 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Reliable Human Pose Forecasting with Uncertainty
Apr 13, 2023



Recently, there has been an arms race of pose forecasting methods aimed at solving the spatio-temporal task of predicting a sequence of future 3D poses of a person given a sequence of past observed ones. However, the lack of unified benchmarks and limited uncertainty analysis have hindered progress in the field. To address this, we first develop an open-source library for human pose forecasting, featuring multiple models, datasets, and standardized evaluation metrics, with the aim of promoting research and moving toward a unified and fair evaluation. Second, we devise two types of uncertainty in the problem to increase performance and convey better trust: 1) we propose a method for modeling aleatoric uncertainty by using uncertainty priors to inject knowledge about the behavior of uncertainty. This focuses the capacity of the model in the direction of more meaningful supervision while reducing the number of learned parameters and improving stability; 2) we introduce a novel approach for quantifying the epistemic uncertainty of any model through clustering and measuring the entropy of its assignments. Our experiments demonstrate up to $25\%$ improvements in accuracy and better performance in uncertainty estimation.
Predicting long-term collective animal behavior with deep learning
Feb 14, 2023



Deciphering the social interactions that govern collective behavior in animal societies has greatly benefited from advancements in modern computing. Computational models diverge into two kinds of approaches: analytical models and machine learning models. This work introduces a deep learning model for social interactions in the fish species Hemigrammus rhodostomus, and compares its results to experiments and to the results of a state-of-the-art analytical model. To that end, we propose a systematic methodology to assess the faithfulness of a model, based on the introduction of a set of stringent observables. We demonstrate that machine learning models of social interactions can directly compete against their analytical counterparts. Moreover, this work demonstrates the need for consistent validation across different timescales and highlights which design aspects critically enables our deep learning approach to capture both short- and long-term dynamics. We also show that this approach is scalable to other fish species.
Causal Triplet: An Open Challenge for Intervention-centric Causal Representation Learning
Jan 12, 2023



Recent years have seen a surge of interest in learning high-level causal representations from low-level image pairs under interventions. Yet, existing efforts are largely limited to simple synthetic settings that are far away from real-world problems. In this paper, we present Causal Triplet, a causal representation learning benchmark featuring not only visually more complex scenes, but also two crucial desiderata commonly overlooked in previous works: (i) an actionable counterfactual setting, where only certain object-level variables allow for counterfactual observations whereas others do not; (ii) an interventional downstream task with an emphasis on out-of-distribution robustness from the independent causal mechanisms principle. Through extensive experiments, we find that models built with the knowledge of disentangled or object-centric representations significantly outperform their distributed counterparts. However, recent causal representation learning methods still struggle to identify such latent structures, indicating substantial challenges and opportunities for future work. Our code and datasets will be available at https://sites.google.com/view/causaltriplet.
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022



The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.
Body Part-Based Representation Learning for Occluded Person Re-Identification
Nov 07, 2022



Occluded person re-identification (ReID) is a person retrieval task which aims at matching occluded person images with holistic ones. For addressing occluded ReID, part-based methods have been shown beneficial as they offer fine-grained information and are well suited to represent partially visible human bodies. However, training a part-based model is a challenging task for two reasons. Firstly, individual body part appearance is not as discriminative as global appearance (two distinct IDs might have the same local appearance), this means standard ReID training objectives using identity labels are not adapted to local feature learning. Secondly, ReID datasets are not provided with human topographical annotations. In this work, we propose BPBreID, a body part-based ReID model for solving the above issues. We first design two modules for predicting body part attention maps and producing body part-based features of the ReID target. We then propose GiLt, a novel training scheme for learning part-based representations that is robust to occlusions and non-discriminative local appearance. Extensive experiments on popular holistic and occluded datasets show the effectiveness of our proposed method, which outperforms state-of-the-art methods by 0.7% mAP and 5.6% rank-1 accuracy on the challenging Occluded-Duke dataset. Our code is available at https://github.com/VlSomers/bpbreid.
Motion Style Transfer: Modular Low-Rank Adaptation for Deep Motion Forecasting
Nov 06, 2022



Deep motion forecasting models have achieved great success when trained on a massive amount of data. Yet, they often perform poorly when training data is limited. To address this challenge, we propose a transfer learning approach for efficiently adapting pre-trained forecasting models to new domains, such as unseen agent types and scene contexts. Unlike the conventional fine-tuning approach that updates the whole encoder, our main idea is to reduce the amount of tunable parameters that can precisely account for the target domain-specific motion style. To this end, we introduce two components that exploit our prior knowledge of motion style shifts: (i) a low-rank motion style adapter that projects and adjusts the style features at a low-dimensional bottleneck; and (ii) a modular adapter strategy that disentangles the features of scene context and motion history to facilitate a fine-grained choice of adaptation layers. Through extensive experimentation, we show that our proposed adapter design, coined MoSA, outperforms prior methods on several forecasting benchmarks.
VL4Pose: Active Learning Through Out-Of-Distribution Detection For Pose Estimation
Oct 12, 2022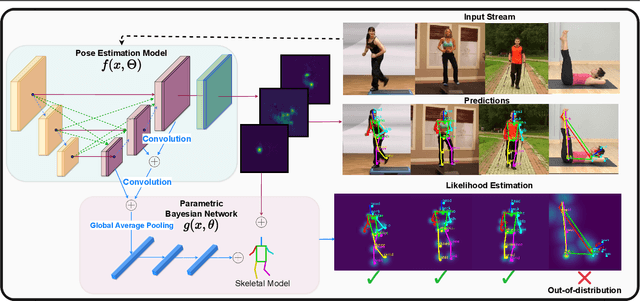
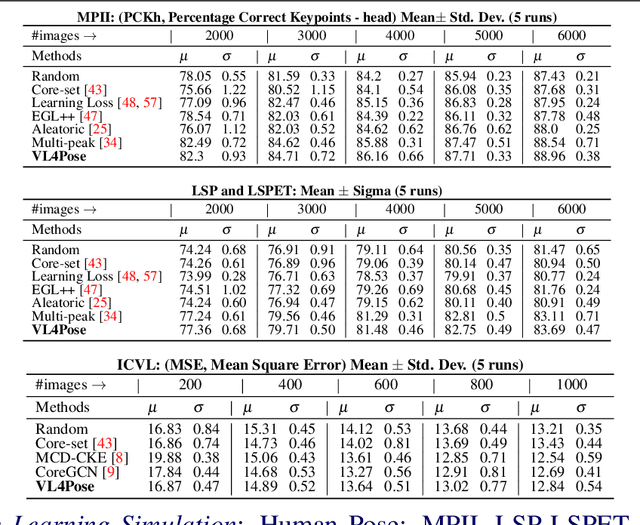

Advances in computing have enabled widespread access to pose estimation, creating new sources of data streams. Unlike mock set-ups for data collection, tapping into these data streams through on-device active learning allows us to directly sample from the real world to improve the spread of the training distribution. However, on-device computing power is limited, implying that any candidate active learning algorithm should have a low compute footprint while also being reliable. Although multiple algorithms cater to pose estimation, they either use extensive compute to power state-of-the-art results or are not competitive in low-resource settings. We address this limitation with VL4Pose (Visual Likelihood For Pose Estimation), a first principles approach for active learning through out-of-distribution detection. We begin with a simple premise: pose estimators often predict incoherent poses for out-of-distribution samples. Hence, can we identify a distribution of poses the model has been trained on, to identify incoherent poses the model is unsure of? Our solution involves modelling the pose through a simple parametric Bayesian network trained via maximum likelihood estimation. Therefore, poses incurring a low likelihood within our framework are out-of-distribution samples making them suitable candidates for annotation. We also observe two useful side-outcomes: VL4Pose in-principle yields better uncertainty estimates by unifying joint and pose level ambiguity, as well as the unintentional but welcome ability of VL4Pose to perform pose refinement in limited scenarios. We perform qualitative and quantitative experiments on three datasets: MPII, LSP and ICVL, spanning human and hand pose estimation. Finally, we note that VL4Pose is simple, computationally inexpensive and competitive, making it suitable for challenging tasks such as on-device active learning.
A generic diffusion-based approach for 3D human pose prediction in the wild
Oct 11, 2022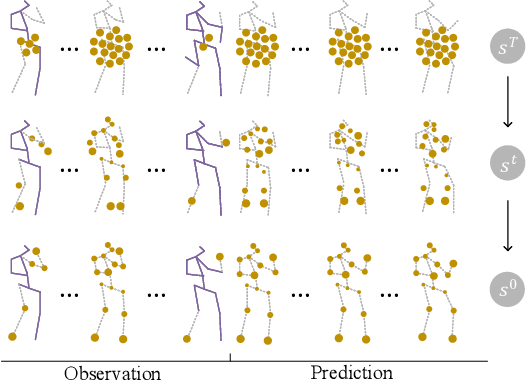
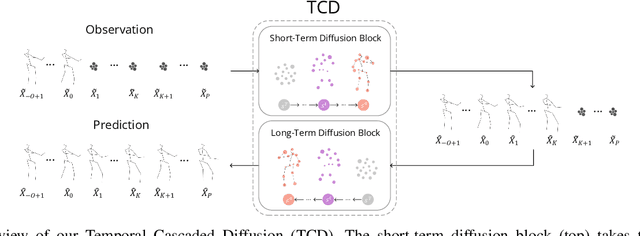

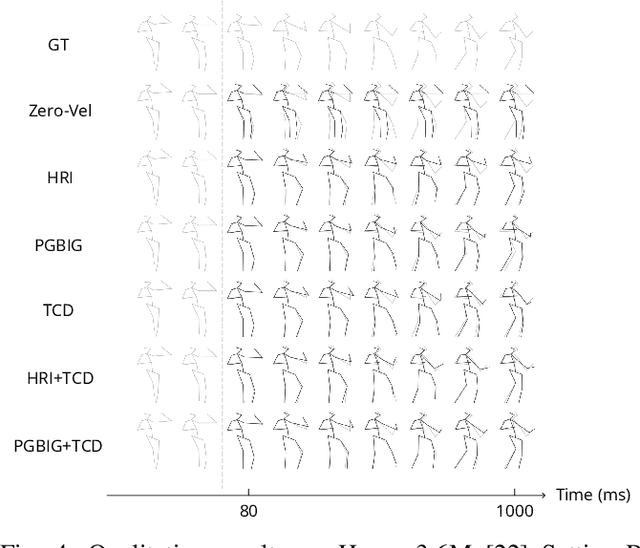
3D human pose forecasting, i.e., predicting a sequence of future human 3D poses given a sequence of past observed ones, is a challenging spatio-temporal task. It can be more challenging in real-world applications where occlusions will inevitably happen, and estimated 3D coordinates of joints would contain some noise. We provide a unified formulation in which incomplete elements (no matter in the prediction or observation) are treated as noise and propose a conditional diffusion model that denoises them and forecasts plausible poses. Instead of naively predicting all future frames at once, our model consists of two cascaded sub-models, each specialized for modeling short and long horizon distributions. We also propose a generic framework to improve any 3D pose forecasting model by leveraging our diffusion model in two additional steps: a pre-processing step to repair the inputs and a post-processing step to refine the outputs. We investigate our findings on four standard datasets (Human3.6M, HumanEva-I, AMASS, and 3DPW) and obtain significant improvements over the state-of-the-art. The code will be made available online.
SoccerNet 2022 Challenges Results
Oct 05, 2022
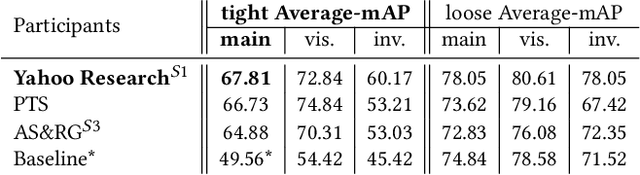
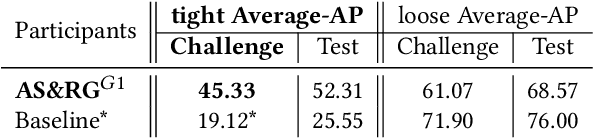
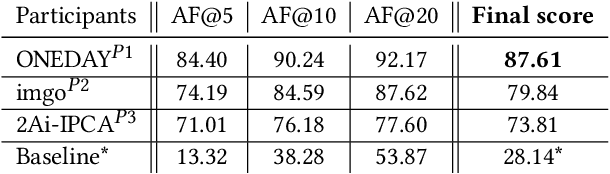
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Safety-compliant Generative Adversarial Networks for Human Trajectory Forecasting
Sep 25, 2022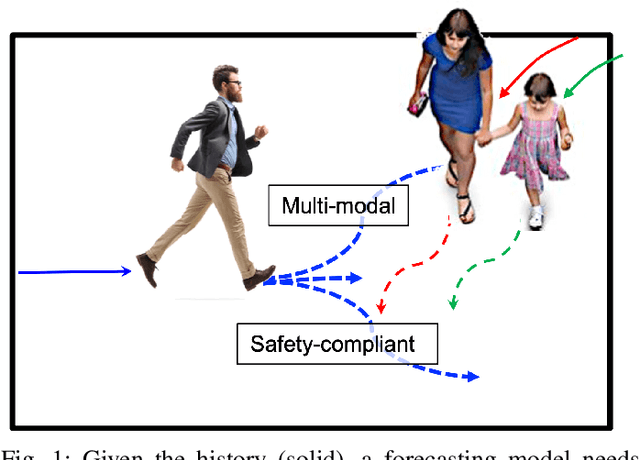
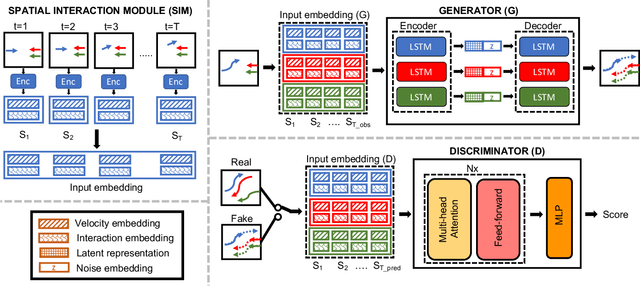
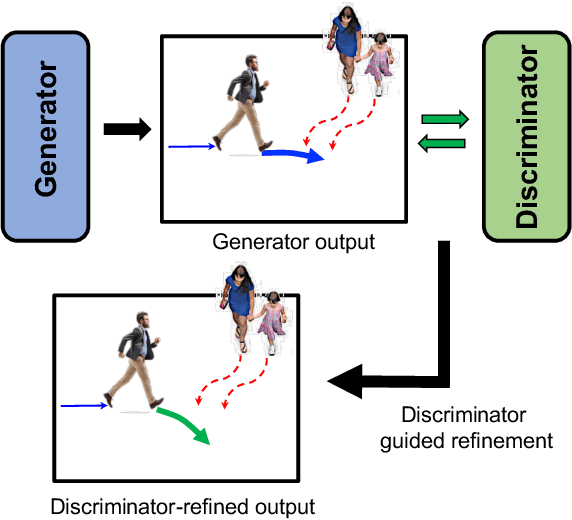
Human trajectory forecasting in crowds presents the challenges of modelling social interactions and outputting collision-free multimodal distribution. Following the success of Social Generative Adversarial Networks (SGAN), recent works propose various GAN-based designs to better model human motion in crowds. Despite superior performance in reducing distance-based metrics, current networks fail to output socially acceptable trajectories, as evidenced by high collisions in model predictions. To counter this, we introduce SGANv2: an improved safety-compliant SGAN architecture equipped with spatio-temporal interaction modelling and a transformer-based discriminator. The spatio-temporal modelling ability helps to learn the human social interactions better while the transformer-based discriminator design improves temporal sequence modelling. Additionally, SGANv2 utilizes the learned discriminator even at test-time via a collaborative sampling strategy that not only refines the colliding trajectories but also prevents mode collapse, a common phenomenon in GAN training. Through extensive experimentation on multiple real-world and synthetic datasets, we demonstrate the efficacy of SGANv2 to provide socially-compliant multimodal trajectories.