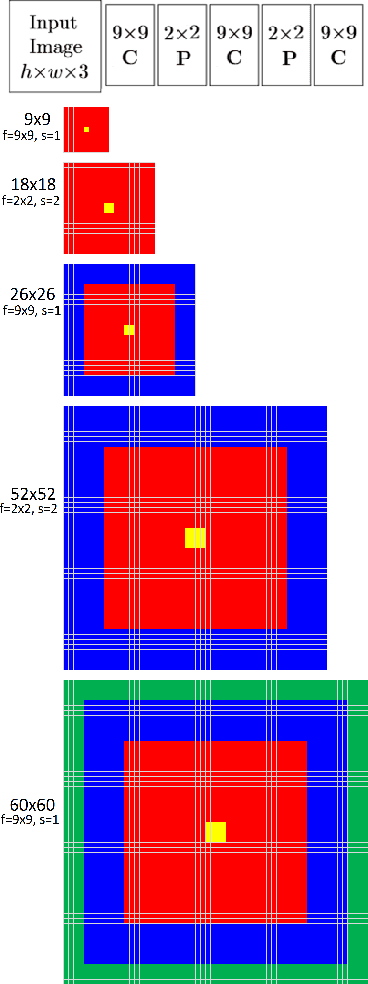
In this work, we explain in detail how receptive fields, effective receptive fields, and projective fields of neurons in different layers, convolution or pooling, of a Convolutional Neural Network (CNN) are calculated. While our focus here is on CNNs, the same operations, but in the reverse order, can be used to calculate these quantities for deconvolutional neural networks. These are important concepts, not only for better understanding and analyzing convolutional and deconvolutional networks, but also for optimizing their performance in real-world applications.
Cross-View Image Synthesis using Conditional GANs
Mar 29, 2018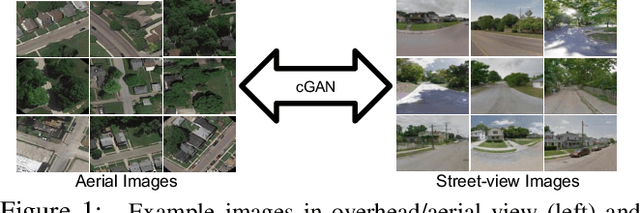
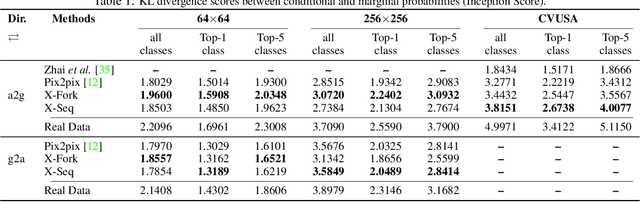
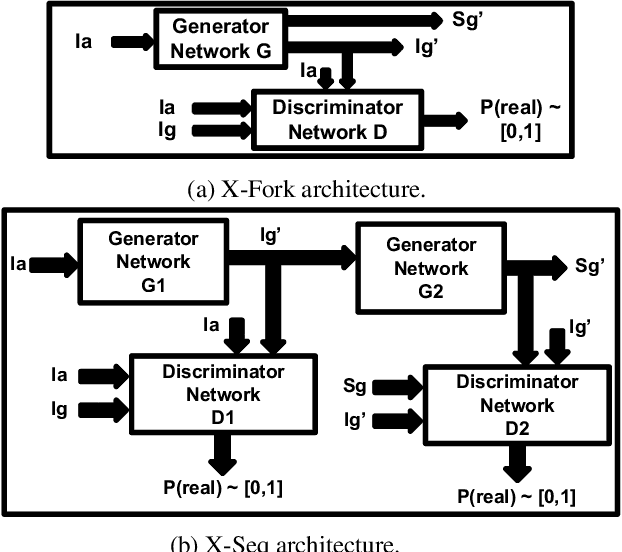
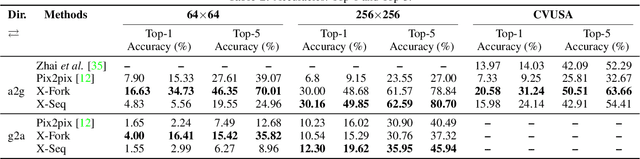
Learning to generate natural scenes has always been a challenging task in computer vision. It is even more painstaking when the generation is conditioned on images with drastically different views. This is mainly because understanding, corresponding, and transforming appearance and semantic information across the views is not trivial. In this paper, we attempt to solve the novel problem of cross-view image synthesis, aerial to street-view and vice versa, using conditional generative adversarial networks (cGAN). Two new architectures called Crossview Fork (X-Fork) and Crossview Sequential (X-Seq) are proposed to generate scenes with resolutions of 64x64 and 256x256 pixels. X-Fork architecture has a single discriminator and a single generator. The generator hallucinates both the image and its semantic segmentation in the target view. X-Seq architecture utilizes two cGANs. The first one generates the target image which is subsequently fed to the second cGAN for generating its corresponding semantic segmentation map. The feedback from the second cGAN helps the first cGAN generate sharper images. Both of our proposed architectures learn to generate natural images as well as their semantic segmentation maps. The proposed methods show that they are able to capture and maintain the true semantics of objects in source and target views better than the traditional image-to-image translation method which considers only the visual appearance of the scene. Extensive qualitative and quantitative evaluations support the effectiveness of our frameworks, compared to two state of the art methods, for natural scene generation across drastically different views.
Analysis of Hand Segmentation in the Wild
Mar 28, 2018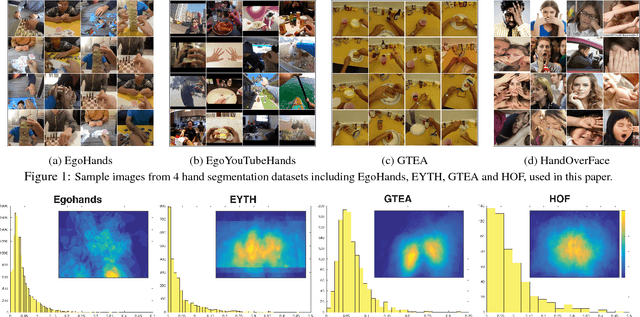
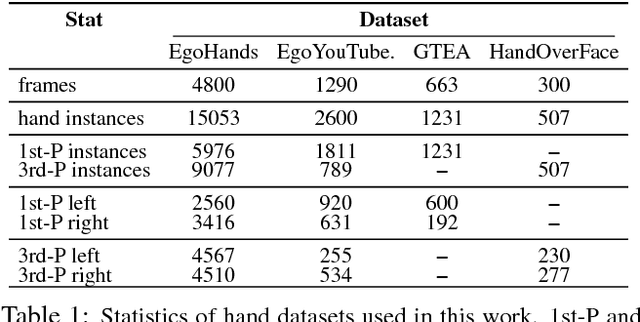

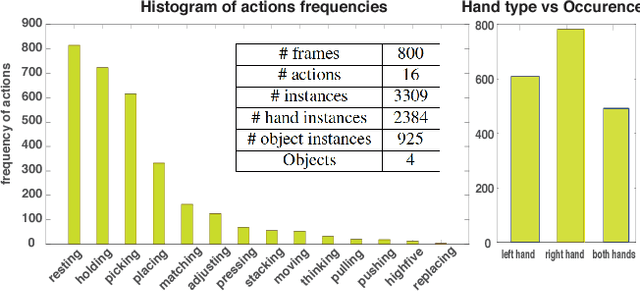
A large number of works in egocentric vision have concentrated on action and object recognition. Detection and segmentation of hands in first-person videos, however, has less been explored. For many applications in this domain, it is necessary to accurately segment not only hands of the camera wearer but also the hands of others with whom he is interacting. Here, we take an in-depth look at the hand segmentation problem. In the quest for robust hand segmentation methods, we evaluated the performance of the state of the art semantic segmentation methods, off the shelf and fine-tuned, on existing datasets. We fine-tune RefineNet, a leading semantic segmentation method, for hand segmentation and find that it does much better than the best contenders. Existing hand segmentation datasets are collected in the laboratory settings. To overcome this limitation, we contribute by collecting two new datasets: a) EgoYouTubeHands including egocentric videos containing hands in the wild, and b) HandOverFace to analyze the performance of our models in presence of similar appearance occlusions. We further explore whether conditional random fields can help refine generated hand segmentations. To demonstrate the benefit of accurate hand maps, we train a CNN for hand-based activity recognition and achieve higher accuracy when a CNN was trained using hand maps produced by the fine-tuned RefineNet. Finally, we annotate a subset of the EgoHands dataset for fine-grained action recognition and show that an accuracy of 58.6% can be achieved by just looking at a single hand pose which is much better than the chance level (12.5%).
Three Birds One Stone: A Unified Framework for Salient Object Segmentation, Edge Detection and Skeleton Extraction
Mar 27, 2018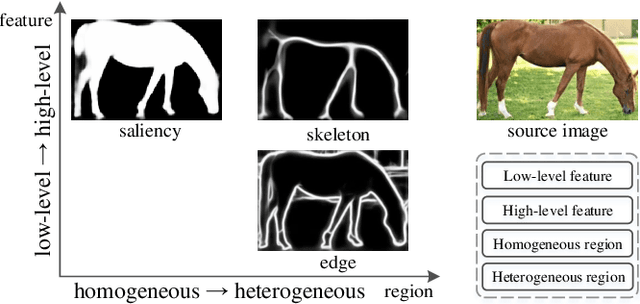
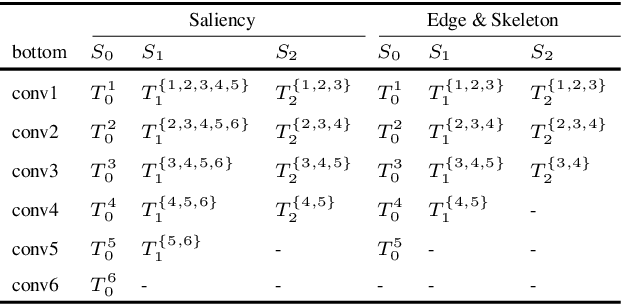
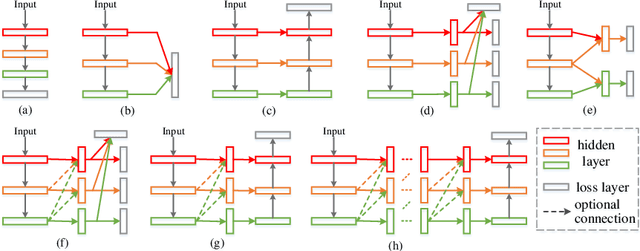
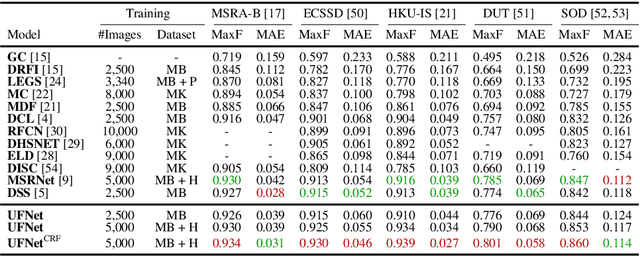
In this paper, we aim at solving pixel-wise binary problems, including salient object segmentation, skeleton extraction, and edge detection, by introducing a unified architecture. Previous works have proposed tailored methods for solving each of the three tasks independently. Here, we show that these tasks share some similarities that can be exploited for developing a unified framework. In particular, we introduce a horizontal cascade, each component of which is densely connected to the outputs of previous component. Stringing these components together allows us to effectively exploit features across different levels hierarchically to effectively address the multiple pixel-wise binary regression tasks. To assess the performance of our proposed network on these tasks, we carry out exhaustive evaluations on multiple representative datasets. Although these tasks are inherently very different, we show that our unified approach performs very well on all of them and works far better than current single-purpose state-of-the-art methods. All the code in this paper will be publicly available.
What Catches the Eye? Visualizing and Understanding Deep Saliency Models
Mar 22, 2018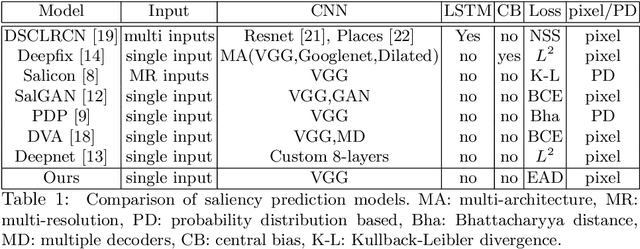
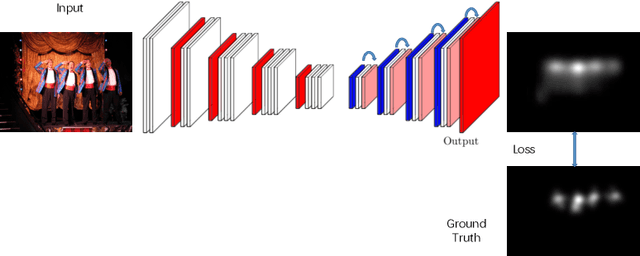
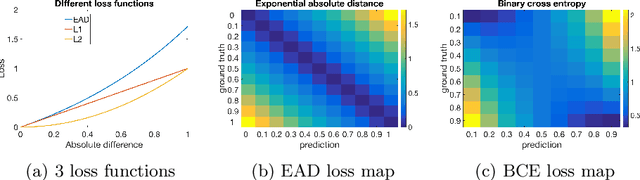
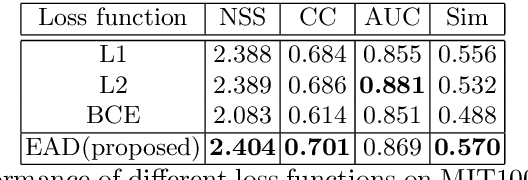
Deep convolutional neural networks have demonstrated high performances for fixation prediction in recent years. How they achieve this, however, is less explored and they remain to be black box models. Here, we attempt to shed light on the internal structure of deep saliency models and study what features they extract for fixation prediction. Specifically, we use a simple yet powerful architecture, consisting of only one CNN and a single resolution input, combined with a new loss function for pixel-wise fixation prediction during free viewing of natural scenes. We show that our simple method is on par or better than state-of-the-art complicated saliency models. Furthermore, we propose a method, related to saliency model evaluation metrics, to visualize deep models for fixation prediction. Our method reveals the inner representations of deep models for fixation prediction and provides evidence that saliency, as experienced by humans, is likely to involve high-level semantic knowledge in addition to low-level perceptual cues. Our results can be useful to measure the gap between current saliency models and the human inter-observer model and to build new models to close this gap.
Deeply supervised salient object detection with short connections
Mar 16, 2018
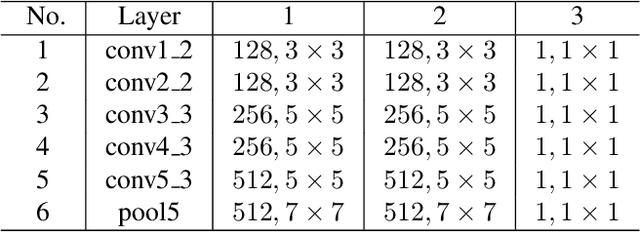


Recent progress on saliency detection is substantial, benefiting mostly from the explosive development of Convolutional Neural Networks (CNNs). Semantic segmentation and saliency detection algorithms developed lately have been mostly based on Fully Convolutional Neural Networks (FCNs). There is still a large room for improvement over the generic FCN models that do not explicitly deal with the scale-space problem. Holistically-Nested Edge Detector (HED) provides a skip-layer structure with deep supervision for edge and boundary detection, but the performance gain of HED on salience detection is not obvious. In this paper, we propose a new method for saliency detection by introducing short connections to the skip-layer structures within the HED architecture. Our framework provides rich multi-scale feature maps at each layer, a property that is critically needed to perform segment detection. Our method produces state-of-the-art results on 5 widely tested salient object detection benchmarks, with advantages in terms of efficiency (0.15 seconds per image), effectiveness, and simplicity over the existing algorithms.
* IEEE TPAMI 2018 (IEEE CVPR 2017)
Salient Object Detection: A Benchmark
Feb 27, 2018


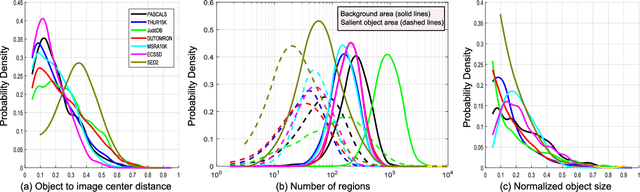
We extensively compare, qualitatively and quantitatively, 40 state-of-the-art models (28 salient object detection, 10 fixation prediction, 1 objectness, and 1 baseline) over 6 challenging datasets for the purpose of benchmarking salient object detection and segmentation methods. From the results obtained so far, our evaluation shows a consistent rapid progress over the last few years in terms of both accuracy and running time. The top contenders in this benchmark significantly outperform the models identified as the best in the previous benchmark conducted just two years ago. We find that the models designed specifically for salient object detection generally work better than models in closely related areas, which in turn provides a precise definition and suggests an appropriate treatment of this problem that distinguishes it from other problems. In particular, we analyze the influences of center bias and scene complexity in model performance, which, along with the hard cases for state-of-the-art models, provide useful hints towards constructing more challenging large scale datasets and better saliency models. Finally, we propose probable solutions for tackling several open problems such as evaluation scores and dataset bias, which also suggest future research directions in the rapidly-growing field of salient object detection.