 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Collapse in Non-Contrastive Learning
Sep 29, 2022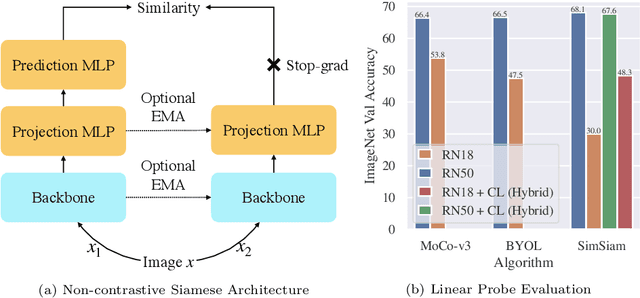

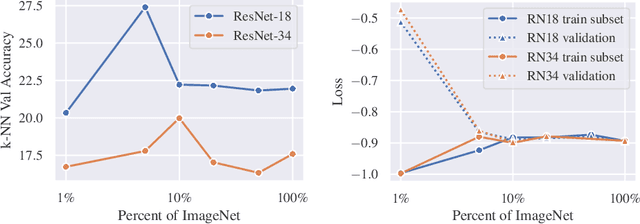
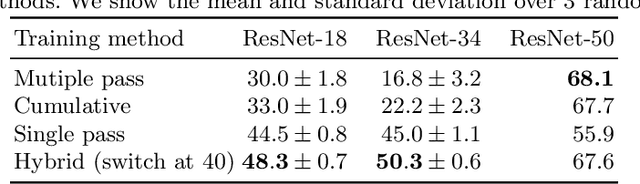
Contrastive methods have led a recent surge in the performance of self-supervised representation learning (SSL). Recent methods like BYOL or SimSiam purportedly distill these contrastive methods down to their essence, removing bells and whistles, including the negative examples, that do not contribute to downstream performance. These "non-contrastive" methods work surprisingly well without using negatives even though the global minimum lies at trivial collapse. We empirically analyze these non-contrastive methods and find that SimSiam is extraordinarily sensitive to dataset and model size. In particular, SimSiam representations undergo partial dimensional collapse if the model is too small relative to the dataset size. We propose a metric to measure the degree of this collapse and show that it can be used to forecast the downstream task performance without any fine-tuning or labels. We further analyze architectural design choices and their effect on the downstream performance. Finally, we demonstrate that shifting to a continual learning setting acts as a regularizer and prevents collapse, and a hybrid between continual and multi-epoch training can improve linear probe accuracy by as many as 18 percentage points using ResNet-18 on ImageNet.
Learning to Learn with Generative Models of Neural Network Checkpoints
Sep 26, 2022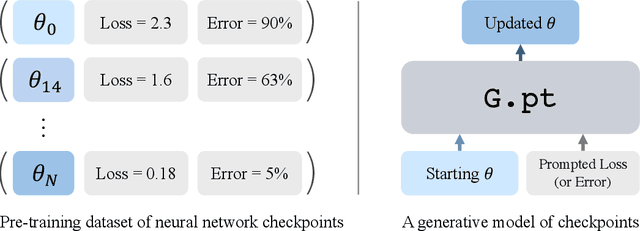
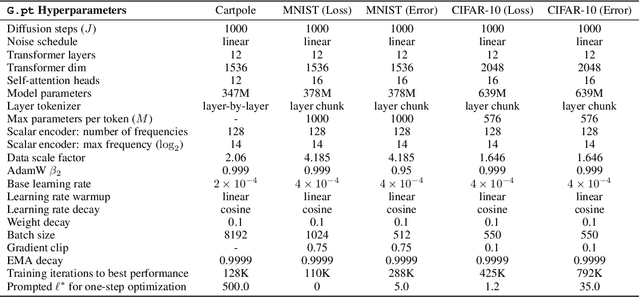
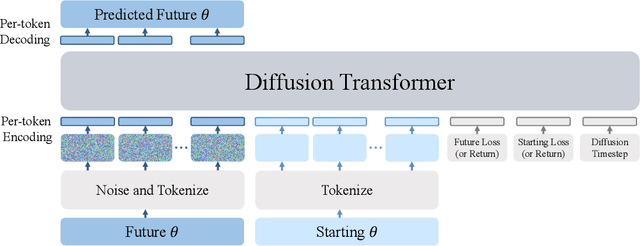
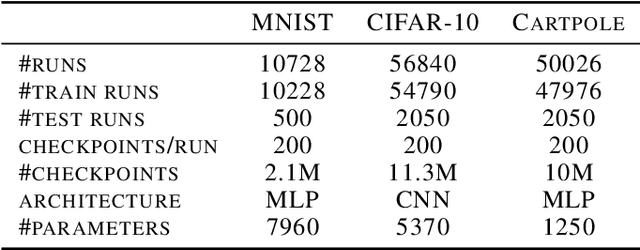
We explore a data-driven approach for learning to optimize neural networks. We construct a dataset of neural network checkpoints and train a generative model on the parameters. In particular, our model is a conditional diffusion transformer that, given an initial input parameter vector and a prompted loss, error, or return, predicts the distribution over parameter updates that achieve the desired metric. At test time, it can optimize neural networks with unseen parameters for downstream tasks in just one update. We find that our approach successfully generates parameters for a wide range of loss prompts. Moreover, it can sample multimodal parameter solutions and has favorable scaling properties. We apply our method to different neural network architectures and tasks in supervised and reinforcement learning.
Test-Time Training with Masked Autoencoders
Sep 15, 2022
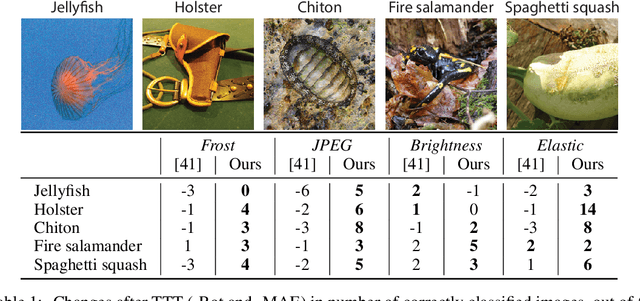
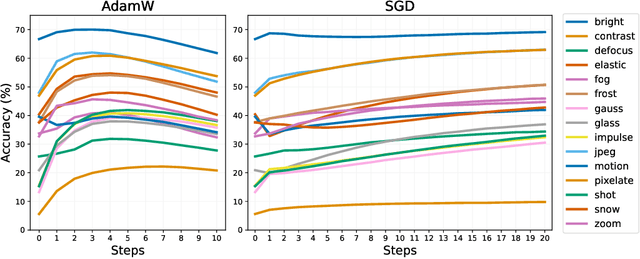

Test-time training adapts to a new test distribution on the fly by optimizing a model for each test input using self-supervision. In this paper, we use masked autoencoders for this one-sample learning problem. Empirically, our simple method improves generalization on many visual benchmarks for distribution shifts. Theoretically, we characterize this improvement in terms of the bias-variance trade-off.
Studying Bias in GANs through the Lens of Race
Sep 15, 2022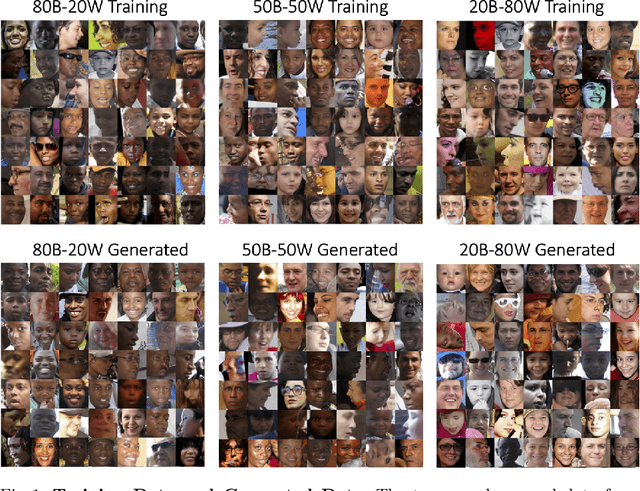



In this work, we study how the performance and evaluation of generative image models are impacted by the racial composition of their training datasets. By examining and controlling the racial distributions in various training datasets, we are able to observe the impacts of different training distributions on generated image quality and the racial distributions of the generated images. Our results show that the racial compositions of generated images successfully preserve that of the training data. However, we observe that truncation, a technique used to generate higher quality images during inference, exacerbates racial imbalances in the data. Lastly, when examining the relationship between image quality and race, we find that the highest perceived visual quality images of a given race come from a distribution where that race is well-represented, and that annotators consistently prefer generated images of white people over those of Black people.
Visual Prompting via Image Inpainting
Sep 01, 2022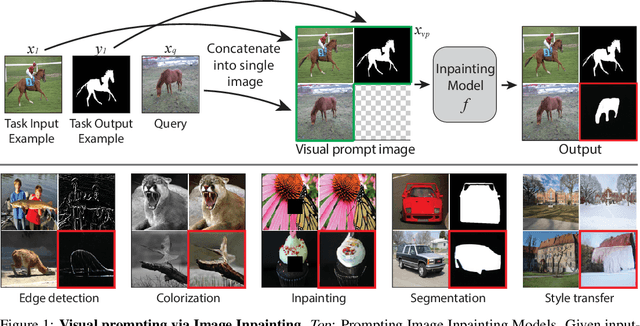
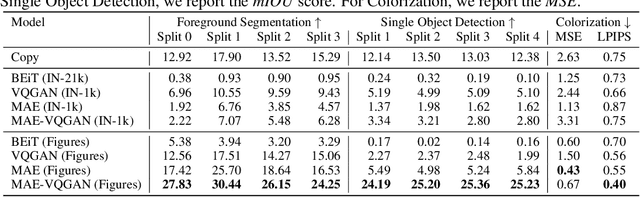
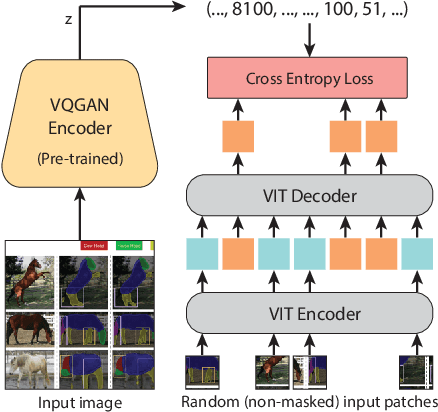
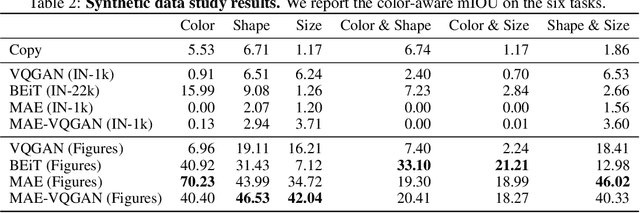
How does one adapt a pre-trained visual model to novel downstream tasks without task-specific finetuning or any model modification? Inspired by prompting in NLP, this paper investigates visual prompting: given input-output image example(s) of a new task at test time and a new input image, the goal is to automatically produce the output image, consistent with the given examples. We show that posing this problem as simple image inpainting - literally just filling in a hole in a concatenated visual prompt image - turns out to be surprisingly effective, provided that the inpainting algorithm has been trained on the right data. We train masked auto-encoders on a new dataset that we curated - 88k unlabeled figures from academic papers sources on Arxiv. We apply visual prompting to these pretrained models and demonstrate results on various downstream image-to-image tasks, including foreground segmentation, single object detection, colorization, edge detection, etc.
Generating Long Videos of Dynamic Scenes
Jun 09, 2022

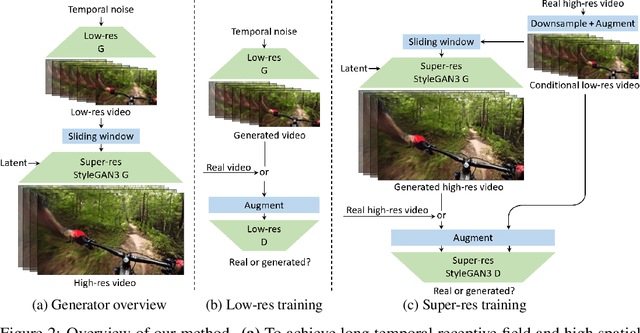

We present a video generation model that accurately reproduces object motion, changes in camera viewpoint, and new content that arises over time. Existing video generation methods often fail to produce new content as a function of time while maintaining consistencies expected in real environments, such as plausible dynamics and object persistence. A common failure case is for content to never change due to over-reliance on inductive biases to provide temporal consistency, such as a single latent code that dictates content for the entire video. On the other extreme, without long-term consistency, generated videos may morph unrealistically between different scenes. To address these limitations, we prioritize the time axis by redesigning the temporal latent representation and learning long-term consistency from data by training on longer videos. To this end, we leverage a two-phase training strategy, where we separately train using longer videos at a low resolution and shorter videos at a high resolution. To evaluate the capabilities of our model, we introduce two new benchmark datasets with explicit focus on long-term temporal dynamics.
BlobGAN: Spatially Disentangled Scene Representations
May 05, 2022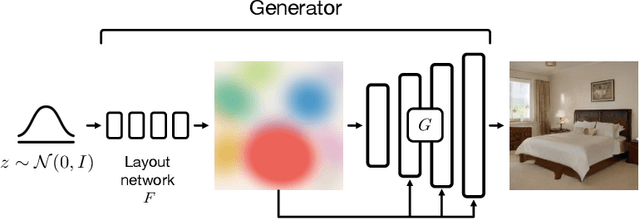
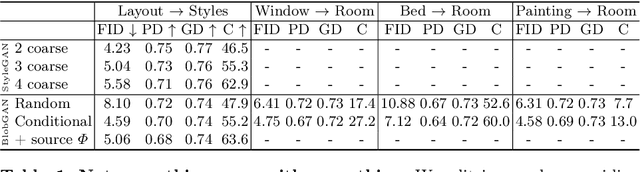
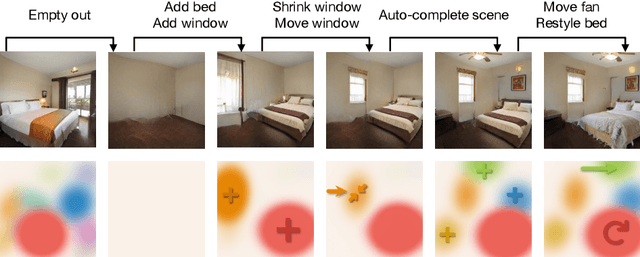
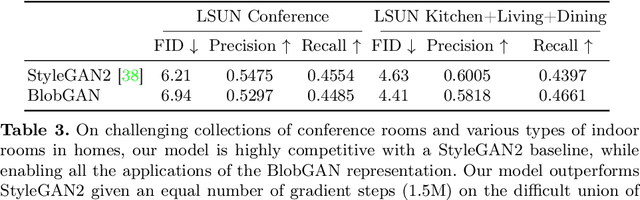
We propose an unsupervised, mid-level representation for a generative model of scenes. The representation is mid-level in that it is neither per-pixel nor per-image; rather, scenes are modeled as a collection of spatial, depth-ordered "blobs" of features. Blobs are differentiably placed onto a feature grid that is decoded into an image by a generative adversarial network. Due to the spatial uniformity of blobs and the locality inherent to convolution, our network learns to associate different blobs with different entities in a scene and to arrange these blobs to capture scene layout. We demonstrate this emergent behavior by showing that, despite training without any supervision, our method enables applications such as easy manipulation of objects within a scene (e.g., moving, removing, and restyling furniture), creation of feasible scenes given constraints (e.g., plausible rooms with drawers at a particular location), and parsing of real-world images into constituent parts. On a challenging multi-category dataset of indoor scenes, BlobGAN outperforms StyleGAN2 in image quality as measured by FID. See our project page for video results and interactive demo: http://www.dave.ml/blobgan
Share With Thy Neighbors: Single-View Reconstruction by Cross-Instance Consistency
Apr 21, 2022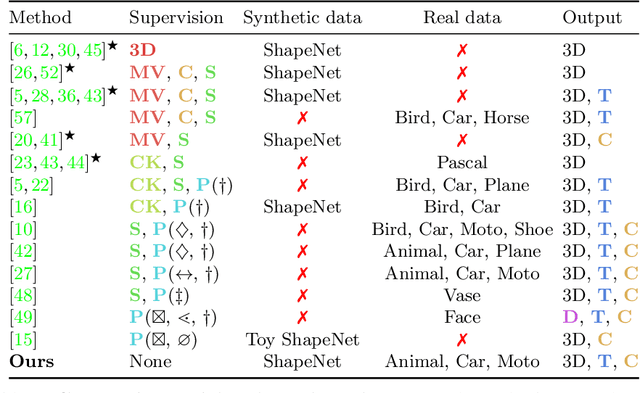
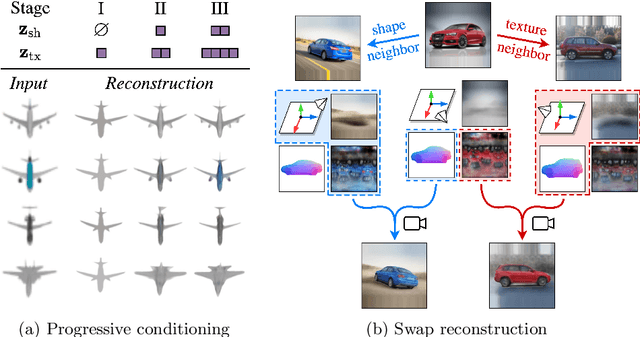
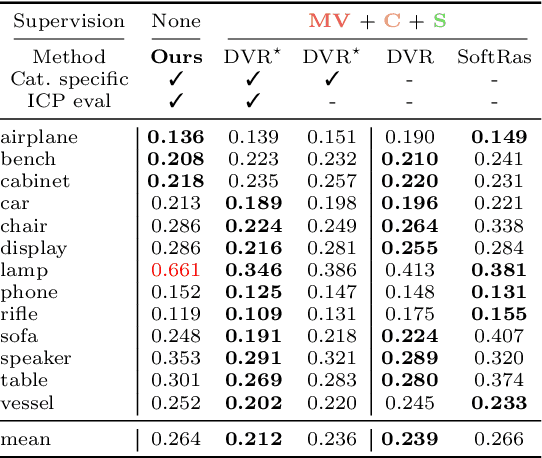
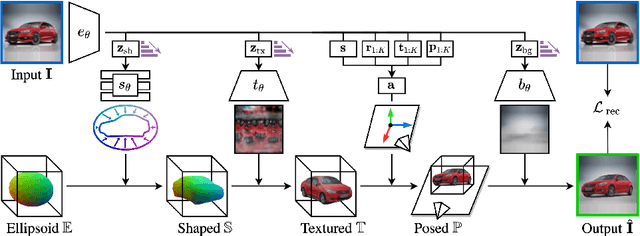
Approaches to single-view reconstruction typically rely on viewpoint annotations, silhouettes, the absence of background, multiple views of the same instance, a template shape, or symmetry. We avoid all of these supervisions and hypotheses by leveraging explicitly the consistency between images of different object instances. As a result, our method can learn from large collections of unlabelled images depicting the same object category. Our main contributions are two approaches to leverage cross-instance consistency: (i) progressive conditioning, a training strategy to gradually specialize the model from category to instances in a curriculum learning fashion; (ii) swap reconstruction, a loss enforcing consistency between instances having similar shape or texture. Critical to the success of our method are also: our structured autoencoding architecture decomposing an image into explicit shape, texture, pose, and background; an adapted formulation of differential rendering, and; a new optimization scheme alternating between 3D and pose learning. We compare our approach, UNICORN, both on the diverse synthetic ShapeNet dataset - the classical benchmark for methods requiring multiple views as supervision - and on standard real-image benchmarks (Pascal3D+ Car, CUB-200) for which most methods require known templates and silhouette annotations. We also showcase applicability to more challenging real-world collections (CompCars, LSUN), where silhouettes are not available and images are not cropped around the object.
Dataset Distillation by Matching Training Trajectories
Mar 22, 2022
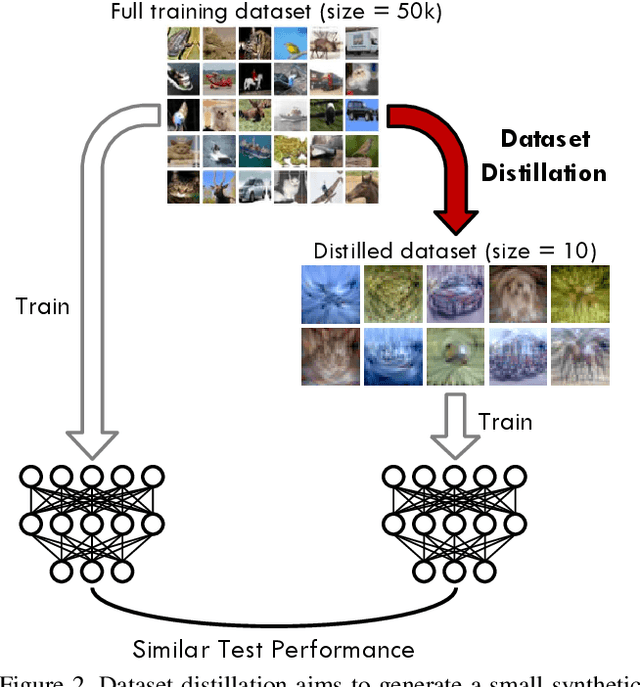
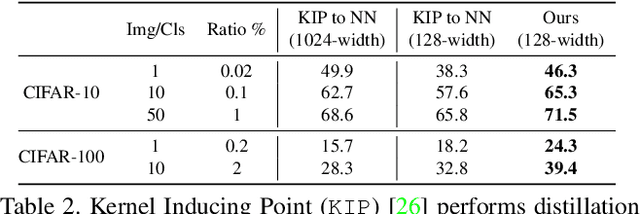
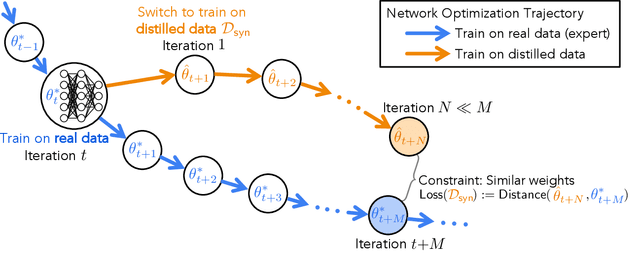
Dataset distillation is the task of synthesizing a small dataset such that a model trained on the synthetic set will match the test accuracy of the model trained on the full dataset. In this paper, we propose a new formulation that optimizes our distilled data to guide networks to a similar state as those trained on real data across many training steps. Given a network, we train it for several iterations on our distilled data and optimize the distilled data with respect to the distance between the synthetically trained parameters and the parameters trained on real data. To efficiently obtain the initial and target network parameters for large-scale datasets, we pre-compute and store training trajectories of expert networks trained on the real dataset. Our method handily outperforms existing methods and also allows us to distill higher-resolution visual data.
Learning Pixel Trajectories with Multiscale Contrastive Random Walks
Jan 20, 2022
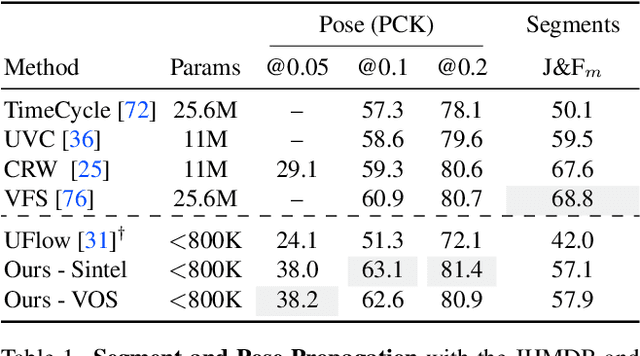
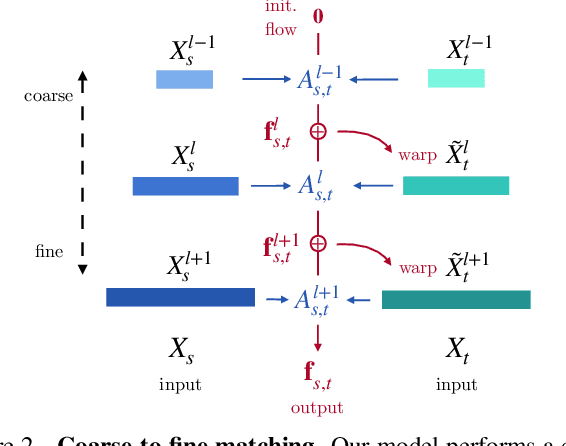

A range of video modeling tasks, from optical flow to multiple object tracking, share the same fundamental challenge: establishing space-time correspondence. Yet, approaches that dominate each space differ. We take a step towards bridging this gap by extending the recent contrastive random walk formulation to much denser, pixel-level space-time graphs. The main contribution is introducing hierarchy into the search problem by computing the transition matrix between two frames in a coarse-to-fine manner, forming a multiscale contrastive random walk when extended in time. This establishes a unified technique for self-supervised learning of optical flow, keypoint tracking, and video object segmentation. Experiments demonstrate that, for each of these tasks, the unified model achieves performance competitive with strong self-supervised approaches specific to that task. Project site: https://jasonbian97.github.io/flowwalk