 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed Universal Transformers
May 29, 2026We introduce \emph{universal transformers}: fixed transformers that can simulate any transformer in a given class via a suitable input embedding. Analogous to a universal Turing machine, the input embedding encodes a description of the target model while all internal parameters remain fixed. We provide explicit sparse constructions achieving universality when the embedding dimension is sufficiently large, and further show that universality is generic: randomly initialized transformers are universal almost surely, which aligns with recent empirical results of Zhong and Andreas (2024). We empirically validate our theory on the algorithmic tasks of parenthesis balancing and multi-hop reasoning. Our results suggest that much of a transformer's expressive power may reside in its input representation rather than its learned weights.
Nearly Optimal Attention Coresets
May 07, 2026We consider the problem of estimating the Attention mechanism in small space, and prove the existence of coresets for it of nearly optimal size. Specifically, we show that for any set of unit-norm keys and values $(K,V)$ in $\mathbb{R}^d$, there exists a subset $(K',V')$ of size at most $O({\sqrt{d} e^{ρ+o(ρ)}/\varepsilon})$ such that \[ \left\| \operatorname{Attn}(q,K,V)- \operatorname{Attn}(q,K',V') \right\| \le \varepsilon \] simultaneously for all queries whose norm is bounded by $ρ$. This outperforms the best known results for this problem. We also offer an improved lower bound showing that $\varepsilon$-coresets must have size $Ω({\sqrt{d} e^ρ/ε})$.
Fast attention mechanisms: a tale of parallelism
Sep 10, 2025Transformers have the representational capacity to simulate Massively Parallel Computation (MPC) algorithms, but they suffer from quadratic time complexity, which severely limits their scalability. We introduce an efficient attention mechanism called Approximate Nearest Neighbor Attention (ANNA) with sub-quadratic time complexity. We prove that ANNA-transformers (1) retain the expressive power previously established for standard attention in terms of matching the capabilities of MPC algorithms, and (2) can solve key reasoning tasks such as Match2 and $k$-hop with near-optimal depth. Using the MPC framework, we further prove that constant-depth ANNA-transformers can simulate constant-depth low-rank transformers, thereby providing a unified way to reason about a broad class of efficient attention approximations.
Statistical-Computational Trade-offs for Density Estimation
Oct 30, 2024


We study the density estimation problem defined as follows: given $k$ distributions $p_1, \ldots, p_k$ over a discrete domain $[n]$, as well as a collection of samples chosen from a ``query'' distribution $q$ over $[n]$, output $p_i$ that is ``close'' to $q$. Recently~\cite{aamand2023data} gave the first and only known result that achieves sublinear bounds in {\em both} the sampling complexity and the query time while preserving polynomial data structure space. However, their improvement over linear samples and time is only by subpolynomial factors. Our main result is a lower bound showing that, for a broad class of data structures, their bounds cannot be significantly improved. In particular, if an algorithm uses $O(n/\log^c k)$ samples for some constant $c>0$ and polynomial space, then the query time of the data structure must be at least $k^{1-O(1)/\log \log k}$, i.e., close to linear in the number of distributions $k$. This is a novel \emph{statistical-computational} trade-off for density estimation, demonstrating that any data structure must use close to a linear number of samples or take close to linear query time. The lower bound holds even in the realizable case where $q=p_i$ for some $i$, and when the distributions are flat (specifically, all distributions are uniform over half of the domain $[n]$). We also give a simple data structure for our lower bound instance with asymptotically matching upper bounds. Experiments show that the data structure is quite efficient in practice.
Data Structures for Density Estimation
Jun 20, 2023



We study statistical/computational tradeoffs for the following density estimation problem: given $k$ distributions $v_1, \ldots, v_k$ over a discrete domain of size $n$, and sampling access to a distribution $p$, identify $v_i$ that is "close" to $p$. Our main result is the first data structure that, given a sublinear (in $n$) number of samples from $p$, identifies $v_i$ in time sublinear in $k$. We also give an improved version of the algorithm of Acharya et al. (2018) that reports $v_i$ in time linear in $k$. The experimental evaluation of the latter algorithm shows that it achieves a significant reduction in the number of operations needed to achieve a given accuracy compared to prior work.
Learning to Hash Robustly, with Guarantees
Aug 17, 2021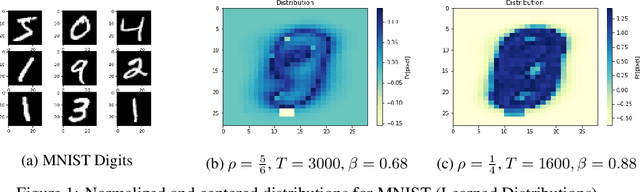



The indexing algorithms for the high-dimensional nearest neighbor search (NNS) with the best worst-case guarantees are based on the randomized Locality Sensitive Hashing (LSH), and its derivatives. In practice, many heuristic approaches exist to "learn" the best indexing method in order to speed-up NNS, crucially adapting to the structure of the given dataset. Oftentimes, these heuristics outperform the LSH-based algorithms on real datasets, but, almost always, come at the cost of losing the guarantees of either correctness or robust performance on adversarial queries, or apply to datasets with an assumed extra structure/model. In this paper, we design an NNS algorithm for the Hamming space that has worst-case guarantees essentially matching that of theoretical algorithms, while optimizing the hashing to the structure of the dataset (think instance-optimal algorithms) for performance on the minimum-performing query. We evaluate the algorithm's ability to optimize for a given dataset both theoretically and practically. On the theoretical side, we exhibit a natural setting (dataset model) where our algorithm is much better than the standard theoretical one. On the practical side, we run experiments that show that our algorithm has a 1.8x and 2.1x better recall on the worst-performing queries to the MNIST and ImageNet datasets.
Streaming Complexity of SVMs
Jul 07, 2020We study the space complexity of solving the bias-regularized SVM problem in the streaming model. This is a classic supervised learning problem that has drawn lots of attention, including for developing fast algorithms for solving the problem approximately. One of the most widely used algorithms for approximately optimizing the SVM objective is Stochastic Gradient Descent (SGD), which requires only $O(\frac{1}{\lambda\epsilon})$ random samples, and which immediately yields a streaming algorithm that uses $O(\frac{d}{\lambda\epsilon})$ space. For related problems, better streaming algorithms are only known for smooth functions, unlike the SVM objective that we focus on in this work. We initiate an investigation of the space complexity for both finding an approximate optimum of this objective, and for the related ``point estimation'' problem of sketching the data set to evaluate the function value $F_\lambda$ on any query $(\theta, b)$. We show that, for both problems, for dimensions $d=1,2$, one can obtain streaming algorithms with space polynomially smaller than $\frac{1}{\lambda\epsilon}$, which is the complexity of SGD for strongly convex functions like the bias-regularized SVM, and which is known to be tight in general, even for $d=1$. We also prove polynomial lower bounds for both point estimation and optimization. In particular, for point estimation we obtain a tight bound of $\Theta(1/\sqrt{\epsilon})$ for $d=1$ and a nearly tight lower bound of $\widetilde{\Omega}(d/{\epsilon}^2)$ for $d = \Omega( \log(1/\epsilon))$. Finally, for optimization, we prove a $\Omega(1/\sqrt{\epsilon})$ lower bound for $d = \Omega( \log(1/\epsilon))$, and show similar bounds when $d$ is constant.
Approximate Nearest Neighbor Search in High Dimensions
Jun 26, 2018The nearest neighbor problem is defined as follows: Given a set $P$ of $n$ points in some metric space $(X,D)$, build a data structure that, given any point $q$, returns a point in $P$ that is closest to $q$ (its "nearest neighbor" in $P$). The data structure stores additional information about the set $P$, which is then used to find the nearest neighbor without computing all distances between $q$ and $P$. The problem has a wide range of applications in machine learning, computer vision, databases and other fields. To reduce the time needed to find nearest neighbors and the amount of memory used by the data structure, one can formulate the {\em approximate} nearest neighbor problem, where the the goal is to return any point $p' \in P$ such that the distance from $q$ to $p'$ is at most $c \cdot \min_{p \in P} D(q,p)$, for some $c \geq 1$. Over the last two decades, many efficient solutions to this problem were developed. In this article we survey these developments, as well as their connections to questions in geometric functional analysis and combinatorial geometry.
Subspace Embedding and Linear Regression with Orlicz Norm
Jun 17, 2018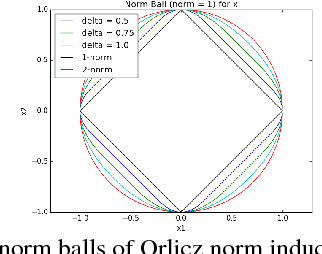


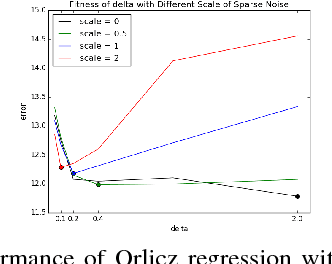
We consider a generalization of the classic linear regression problem to the case when the loss is an Orlicz norm. An Orlicz norm is parameterized by a non-negative convex function $G:\mathbb{R}_+\rightarrow\mathbb{R}_+$ with $G(0)=0$: the Orlicz norm of a vector $x\in\mathbb{R}^n$ is defined as $ \|x\|_G=\inf\left\{\alpha>0\large\mid\sum_{i=1}^n G(|x_i|/\alpha)\leq 1\right\}. $ We consider the cases where the function $G(\cdot)$ grows subquadratically. Our main result is based on a new oblivious embedding which embeds the column space of a given matrix $A\in\mathbb{R}^{n\times d}$ with Orlicz norm into a lower dimensional space with $\ell_2$ norm. Specifically, we show how to efficiently find an embedding matrix $S\in\mathbb{R}^{m\times n},m<n$ such that $\forall x\in\mathbb{R}^{d},\Omega(1/(d\log n)) \cdot \|Ax\|_G\leq \|SAx\|_2\leq O(d^2\log n) \cdot \|Ax\|_G.$ By applying this subspace embedding technique, we show an approximation algorithm for the regression problem $\min_{x\in\mathbb{R}^d} \|Ax-b\|_G$, up to a $O(d\log^2 n)$ factor. As a further application of our techniques, we show how to also use them to improve on the algorithm for the $\ell_p$ low rank matrix approximation problem for $1\leq p<2$.
Approximate Near Neighbors for General Symmetric Norms
Jul 24, 2017We show that every symmetric normed space admits an efficient nearest neighbor search data structure with doubly-logarithmic approximation. Specifically, for every $n$, $d = n^{o(1)}$, and every $d$-dimensional symmetric norm $\|\cdot\|$, there exists a data structure for $\mathrm{poly}(\log \log n)$-approximate nearest neighbor search over $\|\cdot\|$ for $n$-point datasets achieving $n^{o(1)}$ query time and $n^{1+o(1)}$ space. The main technical ingredient of the algorithm is a low-distortion embedding of a symmetric norm into a low-dimensional iterated product of top-$k$ norms. We also show that our techniques cannot be extended to general norms.