 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unreasonable Effectiveness of Deep Features as a Perceptual Metric
Apr 10, 2018


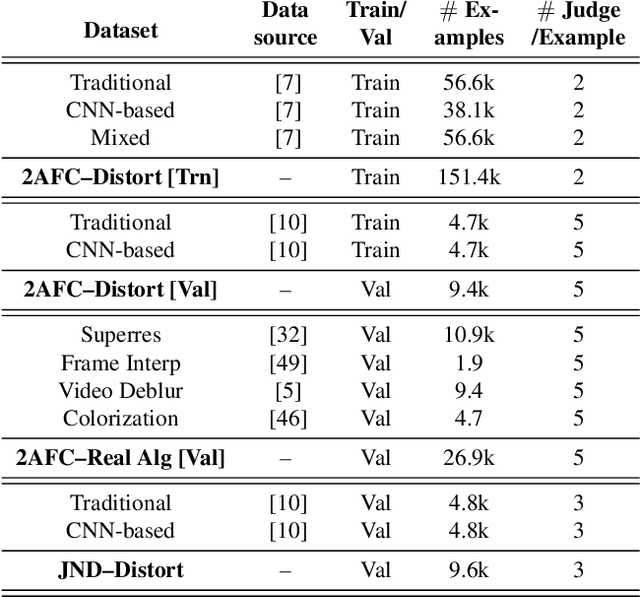
While it is nearly effortless for humans to quickly assess the perceptual similarity between two images, the underlying processes are thought to be quite complex. Despite this, the most widely used perceptual metrics today, such as PSNR and SSIM, are simple, shallow functions, and fail to account for many nuances of human perception. Recently, the deep learning community has found that features of the VGG network trained on ImageNet classification has been remarkably useful as a training loss for image synthesis. But how perceptual are these so-called "perceptual losses"? What elements are critical for their success? To answer these questions, we introduce a new dataset of human perceptual similarity judgments. We systematically evaluate deep features across different architectures and tasks and compare them with classic metrics. We find that deep features outperform all previous metrics by large margins on our dataset. More surprisingly, this result is not restricted to ImageNet-trained VGG features, but holds across different deep architectures and levels of supervision (supervised, self-supervised, or even unsupervised). Our results suggest that perceptual similarity is an emergent property shared across deep visual representations.
Learning Beyond Human Expertise with Generative Models for Dental Restorations
Mar 30, 2018
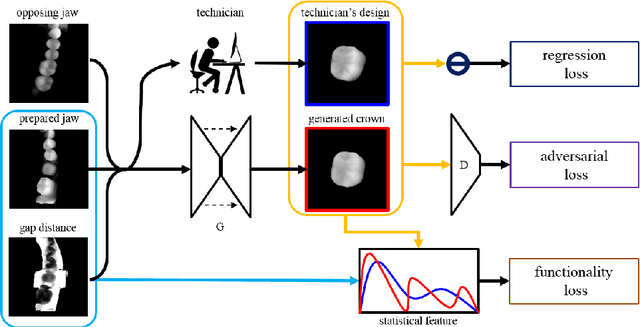
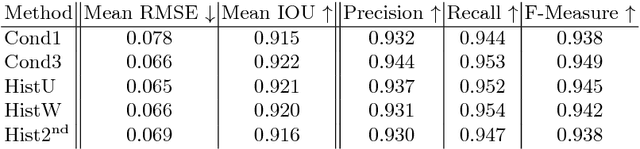
Computer vision has advanced significantly that many discriminative approaches such as object recognition are now widely used in real applications. We present another exciting development that utilizes generative models for the mass customization of medical products such as dental crowns. In the dental industry, it takes a technician years of training to design synthetic crowns that restore the function and integrity of missing teeth. Each crown must be customized to individual patients, and it requires human expertise in a time-consuming and labor-intensive process, even with computer-assisted design software. We develop a fully automatic approach that learns not only from human designs of dental crowns, but also from natural spatial profiles between opposing teeth. The latter is hard to account for by technicians but important for proper biting and chewing functions. Built upon a Generative Adversar-ial Network architecture (GAN), our deep learning model predicts the customized crown-filled depth scan from the crown-missing depth scan and opposing depth scan. We propose to incorporate additional space constraints and statistical compatibility into learning. Our automatic designs exceed human technicians' standards for good morphology and functionality, and our algorithm is being tested for production use.
CyCADA: Cycle-Consistent Adversarial Domain Adaptation
Dec 29, 2017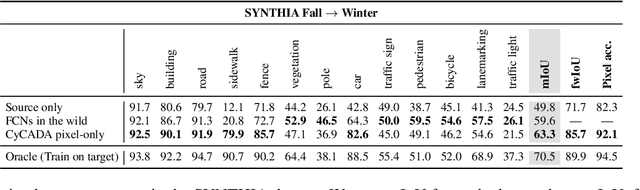
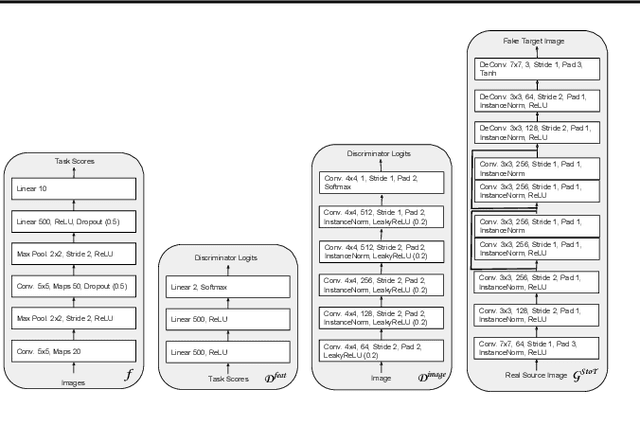


Domain adaptation is critical for success in new, unseen environments. Adversarial adaptation models applied in feature spaces discover domain invariant representations, but are difficult to visualize and sometimes fail to capture pixel-level and low-level domain shifts. Recent work has shown that generative adversarial networks combined with cycle-consistency constraints are surprisingly effective at mapping images between domains, even without the use of aligned image pairs. We propose a novel discriminatively-trained Cycle-Consistent Adversarial Domain Adaptation model. CyCADA adapts representations at both the pixel-level and feature-level, enforces cycle-consistency while leveraging a task loss, and does not require aligned pairs. Our model can be applied in a variety of visual recognition and prediction settings. We show new state-of-the-art results across multiple adaptation tasks, including digit classification and semantic segmentation of road scenes demonstrating transfer from synthetic to real world domains.
From Lifestyle Vlogs to Everyday Interactions
Dec 06, 2017
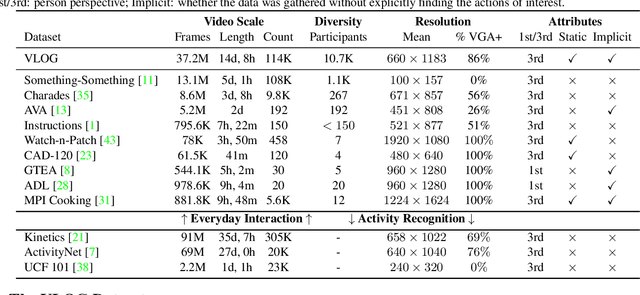

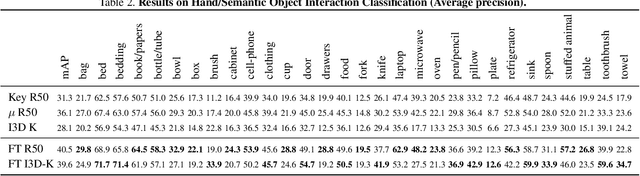
A major stumbling block to progress in understanding basic human interactions, such as getting out of bed or opening a refrigerator, is lack of good training data. Most past efforts have gathered this data explicitly: starting with a laundry list of action labels, and then querying search engines for videos tagged with each label. In this work, we do the reverse and search implicitly: we start with a large collection of interaction-rich video data and then annotate and analyze it. We use Internet Lifestyle Vlogs as the source of surprisingly large and diverse interaction data. We show that by collecting the data first, we are able to achieve greater scale and far greater diversity in terms of actions and actors. Additionally, our data exposes biases built into common explicitly gathered data. We make sense of our data by analyzing the central component of interaction -- hands. We benchmark two tasks: identifying semantic object contact at the video level and non-semantic contact state at the frame level. We additionally demonstrate future prediction of hands.
Image-to-Image Translation with Conditional Adversarial Networks
Nov 22, 2017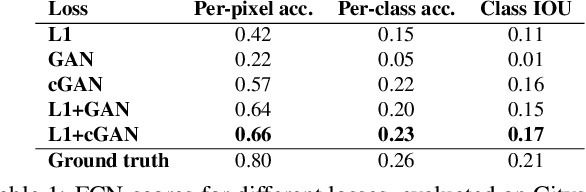
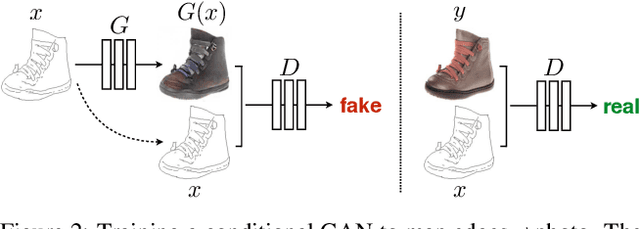

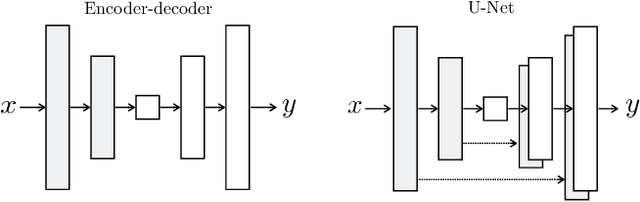
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. Indeed, since the release of the pix2pix software associated with this paper, a large number of internet users (many of them artists) have posted their own experiments with our system, further demonstrating its wide applicability and ease of adoption without the need for parameter tweaking. As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
* Website: https://phillipi.github.io/pix2pix/
Curiosity-driven Exploration by Self-supervised Prediction
May 15, 2017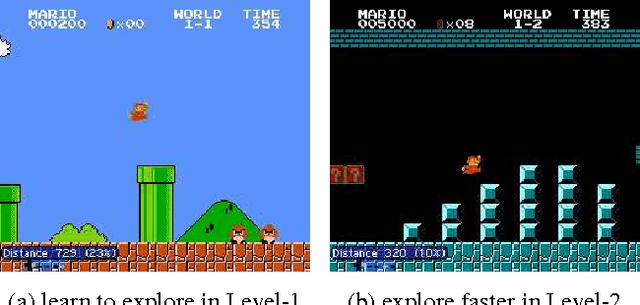
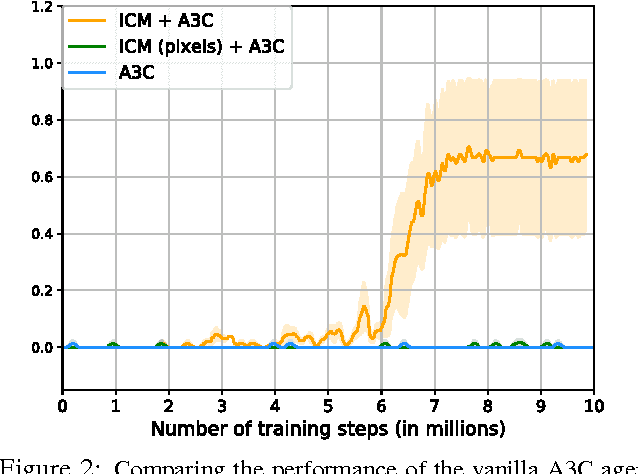
In many real-world scenarios, rewards extrinsic to the agent are extremely sparse, or absent altogether. In such cases, curiosity can serve as an intrinsic reward signal to enable the agent to explore its environment and learn skills that might be useful later in its life. We formulate curiosity as the error in an agent's ability to predict the consequence of its own actions in a visual feature space learned by a self-supervised inverse dynamics model. Our formulation scales to high-dimensional continuous state spaces like images, bypasses the difficulties of directly predicting pixels, and, critically, ignores the aspects of the environment that cannot affect the agent. The proposed approach is evaluated in two environments: VizDoom and Super Mario Bros. Three broad settings are investigated: 1) sparse extrinsic reward, where curiosity allows for far fewer interactions with the environment to reach the goal; 2) exploration with no extrinsic reward, where curiosity pushes the agent to explore more efficiently; and 3) generalization to unseen scenarios (e.g. new levels of the same game) where the knowledge gained from earlier experience helps the agent explore new places much faster than starting from scratch. Demo video and code available at https://pathak22.github.io/noreward-rl/
Real-Time User-Guided Image Colorization with Learned Deep Priors
May 08, 2017
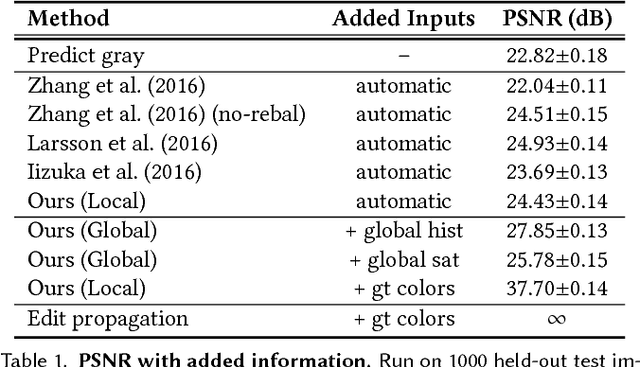
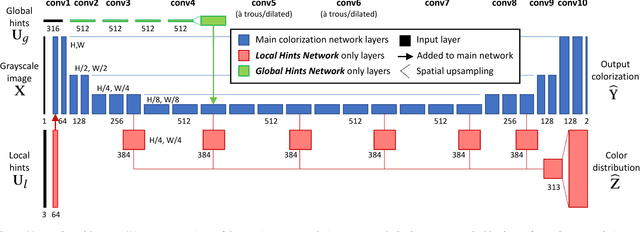

We propose a deep learning approach for user-guided image colorization. The system directly maps a grayscale image, along with sparse, local user "hints" to an output colorization with a Convolutional Neural Network (CNN). Rather than using hand-defined rules, the network propagates user edits by fusing low-level cues along with high-level semantic information, learned from large-scale data. We train on a million images, with simulated user inputs. To guide the user towards efficient input selection, the system recommends likely colors based on the input image and current user inputs. The colorization is performed in a single feed-forward pass, enabling real-time use. Even with randomly simulated user inputs, we show that the proposed system helps novice users quickly create realistic colorizations, and offers large improvements in colorization quality with just a minute of use. In addition, we demonstrate that the framework can incorporate other user "hints" to the desired colorization, showing an application to color histogram transfer. Our code and models are available at https://richzhang.github.io/ideepcolor.
Light Field Video Capture Using a Learning-Based Hybrid Imaging System
May 08, 2017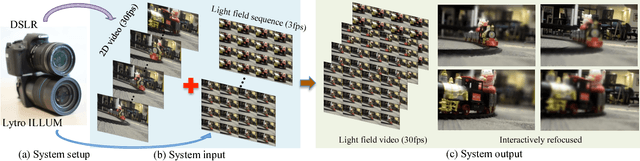
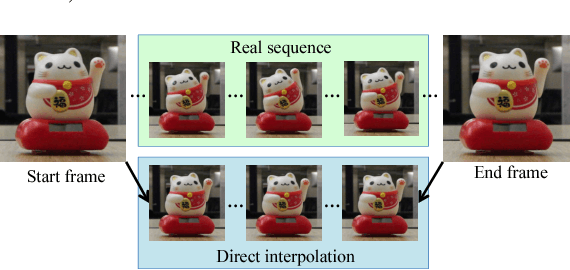
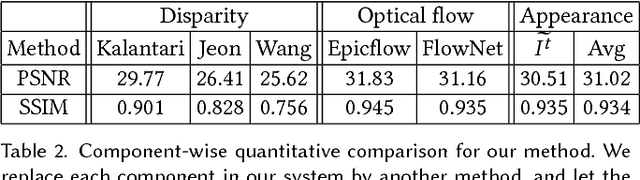
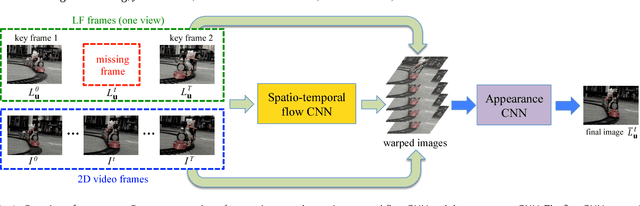
Light field cameras have many advantages over traditional cameras, as they allow the user to change various camera settings after capture. However, capturing light fields requires a huge bandwidth to record the data: a modern light field camera can only take three images per second. This prevents current consumer light field cameras from capturing light field videos. Temporal interpolation at such extreme scale (10x, from 3 fps to 30 fps) is infeasible as too much information will be entirely missing between adjacent frames. Instead, we develop a hybrid imaging system, adding another standard video camera to capture the temporal information. Given a 3 fps light field sequence and a standard 30 fps 2D video, our system can then generate a full light field video at 30 fps. We adopt a learning-based approach, which can be decomposed into two steps: spatio-temporal flow estimation and appearance estimation. The flow estimation propagates the angular information from the light field sequence to the 2D video, so we can warp input images to the target view. The appearance estimation then combines these warped images to output the final pixels. The whole process is trained end-to-end using convolutional neural networks. Experimental results demonstrate that our algorithm outperforms current video interpolation methods, enabling consumer light field videography, and making applications such as refocusing and parallax view generation achievable on videos for the first time.
Multi-view Supervision for Single-view Reconstruction via Differentiable Ray Consistency
Apr 20, 2017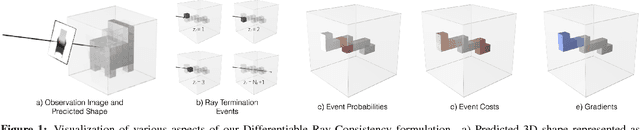
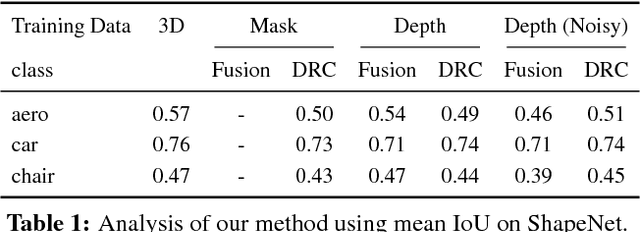

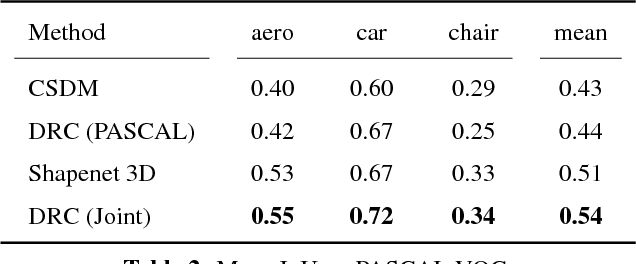
We study the notion of consistency between a 3D shape and a 2D observation and propose a differentiable formulation which allows computing gradients of the 3D shape given an observation from an arbitrary view. We do so by reformulating view consistency using a differentiable ray consistency (DRC) term. We show that this formulation can be incorporated in a learning framework to leverage different types of multi-view observations e.g. foreground masks, depth, color images, semantics etc. as supervision for learning single-view 3D prediction. We present empirical analysis of our technique in a controlled setting. We also show that this approach allows us to improve over existing techniques for single-view reconstruction of objects from the PASCAL VOC dataset.
Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction
Apr 20, 2017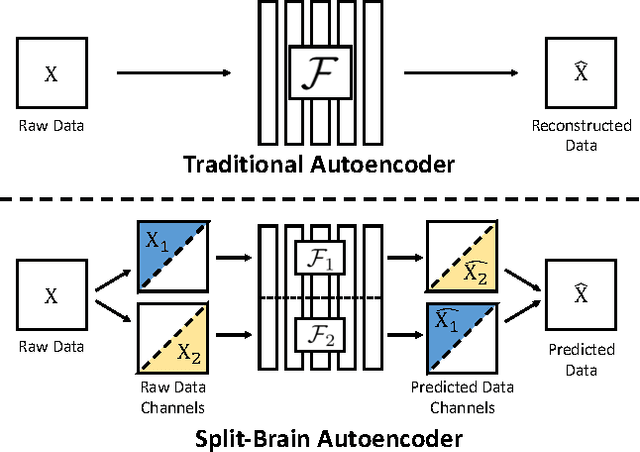


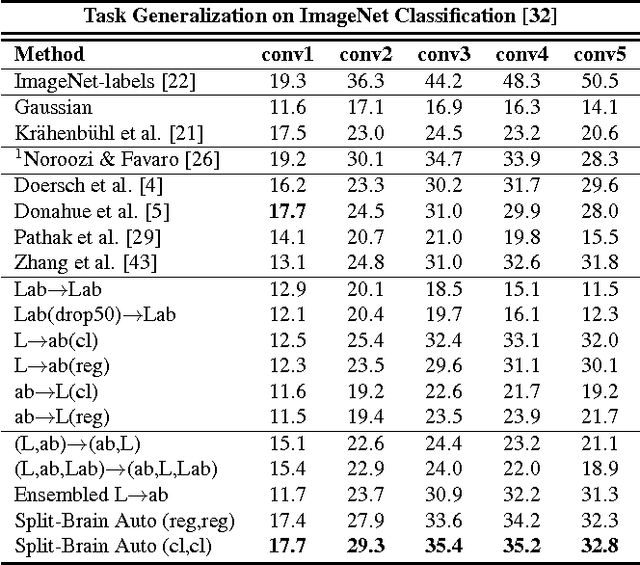
We propose split-brain autoencoders, a straightforward modification of the traditional autoencoder architecture, for unsupervised representation learning. The method adds a split to the network, resulting in two disjoint sub-networks. Each sub-network is trained to perform a difficult task -- predicting one subset of the data channels from another. Together, the sub-networks extract features from the entire input signal. By forcing the network to solve cross-channel prediction tasks, we induce a representation within the network which transfers well to other, unseen tasks. This method achieves state-of-the-art performance on several large-scale transfer learning benchmarks.